Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
- Foundry Local est disponible en préversion. Les versions en préversion publique fournissent un accès anticipé aux fonctionnalités qui sont en déploiement actif.
- Les fonctionnalités, approches et processus peuvent changer ou avoir des capacités limitées avant la disponibilité générale (GA).
Le SDK Local Foundry simplifie la gestion des modèles IA dans les environnements locaux en fournissant des opérations de plan de contrôle distinctes du code d’inférence du plan de données. Cette référence documente les implémentations du Kit de développement logiciel (SDK) pour Python, JavaScript, C# et Rust.
Référence SDK Python
Prerequisites
- Installez Foundry Local et vérifiez que la
foundrycommande est disponible sur votrePATH. - Utilisez Python 3.9 ou version ultérieure.
Installation
Installez le package Python :
pip install foundry-local-sdk
Démarrage rapide
Utilisez cet extrait de code pour vérifier que le Kit de développement logiciel (SDK) peut démarrer le service et atteindre le catalogue local.
from foundry_local import FoundryLocalManager
manager = FoundryLocalManager()
manager.start_service()
catalog = manager.list_catalog_models()
print(f"Catalog models available: {len(catalog)}")
Cet exemple montre comment imprimer un nombre non nul lorsque le service est en cours d’exécution et que le catalogue est disponible.
Références :
Classe FoundryLocalManager
La FoundryLocalManager classe fournit des méthodes pour gérer les modèles, le cache et le service Local Foundry.
Initialisation
from foundry_local import FoundryLocalManager
# Initialize and optionally bootstrap with a model
manager = FoundryLocalManager(alias_or_model_id=None, bootstrap=True)
-
alias_or_model_id: (facultatif) Alias ou ID de modèle à télécharger et charger au démarrage. -
bootstrap: (valeur true par défaut) Si true, démarre le service s’il n’est pas en cours d’exécution et charge le modèle s’il est fourni.
Remarque sur les alias
De nombreuses méthodes décrites dans cette référence ont un alias_or_model_id paramètre dans la signature. Vous pouvez passer à la méthode un alias ou un ID de modèle en tant que valeur. L’utilisation d’un alias est la suivante :
- Sélectionnez le meilleur modèle pour le matériel disponible. Par exemple, si un GPU Nvidia CUDA est disponible, Foundry Local sélectionne le modèle CUDA. Si un NPU pris en charge est disponible, Foundry Local sélectionne le modèle NPU.
- Autorisez-vous à utiliser un nom plus court sans avoir à mémoriser l’ID de modèle.
Conseil / Astuce
Nous vous recommandons de passer au alias_or_model_id paramètre un alias , car lorsque vous déployez votre application, Foundry Local acquiert le meilleur modèle pour l’ordinateur de l’utilisateur final au moment de l’exécution.
Note
Si vous disposez d’un processeur Intel NPU sur Windows, vérifiez que vous avez installé le pilote Intel NPU pour une accélération NPU optimale.
Gestion des services
| Méthode | Signature | Descriptif |
|---|---|---|
is_service_running() |
() -> bool |
Vérifie si le service local Foundry est en cours d’exécution. |
start_service() |
() -> None |
Démarre le service local Foundry. |
service_uri |
@property -> str |
Retourne l’URI du service. |
endpoint |
@property -> str |
Retourne le point de terminaison de service. |
api_key |
@property -> str |
Retourne la clé API (à partir d’env ou de la valeur par défaut). |
Gestion du catalogue
| Méthode | Signature | Descriptif |
|---|---|---|
list_catalog_models() |
() -> list[FoundryModelInfo] |
Répertorie tous les modèles disponibles dans le catalogue. |
refresh_catalog() |
() -> None |
Actualise le catalogue de modèles. |
get_model_info() |
(alias_or_model_id: str, raise_on_not_found=False) -> FoundryModelInfo \| None |
Obtient les informations du modèle via l'alias ou l'ID. |
Gestion du cache
| Méthode | Signature | Descriptif |
|---|---|---|
get_cache_location() |
() -> str |
Retourne le chemin du répertoire du cache du modèle. |
list_cached_models() |
() -> list[FoundryModelInfo] |
Répertorie les modèles téléchargés dans le cache local. |
Gestion des modèles
| Méthode | Signature | Descriptif |
|---|---|---|
download_model() |
(alias_or_model_id: str, token: str = None, force: bool = False) -> FoundryModelInfo |
Télécharge un modèle dans le cache local. |
load_model() |
(alias_or_model_id: str, ttl: int = 600) -> FoundryModelInfo |
Charge un modèle dans le serveur d’inférence. |
unload_model() |
(alias_or_model_id: str, force: bool = False) -> None |
Décharge un modèle à partir du serveur d’inférence. |
list_loaded_models() |
() -> list[FoundryModelInfo] |
Répertorie tous les modèles actuellement chargés dans le service. |
FoundryModelInfo
Les méthodes list_catalog_models(), list_cached_models()et list_loaded_models() retournent une liste d’objets FoundryModelInfo . Vous pouvez utiliser les informations contenues dans cet objet pour affiner davantage la liste. Vous pouvez également obtenir les informations d’un modèle directement en appelant la get_model_info(alias_or_model_id) méthode.
Ces objets contiennent les champs suivants :
| Champ | Type | Descriptif |
|---|---|---|
alias |
str |
Alias du modèle. |
id |
str |
Identifiant unique du modèle. |
version |
str |
Version du modèle. |
execution_provider |
str |
Accélérateur (fournisseur d’exécution) utilisé pour exécuter le modèle. |
device_type |
DeviceType |
Type d’appareil du modèle : PROCESSEUR, GPU, NPU. |
uri |
str |
URI du modèle. |
file_size_mb |
int |
Taille du modèle sur le disque en Mo. |
supports_tool_calling |
bool |
Indique si le modèle prend en charge l’appel d’outils. |
prompt_template |
dict \| None |
Modèle de requête du modèle. |
provider |
str |
Fournisseur du modèle (où le modèle est publié). |
publisher |
str |
Éditeur du modèle (qui a publié le modèle). |
license |
str |
Nom de la licence du modèle. |
task |
str |
Tâche du modèle. Un de chat-completions ou automatic-speech-recognition. |
ep_override |
str \| None |
Remplacer le fournisseur d'exécution, s'il diffère de celui par défaut du modèle. |
Fournisseurs d’exécution
L'un des:
-
CPUExecutionProvider- Exécution basée sur le processeur -
CUDAExecutionProvider- Exécution du GPU NVIDIA CUDA -
WebGpuExecutionProvider- Exécution de WebGPU -
QNNExecutionProvider- Exécution du réseau neuronal Qualcomm (NPU) -
OpenVINOExecutionProvider- Exécution d’Intel OpenVINO -
NvTensorRTRTXExecutionProvider- Exécution de TensorRT NVIDIA -
VitisAIExecutionProvider- Exécution d’AMD Vitis AI
Exemple d’utilisation
Le code suivant montre comment utiliser la FoundryLocalManager classe pour gérer les modèles et interagir avec le service Local Foundry.
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be selected
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry.
manager = FoundryLocalManager()
# List available models in the catalog
catalog = manager.list_catalog_models()
print(f"Available models in the catalog: {catalog}")
# Download and load a model
model_info = manager.download_model(alias)
model_info = manager.load_model(alias)
print(f"Model info: {model_info}")
# List models in cache
local_models = manager.list_cached_models()
print(f"Models in cache: {local_models}")
# List loaded models
loaded = manager.list_loaded_models()
print(f"Models running in the service: {loaded}")
# Unload a model
manager.unload_model(alias)
Cet exemple répertorie les modèles, télécharge et charge un modèle, puis le décharge.
Références :
Intégrer avec le Kit de développement logiciel (SDK) OpenAI
Installez le package OpenAI :
pip install openai
Le code suivant montre comment intégrer le FoundryLocalManager Kit de développement logiciel (SDK) OpenAI pour interagir avec un modèle local.
import openai
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be downloaded
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry
# Local service if it is not already running and load the specified model.
manager = FoundryLocalManager(alias)
# The remaining code uses the OpenAI Python SDK to interact with the local model.
# Configure the client to use the local Foundry service
client = openai.OpenAI(
base_url=manager.endpoint,
api_key=manager.api_key # API key is not required for local usage
)
# Set the model to use and generate a streaming response
stream = client.chat.completions.create(
model=manager.get_model_info(alias).id,
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True
)
# Print the streaming response
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
Cet exemple diffuse une réponse de complétion de conversation à partir du modèle local.
Références :
Informations de référence sur le Kit de développement logiciel (SDK) JavaScript
Prerequisites
- Installez Foundry Local et vérifiez que la
foundrycommande est disponible sur votrePATH.
Installation
Installez le package à partir de npm :
npm install foundry-local-sdk
Démarrage rapide
Utilisez cet extrait de code pour vérifier que le Kit de développement logiciel (SDK) peut démarrer le service et atteindre le catalogue local.
import { FoundryLocalManager } from "foundry-local-sdk";
const manager = new FoundryLocalManager();
await manager.startService();
const catalogModels = await manager.listCatalogModels();
console.log(`Catalog models available: ${catalogModels.length}`);
Cet exemple montre comment imprimer un nombre non nul lorsque le service est en cours d’exécution et que le catalogue est disponible.
Références :
Classe FoundryLocalManager
La FoundryLocalManager classe vous permet de gérer des modèles, de contrôler le cache et d’interagir avec le service Local Foundry dans les environnements de navigateur et de Node.js.
Initialisation
import { FoundryLocalManager } from "foundry-local-sdk";
const foundryLocalManager = new FoundryLocalManager();
Options disponibles :
-
host: URL de base du service local Foundry -
fetch: (facultatif) Implémentation d’extraction personnalisée pour les environnements tels que Node.js
Remarque sur les alias
De nombreuses méthodes décrites dans cette référence ont un aliasOrModelId paramètre dans la signature. Vous pouvez passer à la méthode un alias ou un ID de modèle en tant que valeur. L’utilisation d’un alias est la suivante :
- Sélectionnez le meilleur modèle pour le matériel disponible. Par exemple, si un GPU Nvidia CUDA est disponible, Foundry Local sélectionne le modèle CUDA. Si un NPU pris en charge est disponible, Foundry Local sélectionne le modèle NPU.
- Autorisez-vous à utiliser un nom plus court sans avoir à mémoriser l’ID de modèle.
Conseil / Astuce
Nous vous recommandons de passer au aliasOrModelId paramètre un alias , car lorsque vous déployez votre application, Foundry Local acquiert le meilleur modèle pour l’ordinateur de l’utilisateur final au moment de l’exécution.
Note
Si vous disposez d’un processeur Intel NPU sur Windows, vérifiez que vous avez installé le pilote Intel NPU pour une accélération NPU optimale.
Gestion des services
| Méthode | Signature | Descriptif |
|---|---|---|
init() |
(aliasOrModelId?: string) => Promise<FoundryModelInfo \| void> |
Initialise le Kit de développement logiciel (SDK) et charge éventuellement un modèle. |
isServiceRunning() |
() => Promise<boolean> |
Vérifie si le service local Foundry est en cours d’exécution. |
startService() |
() => Promise<void> |
Démarre le service local Foundry. |
serviceUrl |
string |
URL de base du service local Foundry. |
endpoint |
string |
Point de terminaison de l’API (serviceUrl + /v1). |
apiKey |
string |
Clé API (aucune). |
Gestion du catalogue
| Méthode | Signature | Descriptif |
|---|---|---|
listCatalogModels() |
() => Promise<FoundryModelInfo[]> |
Répertorie tous les modèles disponibles dans le catalogue. |
refreshCatalog() |
() => Promise<void> |
Actualise le catalogue de modèles. |
getModelInfo() |
(aliasOrModelId: string, throwOnNotFound = false) => Promise<FoundryModelInfo \| null> |
Obtient les informations du modèle via l'alias ou l'ID. |
Gestion du cache
| Méthode | Signature | Descriptif |
|---|---|---|
getCacheLocation() |
() => Promise<string> |
Retourne le chemin du répertoire du cache du modèle. |
listCachedModels() |
() => Promise<FoundryModelInfo[]> |
Répertorie les modèles téléchargés dans le cache local. |
Gestion des modèles
| Méthode | Signature | Descriptif |
|---|---|---|
downloadModel() |
(aliasOrModelId: string, token?: string, force = false, onProgress?) => Promise<FoundryModelInfo> |
Télécharge un modèle dans le cache local. |
loadModel() |
(aliasOrModelId: string, ttl = 600) => Promise<FoundryModelInfo> |
Charge un modèle dans le serveur d’inférence. |
unloadModel() |
(aliasOrModelId: string, force = false) => Promise<void> |
Décharge un modèle à partir du serveur d’inférence. |
listLoadedModels() |
() => Promise<FoundryModelInfo[]> |
Répertorie tous les modèles actuellement chargés dans le service. |
Exemple d’utilisation
Le code suivant montre comment utiliser la FoundryLocalManager classe pour gérer les modèles et interagir avec le service Local Foundry.
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
const manager = new FoundryLocalManager();
// Initialize the SDK and optionally load a model
const modelInfo = await manager.init(alias);
console.log("Model Info:", modelInfo);
// Check if the service is running
const isRunning = await manager.isServiceRunning();
console.log(`Service running: ${isRunning}`);
// List available models in the catalog
const catalog = await manager.listCatalogModels();
// Download and load a model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// List models in cache
const localModels = await manager.listCachedModels();
// List loaded models
const loaded = await manager.listLoadedModels();
// Unload a model
await manager.unloadModel(alias);
Cet exemple télécharge et charge un modèle, puis répertorie les modèles mis en cache et chargés.
Références :
Intégration à OpenAI Client
Installez le package OpenAI :
npm install openai
Le code suivant montre comment intégrer le FoundryLocalManager avec le client OpenAI pour interagir avec un modèle local.
import { OpenAI } from "openai";
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
// Create a FoundryLocalManager instance. This will start the Foundry
// Local service if it is not already running.
const foundryLocalManager = new FoundryLocalManager();
// Initialize the manager with a model. This will download the model
// if it is not already present on the user's device.
const modelInfo = await foundryLocalManager.init(alias);
console.log("Model Info:", modelInfo);
const openai = new OpenAI({
baseURL: foundryLocalManager.endpoint,
apiKey: foundryLocalManager.apiKey,
});
async function streamCompletion() {
const stream = await openai.chat.completions.create({
model: modelInfo.id,
messages: [{ role: "user", content: "What is the golden ratio?" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
}
streamCompletion();
Cet exemple diffuse une réponse de complétion de conversation à partir du modèle local.
Références :
Utilisation du navigateur
Le Kit de développement logiciel (SDK) inclut une version compatible avec le navigateur, où vous devez spécifier manuellement l’URL de l’hôte :
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
// Note: The `init`, `isServiceRunning`, and `startService` methods
// are not available in the browser version
Note
La version du navigateur ne prend pas en charge les méthodes init, isServiceRunning, et startService. Vous devez vous assurer que le service local Foundry est en cours d’exécution avant d’utiliser le Kit de développement logiciel (SDK) dans un environnement de navigateur. Vous pouvez démarrer le service à l’aide de l’interface CLI locale Foundry : foundry service start. Vous pouvez glaner l’URL du service à partir de la sortie CLI.
Exemple d’utilisation
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
const alias = "qwen2.5-0.5b";
// Get all available models
const catalog = await manager.listCatalogModels();
console.log("Available models in catalog:", catalog);
// Download and load a specific model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// View models in your local cache
const localModels = await manager.listCachedModels();
console.log("Cached models:", localModels);
// Check which models are currently loaded
const loaded = await manager.listLoadedModels();
console.log("Loaded models in inference service:", loaded);
// Unload a model when finished
await manager.unloadModel(alias);
Références :
Informations de référence sur le SDK C#
Guide de configuration du projet
Il existe deux packages NuGet pour le SDK Local Foundry ( WinML et un package multiplateforme) qui ont la même surface d’API, mais qui sont optimisés pour différentes plateformes :
-
Windows : utilise le
Microsoft.AI.Foundry.Local.WinMLpackage spécifique aux applications Windows, qui utilise l’infrastructure Windows Machine Learning (WinML). -
Multiplateforme : utilise le
Microsoft.AI.Foundry.Localpackage qui peut être utilisé pour les applications multiplateformes (Windows, Linux, macOS).
Selon votre plateforme cible, suivez ces instructions pour créer une application C# et ajouter les dépendances nécessaires :
Utilisez Foundry Local dans votre projet C# en suivant ces instructions spécifiques à Windows ou multiplateformes (macOS/Linux/Windows) :
- Créez un projet C# et accédez-y :
dotnet new console -n app-name cd app-name - Ouvrez et modifiez le
app-name.csprojfichier dans :<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0-windows10.0.26100</TargetFramework> <RootNamespace>app-name</RootNamespace> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <WindowsAppSDKSelfContained>false</WindowsAppSDKSelfContained> <WindowsPackageType>None</WindowsPackageType> <EnableCoreMrtTooling>false</EnableCoreMrtTooling> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.AI.Foundry.Local.WinML" Version="0.8.2.1" /> <PackageReference Include="Microsoft.Extensions.Logging" Version="9.0.10" /> <PackageReference Include="OpenAI" Version="2.5.0" /> </ItemGroup> </Project> - Créez un
nuget.configfichier à la racine du projet avec le contenu suivant afin que les packages soient restaurés correctement :<?xml version="1.0" encoding="utf-8"?> <configuration> <packageSources> <clear /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> <add key="ORT" value="https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT/nuget/v3/index.json" /> </packageSources> <packageSourceMapping> <packageSource key="nuget.org"> <package pattern="*" /> </packageSource> <packageSource key="ORT"> <package pattern="*Foundry*" /> </packageSource> </packageSourceMapping> </configuration>
Démarrage rapide
Utilisez cet extrait de code pour vérifier que le Kit de développement logiciel (SDK) peut initialiser et accéder au catalogue de modèles local.
using Microsoft.AI.Foundry.Local;
using Microsoft.Extensions.Logging;
using System.Linq;
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
};
using var loggerFactory = LoggerFactory.Create(builder =>
{
builder.SetMinimumLevel(Microsoft.Extensions.Logging.LogLevel.Information);
});
var logger = loggerFactory.CreateLogger<Program>();
await FoundryLocalManager.CreateAsync(config, logger);
var manager = FoundryLocalManager.Instance;
var catalog = await manager.GetCatalogAsync();
var models = await catalog.ListModelsAsync();
Console.WriteLine($"Models available: {models.Count()}");
Cet exemple montre comment imprimer le nombre de modèles disponibles pour votre matériel.
Références :
Refonte
Pour améliorer votre capacité à expédier des applications à l’aide de l’IA sur appareil, il existe des modifications substantielles apportées à l’architecture du SDK C# dans la version 0.8.0 et les versions ultérieures. Dans cette section, nous décrivons les principales modifications pour vous aider à migrer vos applications vers la dernière version du SDK.
Note
Dans la version 0.8.0 du Kit de développement logiciel (SDK) et les versions ultérieures, il existe des modifications majeures dans l’API par rapport aux versions précédentes.
Le diagramme suivant montre comment l’architecture précédente - pour les versions antérieures à - 0.8.0 s’appuyait fortement sur l’utilisation d’un serveur web REST pour gérer les modèles et l’inférence comme les achèvements de conversation :

Le Kit de développement logiciel (SDK) utilise un appel procédural distant (RPC) pour rechercher l’exécutable CLI local Foundry sur l’ordinateur, démarrer le serveur web, puis communiquer avec lui via HTTP. Cette architecture a eu plusieurs limitations, notamment :
- Complexité de la gestion du cycle de vie du serveur web.
- Déploiement difficile : les utilisateurs finaux ont dû installer l’interface CLI locale Foundry sur leurs ordinateurs et votre application.
- La gestion des versions de l’interface CLI et du Kit de développement logiciel (SDK) peut entraîner des problèmes de compatibilité.
Pour résoudre ces problèmes, l’architecture repensée dans la version 0.8.0 et les versions ultérieures utilise une approche plus rationalisée. La nouvelle architecture est la suivante :

Dans cette nouvelle architecture :
- Votre application est autonome. L’interface CLI locale Foundry n’est pas nécessaire pour être installée séparément sur l’ordinateur de l’utilisateur final, ce qui facilite le déploiement d’applications.
- Le serveur web REST est facultatif. Vous pouvez toujours utiliser le serveur web si vous souhaitez intégrer d’autres outils qui communiquent via HTTP. Lisez Complétions de chat via le serveur REST avec Foundry Local pour plus d'informations sur cette fonctionnalité.
- Le SDK prend en charge nativement les saisies semi-automatiques et les transcriptions audio, ce qui vous permet de créer des applications IA conversationnelles avec moins de dépendances. Pour des détails sur l'utilisation de cette fonctionnalité, lisez l'API de complétions de chat native Foundry Local.
- Sur les appareils Windows, vous pouvez utiliser une build Windows ML qui gère l’accélération matérielle pour les modèles présents sur l’appareil en intégrant le bon environnement d'exécution et les pilotes appropriés.
Modifications d'API
La version 0.8.0 et les versions ultérieures fournissent une API plus orientée objet et composable. Le point d’entrée principal continue d’être la FoundryLocalManager classe, mais au lieu d’être un ensemble plat de méthodes qui fonctionnent via des appels statiques à une API HTTP sans état, le SDK expose désormais des méthodes sur l’instance FoundryLocalManager qui conservent l’état sur le service et les modèles.
| Primitif | Versions < 0.8.0 | Versions >= 0.8.0 |
|---|---|---|
| Configuration | N/A | config = Configuration(...) |
| Obtenir le gestionnaire | mgr = FoundryLocalManager(); |
await FoundryLocalManager.CreateAsync(config, logger);var mgr = FoundryLocalManager.Instance; |
| Obtenir le catalogue | N/A | catalog = await mgr.GetCatalogAsync(); |
| Répertorier les modèles | mgr.ListCatalogModelsAsync(); |
catalog.ListModelsAsync(); |
| Obtenir un modèle | mgr.GetModelInfoAsync("aliasOrModelId"); |
catalog.GetModelAsync(alias: "alias"); |
| Obtenir un variant | N/A | model.SelectedVariant; |
| Définir le variant | N/A | model.SelectVariant(); |
| Télécharger un modèle | mgr.DownloadModelAsync("aliasOrModelId"); |
model.DownloadAsync() |
| Charger un modèle | mgr.LoadModelAsync("aliasOrModelId"); |
model.LoadAsync() |
| Décharger un modèle | mgr.UnloadModelAsync("aliasOrModelId"); |
model.UnloadAsync() |
| Répertorier les modèles chargés | mgr.ListLoadedModelsAsync(); |
catalog.GetLoadedModelsAsync(); |
| Obtenir le chemin d’accès au modèle | N/A | model.GetPathAsync() |
| Démarrer le service | mgr.StartServiceAsync(); |
mgr.StartWebServerAsync(); |
| Arrêter le service | mgr.StopServiceAsync(); |
mgr.StopWebServerAsync(); |
| Emplacement du cache | mgr.GetCacheLocationAsync(); |
config.ModelCacheDir |
| Répertorier les modèles mis en cache | mgr.ListCachedModelsAsync(); |
catalog.GetCachedModelsAsync(); |
L’API permet à Foundry Local d’être plus configurable sur le serveur web, la journalisation, l’emplacement du cache et la sélection de variantes de modèle. Par exemple, la Configuration classe vous permet de configurer le nom de l’application, le niveau de journalisation, les URL de serveur web et les répertoires pour les données d’application, le cache de modèle et les journaux :
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
Web = new Configuration.WebService
{
Urls = "http://127.0.0.1:55588"
},
AppDataDir = "./foundry_local_data",
ModelCacheDir = "{AppDataDir}/model_cache",
LogsDir = "{AppDataDir}/logs"
};
Références :
Dans la version précédente du SDK C# local Foundry, vous n’avez pas pu configurer ces paramètres directement via le SDK, ce qui a limité votre capacité à personnaliser le comportement du service.
Réduire la taille du package d’application
Le Kit de développement logiciel (SDK) Local Foundry utilise le package NuGet Microsoft.ML.OnnxRuntime.Foundry en tant que dépendance. Le Microsoft.ML.OnnxRuntime.Foundry package fournit le bundle d’exécution d’inférence, qui est l’ensemble de bibliothèques nécessaires pour exécuter efficacement l’inférence sur des appareils matériels de fournisseur spécifiques. Le bundle du runtime d'inférence comprend les composants suivants :
-
Bibliothèque ONNX Runtime : moteur d’inférence principal (
onnxruntime.dll). -
Bibliothèque du fournisseur d’exécution du runtime ONNX (EP). Back-end spécifique au matériel dans ONNX Runtime qui optimise et exécute des parties d’un modèle d'apprentissage automatique avec un accélérateur matériel. Par exemple:
- CUDA EP :
onnxruntime_providers_cuda.dll - QNN EP :
onnxruntime_providers_qnn.dll
- CUDA EP :
-
Bibliothèques de fournisseurs de matériel indépendants (IHV) Par exemple:
- WebGPU : Dépendances DirectX (
dxcompiler.dll,dxil.dll) - QNN : Dépendances QNN de Qualcomm (
QnnSystem.dll, etc.)
- WebGPU : Dépendances DirectX (
Le tableau suivant résume les bibliothèques EP et IHV qui sont regroupées avec votre application et ce que WinML télécharge/installe au moment de l’exécution :
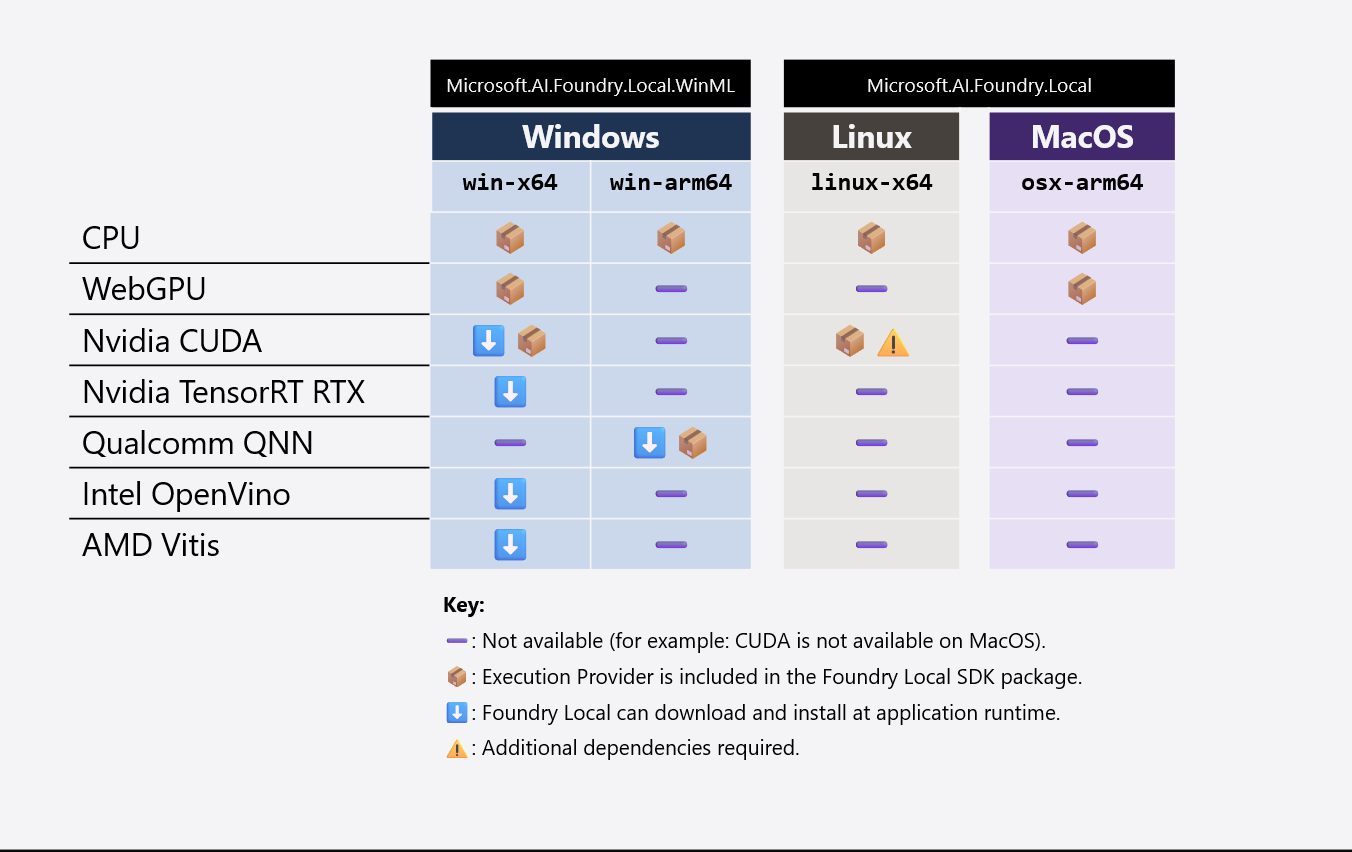
Dans toutes les plateformes et architectures, le processeur EP est requis. Les bibliothèques WEBGPU EP et IHV sont de petite taille (par exemple, WebGPU ajoute seulement ~7 Mo à votre package d’application) et sont requises dans Windows et macOS. Toutefois, les adresses EPS CUDA et QNN sont de grande taille (par exemple, CUDA ajoute ~1 Go à votre package d’application) afin que nous vous recommandons d’exclure ces EPs de votre package d’application. WinML télécharge/installe CUDA et QNN au moment de l’exécution si l’utilisateur final dispose d’un matériel compatible.
Note
Nous travaillons à supprimer les EPs CUDA et QNN du Microsoft.ML.OnnxRuntime.Foundry paquet dans les futures versions afin que vous n'ayez pas besoin d'inclure un ExcludeExtraLibs.props fichier pour les retirer de votre paquet de l'application.
Pour réduire la taille de votre package d’application, vous pouvez créer un ExcludeExtraLibs.props fichier dans votre répertoire de projet avec le contenu suivant, ce qui exclut les bibliothèques CUDA et QNN EP et IHV lorsque vous publiez votre application :
<Project>
<!-- we want to ensure we're using the onnxruntime libraries from Foundry Local Core so
we delete the WindowsAppSdk versions once they're unzipped. -->
<Target Name="ExcludeOnnxRuntimeLibs" AfterTargets="ExtractMicrosoftWindowsAppSDKMsixFiles">
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime.dll"/>
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime_providers_shared.dll"/>
<Message Importance="Normal" Text="Deleted onnxruntime libraries from $(MicrosoftWindowsAppSDKMsixContent)." />
</Target>
<!-- Remove CUDA EP and IHV libraries on Windows x64 -->
<Target Name="ExcludeCudaLibs" Condition="'$(RuntimeIdentifier)'=='win-x64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<!-- match onnxruntime*cuda.* (we're matching %(Filename) which excludes the extension) -->
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^onnxruntime.*cuda.*', RegexOptions.IgnoreCase))" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime CUDA libraries from package." />
</Target>
<!-- Remove QNN EP and IHV libraries on Windows arm64 -->
<Target Name="ExcludeQnnLibs" Condition="'$(RuntimeIdentifier)'=='win-arm64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)%(Extension)',
'^QNN.*\.dll', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^libQNNhtp.*', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="'%(FileName)%(Extension)' == 'onnxruntime_providers_qnn.dll'" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime QNN libraries from package." />
</Target>
<!-- need to manually copy on linux-x64 due to the nuget packages not having the correct props file setup -->
<ItemGroup Condition="'$(RuntimeIdentifier)' == 'linux-x64'">
<!-- 'Update' as the Core package will add these dependencies, but we want to be explicit about the version -->
<PackageReference Update="Microsoft.ML.OnnxRuntime.Gpu" />
<PackageReference Update="Microsoft.ML.OnnxRuntimeGenAI.Cuda" />
<OrtNativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntime.gpu.linux/$(OnnxRuntimeVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
<OrtGenAINativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntimegenai.cuda/$(OnnxRuntimeGenAIVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
</ItemGroup>
<Target Name="CopyOrtNativeLibs" AfterTargets="Build" Condition=" '$(RuntimeIdentifier)' == 'linux-x64'">
<Copy SourceFiles="@(OrtNativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
<Copy SourceFiles="@(OrtGenAINativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
</Target>
</Project>
Dans votre fichier projet (.csproj), ajoutez la ligne suivante pour importer le ExcludeExtraLibs.props fichier :
<!-- other project file content -->
<Import Project="ExcludeExtraLibs.props" />
Windows : Dépendances CUDA
L’EP CUDA est extrait dans votre application Linux via Microsoft.ML.OnnxRuntime.Foundry, mais nous n’incluons pas les bibliothèques IHV. Si vous souhaitez autoriser vos utilisateurs finaux avec des appareils CUDA à bénéficier de performances plus élevées, vous devez ajouter les bibliothèques CUDA IHV suivantes à votre application :
- CUBLAS v12.8.4 (télécharger à partir de NVIDIA Developer)
- cublas64_12.dll
- cublasLt64_12.dll
- CUDA RT v12.8.90 (télécharger à partir de NVIDIA Developer)
- cudart64_12.dll
- CUDNN v9.8.0 (télécharger à partir de NVIDIA Developer)
- cudnn_graph64_9.dll
- cudnn_ops64_9.dll
- cudnn64_9.dll
- CUDA FFT v11.3.3.83 (télécharger à partir de NVIDIA Developer)
- cufft64_11.dll
Avertissement
L’ajout des bibliothèques CUDA EP et IHV à votre application augmente la taille de votre package d’application de 1 Go.
Échantillons
- Pour obtenir des exemples d’applications qui montrent comment utiliser le SDK C# local Foundry, consultez le dépôt GitHub d’exemples de sdk C# Foundry.
Référence d’API
- Pour plus d’informations sur le SDK C# local Foundry, consultez la référence de l’API du SDK C# Local Foundry.
Référence du SDK Rust
Le Kit de développement logiciel (SDK) Rust pour Foundry Local permet de gérer les modèles, de contrôler le cache et d’interagir avec le service Local Foundry.
Prerequisites
- Installez Foundry Local et vérifiez que la
foundrycommande est disponible sur votrePATH. - Utilisez Rust 1.70.0 ou version ultérieure.
Installation
Pour utiliser le Kit de développement logiciel (SDK) Rust local Foundry, ajoutez ce qui suit à votre Cargo.toml:
[dependencies]
foundry-local = "0.1.0"
Vous pouvez également ajouter le crate Foundry Local à l’aide de cargo :
cargo add foundry-local
Démarrage rapide
Utilisez cet extrait de code pour vérifier que le Kit de développement logiciel (SDK) peut démarrer le service et lire le catalogue local.
use anyhow::Result;
use foundry_local::FoundryLocalManager;
#[tokio::main]
async fn main() -> Result<()> {
let mut manager = FoundryLocalManager::builder().bootstrap(true).build().await?;
let models = manager.list_catalog_models().await?;
println!("Catalog models available: {}", models.len());
Ok(())
}
Cet exemple montre comment imprimer un nombre non nul lorsque le service est en cours d’exécution et que le catalogue est disponible.
Références :
FoundryLocalManager
Gestionnaire des opérations du Kit de développement logiciel (SDK) local Foundry.
Fields
-
service_uri: Option<String>— URI du service Foundry. -
client: Option<HttpClient>: client HTTP pour les requêtes d’API. -
catalog_list: Option<Vec<FoundryModelInfo>>— Liste mise en cache des modèles de catalogue. -
catalog_dict: Option<HashMap<String, FoundryModelInfo>>— Dictionnaire mis en cache des modèles de catalogue. -
timeout: Option<u64>— Délai d’expiration du client HTTP facultatif.
Méthodes
pub fn builder() -> FoundryLocalManagerBuilder
Créer un générateur pourFoundryLocalManager.pub fn service_uri(&self) -> Result<&str>
Obtenez l’URI du service.
Retourne : URI du service Foundry.fn client(&self) -> Result<&HttpClient>
Obtenez l’instance du client HTTP.
Retourne : Client HTTP.pub fn endpoint(&self) -> Result<String>
Obtenir le point de terminaison du service.
Retourne : URL du point de terminaison.pub fn api_key(&self) -> String
Obtenez la clé API pour l’authentification.
Retourne : Clé API.pub fn is_service_running(&mut self) -> bool
Vérifiez si le service est en cours d’exécution et définissez l’URI du service s’il est trouvé.
Retourne :truesi en cours d’exécution,falsesinon.pub fn start_service(&mut self) -> Result<()>
Démarrez le service Foundry Local.pub async fn list_catalog_models(&mut self) -> Result<&Vec<FoundryModelInfo>>
Obtenez la liste des modèles disponibles dans le catalogue.pub fn refresh_catalog(&mut self)
Actualisez le cache du catalogue.pub async fn get_model_info(&mut self, alias_or_model_id: &str, raise_on_not_found: bool) -> Result<FoundryModelInfo>
Obtenez des informations sur le modèle par alias ou ID.
Arguments :-
alias_or_model_id: Alias ou ID de modèle. -
raise_on_not_found: Si VRAI, erreur si introuvable.
-
pub async fn get_cache_location(&self) -> Result<String>
Obtenez l’emplacement du cache sous forme de chaîne.pub async fn list_cached_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Répertorier les modèles mis en cache.pub async fn download_model(&mut self, alias_or_model_id: &str, token: Option<&str>, force: bool) -> Result<FoundryModelInfo>
Téléchargez un modèle.
Arguments :-
alias_or_model_id: Alias ou ID de modèle. -
token: jeton d’authentification facultatif. -
force: Forcer un nouveau téléchargement si déjà mis en cache.
-
pub async fn load_model(&mut self, alias_or_model_id: &str, ttl: Option<i32>) -> Result<FoundryModelInfo>
Chargez un modèle pour l’inférence.
Arguments :-
alias_or_model_id: Alias ou ID de modèle. -
ttl: durée de vie facultative en secondes.
-
pub async fn unload_model(&mut self, alias_or_model_id: &str, force: bool) -> Result<()>
Décharger un modèle.
Arguments :-
alias_or_model_id: Alias ou ID de modèle. -
force: Forcer un déchargement même en cas d’utilisation.
-
pub async fn list_loaded_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Lister les modèles chargés.
FoundryLocalManagerBuilder
Générateur pour la création d’une FoundryLocalManager instance.
Fields
-
alias_or_model_id: Option<String>— Alias ou ID de modèle à télécharger et charger. -
bootstrap: bool— Indique si le service doit être démarré s’il n’est pas en cours d’exécution. -
timeout_secs: Option<u64>— Délai d’expiration du client HTTP en secondes.
Méthodes
pub fn new() -> Self
Créez une nouvelle instance de constructeur.pub fn alias_or_model_id(mut self, alias_or_model_id: impl Into<String>) -> Self
Définissez l’alias ou l’ID de modèle à télécharger et charger.pub fn bootstrap(mut self, bootstrap: bool) -> Self
Définissez s’il faut démarrer le service s’il n’est pas en cours d’exécution.pub fn timeout_secs(mut self, timeout_secs: u64) -> Self
Définissez le délai d’expiration du client HTTP en secondes.pub async fn build(self) -> Result<FoundryLocalManager>
Générez l’instanceFoundryLocalManager.
FoundryModelInfo
Représente des informations sur un modèle.
Fields
-
alias: String— Alias de modèle. -
id: String— ID de modèle. -
version: String— Version du modèle. -
runtime: ExecutionProvider— Fournisseur d’exécution (PROCESSEUR, CUDA, etc.). -
uri: String— URI du modèle. -
file_size_mb: i32— Taille du fichier de modèle en Mo. -
prompt_template: serde_json::Value— Modèle de requête du modèle. -
provider: String— Nom du fournisseur. -
publisher: String— Nom du serveur de publication. -
license: String— Type de licence. -
task: String— Tâche de modèle (par exemple, génération de texte).
Méthodes
from_list_response(response: &FoundryListResponseModel) -> Self
Crée uneFoundryModelInfoà partir d’une réponse de catalogue.to_download_body(&self) -> serde_json::Value
Convertit les informations du modèle en corps JSON pour les demandes de téléchargement.
ExecutionProvider
Énumération pour les fournisseurs d’exécution pris en charge.
CPUWebGPUCUDAQNN
Méthodes
get_alias(&self) -> String
Retourne une chaîne d’alias pour le fournisseur d’exécution.
ModelRuntime
Décrit l’environnement d’exécution d’un modèle.
device_type: DeviceTypeexecution_provider: ExecutionProvider