Mise à l’échelle automatique de clusters HDInsight sur AKS
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Le dimensionnement de n’importe quel cluster pour répondre aux performances des travaux et gérer les coûts à l’avance est toujours délicat et difficile à déterminer ! L’un des avantages lucratifs de la création de data lake house sur le cloud est son élasticité, ce qui signifie utiliser la fonctionnalité de mise à l’échelle automatique pour optimiser l’utilisation des ressources disponibles. La mise à l’échelle automatique avec Kubernetes est une clé pour établir un écosystème à coût optimisé. Avec des modèles d’utilisation variés dans n’importe quelle entreprise, il peut y avoir des variations dans les charges de cluster au fil du temps, ce qui peut entraîner le sous-approvisionnement des clusters (performances fastidieuses) ou leur sur-approvisionnement (coûts inutiles en raison de ressources inactives).
La fonctionnalité de mise à l’échelle automatique proposée dans HDInsight sur AKS peut augmenter ou diminuer automatiquement le nombre de nœuds Worker dans votre cluster. La mise à l’échelle automatique utilise les métriques de cluster et la stratégie de mise à l’échelle utilisées par les clients.
Cette fonctionnalité convient parfaitement aux charges de travail stratégiques, qui peuvent avoir
- Des modèles de trafic variables ou imprévisibles et nécessitent des contrats SLA sur des performances élevées et une mise à l’échelle ou
- Une planification prédéterminée pour que les nœuds Worker requis soient disponibles pour exécuter correctement les travaux sur le cluster.
La mise à l’échelle automatique avec les clusters HDInsight sur AKS rend les clusters rentables et élastiques sur Azure.
Avec la mise à l’échelle automatique, les clients peuvent effectuer un scale-down des clusters sans affecter les charges de travail. Elle est activée avec des fonctionnalités avancées telles que la désaffectation et la période de refroidissement normales. Ces fonctionnalités permettent aux utilisateurs de faire des choix éclairés sur l’ajout et la suppression de nœuds en fonction de la charge actuelle du cluster.
Fonctionnement
Cette fonctionnalité consiste à mettre à l’échelle le nombre de nœuds dans des limites prédéfinies, en fonction de métriques de cluster ou d’une planification définie des opérations de scale-up et de scale-down. Il existe deux types de conditions pour déclencher des événements de mise à l’échelle automatique : des déclencheurs basés sur des seuils pour diverses métriques de performances de cluster (mise à l’échelle basée sur la charge) et des déclencheurs temporels (mise à l’échelle basée sur la planification).
Une mise à l’échelle basée sur la charge modifie le nombre de nœuds dans votre cluster, selon une plage que vous définissez, pour assurer une utilisation optimale de l’UC et réduire les coûts d’exécution.
Une mise à l’échelle basée sur la planification change le nombre de nœuds de votre cluster en fonction d’une planification d’opérations de scale-up et de scale-down.
Remarque
La mise à l’échelle automatique ne prend pas en charge la modification du type de référence SKU d’un cluster existant.
Compatibilité du cluster
Le tableau suivant décrit les types de cluster compatibles avec la fonctionnalité de mise à l’échelle automatique, ainsi que les éléments disponibles ou planifiés.
| Charge de travail | Basée sur la charge | Basée sur la planification |
|---|---|---|
| Flink | Prévu | Oui |
| Trino | Oui** | Oui** |
| Spark | Oui** | Oui** |
**La désaffectation normale est configurable.
Méthodes de mise à l’échelle
Mise à l’échelle basée sur la planification :
Lorsque vos travaux sont censés s’exécuter selon des planifications fixes et pour une durée prévisible ou si vous prévoyez une faible utilisation pendant des horaires spécifiques de la journée Par exemple, environnements de test et de développement après les horaires de travail, travaux de fin de journée.
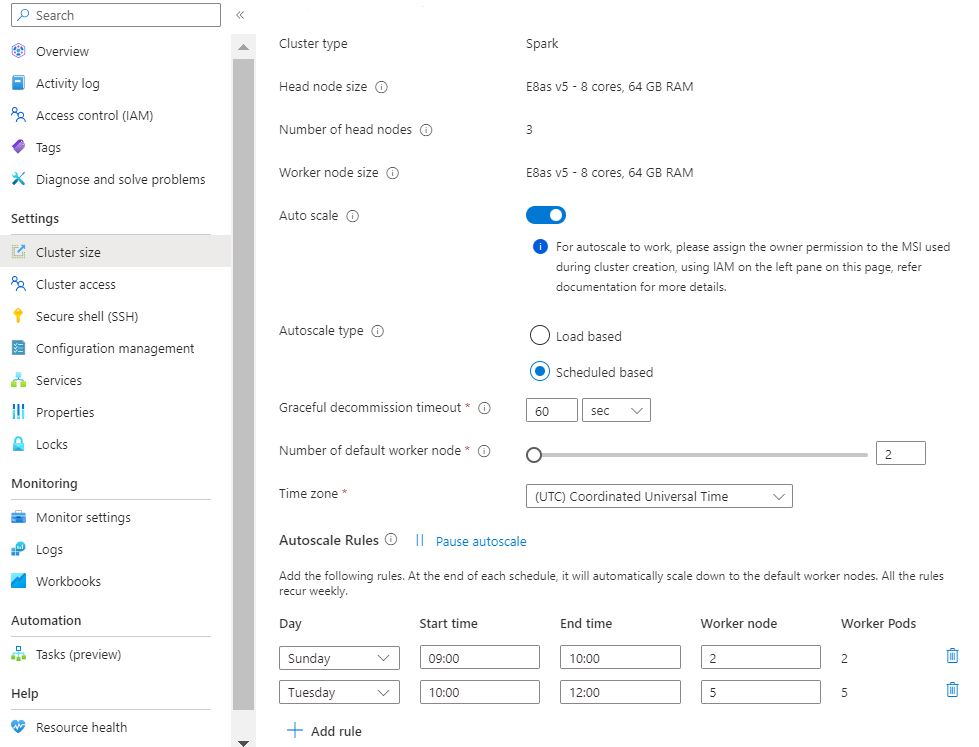
Mise à l'échelle basée sur la charge :
Lorsque les modèles de charge varient considérablement et de façon imprévisible pendant la journée, par exemple, le traitement des données de commande avec des fluctuations aléatoires dans les modèles de charge en fonction de différents facteurs.
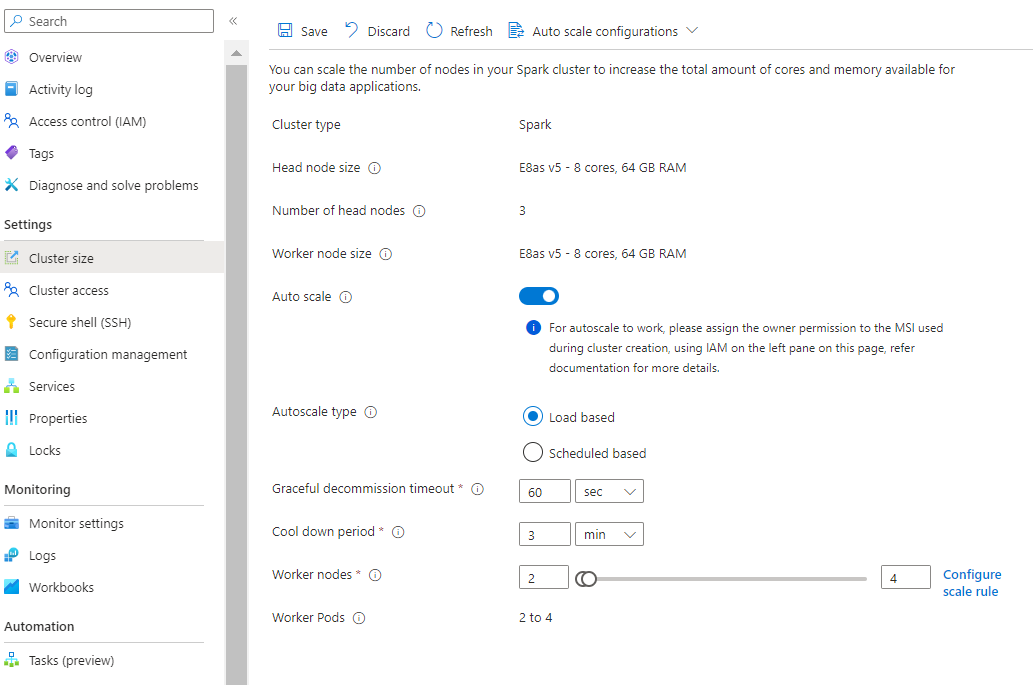
Avec la nouvelle option de configuration de règles de mise à l'échelle, vous pouvez désormais personnaliser les règles de mise à l'échelle.
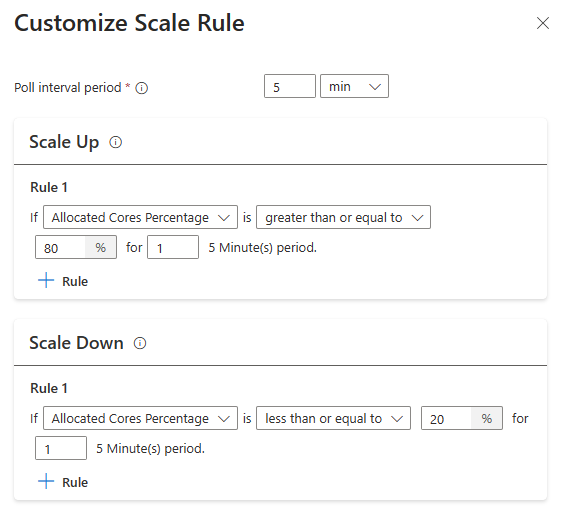
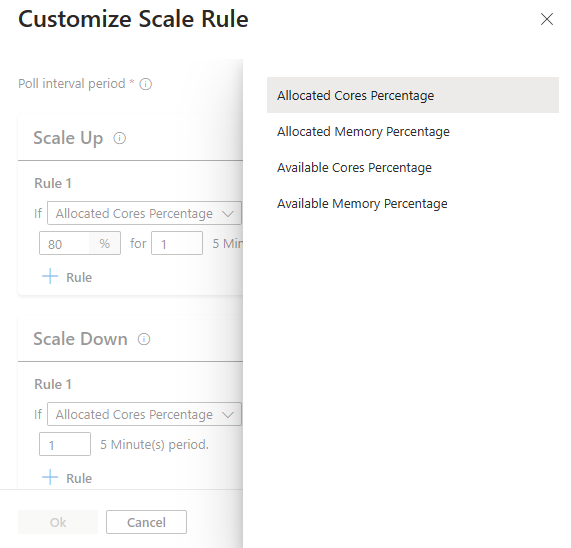
Conseil
- Les règles de scale-up sont prioritaires quand une ou plusieurs règles sont déclenchées. Même si une seule des règles de scale-up suggère le sous-approvisionnement du cluster, le cluster tente d’effectuer un scale-up. Pour que le scale-down se produise, aucune règle de scale-up ne doit être déclenchée.


Conditions de mise à l’échelle basée sur la charge
Lorsque les conditions suivantes sont détectées, la mise à l’échelle automatique émet une requête de mise à l’échelle
| Scale-up | Scale-down |
|---|---|
| Les cœurs alloués sont supérieurs à 80 % pour l’intervalle de sondage de 5 minutes (période de vérification de 1 minute) | Les cœurs alloués sont inférieurs ou égaux à 20 % pour l’intervalle de sondage de 5 minutes (période de vérification de 1 minute) |
Pour le scale-up, la mise à l’échelle automatique émet une demande de scale-up pour ajouter le nombre de nœuds requis. La montée en puissance est basée sur le nombre de nœuds Worker nécessaires pour répondre aux besoins actuels en matière d’UC et de mémoire. Cette valeur est limitée au nombre maximal de nœuds Worker définis.
Pour le scale-down, la mise à l’échelle automatique émet une demande de suppression d’un certain nombre de nœuds. Les considérations relatives au scale-down incluent le nombre de pods par nœud, les exigences actuelles en matière de processeur et de mémoire et les nœuds Worker, qui sont des candidats à la suppression en fonction de l’exécution actuelle du travail. L’opération de descente en puissance désactive tout d’abord les nœuds, puis les supprime du cluster.
Important
Le moteur de règles de mise à l’échelle automatique vide de manière proactive les anciens événements toutes les 30 minutes pour optimiser la mémoire système. Par conséquent, il existe une limite supérieure de 30 minutes sur l’intervalle de règle de mise à l’échelle. Pour garantir le déclenchement cohérent et fiable des actions de mise à l’échelle, il est impératif de définir l’intervalle de règles de mise à l’échelle sur une valeur inférieure à la limite. En respectant cette directive, vous pouvez garantir un processus de mise à l’échelle fluide et efficace tout en gérant efficacement les ressources système.
Métriques de cluster
La mise à l’échelle automatique supervise en permanence le cluster et collecte les métriques suivantes pour la mise à l’échelle automatique basée sur la charge :
Métriques de cluster disponibles à des fins de mise à l’échelle
| Métrique | Description |
|---|---|
| Pourcentage de cœurs disponibles | Le nombre total de cœurs disponibles dans le cluster par rapport au nombre total de cœurs du cluster. |
| Pourcentage de mémoire disponible | La mémoire totale (en Mo) disponible dans le cluster par rapport à la quantité totale de mémoire dans le cluster. |
| Pourcentage de cœurs alloués | Le nombre total de cœurs alloués dans le cluster par rapport au nombre total de cœurs du cluster. |
| Pourcentage de mémoire allouée | La quantité de mémoire allouée dans le cluster par rapport à la quantité totale de mémoire dans le cluster. |
Par défaut, les métriques ci-dessus sont vérifiées toutes les 300 secondes. Cette durée peut également être configurée lorsque vous personnalisez l’intervalle de sondage avec l’option de personnalisation de la mise à l’échelle automatique. La fonction de mise à l’échelle automatique prend des décisions de scale-up ou de scale-down en fonction de ces métriques.
Remarque
Par défaut, la mise à l’échelle automatique utilise la calculatrice de ressources par défaut pour YARN pour Apache Spark. La mise à l’échelle basée sur la charge est disponible pour les clusters Apache Spark.
Désaffectation normale
Les entreprises ont besoin de moyens d’effectuer une mise à l’échelle pétaoctet avec mise à l’échelle automatique et de désactiver normalement les ressources lorsqu’elles ne sont plus nécessaires. Dans ce scénario, la fonctionnalité de désaffectation normale est pratique.
La désaffectation normale permet aux travaux de se terminer même après le déclenchement de la désaffectation de nœuds Worker par la fonction de mise à l’échelle automatique. Cette fonctionnalité permet aux nœuds de rester approvisionnés jusqu’à ce que les travaux soient terminés.
Trino : les Workers ont la désaffectation normale activée par défaut. Le coordinateur permet à un worker de terminer ses tâches pendant une durée configurée avant de supprimer le worker du cluster. Vous pouvez configurer la durée à l’aide du paramètre Trino natif
shutdown.grace-periodou sur la page de configuration du service du portail Azure.Apache Spark : le scale-down peut avoir un impact/arrêter les travaux en cours d’exécution dans le cluster. Si vous activez les paramètres de désaffectation normale sur le portail Azure, il intègre la désaffectation normale des nœuds YARN et garantit que tout travail en cours sur un nœud Worker est terminé avant que le nœud soit supprimé du cluster HDInsight sur AKS.
Période de refroidissement
Pour éviter les opérations de scale-up continu, le moteur de mise à l’échelle automatique attend un intervalle configurable avant de lancer un autre ensemble d’opérations de scale-up. Par défaut, cette valeur est définie sur 180 secondes
Remarque
- Dans les règles de mise à l’échelle personnalisées, aucun déclencheur de règle ne peut avoir un intervalle de déclencheur supérieur à 30 minutes. Une fois qu’un événement de mise à l’échelle automatique se produit, la durée d’attente avant d’appliquer une autre stratégie de mise à l’échelle.
- La période de refroidissement doit être supérieure à l’intervalle de stratégie, de sorte que les métriques de cluster peuvent être réinitialisées.
Bien démarrer
Pour que la mise à l’échelle automatique fonctionne, vous devez affecter l’autorisation propriétaire ou contributeur au MSI (utilisé lors de la création du cluster) au niveau du cluster, à l’aide d’IAM dans le volet gauche.
Reportez-vous à l’illustration suivante et aux étapes répertoriées sur la façon d’ajouter une attribution de rôle
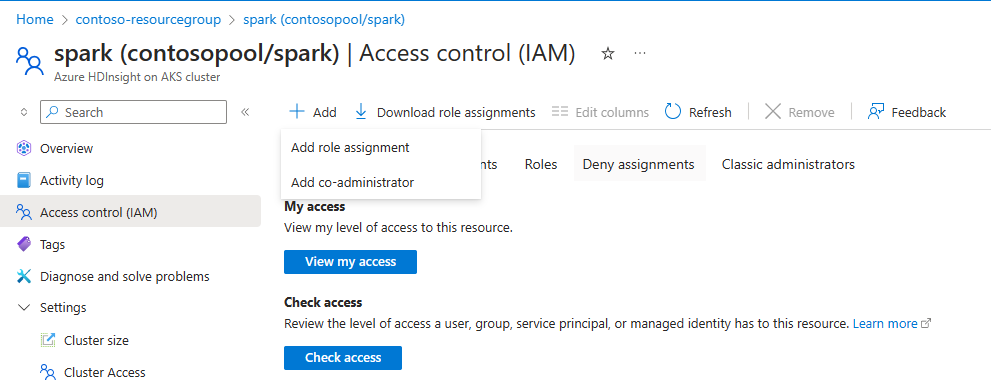
Sélectionnez ajouter une attribution de rôle,
- Type d’affectation : rôles d’administrateur privilégié
- Rôle : Propriétaire ou Contributeur
- Membres : choisissez l’identité managée et sélectionnez l’Identité managée affectée par l’utilisateur, qui a été donnée pendant la phase de création du cluster.
- Attribuez le rôle.

Créer un cluster avec une mise à l’échelle automatique basée sur la planification
Une fois votre pool de clusters créé, créez un cluster avec votre charge de travail souhaitée (sur le type de cluster) et effectuez les autres étapes dans le cadre du processus normal de création du cluster.
Sous l’onglet Configuration , activez le bouton bascule Mise à l’échelle automatique.
Sélectionnez la mise à l’échelle automatique basée sur la planification
Sélectionnez votre fuseau horaire, puis cliquez sur + Ajouter une règle
Sélectionnez les jours de la semaine pour lesquels la nouvelle condition doit s’appliquer.
Modifiez l’heure à laquelle la condition doit prendre effet, ainsi que le nombre de nœuds du cluster à mettre à l’échelle.

Remarque
- L’utilisateur doit avoir le rôle « propriétaire » ou « contributeur » sur le MSI du cluster pour que la mise à l’échelle automatique fonctionne.
- La valeur par défaut définit la taille initiale du cluster lors de sa création.
- La différence entre deux planifications est définie par défaut à 30 minutes.
- La valeur de temps suit le format de 24 heures
- Dans le cas d’une fenêtre continue de plus de 24 heures sur plusieurs jours, vous devez définir la planification de mise à l’échelle automatique sur plusieurs jours, et la mise à l’échelle automatique suppose 23:59 comme 00:00 (avec le même nombre de nœuds) couvrant deux jours de 22:00 à 23:59, 00:00 à 02:00 comme 22:00 à 02:00.
- Les planifications sont définies en temps universel coordonné (UTC), par défaut. Vous pouvez toujours mettre à jour le fuseau horaire correspondant à votre fuseau horaire local dans la liste déroulante disponible. Lorsque vous êtes sur un fuseau horaire qui observe les heures d’été, la planification ne s’ajuste pas automatiquement, vous devez gérer les mises à jour de planification en conséquence.

Créer un cluster avec une mise à l’échelle automatique basée sur la charge
Une fois votre pool de clusters créé, créez un cluster avec votre charge de travail souhaitée (sur le type de cluster) et effectuez les autres étapes dans le cadre du processus normal de création du cluster.
Sous l’onglet Configuration , activez le bouton bascule Mise à l’échelle automatique.
Sélectionner la mise à l’échelle automatique basée sur la charge
En fonction du type de charge de travail, vous avez des options permettant d’ajouter une durée de désaffectation normale, une période de refroidissement
Sélectionnez les nœuds minimum et maximum et, si nécessaire, configurez les règles de mise à l’échelle pour personnaliser la mise à l’échelle automatique en fonction de vos besoins.
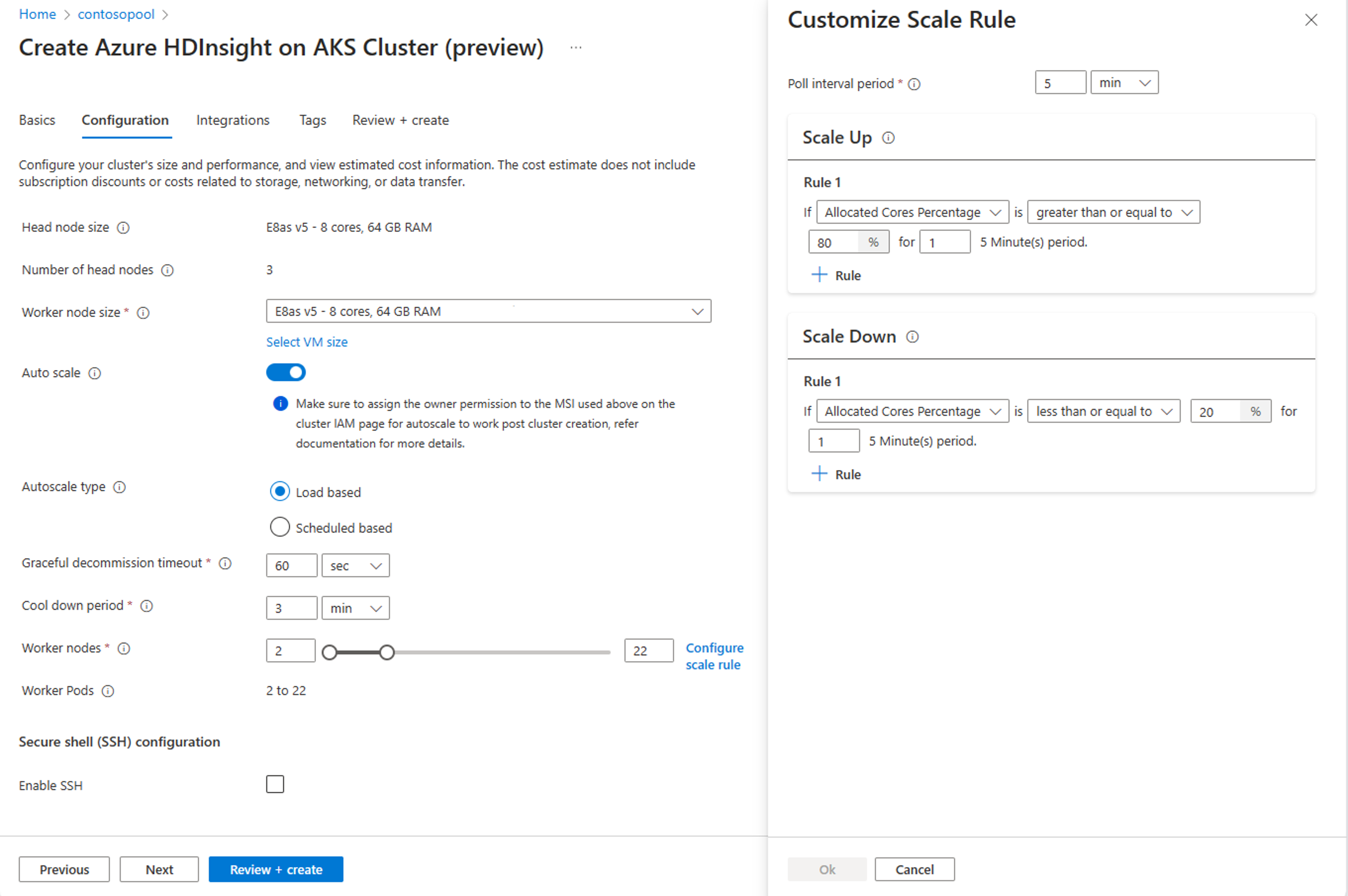
Conseil
- Votre abonnement a un quota de capacité pour chaque région. Le nombre total de cœurs de vos nœuds principaux et le nombre maximum de nœuds Worker ne peuvent pas dépasser le quota de capacité. Toutefois, ce quota est une limite logicielle ; vous pouvez toujours créer un ticket de support pour l’augmenter aisément.
- Si vous dépassez la limite de quota totale de cœurs, vous recevrez un message d’erreur indiquant
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Les règles de scale-up sont prioritaires quand une ou plusieurs règles sont déclenchées. Même si une seule des règles de scale-up suggère le sous-approvisionnement du cluster, le cluster tente d’effectuer un scale-up. Pour que le scale-down se produise, aucune règle de scale-up ne doit être déclenchée.
- En préversion publique, HDInsight sur AKS prend en charge jusqu’à 500 nœuds dans un cluster.

Création d’un cluster avec un modèle Resource Manager
Mise à l’échelle automatique basée sur la planification
Vous pouvez créer un cluster HDInsight sur AKS avec mise à l’échelle automatique basée sur la planification à l’aide d’un modèle Azure Resource Manager, en ajoutant une mise à l’échelle automatique à la section clusterProfile -> autoscaleProfile.
Le nœud de mise à l’échelle automatique contient une périodicité qui a un fuseau horaire et une planification qui décrit quand la modification a lieu. Pour obtenir un modèle Resource Manager complet, consultez l’exemple de fichier JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Conseil
- Vous devez définir des planifications non conflictuelles à l’aide de déploiements ARM pour éviter les échecs d’opération de mise à l’échelle.
Mise à l’échelle automatique basée sur la charge
Vous pouvez créer un cluster HDInsight sur AKS avec mise à l’échelle automatique basée sur la charge à l’aide d’un modèle Azure Resource Manager, en ajoutant une mise à l’échelle automatique à la section clusterProfile -> autoscaleProfile.
Le nœud de mise à l’échelle automatique contient
- un intervalle de sondage, une période de refroidissement,
- la désaffectation normale,
- les nœuds minimum et maximum,
- les règles de seuil standard,
- les métriques de mise à l’échelle qui décrivent le moment où la modification a lieu.
Pour obtenir un modèle Resource Manager complet, consultez l’exemple de fichier JSON suivant
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
En utilisant l’API REST
Pour activer ou désactiver la mise à l’échelle automatique sur un cluster en cours d’exécution à l’aide de l’API REST, envoyez une requête PATCH au point de terminaison de mise à l’échelle automatique : https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Utilisez les paramètres appropriés dans la charge utile de la requête. La charge utile JSON peut être utilisée pour activer la mise à l’échelle automatique.
- Utilisez la charge utile (autoscaleProfile : null) ou utilisez l’indicateur (activé, false) pour désactiver la mise à l’échelle automatique.
- Reportez-vous aux exemples de fichiers JSON mentionnés à l’étape ci-dessus pour référence.
Suspendre la mise à l’échelle automatique pour un cluster en cours d’exécution
Nous avons introduit la fonctionnalité de pause dans la mise à l’échelle automatique. À présent, à l’aide du portail Azure, vous pouvez suspendre la mise à l’échelle automatique sur un cluster en cours d’exécution. Le diagramme ci-dessous montre comment mettre en pause et reprendre la mise à l’échelle automatique

Vous pouvez reprendre une fois que vous souhaitez reprendre les opérations de mise à l’échelle automatique.

Conseil
Lorsque vous configurez plusieurs planifications et que vous suspendez la mise à l’échelle automatique, elle ne déclenche pas la planification suivante. Le nombre de nœuds reste identique, même si les nœuds sont dans un état désactivé.
Copier les configurations de mise à l’échelle automatique
À l’aide du portail Azure, vous pouvez désormais copier les mêmes configurations de mise à l’échelle automatique pour une même forme de cluster sur votre pool de clusters, vous pouvez utiliser cette fonctionnalité et exporter ou importer les mêmes configurations.

Supervision des activités de mise à l’échelle automatique
État du cluster
L’état du cluster répertorié sur le portail Azure peut vous aider à surveiller les activités de mise à l’échelle automatique. Tous les messages d’état de cluster susceptibles de s’afficher sont expliqués dans la liste.
| État du cluster | Description |
|---|---|
| Opération réussie | Le cluster fonctionne normalement. Toutes les activités de mise à l’échelle automatique précédentes ont été réussies. |
| Accepté | L’opération de cluster (par exemple : scale-up) est acceptée, en attendant que l’opération soit terminée. |
| Échoué | Cela signifie qu’une opération actuelle a échoué pour une raison quelconque et que le cluster n’est peut-être pas fonctionnel. |
| Annulé | L’opération actuelle est annulée. |
Pour afficher le nombre actuel de nœuds dans votre cluster, accédez au graphique Taille du cluster sur la page Vue d’ensemble de votre cluster.

Historique de l’opération
Vous pouvez afficher l’historique de Scale up/Scale down du cluster dans le cadre des métriques de celui-ci. Vous pouvez également énumérer toutes les actions de mise à l’échelle au cours de la journée, de la semaine ou d’une autre période.

Ressources supplémentaires
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour