Traiter et analyser des documents JSON avec Apache Hive dans Azure HDInsight
Découvrez comment traiter et analyser des fichiers JSON (JavaScript Object Notation) avec Apache Hive dans Azure HDInsight. Cet article utilise le document JSON suivant :
{
"StudentId": "trgfg-5454-fdfdg-4346",
"Grade": 7,
"StudentDetails": [
{
"FirstName": "Peggy",
"LastName": "Williams",
"YearJoined": 2012
}
],
"StudentClassCollection": [
{
"ClassId": "89084343",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "High",
"Score": 93,
"PerformedActivity": false
},
{
"ClassId": "78547522",
"ClassParticipation": "NotSatisfied",
"ClassParticipationRank": "None",
"Score": 74,
"PerformedActivity": false
},
{
"ClassId": "78675563",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "Low",
"Score": 83,
"PerformedActivity": true
}
]
}
Le fichier se trouve à l’emplacement suivant : wasb://processjson@hditutorialdata.blob.core.windows.net/. Pour plus d’informations sur l’utilisation du stockage Blob Azure avec HDInsight, consultez Utiliser le stockage Blob Azure compatible HDFS avec Apache Hadoop dans HDInsight. Vous pouvez copier le fichier dans le conteneur par défaut de votre cluster.
Dans cet article, vous utilisez la console Apache Hive. Pour obtenir des instructions sur l’ouverture de la console Hive, consultez Utiliser l’affichage Apache Ambari Hive avec Apache Hadoop sur HDInsight.
Notes
L’affichage Hive n’est plus disponible dans HDInsight 4.0.
Aplatir des documents JSON
Pour les méthodes répertoriées dans la section suivante, le document JSON doit se composer d’une seule ligne. Par conséquent, vous devez aplatir le document JSON pour le réduire à une chaîne. Si votre document JSON est déjà aplati, vous pouvez ignorer cette étape et passer directement à la section suivante sur l’analyse des données JSON. Pour aplatir le document JSON, exécutez le script suivant :
DROP TABLE IF EXISTS StudentsRaw;
CREATE EXTERNAL TABLE StudentsRaw (textcol string) STORED AS TEXTFILE LOCATION "wasb://processjson@hditutorialdata.blob.core.windows.net/";
DROP TABLE IF EXISTS StudentsOneLine;
CREATE EXTERNAL TABLE StudentsOneLine
(
json_body string
)
STORED AS TEXTFILE LOCATION '/json/students';
INSERT OVERWRITE TABLE StudentsOneLine
SELECT CONCAT_WS(' ',COLLECT_LIST(textcol)) AS singlelineJSON
FROM (SELECT INPUT__FILE__NAME,BLOCK__OFFSET__INSIDE__FILE, textcol FROM StudentsRaw DISTRIBUTE BY INPUT__FILE__NAME SORT BY BLOCK__OFFSET__INSIDE__FILE) x
GROUP BY INPUT__FILE__NAME;
SELECT * FROM StudentsOneLine
Le fichier JSON brut se trouve à l’emplacement suivant : wasb://processjson@hditutorialdata.blob.core.windows.net/. La table Hive StudentsRaw pointe vers le document JSON brut non aplati.
La table Hive StudentsOneLine stocke les données dans le système de fichiers HDInsight par défaut sous le chemin d’accès /json/students/ .
L’instruction INSERT remplit la table StudentOneLine avec les données JSON aplaties.
L’instruction SELECT retourne une seule ligne.
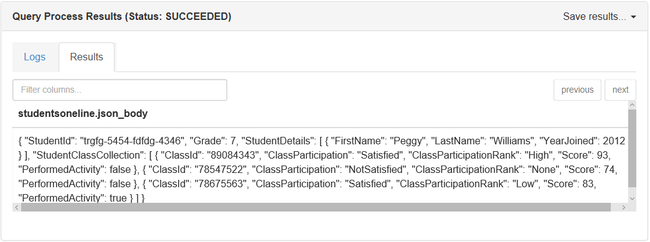
Voici la sortie de l’instruction SELECT :
Analyser les documents JSON dans Hive
Hive propose trois mécanismes différents pour exécuter des requêtes sur des documents JSON, mais vous pouvez aussi écrire les vôtres :
- Utiliser la fonction UDF get_json_object.
- Utiliser la fonction UDF json_tuple.
- Utiliser le sérialiseur/désérialiseur personnalisé (SerDe).
- Vous pouvez écrire votre propre fonction définie par l’utilisateur (UDF) avec Python ou d’autres langages. Pour savoir plus en détail comment exécuter votre propre code Python avec Hive, voir Fonction définie par l’utilisateur (UDF) Python avec Apache Hive et Apache Pig.
Utiliser la fonction définie par l’utilisateur get_json_object
Hive intègre une fonction UDF appelée get_json_object qui interroge un document JSON pendant l’exécution. Cette méthode accepte deux arguments : le nom de la table et le nom de la méthode. Le nom de la méthode contient le document JSON aplati et le champ JSON qui doit être analysé. Prenons un exemple pour examiner de plus près cette fonction UDF.
La requête suivante retourne le prénom et le nom de chaque élève :
SELECT
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.FirstName'),
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.LastName')
FROM StudentsOneLine;
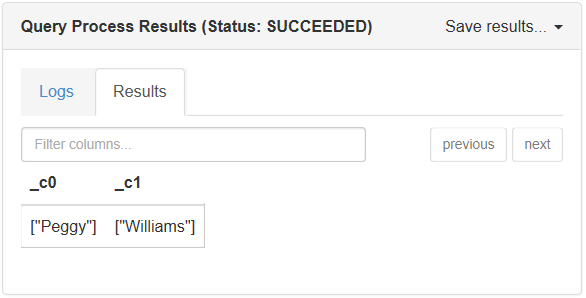
Voici la sortie lorsque vous exécutez cette requête dans la fenêtre de la console :
La fonction UDF get_json_object présente des limitations :
- Étant donné que chaque champ de la requête implique une nouvelle analyse de la requête, cela affecte les performances.
- GET_JSON_OBJECT() retourne une représentation sous forme de chaîne d’un tableau. Pour convertir ce tableau en un tableau Hive, vous devez utiliser des expressions régulières pour remplacer les crochets « [ » et « ] », puis fractionner pour obtenir le tableau.
Cette conversion est la raison pour laquelle le wiki Hive recommande d’utiliser json_tuple.
Utiliser la fonction UDF json_tuple
L’autre fonction UDF fournie par Hive, intitulée json_tuple, est plus performante que get_json_object. Cette méthode prend un ensemble de clés et une chaîne JSON. Elle retourne ensuite un tuple de valeurs. La requête suivante retourne l’ID et la classe de l’étudiant du document JSON :
SELECT q1.StudentId, q1.Grade
FROM StudentsOneLine jt
LATERAL VIEW JSON_TUPLE(jt.json_body, 'StudentId', 'Grade') q1
AS StudentId, Grade;
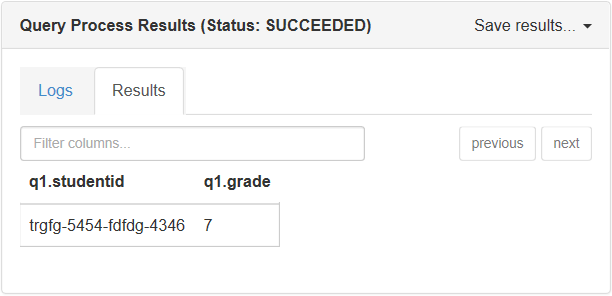
Sortie de ce script dans la console Hive :
La fonction UDF json_tuple utilise la syntaxe lateral view dans Hive, ce qui permet à json_tuple de créer une table virtuelle en appliquant la fonction UDT à chaque ligne de la table d’origine. Les documents JSON complexes deviennent trop lourds en raison de l’utilisation répétée de LATERAL VIEW. De plus, JSON_TUPLE ne gère pas les documents JSON imbriqués.
Utiliser un SerDe personnalisé
SerDe constitue le meilleur moyen d’analyser des documents JSON imbriqués. Il vous permet de définir le schéma JSON qui vous servira à analyser les documents. Pour obtenir des instructions, consultez Guide pratique pour utiliser un SerDe JSON personnalisé avec Microsoft Azure HDInsight.
Résumé
Le type d’opérateur JSON que vous choisissez dans Hive dépend de votre scénario. Avec un document JSON simple et un champ à rechercher, choisissez la fonction UDF Hive get_json_object. Si la recherche porte sur plusieurs clés, vous pouvez utiliser json_tuple. Pour les documents imbriqués, utilisez JSON SerDe.
Étapes suivantes
Articles associés :