Démarrage rapide : Exécuter des requêtes Apache Hive dans Azure HDInsight avec Apache Zeppelin
Dans ce guide de démarrage rapide, vous allez apprendre à utiliser Apache Zeppelin pour exécuter des requêtes Apache Hive dans Azure HDInsight. Les clusters Interactive Query HDInsight incluent les blocs-notes Apache Zeppelin que vous pouvez utiliser pour exécuter des requêtes Hive interactives.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Un cluster HDInsight Interactive Query. Consultez Créer un cluster pour créer un cluster HDInsight. Vous devez choisir Interactive Query comme type de cluster.
Créer une note Apache Zeppelin
Remplacez
CLUSTERNAMEpar le nom de votre cluster dans l’URL suivantehttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Entrez ensuite l’URL dans un navigateur web.Entrez le nom d’utilisateur et le mot de passe de connexion pour votre cluster. Dans la page Zeppelin, choisissez d’ouvrir une note existante ou d’en créer une. HiveSample contient plusieurs exemples de requêtes Hive.
Sélectionnez Créer une note.
Dans la boîte de dialogue Créer une note, entrez ou sélectionnez les valeurs suivantes :
- Note Name : entrez un nom pour la note.
- Default interpreter : sélectionnez jdbc dans la liste déroulante.
Sélectionnez Créer une note.
Entrez la requête Hive suivante dans la section de code, puis appuyez sur Maj+Entrée :
%jdbc(hive) show tables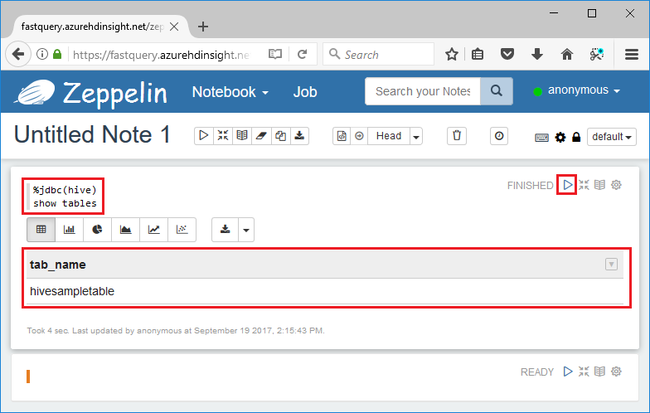
L’instruction %jdbc(hive) dans la première ligne indique au notebook d’utiliser l’interpréteur Hive JDBC.
La requête retourne une table Hive appelée hivesampletable.
Vous pouvez exécuter les deux autres requêtes Hive suivantes sur la table hivesampletable :
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Les résultats de la requête sont retournés plus rapidement qu’avec une requête Hive standard.
Exemples supplémentaires
Créez une table. Exécutez le code ci-dessous dans le notebook Zeppelin :
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Chargez des données dans la nouvelle table. Exécutez le code ci-dessous dans le notebook Zeppelin :
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Insérez un enregistrement unique. Exécutez le code ci-dessous dans le notebook Zeppelin :
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Passez en revue le manuel du langage Hive pour découvrir d’autres syntaxes.
Nettoyer les ressources
Après avoir suivi ce guide de démarrage rapide, vous souhaiterez peut-être supprimer le cluster. Avec HDInsight, vos données sont stockées dans le stockage Azure. Vous pouvez ainsi supprimer un cluster en toute sécurité s’il n’est pas en cours d’utilisation. Vous devez également payer pour un cluster HDInsight, même quand vous ne l’utilisez pas. Étant donné que les frais pour le cluster sont bien plus élevés que les frais de stockage, mieux vaut supprimer les clusters quand ils ne sont pas utilisés.
Pour supprimer un cluster, consultez Supprimer un cluster HDInsight à l’aide de votre navigateur, de PowerShell ou d’Azure CLI.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez appris à utiliser Apache Zeppelin pour exécuter des requêtes Apache Hive dans Azure HDInsight. Pour en savoir plus sur les requêtes Hive, consultez l’article suivant qui explique comment exécuter des requêtes avec Visual Studio.