Cet article fournit des réponses à certaines questions fréquemment posées sur l’exécution d’Azure HDInsight.
Création et suppression des clusters HDInsight
Comment provisionner un cluster HDInsight ?
Pour connaître les types de clusters HDInsight et les méthodes d’approvisionnement, consultez Configurer des clusters dans HDInsight avec Apache Hadoop, Apache Spark, Apache Kafka, etc.
Comment supprimer un cluster HDInsight existant ?
Pour plus d’informations sur la suppression d’un cluster non utilisé, voir Supprimer un cluster HDInsight.
Essayez de laisser au moins 30 à 60 minutes entre les opérations de création et de suppression. Sinon, l’opération peut échouer et retourner le message d’erreur suivant :
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
Comment sélectionner un nombre de cœurs ou de nœuds adapté à ma charge de travail ?
Le nombre de cœurs nécessaire, ainsi que d’autres options de configuration, dépendent de différents facteurs.
Pour plus d’informations, consultez Planification de la capacité pour les clusters HDInsight.
Quels sont les différents types de nœuds d’un cluster HDInsight ?
Quelles sont les meilleures pratiques pour créer de grands clusters HDInsight ?
- Nous vous recommandons de configurer des clusters HDInsight avec une base de données Ambari personnalisée pour améliorer la scalabilité du cluster.
- Utilisez Azure Data Lake Storage Gen2 pour créer des clusters HDInsight afin de tirer parti de la bande passante plus élevée et d’autres caractéristiques de performances de Azure Data Lake Storage Gen2.
- Les nœuds principaux doivent être suffisamment grands pour prendre en charge plusieurs services maîtres s’exécutant sur ces nœuds.
- Certaines charges de travail spécifiques, telles que Interactive Query, nécessitent également des nœuds Zookeeper plus volumineux. Envisagez des machines virtuelles d’au moins 8 cœurs.
- Dans le cas de Hive et Spark, utilisez Metastore Hive externe.
Composants individuels
Puis-je installer des composants supplémentaires dans un cluster ?
Oui. Pour installer des composants supplémentaires ou personnaliser la configuration du cluster, utilisez les ressources suivantes :
Scripts pendant ou après la création. Les scripts sont appelés à l’aide d’une action de script. Une action de script est une option de configuration que vous pouvez utiliser à partir du Portail Azure, de cmdlets HDInsight Windows PowerShell ou du Kit de développement logiciel (SDK) HDInsight .NET. Cette option de configuration peut être utilisée dans le portail Azure, dans des applets de commande HDInsight Windows PowerShell ou dans le SDK HDInsight .NET.
Plateforme d’application HDInsight pour installer des applications.
Pour obtenir la liste des composants pris en charge, consultez Quels sont les composants et versions d'Apache Hadoop disponibles avec HDInsight ?
Est-il possible de mettre à niveau chacun des composants qui sont préinstallés sur le cluster ?
Si vous mettez à niveau des composants intégrés ou des applications qui sont préinstallées sur votre cluster, la configuration obtenue ne sera pas prise en charge par Microsoft. Ces configurations système n’ont pas été testées par Microsoft. Essayez d’utiliser une autre version du cluster HDInsight qui a peut-être déjà le composant mis à niveau préinstallé.
Par exemple, la mise à niveau de Hive en tant que composant n’est pas prise en charge. HDInsight est un service managé, et de nombreux services ont été testés et intégrés au serveur Ambari. Le fait de mettre à niveau Hive séparément entraîne la modification des binaires indexés des autres composants, ce qui entraîne des problèmes d’intégration des composants dans votre cluster.
Spark et Kafka peuvent-ils s’exécuter sur le même cluster HDInsight ?
Non, il n’est pas possible d’exécuter Apache Kafka et Apache Spark sur un même cluster HDInsight. Pour éviter les conflits de ressources, créez des clusters séparés pour Kafka et Spark.
Comment modifier le fuseau horaire dans Ambari ?
Ouvrez l’interface utilisateur web d’Ambari à l’adresse
https://CLUSTERNAME.azurehdinsight.net, où CLUSTERNAME correspond au nom de votre cluster.En haut à droite, sélectionnez Administrateur | Paramètres.
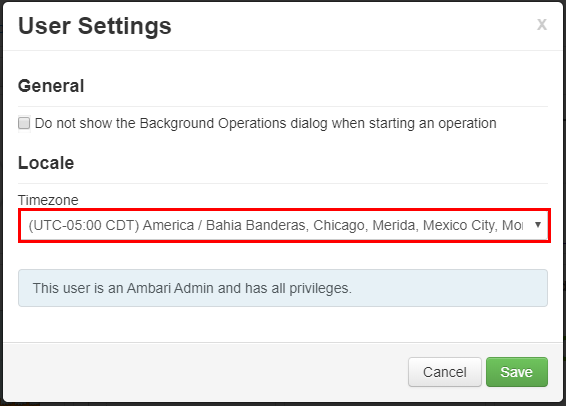
Dans la fenêtre Paramètres utilisateur, sélectionnez le nouveau fuseau horaire dans la liste déroulante Fuseau horaire, puis sélectionnez Enregistrer.
Metastore
Comment effectuer la migration d’un metastore existant vers Azure SQL Database ?
Pour effectuer la migration de SQL Server vers Azure SQL Database, consultez le Tutoriel : Migrer SQL Server vers une base de données unique ou mise en pool dans Azure SQL Database hors connexion à l’aide de DMS.
Le metastore Hive est-il supprimé en même temps que le cluster ?
Cela dépend du type de metastore pour lequel votre cluster est configuré.
Pour un metastore par défaut : Le metastore par défaut fait partie du cycle de vie du cluster. Lorsque vous supprimez un cluster, le metastore et les métadonnées correspondants sont également supprimés.
Pour un metastore personnalisé : Le cycle de vie du metastore n’est pas lié au cycle de vie d’un cluster. Ainsi, vous pouvez créer et supprimer des clusters sans perdre de métadonnées. Les métadonnées telles que vos schémas Hive sont conservées, même après avoir supprimé et recréé le cluster HDInsight.
Pour plus d’informations, consultez Utiliser des magasins de métadonnées externes dans Azure HDInsight.
La migration d’un metastore Hive entraîne-t-elle la migration des stratégies par défaut de la base de données Ranger ?
Non, la définition de stratégie se trouve dans la base de données Ranger. La migration de celle-ci a donc pour effet de migrer sa stratégie.
Est-il possible d’effectuer la migration d’un metastore Hive entre un cluster Pack Sécurité Entreprise (ESP) et un cluster non-ESP, et inversement ?
Oui, vous pouvez procéder à la migration d’un metastore Hive entre un cluster ESP et un cluster non ESP.
Comment estimer la taille d’une base de données metastore Hive ?
Un metastore Hive est utilisé pour stocker les métadonnées des sources de données utilisées par le serveur Hive. La taille requise dépend en partie du nombre et de la complexité de vos sources de données Hive. Ces éléments ne peuvent pas être estimés à l’avance. Comme indiqué dans Instructions pour le metastore Hive, vous pouvez commencer avec un niveau S2. Le niveau fournit 50 DTU et 250 Go de stockage, et si vous constatez un goulet d’étranglement, effectuez un scale-up de la base de données.
En dehors d’Azure SQL Database, existe-t-il d’autres bases de données qui peuvent être utilisées en tant que metastore externe ?
Non, Microsoft permet seulement d’utiliser Azure SQL Database comme un metastore personnalisé externe.
Peut-on partager un metastore entre plusieurs clusters ?
Oui, vous pouvez partager un metastore personnalisé entre plusieurs clusters, à condition que ceux-ci utilisent la même version de HDInsight.
Connectivité et réseaux virtuels
Quelles sont les conséquences du blocage des ports 22 et 23 sur mon réseau ?
Si vous bloquez les ports 22 et 23, vous ne disposerez pas d’un accès SSH au cluster. Ces ports ne sont pas utilisés par le service HDInsight.
Pour plus d’informations, consultez les documents suivants :
Puis-je déployer une machine virtuelle supplémentaire au sein d’un même sous-réseau en tant que cluster HDInsight ?
Oui, vous pouvez déployer une machine virtuelle supplémentaire au sein d’un même sous-réseau en tant que cluster HDInsight. Les configurations suivantes sont possibles :
Nœuds de périphérie : Vous pouvez ajouter un autre nœud de périphérie au cluster, comme décrit dans Utiliser des nœuds de périphérie vides sur des clusters Apache Hadoop dans HDInsight.
Nœuds autonomes : Vous pouvez ajouter une machine virtuelle autonome au même sous-réseau et accéder au cluster à partir de cette machine virtuelle à l’aide du point de terminaison privé
https://<CLUSTERNAME>-int.azurehdinsight.net. Pour plus d’informations, consultez Contrôler le trafic réseau.
Dois-je stocker les données sur le disque local d’un nœud de périphérie ?
Non, stocker les données sur un disque local n’est pas une bonne pratique. En cas de défaillance du nœud, toutes les données stockées localement seraient perdues. Nous vous conseillons de stocker les données dans Azure Data Lake Storage Gen2 ou le Stockage Blob Azure, ou dans un partage Azure Files que vous montez à cet usage.
Puis-je ajouter un cluster HDInsight existant à un autre réseau virtuel ?
Non, c’est impossible. Le réseau virtuel doit être spécifié au moment du provisionnement. Si aucun réseau virtuel n’est spécifié lors de l’approvisionnement, le déploiement crée un réseau interne inaccessible de l’extérieur. Pour plus d’informations, consultez Ajouter HDInsight à un réseau virtuel existant.
Sécurité et certificats
Quelles sont les recommandations concernant la protection contre les programmes malveillants des clusters Azure HDInsight ?
Pour plus d’informations sur la protection contre les programmes malveillants, consultez Microsoft Antimalware pour les services cloud Azure et les machines virtuelles.
Comment créer un keytab pour un cluster ESP HDInsight ?
Créez un keytab Kerberos pour le nom d’utilisateur de votre domaine. Vous pourrez utiliser ce keytab ultérieurement pour vous authentifier auprès de clusters distants joints à un domaine sans entrer de mot de passe. Le nom de domaine est en majuscules :
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Quand le salage est-il nécessaire pour le chiffrement AES256 pendant la création du keytab ?
Si vos TenantName et DomainName sont différents (par exemple TenantName : bob@CONTOSO.ONMICROSOFT.COM et DomainName : bob@CONTOSOMicrosoft.ONMICROSOFT.COM), vous devez ajouter une valeur SALT en utilisant l’option -s.
Comment faire pour déterminer la valeur SALT adéquate ?
- Utilisez une connexion Kerberos interactive pour déterminer la valeur salt adéquate pour le keytab. La connexion Kerberos interactive utilise par défaut le chiffrement le plus élevé. Le suivi doit être activé pour observer la valeur salt. Ci-dessous se trouve un exemple de connexion Kerberos :
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Examinez la sortie pour ligne salt « ....... ».
- Utilisez cette valeur salt pendant la création du keytab.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Puis-je utiliser un locataire Microsoft Entra existant pour créer un cluster HDInsight doté de l'ESP ?
Activez Microsoft Entra Domain Services avant de pouvoir créer un cluster HDInsight avec ESP. Hadoop open source s’appuie sur Kerberos pour l’authentification (et non sur OAuth).
Pour joindre des machines virtuelles à un domaine, vous devez disposer d’un contrôleur de domaine. Microsoft Entra Domain Services est le contrôleur de domaine géré et est considéré comme une extension de Microsoft Entra ID. Microsoft Entra Domain Services fournit toutes les exigences Kerberos pour créer un cluster Hadoop sécurisé de manière gérée. HDInsight en tant que service géré s'intègre aux services de domaine Microsoft Entra pour assurer la sécurité.
Puis-je utiliser un certificat auto-signé dans une configuration LDAP sécurisée de Microsoft Entra Domain Services et provisionner un cluster ESP ?
Il est recommandé d’utiliser un certificat émis par une autorité de certification. Toutefois, l’utilisation d’un certificat auto-signé est également prise en charge sur ESP. Pour en savoir plus, consultez :
Puis-je installer un serveur d'accès aux données (DAS) comme un cluster ESP ?
Non, DAS n’est pas pris en charge sur les clusters ESP.
Comment tirer (pull) les activités de connexion affichées dans Ranger ?
Pour les besoins d’audit, Microsoft recommande d’activer les journaux Azure Monitor, comme décrit dans Utiliser les journaux Azure Monitor pour superviser les clusters HDInsight.
Puis-je désactiver Clamscan sur un cluster ?
Clamscan est le logiciel antivirus qui s’exécute sur le cluster HDInsight. Il est utilisé par la sécurité Azure (azsecd) pour protéger vos clusters des attaques de virus. Microsoft recommande vivement aux utilisateurs de ne pas apporter de modifications à la configuration Clamscan par défaut.
Ce processus n’interfère pas avec les cycles des autres processus ni ne les supprime. Il passe toujours à un autre processus. Les pics d’utilisation de l’UC de Clamscan ne doivent être visibles que lorsque le système est inactif.
Dans les scénarios où vous devez contrôler la planification, vous pouvez utiliser les étapes suivantes :
Désactivez l’exécution automatique à l’aide de la commande suivante :
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restartAjoutez un travail Cron qui exécute la commande suivante en tant que racine :
/usr/local/bin/azsecd manual -s clamav
Pour plus d’informations sur la configuration et l’exécution d’un travail Cron, consultez How do I set up a Cron job ?.
Pourquoi LLAP est-il disponible sur les clusters ESP Spark ?
LLAP est activé pour des raisons de sécurité (Apache Ranger) et non de performances. Utilisez des machines virtuelles dotées de nœuds de plus grande taille pour prendre en charge l’utilisation des ressources de LLAP (par exemple, minimum D13V2).
Comment puis-je ajouter des groupes Microsoft Entra supplémentaires après avoir créé un cluster ESP ?
Il existe deux moyens de parvenir à cet objectif : 1- Vous pouvez recréer le cluster en ajoutant le groupe supplémentaire. Si vous utilisez la synchronisation étendue dans Microsoft Entra Domain Services, assurez-vous que le groupe B est inclus dans la synchronisation étendue.
2- Ajoutez le groupe en tant que sous-groupe imbriqué du groupe précédent utilisé pour créer le cluster ESP. Par exemple, si vous avez créé un cluster ESP avec un groupe A, vous pouvez ultérieurement ajouter un groupe B en tant que sous-groupe imbriqué de A. Après environ une heure, il sera synchronisé et disponible automatiquement dans le cluster.
Stockage
Puis-je ajouter Azure Data Lake Storage Gen2 à un cluster HDInsight existant en tant que compte de stockage supplémentaire ?
Non, il n’est actuellement pas possible d’ajouter un compte de stockage Azure Data Lake Storage Gen2 à un cluster dont le stockage principal est un stockage blob. Pour plus d’informations, voir Comparer les options de stockage.
Comment trouver le principal de service qui est lié à un compte de stockage Data Lake ?
Vos paramètres figurent dans Accès à Data Lake Storage Gen1 sous les propriétés de votre cluster dans le portail Azure. Pour plus d’informations, voir Vérifier la configuration du cluster.
Comment calculer l’utilisation des comptes de stockage et des conteneurs d’objets blob pour mes clusters HDInsight ?
Effectuez l’une des actions suivantes :
Recherchez la taille du dossier /user/hive/.Trash/ sur le cluster HDInsight à l’aide de la ligne de commande suivante :
hdfs dfs -du -h /user/hive/.Trash/
Comment configurer l’audit de mon compte de stockage Blob ?
Pour auditer les comptes de stockage blob, configurez la surveillance en suivant la procédure décrite dans Surveiller un compte de stockage dans le portail Azure. Un journal HDFS-audit fournit uniquement des informations d’audit pour le système de fichiers HDFS local (hdfs://mycluster). Il n’inclut pas les opérations qui sont effectuées sur le stockage distant.
Comment transférer des fichiers entre un conteneur d’objets blob et un nœud principal HDInsight ?
Exécutez un script similaire au script shell suivant sur votre nœud principal :
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Notes
Le fichier filenames.txt contient le chemin absolu des fichiers du conteneurs d’objets blob.
Existe-t-il des plug-ins Ranger pour le stockage ?
Actuellement, il n’existe pas de plug-in Ranger pour le stockage blob et Azure Data Lake Storage Gen1 ou Gen2. Pour les clusters ESP, vous devez utiliser Azure Data Lake Storage. Vous pouvez au moins définir des autorisations affinées manuellement au niveau du système de fichiers à l’aide des outils HDFS. De plus, lors de l'utilisation d'Azure Data Lake Storage, les clusters ESP effectueront une partie du contrôle d'accès au système de fichiers à l'aide de Microsoft Entra ID au niveau du cluster.
Vous pouvez affecter des stratégies d’accès aux données aux groupes de sécurité de vos utilisateurs à l’aide de l’Explorateur Stockage Azure. Pour en savoir plus, consultez :
- Comment définir les autorisations permettant aux utilisateurs de Microsoft Entra d'interroger des données dans Data Lake Storage Gen2 à l'aide de Hive ou d'autres services ?
- Définir des autorisations au niveau de fichiers et de répertoires à l'aide de l'Explorateur Stockage Azure avec Azure Data Lake Storage Gen2
Puis-je augmenter le stockage HDFS sur un cluster sans augmenter la taille du disque des nœuds worker ?
Non. Vous ne pouvez pas augmenter la taille du disque d’un nœud Worker. La seule façon d’augmenter la taille du disque consiste à supprimer le cluster, puis à le recréer avec des machines virtuelles Worker plus volumineuses. N’utilisez pas HDFS pour stocker vos données HDInsight car celles-ci seront supprimées si vous supprimez votre cluster. Au lieu de cela, stockez vos données dans Azure. Une montée en puissance du cluster peut également augmenter la capacité de votre cluster HDInsight.
Nœuds de périmètre
Puis-je ajouter un nœud de périphérie après la création du cluster ?
Comment me connecter à un nœud de périphérie ?
Après avoir créé un nœud de périphérie, vous pouvez vous y connecter en utilisant SSH sur le port 22. Le nom du nœud de périphérie se trouve sur le portail du cluster. Les noms se terminent généralement par -ed.
Pourquoi les scripts persistants ne s’exécutent-ils pas automatiquement sur les nœuds de périphérie nouvellement créés ?
Vous pouvez utiliser des scripts persistants pour personnaliser les nouveaux nœuds Worker ajoutés au cluster lors d’opérations de mise à l’échelle. Les scripts persistants ne s’appliquent pas aux nœuds de périphérie.
API REST
Quels sont les appels d’API REST qui permettent de tirer (pull) l’affichage des requêtes Tez à partir du cluster ?
Vous pouvez utiliser les points de terminaison REST suivants pour extraire les informations nécessaires au format JSON. Utilisez des en-têtes d’authentification de base pour exécuter les demandes.
Tez Query View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/Tez Dag View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
Comment récupérer les détails de configuration du cluster HDI à l'aide d'un utilisateur Microsoft Entra ?
Pour négocier des jetons d'authentification appropriés avec votre utilisateur Microsoft Entra, passez par la passerelle en utilisant le format suivant :
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/versions_stack/1/versions_référentiel/1
Comment faire pour superviser les performances de YARN à l’aide d’Ambari RESTful ?
Si vous appelez la commande Curl dans le même réseau virtuel ou dans un réseau virtuel appairé, la commande est la suivante :
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Si vous appelez la commande à partir de l’extérieur du réseau virtuel ou d’un réseau virtuel non appairé, le format de la commande est le suivant :
Pour un cluster non ESP :
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuPour un cluster ESP :
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Remarque
Curl vous invite à entrer un mot de passe. Vous devez entrer un mot de passe valide pour le nom d’utilisateur de connexion du cluster.
Facturation
Combien coûte le déploiement d’un cluster HDInsight ?
Pour plus d’informations sur les tarifs et les questions fréquentes relatives à la facturation, consultez la page Tarifs Azure HDInsight.
Quand la facturation HDInsight démarre-t-elle et s’arrête-t-elle ?
La facturation du cluster HDInsight démarre à la création du cluster et s’arrête à sa suppression. La facturation est calculée à la minute.
Comment annuler mon abonnement ?
Pour plus d’informations sur l’annulation des abonnements, consultez Annulation de votre abonnement Azure.
Pour les abonnements avec paiement à l’utilisation, que se passe-t-il après l’annulation de mon abonnement ?
Pour plus d’informations sur votre abonnement après son annulation, consultez What happens after I cancel my subscription?.
Hive
Pourquoi la version 1.2.1000 de Hive s’affiche-t-elle au lieu de la version 2.1 dans l’interface utilisateur Ambari, alors que j’exécute un cluster HDInsight 3.6 ?
Même si seule la version 1.2 s’affiche dans l’interface utilisateur Ambari, HDInsight 3.6 contient bien Hive 1.2 et Hive 2.1.
Autres questions fréquentes
Quelles sont les capacités de traitement du flux en temps réel qui sont proposées par HDInsight ?
Pour plus d’informations sur les capacités d’intégration du traitement de flux, consultez Sélectionner une technologie de traitement de flux dans Azure.
Existe-t-il un moyen de tuer dynamiquement le nœud principal du cluster lorsque le cluster est inactif pendant une période donnée ?
Vous ne pouvez pas effectuer cette action avec des clusters HDInsight. Dans ce cas, vous pouvez utiliser Azure Data Factory.
Quelles offres de conformité HDInsight inclut-elle ?
Si vous voulez en savoir plus sur la conformité, visitez le Centre de gestion de la confidentialité de Microsoft.