Services de haute disponibilité pris en charge par Azure HDInsight
Afin de vous fournir des niveaux optimaux de disponibilité pour vos composants analytiques, HDInsight a été développé avec une architecture unique pour assurer une haute disponibilité (HA) des services critiques. Microsoft a développé certains composants de cette architecture pour assurer un basculement automatique. Les autres composants sont des composants Apache standard déployés pour prendre en charge des services spécifiques. Cet article décrit en détail l’architecture du modèle de service de haute disponibilité dans HDInsight, la façon dont HDInsight prend en charge le basculement pour les services haute disponibilité et les meilleures pratiques pour effectuer une reprise à partir d’autres interruptions de service.
Notes
Cet article contient des références au terme esclave, un terme que Microsoft n’utilise plus. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Infrastructure de haute disponibilité
HDInsight fournit une infrastructure personnalisée pour garantir que quatre services principaux offrent une haute disponibilité avec des fonctionnalités de basculement automatique :
- Serveur Apache Ambari
- Serveur de chronologie de l'application pour Apache YARN
- Serveur d’historique des travaux pour Hadoop MapReduce
- Apache Livy
Cette infrastructure est constituée de nombreux services et composants logiciels, dont certains sont conçus par Microsoft. Les composants suivants sont spécifiques à la plateforme HDInsight :
- Basculer le contrôleur esclave
- Basculer le contrôleur maître
- Service de haute disponibilité esclave
- Service de haute disponibilité maître
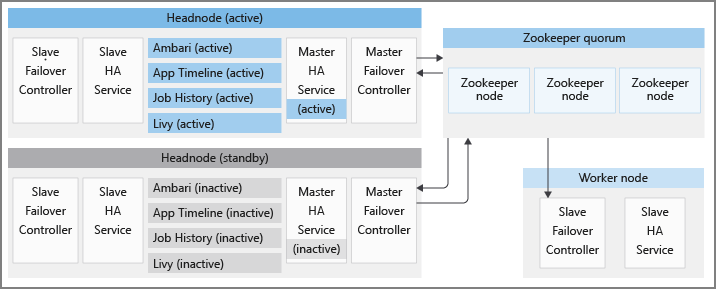
Il existe également d’autres services de haute disponibilité, qui sont pris en charge par les composants open source de fiabilité Apache. Ces composants sont également présents sur les clusters HDInsight :
- Système de fichiers Hadoop (HDFS) NameNode
- Interface utilisateur de ResourceManager YARN
- HBase Master
Les sections suivantes fournissent plus de détails sur la façon dont ces services fonctionnent ensemble.
Services de haute disponibilité HDInsight
Microsoft assure la prise en charge des quatre services Apache dans le tableau suivant des clusters HDInsight. Pour les distinguer des services de haute disponibilité pris en charge par les composants d’Apache, ceux-ci sont appelés services HDInsight HA.
| Service | Nœuds de cluster | Types de cluster | Objectif |
|---|---|---|---|
| Serveur Apache Ambari | Nœud principal actif | Tous | Supervise et gère le cluster. |
| Serveur de chronologie de l'application pour Apache YARN | Nœud principal actif | Tout sauf Kafka | Gère les informations de débogage relatives aux travaux YARN en cours d’exécution sur le cluster. |
| Serveur d’historique des travaux pour Hadoop MapReduce | Nœud principal actif | Tout sauf Kafka | Gère les données de débogage pour les tâches MapReduce. |
| Apache Livy | Nœud principal actif | Spark | Permet une interaction facile avec un cluster Spark sur une interface REST |
Notes
Les clusters HDInsight Pack Sécurité Entreprise (ESP) fournissent actuellement uniquement la haute disponibilité du serveur Ambari. Le serveur de chronologie de l’application, le serveur d’historique des travaux et Livy sont tous en cours d’exécution uniquement sur headnode0 et ne basculent pas vers headnode1 lorsque Ambari bascule. La base de données de chronologie de l’application se trouve également sur headnode0 et non sur le serveur SQL Ambari.
Architecture
Chaque cluster HDInsight a deux nœuds principaux en mode actif et en mode veille, respectivement. Les services de haute disponibilité HDInsight s’exécutent uniquement sur nœuds principaux. Ces services doivent toujours s’exécuter sur le nœud principal actif, puis être arrêtés et mis en mode maintenance sur le nœud principal de secours.
Pour conserver les états corrects des services de haute disponibilité et fournir un basculement rapide, HDInsight utilise Apache ZooKeeper, qui est un service de coordination pour les applications distribuées afin d’effectuer l’élection du nœud principal actif. HDInsight provisionne également quelques processus Java en arrière-plan, qui coordonnent la procédure de basculement pour les services haute disponibilité HDInsight. Ces services sont : le contrôleur de basculement maître, le contrôleur de basculement esclave, le master-ha-service et le slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper est un service de coordination à hautes performances pour les applications distribuées. En production, ZooKeeper s'exécute généralement en mode répliqué où un groupe répliqué de serveur ZooKeeper forme un quorum. Chaque cluster HDInsight comporte trois nœuds ZooKeeper qui autorisent trois serveurs ZooKeeper à former un quorum. HDInsight possède deux quorums ZooKeeper s’exécutant en parallèle. Un quorum détermine le nœud principal actif dans un cluster sur lequel les services de haute disponibilité HDInsight doivent s’exécuter. Un autre quorum permet de coordonner les services haute disponibilité fournis par Apache, comme détaillé dans les sections ultérieures.
Basculer le contrôleur esclave
Le contrôleur de basculement esclave s’exécute sur chaque nœud d’un cluster HDInsight. Ce contrôleur est responsable du démarrage de l’agent Ambari et slave-ha-service sur chaque nœud. Il interroge régulièrement le premier quorum ZooKeeper sur le nœud principal actif. Lorsque les nœuds principaux actifs et en veille changent, le contrôleur de basculement esclave effectue les étapes suivantes :
- Met à jour le fichier de configuration d’hôte.
- Redémarre l’agent Ambari.
slave-ha-service est chargé d’arrêter les services haute disponibilité HDInsight (à l’exception du serveur Ambari) sur le nœud principal de secours.
Basculer le contrôleur maître
Un contrôleur de basculement principal s’exécute sur les deux nœuds principaux. Les deux contrôleurs de basculement principaux communiquent avec le premier quorum ZooKeeper pour désigner le nœud principal sur lequel ils s’exécutent en tant que nœud principal actif.
Par exemple, si le contrôleur de basculement principal sur le nœud principal 0 gagne l’élection, les modifications suivantes ont lieu :
- Le nœud principal 0 devient actif.
- Le contrôleur de basculement maître démarre le serveur Ambari et master-ha-service sur le nœud principal 0.
- L’autre contrôleur de basculement maître arrête le serveur Ambari et master-ha-service sur le nœud principal 1.
Le service master-ha-service s’exécute uniquement sur le nœud principal actif, il arrête les services haute disponibilité HDInsight (à l’exception du serveur Ambari) sur le nœud principal de secours et les démarre sur le nœud principal actif.
Processus de basculement
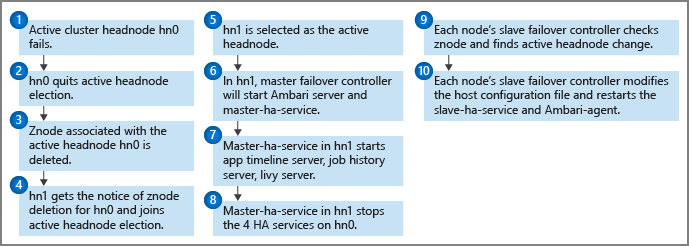
Un moniteur d’intégrité s’exécute sur chaque nœud principal avec le contrôleur de basculement principal pour envoyer des notifications de pulsation au quorum Zookeeper. Le nœud principal est considéré comme un service haute disponibilité dans ce scénario. Le moniteur d’intégrité vérifie si chaque service haute disponibilité est sain et s’il est prêt à participer à l’élection du service maître. Si oui, ce nœud principal participe aux élections. Dans le cas contraire, il abandonne l'élection jusqu'à ce qu'il soit à nouveau prêt.
Si le nœud principal de secours atteint le leadership et devient actif (par exemple en cas de panne du nœud actif précédent), son contrôleur de basculement maître démarre tous les services HDInsight HA sur celui-ci. Le contrôleur de basculement maître arrête ces services sur l’autre nœud principal.
Pour les échecs de services haute disponibilité HDInsight, tels qu’un service en panne ou défectueux, le contrôleur de basculement principal doit automatiquement redémarrer ou arrêter les services en fonction de l’état du nœud principal. Les utilisateurs ne doivent pas démarrer manuellement les services HA HDInsight sur les deux nœuds principaux. Au lieu de cela, autorisez le basculement automatique ou manuel pour faciliter la récupération du service.
Intervention manuelle involontaire
Les services HDInsight HA ne doivent s'exécuter que sur le nœud principal actif et redémarrer automatiquement si nécessaire. Étant donné que les services de haute disponibilité individuels ne possèdent pas leur propre moniteur d’intégrité, le basculement ne peut pas être déclenché au niveau du service individuel. Le basculement est assuré au niveau du nœud et non pas au niveau du service.
Autres problèmes connus
Lors du démarrage manuel d’un service de haute disponibilité sur le nœud principal de secours, il ne s’arrête pas tant que le basculement suivant n’a pas lieu. Lorsque les services haute disponibilité s’exécutent sur les deux nœuds principaux, certains problèmes potentiels incluent ce qui suit : L’interface utilisateur Ambari est inaccessible, Ambari génère des erreurs, des tâches YARN, Spark et Oozie peuvent se bloquer.
Lorsqu’un service haute disponibilité s’arrête sur le nœud principal actif, il ne redémarre pas tant que le basculement suivant n’a pas eu lieu ou que le contrôleur de basculement principal/master-ha-service n’a pas redémarré. Lorsqu’un ou plusieurs services haute disponibilité s’arrêtent sur le nœud principal actif, en particulier lorsque le serveur Ambari s’arrête, l’interface utilisateur Ambari est inaccessible, d’autres problèmes potentiels incluent des échecs de tâches YARN, Spark et Oozie.
Services haute disponibilité Apache
Apache propose la haute disponibilité pour HDFS NameNode, YARN ResourceManager et HBase Master, qui sont également disponibles dans les clusters HDInsight. Contrairement aux services HA HDInsight, ils sont pris en charge dans les clusters ESP. Les services haute disponibilité Apache communiquent avec le deuxième quorum ZooKeeper (décrit dans la section ci-dessus) pour choisir les états actif/de veille et effectuer le basculement automatique. Les sections suivantes détaillent le fonctionnement de ces services.
Système de fichiers Hadoop Distributed File System (HDFS) NameNode
Les clusters HDInsight basés sur Apache Hadoop 2.0 ou une version ultérieure fournissent la haute disponibilité NameNode. Deux NameNodes s’exécutent sur le nœuds principaux, qui sont configurés pour le basculement automatique. Le NameNodes utilise le ZKFailoverController pour communiquer avec Zookeeper afin de choisir l’état actif/de veille. Le ZKFailoverController s'exécute sur les deux nœuds principaux et fonctionne de la même manière que le contrôleur de basculement principal.
Le deuxième quorum Zookeeper est indépendant du premier quorum, de sorte que le NameNode actif peut ne pas s’exécuter sur le nœud principal actif. Lorsque le NameNode actif est mort ou n’est pas sain, le NameNode de secours gagne l’élection et devient actif.
Interface utilisateur de ResourceManager YARN
Les clusters HDInsight basés sur Apache Hadoop 2.4 ou une version ultérieure prennent en charge la haute disponibilité du service de réplication ResourceManager. Deux ResourceManagers, RM1 et RM2, s’exécutent sur le nœud principal 0 et le nœud principal 1, respectivement. Comme NameNode, YARN ResourceManager est également configuré pour le basculement automatique. Un autre ResourceManager est automatiquement choisi comme actif lorsque le ResourceManager actif est en panne ou ne répond pas.
YARN ResourceManager utilise son ActiveStandbyElector intégré en tant que détecteur de panne et électeur du chef de groupe. Contrairement à HDFS NameNode, YARN ResourceManager n’a pas besoin d’un démon ZKFC distinct. Le ResourceManager actif écrit ses états dans Apache Zookeeper.
La haute disponibilité de YARN ResourceManager est indépendante de NameNode et d’autres services haute disponibilité HDInsight. Le ResourceManager actif peut ne pas s’exécuter sur le nœud principal actif ou sur le nœud principal où le NameNode actif est en cours d’exécution. Pour plus d’informations sur la haute disponibilité de YARN ResourceManager, consultez Haute disponibilité de ResourceManager.
HBase Master
Les clusters HDInsight HBase prennent en charge la haute disponibilité du maître HBase. Contrairement à d’autres services haute disponibilité, qui s’exécutent sur les nœuds principaux, les maîtres HBase s’exécutent sur les trois nœuds Zookeeper, dans lesquels un nœud est le maître actif et les deux autres sont en veille. Comme NameNode, le maître HBase se coordonne avec Apache Zookeeper pour l’élection du chef et effectue un basculement automatique lorsque le maître actif actuel a des problèmes. Il n’y a qu’un maître HBase actif à la fois.
Étapes suivantes
- Availability and reliability of Apache Hadoop clusters in HDInsight (Disponibilité et fiabilité des clusters Apache Hadoop dans HDInsight)
- Architecture de réseau virtuel Azure HDInsight
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour