Superviser les performances des clusters dans Azure HDInsight
La surveillance de l’intégrité et des performances d’un cluster HDInsight est essentielle à l’optimisation continue des performances et de l’utilisation des ressources. La surveillance peut également vous aider à détecter et résoudre les erreurs de configuration du cluster ainsi que les problèmes de code utilisateur.
Les sections suivantes expliquent comment surveiller et optimiser la charge de vos clusters et les files d'attente Apache Hadoop YARN, et détecter les problèmes de limitation de stockage.
Surveiller la charge du cluster
Les clusters Hadoop peuvent offrir des performances optimales lorsque la charge est répartie de manière uniforme sur tous les nœuds. Cela permet aux tâches de traitement de s'exécuter sans être gênées par la RAM, l'UC ou les ressources disque sur les nœuds individuels.
Pour obtenir une vue d’ensemble des nœuds de votre cluster et de leur charge, connectez-vous à l’interface utilisateur web Ambari, puis sélectionnez l’onglet Hosts (Hôtes). Vos hôtes sont répertoriés par leur nom de domaine complet. L’état de fonctionnement de chaque hôte est spécifié par un indicateur d’intégrité en couleur :
| Couleur | Description |
|---|---|
| Rouge | Au moins un composant maître de l’hôte est défaillant. Pointez sur l’indicateur pour visualiser une info-bulle répertoriant les composants concernés. |
| Orange | Au moins un composant secondaire de l’hôte est défaillant. Pointez sur l’indicateur pour visualiser une info-bulle répertoriant les composants concernés. |
| Yellow | Le serveur Ambari n’a reçu aucune pulsation de l’hôte depuis plus de trois minutes. |
| Vert | L’état de fonctionnement est normal. |
Le tableau de bord comporte également des colonnes indiquant le nombre de cœurs et la quantité de RAM de chaque hôte, ainsi que l’utilisation du disque et la charge moyenne.
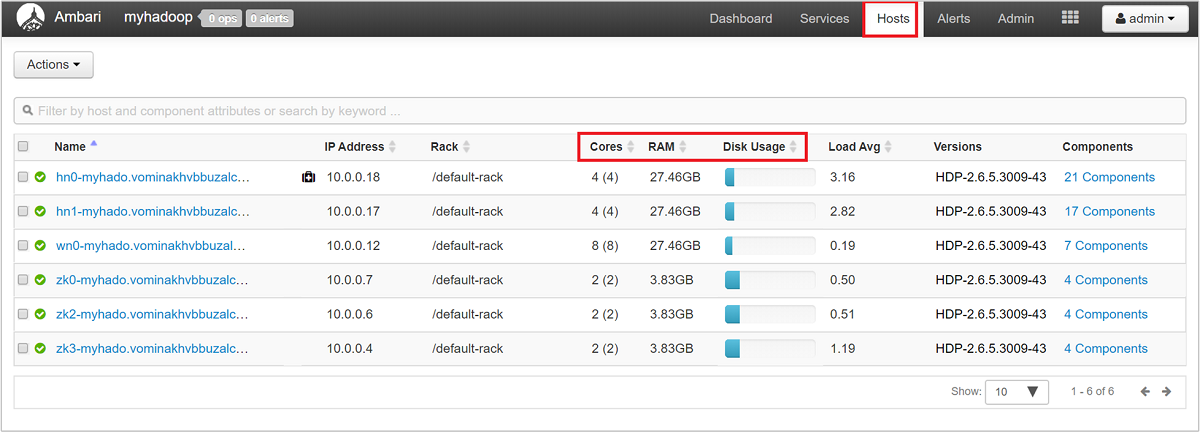
Sélectionnez l’un des noms d’hôte pour obtenir une vue d’ensemble détaillée des composants en cours d’exécution sur cet hôte et de leurs métriques. Les métriques sont présentés en fonction d’une chronologie configurable et concernent l’utilisation du processeur, la charge, l’utilisation du disque, l’utilisation de la mémoire, l’utilisation du réseau et les nombres de processus.
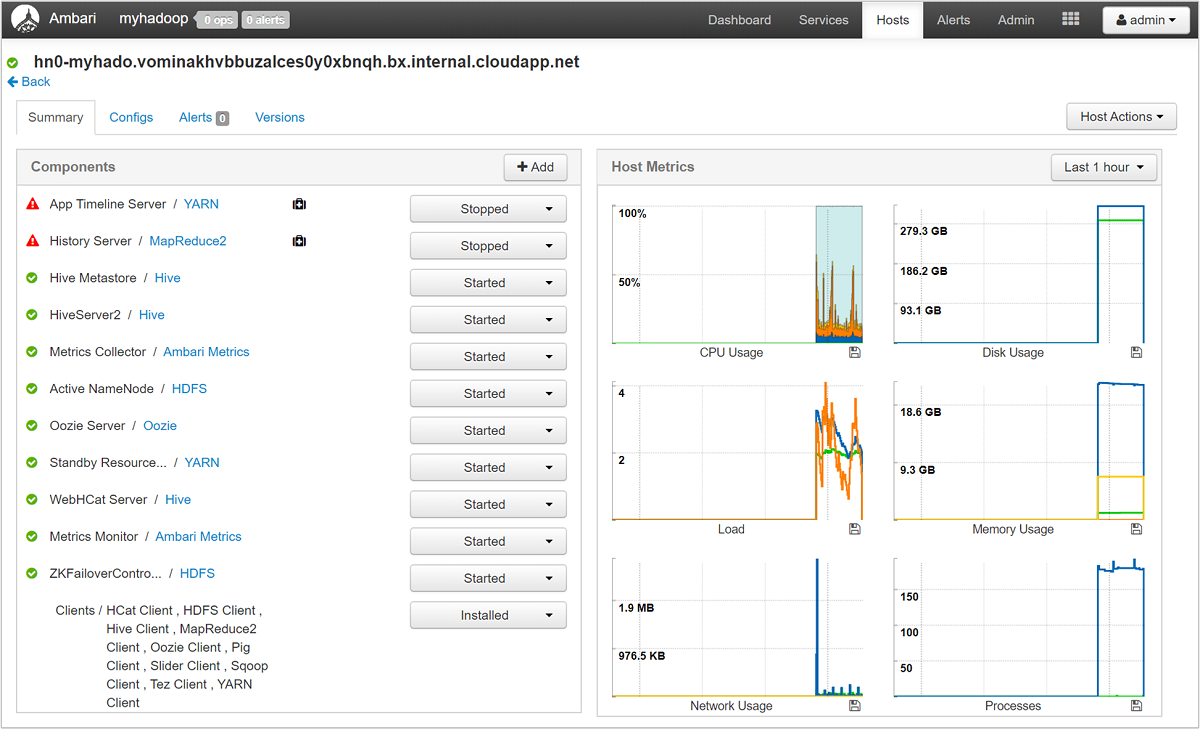
Pour plus d’informations sur la configuration d’alertes et sur la visualisation des métriques, consultez l’article Gérer des clusters HDInsight à l’aide de l’interface utilisateur web d’Apache Ambari.
Configuration des files d’attente YARN
Hadoop exécute différents services sur sa plateforme distribuée. YARN (Yet Another Resource Negotiator) coordonne ces services et alloue les ressources de cluster afin de veiller à ce que toute charge soit répartie de manière uniforme sur le cluster.
YARN répartit les deux responsabilités du JobTracker, à savoir la gestion des ressources et la planification/surveillance des travaux, entre deux démons : un démon Resource Manager global, et un démon ApplicationMaster (AM) par application.
Le démon Resource Manager est un pur planificateur dont la seule fonction consiste à arbitrer la répartition des ressources disponibles entre toutes les applications concurrentes. Le démon Resource Manager garantit l’utilisation systématique de la totalité des ressources, optimisant ainsi différentes constantes telles que les Contrats de niveau de service (SLA), les garanties de capacité, et ainsi de suite. Le démon ApplicationMaster négocie les ressources auprès du démon Resource Manager et fonctionne avec les NodeManagers pour exécuter et surveiller les conteneurs et leur consommation des ressources.
Lorsque plusieurs locataires partagent un cluster volumineux, ils entrent en concurrence pour les ressources du cluster. Le CapacityScheduler est un planificateur enfichable qui facilite le partage des ressources en plaçant les requêtes en file d’attente. Le CapacityScheduler prend également en charge les files d’attente hiérarchiques pour garantir le partage des ressources entre les sous-files d’attente d’une organisation, avant que les files d’attente des autres applications soient autorisées à utiliser les ressources disponibles.
YARN nous permet également d’allouer des ressources à ces files d’attente et vous indique si toutes vos ressources disponibles sont ou non attribuées. Pour visualiser les informations concernant vos files d’attente, connectez-vous à l’interface utilisateur web Ambari, puis sélectionnez YARN Queue Manager (Gestionnaire de files d’attente YARN) dans le menu supérieur.
La page YARN Queue Manager (Gestionnaire de files d’attente YARN) répertorie vos files d’attente sur la gauche et indique le pourcentage de capacité attribué à chacune.
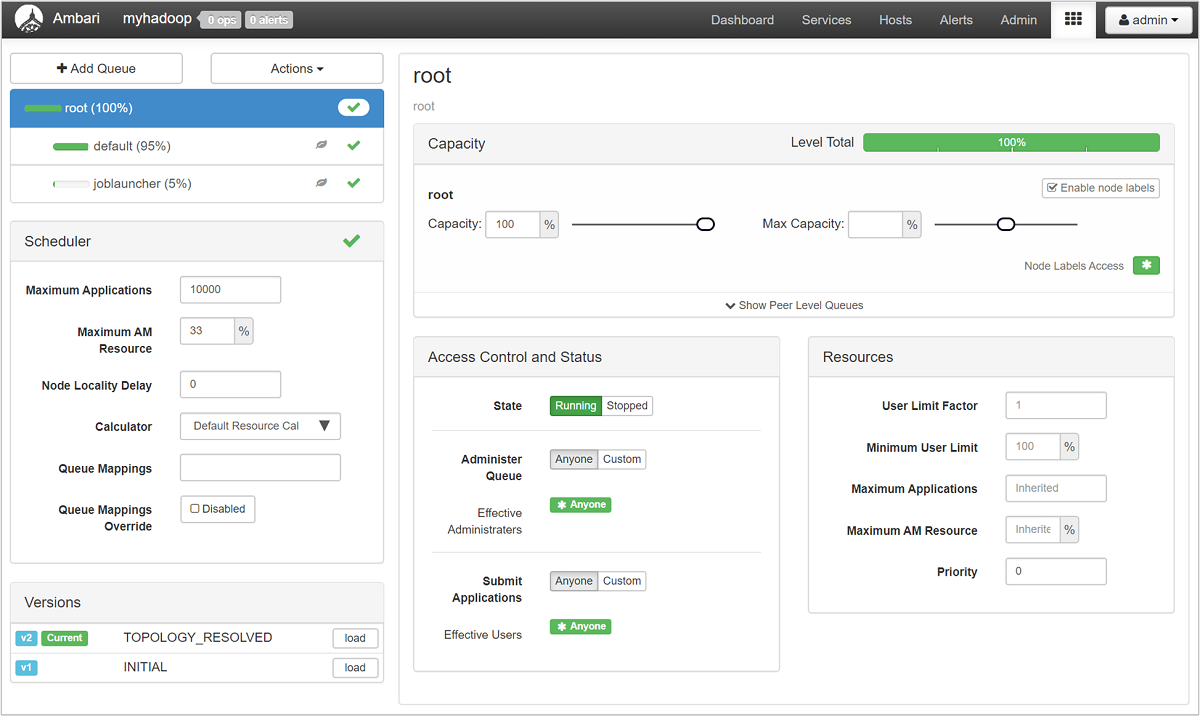
Pour obtenir une vue d’ensemble plus détaillée de vos files d’attente, dans le tableau de bord Ambari, sélectionnez le service YARN (YARN) dans la liste de gauche. Ensuite, dans le menu déroulant Quick Links (Liens rapides), sélectionnez Resource Manager UI (Interface utilisateur Resource Manager) sous votre nœud actif.
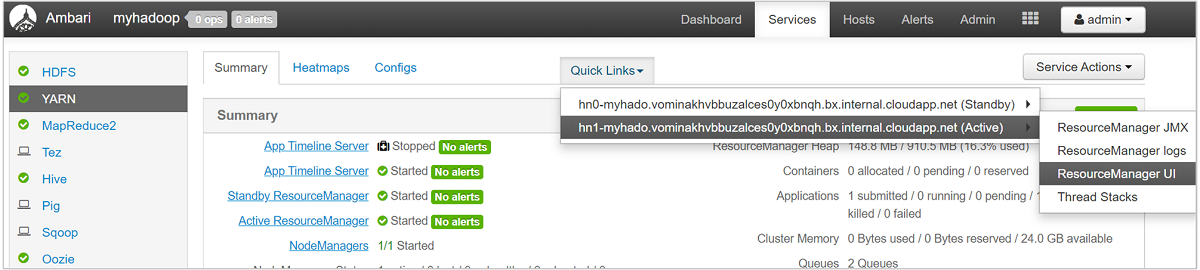
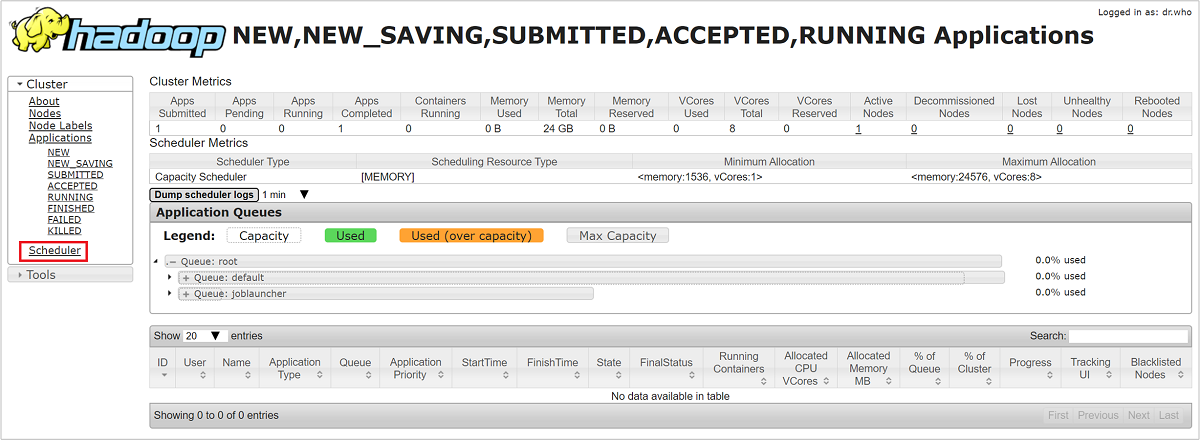
Dans l’interface utilisateur Resource Manager, sélectionnez Scheduler (Planificateur) à partir du menu de gauche. La liste de vos files d’attente s’affiche sous Application Queues (Files d’attente d’application). Cette zone présente la capacité utilisée pour chacune de vos files d’attente, ainsi que l’efficacité de la répartition des travaux entre ces files d’attente, et indique si des travaux sont limités en ressources.
Limitation du stockage
Un goulot d’étranglement des performances d’un cluster peut survenir au niveau du stockage. Ce type de goulot d’étranglement est généralement dû au blocage des opérations d’entrée et de sortie (E/S), qui se produit si vos tâches en cours d’exécution envoient plus d’E/S que le service de stockage ne peut en traiter. Ce blocage crée une file d’attente des requêtes d’E/S en attente de traitement, le temps que les E/S actuelles soient traitées. Les blocages découlent d’une limitation du stockage, qui n’est pas une limite physique, mais plutôt une limite imposée par le service de stockage en vertu d’un contrat de niveau de service (SLA). Cette limite évite tout risque qu’un client ou locataire monopolise le service. Le SLA limite le nombre d’E/S par seconde (IOPS) pour le stockage Azure. Pour plus d’informations, consultez l’article Objectifs de performance et d’extensibilité pour les comptes de stockage standard.
Si vous utilisez le service Stockage Azure et que vous souhaitez en savoir plus sur la supervision des problèmes liés au stockage, notamment la limitation, consultez l’article Surveiller, diagnostiquer et résoudre les problèmes liés à Microsoft Azure Storage.
Si le magasin de stockage de votre cluster est Azure Data Lake Storage (ADLS), le problème de limitation découle probablement des limites de bande passante. Dans ce cas, vous pouvez identifier la limitation en consultant les erreurs de limitation consignées dans les journaux d’activité des tâches. Pour ADLS, consultez la section sur la limitation relative au service approprié dans les articles suivants :
- Recommandations en matière d’optimisation des performances pour Apache Hive sur HDInsight et Azure Data Lake Storage
- Recommandations en matière d’optimisation des performances pour MapReduce sur HDInsight et Azure Data Lake Storage
Détecter un problème de nœuds lents
Dans certains cas, un ralentissement peut se produire en raison d’un espace disque faible sur le cluster. Utilisez les étapes suivantes pour recherchez la cause du problème :
Utilisez ssh command pour vous connecter à chacun des nœuds.
Vérifiez l’utilisation du disque en exécutant l’une des commandes suivantes :
df -h du -h --max-depth=1 / | sort -hExaminez la sortie et recherchez la présence de fichiers volumineux dans le dossier
mntou dans d’autres dossiers. En règle générale, les dossiersusercacheetappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) contiennent des fichiers volumineux.S’il y a des fichiers volumineux, soit un travail en cours est à l’origine de la croissance du fichier, soit un travail précédent ayant échoué peut avoir contribué à ce problème. Pour vérifier si ce comportement est dû à un travail en cours, exécutez la commande suivante :
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Si cette commande indique un travail spécifique, vous pouvez choisir de mettre fin au travail avec une commande similaire à celle-ci :
yarn application -kill -applicationId <application_id>Remplacez
application_idpar l’ID de l’application. Si aucun travail spécifique n’est indiqué, passez à l’étape suivante.Une fois la commande ci-dessus terminée ou si aucun travail spécifique n’est indiqué, supprimez les fichiers volumineux que vous avez identifiés en exécutant une commande similaire à celle-ci :
rm -rf filecache usercache
Pour plus d’informations sur les problèmes d’espace disque, consultez Espace disque insuffisant.
Notes
Si vous avez des fichiers volumineux que vous souhaitez conserver, mais qui contribuent au problème d’espace disque faible, vous devez monter votre cluster HDInsight en puissance et redémarrer vos services. Une fois cette procédure terminée et après avoir attendu quelques minutes, vous noterez que le stockage est libéré et que les performances habituelles du nœud sont restaurées.
Étapes suivantes
Pour plus d’informations sur la résolution des problèmes et la surveillance de vos clusters, cliquez sur les liens suivants :