Gérer les journaux d’activité pour un cluster HDInsight
Un cluster HDInsight génère plusieurs fichiers journaux. Par exemple, Apache Hadoop et des services associés, tels que Apache Spark, génèrent des journaux d’activité d’exécution de travaux détaillés. La gestion des fichiers journaux fait partie intégrante de la gestion d’un cluster HDInsight sain. Ce processus peut également être une exigence réglementaire pour l’archivage des journaux. En raison du nombre et de la taille des fichiers journaux, l’optimisation du stockage des journaux et l’archivage vous aident à gérer la gestion des coûts.
La gestion des journaux d’activité de cluster HDInsight inclut la conservation d’informations sur tous les aspects de l’environnement de cluster. Ces informations incluent tous les journaux d’activité de service Azure associés, la configuration du cluster, les informations sur l’exécution des travaux, les états d’erreur et d’autres données en fonction des besoins.
Les étapes classiques de gestion des journaux HDInsight sont les suivantes :
- Étape 1 : Déterminer les stratégies de rétention du journal
- Étape 2 : Gérer les journaux d’activité de configuration des versions du service de cluster
- Étape 3 : Gérer les fichiers journaux d’exécution des travaux de cluster
- Étape 4 : Prévoir les tailles de stockage du volume du fichier journal et les coûts associés
- Étape 5 : Déterminer les stratégies d’archivage de journaux et les processus associés
Étape 1 : Déterminer les stratégies de rétention du journal
La première étape pour la création d’une stratégie de gestion des journaux de cluster HDInsight consiste à recueillir des informations sur les scénarios d’entreprise et les besoins de stockage de l’historique d’exécution des travaux.
Détails du cluster
Les informations de cluster suivantes sont utiles pour collecter des informations dans votre stratégie de gestion des journaux. Collectez ces informations à partir de tous les clusters HDInsight que vous avez créés dans un compte Azure particulier.
- Nom du cluster
- Région de cluster et zone de disponibilité Azure
- État du cluster, y compris les détails de la dernière modification d’état
- Type et nombre d’instances HDInsight spécifiés pour les nœuds maître, principaux et de tâche
Vous pouvez obtenir la plupart de ces informations de niveau supérieur à l’aide du portail Azure. Vous pouvez aussi utiliser Azure CLI pour obtenir des informations sur votre ou vos clusters HDInsight :
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Vous pouvez également utiliser PowerShell pour afficher ces informations. Pour en savoir plus, consultez Gestion des clusters Apache Hadoop dans HDInsight au moyen d’Azure PowerShell.
Comprendre les charges de travail exécutées sur des clusters
Il est important de comprendre les types de charges de travail exécutées sur votre cluster HDInsight pour concevoir de façon appropriée les stratégies de journalisation pour chaque type.
- Les charges de travail sont-elles expérimentales (par exemple, en développement ou test) ou de qualité production ?
- À quelle fréquence les charges de travail de qualité production s’exécutent-elles normalement ?
- S’agit-il de charges de travail gourmandes en ressources et/ou exécutées à long terme ?
- Certaines de ces charges de travail utilisent-elles un jeu complexe de services Hadoop pour lesquels plusieurs types de journaux d’activité sont générés ?
- Certaines charges de travail sont-elles associées à des exigences de lignage d’exécution réglementaires ?
Pratiques et modèles de rétention de journal
Envisagez d’assurer le suivi du lignage des données en ajoutant un identificateur à chaque entrée de journal, ou par d’autres techniques. Cela vous permet de retrouver la source d’origine des données et de l’opération et de suivre les données à chaque étape pour comprendre leur cohérence et validité.
Définissez la façon dont vous pouvez collecter les journaux d’activité à partir du cluster, ou à partir de plusieurs clusters, et les rassembler pour des opérations telles que l’audit, la supervision, la planification et les alertes. Vous pouvez utiliser une solution personnalisée pour accéder à et télécharger les fichiers journaux régulièrement, puis les combiner et les analyser pour fournir un tableau de bord. Vous pouvez également ajouter des fonctionnalités supplémentaires pour les alertes de sécurité ou la détection des défaillances. Vous pouvez générer ces utilitaires à l’aide de PowerShell, des kits de développement logiciel HDInsight ou d’un code qui accède au modèle de déploiement Azure Classic.
Décidez si une solution ou un service de supervision peut être utile. Microsoft System Center fournit un pack d’administration HDInsight. Vous pouvez également utiliser des outils tiers tels qu’Apache Chukwa et Ganglia pour collecter et centraliser les journaux d’activité. De nombreuses sociétés proposent des services pour monitorer des solutions Big Data basées sur Hadoop, par exemple :
Centerity, Compuware APM, Sematext SPM et Zettaset Orchestrator.
Étape 2 : Gérer les versions du service de cluster et consulter les journaux d’activité
Un cluster HDInsight classique s’appuie sur plusieurs services et packages logiciels open source (tels que Apache HBase, Apache Spark, etc.). Pour certaines charges de travail, telles que la bio-informatique, vous devez conserver l’historique des journaux d’activité de configuration du service en plus des journaux d’activité d’exécution des travaux.
Vérifier les paramètres de configuration du cluster avec l’interface utilisateur Ambari
Apache Ambari simplifie la gestion, la configuration et le monitoring d’un cluster HDInsight en fournissant une interface utilisateur web et une API REST. Ambari est inclus sur les clusters HDInsight sous Linux. Sélectionnez le volet Tableau de bord du cluster sur la page HDInsight du portail Azure pour ouvrir la page de liens Tableaux de bord du cluster. Sélectionnez ensuite le volet Tableau de bord du cluster HDInsight pour ouvrir l’interface utilisateur Ambari. Vous êtes invité à entrer les informations d’identification utilisées pour vous connecter au cluster.
Pour ouvrir une liste de vues du service, sélectionnez Vues Ambari sur la page du portail Azure pour HDInsight. Cette liste varie selon les bibliothèques que vous avez installées. Elle peut contenir par exemple YARN Queue Manager, Hive View et Tez View. Sélectionnez le lien d’un service pour afficher des informations sur la configuration et le service. La page Pile et version de l’interface utilisateur Ambari fournit des informations sur la configuration des services du cluster et sur l’historique de version des services. Pour accéder à cette section de l’interface utilisateur Ambari, sélectionnez le menu Admin, puis Piles et versions. Sélectionnez l’onglet Versions pour afficher des informations sur la version du service.
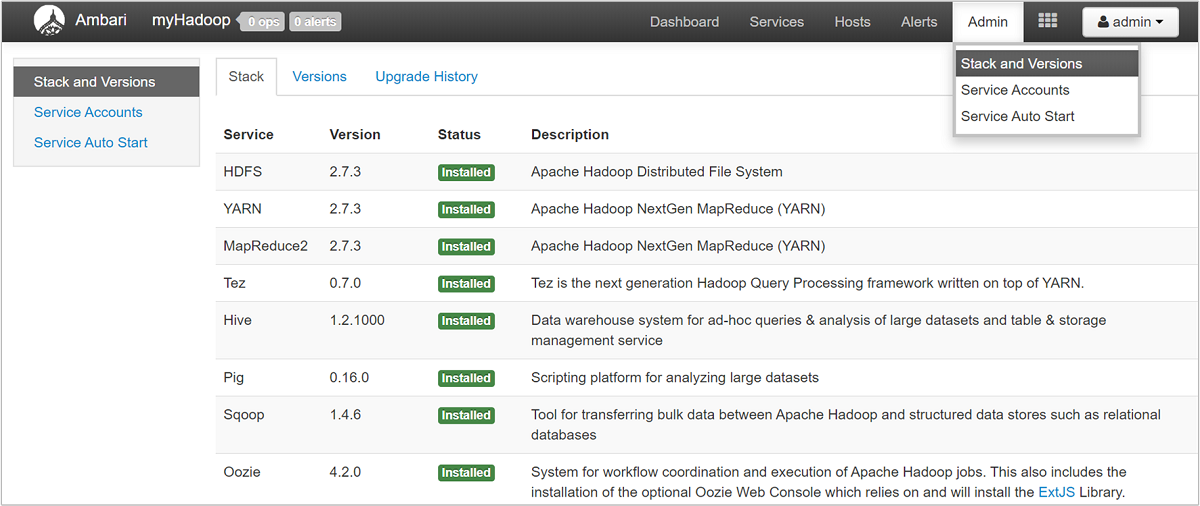
À l’aide de l’UI Ambari, vous pouvez télécharger la configuration d’un ou de tous les services exécutés sur un hôte particulier (ou un nœud) du cluster. Sélectionnez le menu Hôtes, puis le lien pour l’hôte qui vous intéresse. Sur la page de l’hôte, sélectionnez le bouton Actions de l’hôte, puis Télécharger les configurations clientes.
Voir les journaux d’activité d’actions de script
Les actions de script HDInsight exécutent des scripts sur le cluster manuellement ou à l’intervalle spécifié. Par exemple, des actions de script peuvent être utilisées pour installer des logiciels supplémentaires sur le cluster ou pour modifier les paramètres de configuration à partir des valeurs par défaut. Les journaux d’activité d’actions de script peuvent fournir des insights sur les erreurs qui se sont produites pendant l’installation du cluster, ainsi que les modifications des paramètres de configuration qui peuvent affecter la disponibilité et les performances du cluster. Pour consulter l’état d’une action de script, sélectionnez le bouton ops dans l’interface utilisateur Ambari, ou accédez aux journaux d’activité d’état à partir du compte de stockage par défaut. Les journaux d’activité de stockage sont disponibles dans /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Consulter les journaux d’état des alertes Ambari
Apache Ambari écrit les modifications d’état d’alerte dans ambari-alerts.log. Le chemin complet est /var/log/ambari-server/ambari-alerts.log. Pour activer le débogage du journal, changez une propriété dans /etc/ambari-server/conf/log4j.properties. Changez ensuite l’entrée sous # Log alert state changes à partir de :
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Étape 3 : Gérer les fichiers journaux d’exécution des travaux de cluster
L’étape suivante examine les fichiers journaux d’exécution des travaux des différents services. Par exemple Apache HBase, Apache Spark et bien d’autres. Un cluster Hadoop génère un grand nombre de journaux d’activité détaillés. Aussi, déterminer quels journaux d’activité sont utiles (et ne le sont pas) peut prendre du temps. Comprendre le système de journalisation est important pour la gestion ciblée des fichiers journaux. L’image ci-dessous est un exemple de fichier journal.

Accéder aux fichiers journaux Hadoop
HDInsight stocke ses fichiers journaux dans le système de fichiers du cluster et dans Stockage Azure. Vous pouvez examiner les fichiers journaux dans le cluster en ouvrant une connexion SSH au cluster et en parcourant le système de fichiers, ou à l’aide du portail Hadoop YARN Status sur le serveur du nœud principal distant. Vous pouvez examiner les fichiers journaux dans Stockage Azure à l’aide d’outils qui peuvent parcourir et télécharger des données à partir de Stockage Azure. AZCopy, CloudXplorer et l’Explorateur de serveurs Visual Studio en sont des exemples. Vous pouvez également utiliser PowerShell et les bibliothèques de client de stockage Azure ou les Kits de développement logiciel Azure .NET pour accéder aux données dans le stockage blob Azure.
Hadoop exécute les travaux en tant que tentatives de tâches sur différents nœuds du cluster. HDInsight peut initier des tentatives de tâches spéculatives, en arrêtant les tentatives de tâches qui ne se terminent. Cela génère une activité importante qui est journalisée dans le contrôleur, stderr et les fichiers journaux syslog à la volée. De plus, plusieurs tentatives de tâches sont exécutées simultanément, mais un fichier journal peut uniquement afficher des résultats de façon linéaire.
Journaux d’activité HDInsight écrits dans Stockage Blob Azure
Les clusters HDInsight sont configurés pour écrire les journaux d’activité des tâches dans un compte de stockage d’objets blob Azure pour toute tâche envoyée par le biais des cmdlets Azure PowerShell ou les API d’envoi de travaux .NET. Si vous envoyez des travaux via SSH au cluster, les informations de journalisation de l’exécution sont stockées dans des Tables Azure, comme expliqué dans la section précédente.
Outre les principaux fichiers journaux générés par HDInsight, les services installés tels que YARN génèrent également des fichiers journaux d’exécution des travaux. Le nombre et le type des fichiers journaux dépendent des services installés. Apache HBase, Apache Spark, etc. sont des services courants. Examinez les fichiers journaux d’exécution des travaux pour chaque service afin de comprendre les fichiers de journalisation disponibles sur votre cluster. Chaque service a ses propres méthodes uniques de journalisation et emplacements pour le stockage des fichiers journaux. Par exemple, la section suivante vous montre comment accéder aux fichiers journaux des services courants (à partir de YARN).
Journaux d’activité HDInsight générés par YARN
YARN regroupe les journaux d’activité de tous les conteneurs sur un nœud Worker et les stocke dans un fichier journal agrégé par nœud Worker. Ce journal est stocké sur le système de fichiers par défaut après la fin d’une application. Votre application peut utiliser des centaines voire des milliers de conteneurs, mais les journaux d’activité de tous les conteneurs exécutés sur un nœud worker unique sont toujours regroupés dans un fichier unique. Cela se traduit par l’existence d’un fichier journal par nœud worker utilisé par votre application. L’agrégation de journaux est activée par défaut sur les clusters HDInsight version 3.0 et versions ultérieures. Les journaux d’activité agrégés sont situés dans le stockage par défaut pour le cluster.
/app-logs/<user>/logs/<applicationId>
Les journaux agrégés ne sont pas lisibles directement, car ils sont écrits dans un format binaire TFile indexé par conteneur. Utilisez les journaux ResourceManager YARN ou les outils CLI pour afficher ces journaux au format texte brut pour les applications ou les conteneurs qui présentent un intérêt.
Outils de l’interface de ligne de commande YARN
Pour utiliser les outils de l’interface de ligne de commande YARN, vous devez d’abord vous connecter au cluster HDInsight en utilisant le protocole SSH. Spécifiez les informations <applicationId>, <user-who-started-the-application>, <containerId> et <worker-node-address> lors de l’exécution de ces commandes. Vous pouvez afficher les journaux d’activité en texte brut en exécutant l’une des commandes suivantes :
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Interface utilisateur Resource Manager YARN
L’interface utilisateur Resource Manager YARN s’exécute sur le nœud principal du cluster et est accessible via l’interface utilisateur web d’Ambari. Procédez comme suit pour afficher les journaux d’activité YARN :
- Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net. Remplacez CLUSTERNAME par le nom de votre cluster HDInsight. - Dans la liste des services sur la gauche, sélectionnez YARN.
- Dans la liste déroulante Liens rapides, sélectionnez un des nœuds principaux du cluster, puis Journaux d’activité Resource Manager. Une liste de liens menant vers les journaux d’activité YARN s’affiche.
Étape 4 : Prévoir les tailles de stockage du volume du fichier journal et les coûts associés
Une fois que vous aurez effectué les étapes précédentes, vous comprendrez les types et les volumes de fichiers journaux produits par votre ou vos clusters HDInsight.
Ensuite, analysez le volume de données de journal dans les principaux emplacements de stockage des journaux sur une période donnée. Par exemple, vous pouvez analyser le volume et la croissance sur des périodes de 30-60-90 jours. Enregistrez ces informations dans une feuille de calcul ou utilisez d’autres outils tels que Visual Studio, l’Explorateur de stockage Azure ou Power Query pour Excel. ```
Vous avez maintenant suffisamment d’informations pour créer une stratégie de gestion des principaux journaux d’activité. Utilisez votre feuille de calcul (ou l’outil de votre choix) pour prévoir l’augmentation de la taille des journaux et des coûts du stockage des journaux. Envisagez également les conditions de rétention de l’ensemble des journaux d’activité que vous examinez. Vous pouvez à présent recalculer les futurs coûts de stockage des journaux, après avoir déterminé les fichiers journaux pouvant être supprimés (le cas échéant) et les journaux devant être conservés et archivés dans un Stockage Azure moins coûteux.
Étape 5 : Déterminer les stratégies d’archivage de journaux et les processus associés
Une fois que vous avez déterminé quels fichiers journaux peuvent être supprimés, vous pouvez ajuster les paramètres de journalisation de nombreux services Hadoop pour supprimer automatiquement des fichiers journaux après une période donnée.
Pour certains fichiers journaux, vous pouvez utiliser une approche d’archivage de fichiers journaux moins onéreuse. Pour les journaux d’activité Azure Resource Manager, vous pouvez explorer cette approche via le portail Azure. Configurez l’archivage des journaux d’activité Resource Manager en sélectionnant le lien Journal d’activité dans le portail Azure pour votre instance HDInsight. En haut de la page de recherche de journal d’activité, sélectionnez l’élément de menu Exporter pour ouvrir le volet Exporter le journal d’activité. Remplissez l’abonnement, la région, s’il faut exporter vers un compte de stockage et le nombre de jours pendant lesquels conserver les journaux d’activité. Dans ce même volet, vous pouvez également indiquer s’il faut exporter vers un Event Hub.
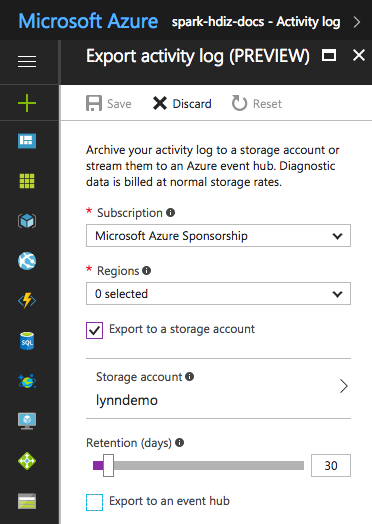
Vous pouvez également créer un script d’archivage de journaux avec PowerShell.
Accès aux métriques Stockage Azure
Stockage Azure peut être configuré pour journaliser les opérations de stockage et l’accès. Vous pouvez utiliser ces journaux d’activité très détaillés pour le suivi et la planification de la capacité, ainsi que pour l’audit des requêtes envoyées au stockage. Les informations journalisées comprennent des détails sur la latence, ce qui vous permet de surveiller et d’optimiser les performances de vos solutions. Vous pouvez utiliser le SDK .NET pour Hadoop afin d’examiner les fichiers journaux générés pour le Stockage Azure qui contient les données d’un cluster HDInsight.
Contrôler la taille et le nombre d’index de sauvegarde pour les anciens fichiers journaux
Pour contrôler la taille et le nombre des fichiers journaux conservés, définissez les propriétés suivantes de la RollingFileAppender :
maxFileSizeest la taille critique du fichier, au-delà de laquelle le fichier est restauré. La valeur par défaut est 10 Mo.maxBackupIndexSpécifie le nombre de fichiers de sauvegarde à créer (la valeur par défaut est 1).
Autres techniques de gestion des journaux
Pour éviter de manquer d’espace disque, vous pouvez utiliser des outils du système d’exploitation, comme logrotate pour gérer les fichiers journaux. Vous pouvez configurer logrotate pour s’exécuter sur une base quotidienne, en compressant les fichiers journaux et en supprimant les anciens. Votre approche dépend de vos besoins, tels que la durée pendant laquelle conserver les fichiers journaux sur les nœuds locaux.
Vous pouvez également vérifier si la journalisation DEBUG est activée pour un ou plusieurs services, ce qui augmente considérablement la taille des journaux de sortie.
Pour collecter les journaux d’activité de tous les nœuds dans un seul emplacement central, vous pouvez créer un flux de données, tel que l’ingestion de toutes les entrées de journal d’activité dans Solr.