Mettre à l’échelle manuellement des clusters Azure HDInsight
HDInsight fournit une élasticité avec des options de scale-up ou scale-down du nombre de nœuds Worker dans vos clusters. Cette élasticité vous permet de réduire un cluster après certaines heures ou les week-ends, et de le développer pendant les pics d’activité.
Effectuez un scale-up de votre cluster avant le traitement périodique par lots afin que le cluster dispose des ressources appropriées. Une fois que le traitement est terminé et que l’utilisation est redescendue, effectuez un scale-down du cluster HDInsight de façon à utiliser moins de nœuds Worker.
Vous pouvez mettre à l’échelle un cluster manuellement en appliquant une des méthodes suivantes. Vous pouvez également utiliser des options de mise à l’échelle automatique pour effectuer un scale-up ou un scale-down automatiquement en fonction de certaines métriques.
Notes
Seuls les clusters ayant la version 3.1.3 de HDInsight ou une version ultérieure sont pris en charge. Si vous n’êtes pas sûr de la version de votre cluster, vous pouvez consulter la page Propriétés.
Utilitaires permettant de mettre à l’échelle des clusters
Microsoft fournit les utilitaires suivants pour la mise à l’échelle des clusters :
| Utilitaire | Description |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Azure Classic CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure portal | Ouvrez le volet de votre cluster HDInsight, sélectionnez Taille de cluster dans le menu de gauche, puis, dans le volet Taille de cluster, entrez le nombre de nœuds Worker, puis sélectionnez Enregistrer. |

Grâce à ces méthodes, vous pouvez monter ou descendre en puissance votre cluster HDInsight en quelques minutes.
Important
Impact des opérations de mise à l’échelle
Quand vous ajoutez des nœuds à votre cluster HDInsight en cours d’exécution (scale-up), les travaux restent non affectés. De nouveaux travaux peuvent être soumis en toute sécurité pendant que le processus de mise à l’échelle est en cours d’exécution. En cas d’échec de l’opération de mise à l’échelle, l’échec laisse votre cluster dans un état fonctionnel.
Si vous supprimez des nœuds (scale-down), tous les travaux en attente ou en cours d’exécution échouent quand l’opération de mise à l’échelle se termine. Cet échec est dû au redémarrage de certains des services pendant le processus de mise à l’échelle. Votre cluster risque d’être bloqué en mode sans échec lors d’une opération de mise à l’échelle manuelle.
L’impact de la modification du nombre de nœuds de données varie en fonction de chaque type de cluster pris en charge par HDInsight :
Apache Hadoop
Vous pouvez augmenter en toute transparence le nombre de nœuds Worker dans un cluster Hadoop en cours d’exécution sans affecter les travaux. De nouvelles tâches peuvent également être soumises lorsque l'opération est en cours. Les échecs lors d’une opération de mise à l’échelle sont gérés de manière appropriée. Le cluster est toujours laissé dans un état fonctionnel.
Quand un cluster Hadoop est mis à l’échelle avec moins de nœuds de données, certains services sont redémarrés. Ce comportement entraîne l’échec de toutes les tâches en cours d’exécution ou en attente lors de la réalisation de l’opération de mise à l’échelle. Toutefois, vous pouvez soumettre à nouveau les tâches une fois l'opération terminée.
Apache HBase
Vous pouvez ajouter ou supprimer des nœuds en continu à votre cluster HBase pendant son exécution. Les serveurs régionaux sont équilibrés automatiquement quelques minutes après la fin de l’opération de mise à l’échelle. Toutefois, vous pouvez équilibrer manuellement les serveurs régionaux. Connectez-vous au nœud principal du cluster et exécutez les commandes suivantes :
pushd %HBASE_HOME%\bin hbase shell balancerPour plus d’informations sur l’utilisation de l’interpréteur de commandes HBase, consultez Prise en main d’un exemple Apache HBase dans HDInsight.
Remarque
Non applicable pour des clusters Kafka.
LLAP d’Apache Hive
Après la mise à l’échelle vers
Nnœuds Worker, HDInsight définit automatiquement les configurations suivantes et redémarre Hive.- Nombre total maximal de requêtes simultanées :
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Nombre de nœuds utilisés par le LLAP de Hive :
num_llap_nodes = N - Nombre de nœuds pour l’exécution du démon LLAP Hive :
num_llap_nodes_for_llap_daemons = N
- Nombre total maximal de requêtes simultanées :
Scale down d’un cluster en toute sécurité
Effectuer un scale down sur un cluster dont des travaux sont en cours d’exécution
Pour éviter l’échec de vos travaux en cours d’exécution pendant une opération de scale down, vous pouvez essayer trois choses :
- Attendez la fin des travaux avant de procéder au scale down du cluster.
- Mettez fin aux travaux manuellement.
- Soumettez à nouveau les travaux une fois l’opération de mise à l’échelle terminée.
Pour afficher la liste des travaux en attente ou en cours d’exécution, vous pouvez utiliser l’interface utilisateur Resource Manager de YARN en procédant comme suit :
Dans le Portail Azure, sélectionnez votre cluster. Le cluster est ouvert dans une nouvelle page du portail.
À partir de la vue principale, accédez à Tableaux de bord du cluster>Accueil Ambari. Entrez les informations d’identification de votre cluster.
Dans l’interface utilisateur d’Ambari, sélectionnez YARN dans la liste des services du menu de gauche.
Dans la page YARN, sélectionnez Quick Links (Liens rapides), placez le curseur sur le nœud principal actif, puis sélectionnez Resource Manager UI (Interface utilisateur Resource Manager).

Vous pouvez accéder directement à l’interface utilisateur Resource Manager avec https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Une liste de travaux avec leur état actuel apparaît. La capture d’écran indique un travail en cours d’exécution :
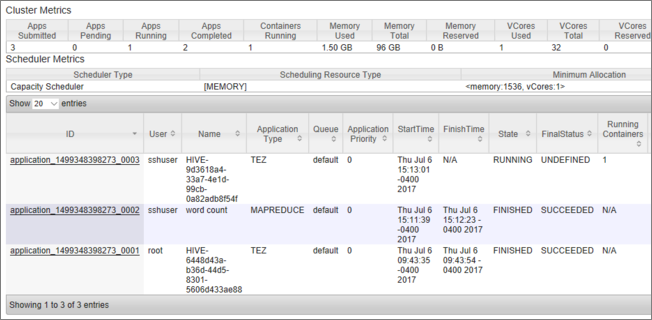
Pour arrêter manuellement cette application en cours d’exécution, exécutez la commande suivante à partir de l’interpréteur de commandes SSH :
yarn application -kill <application_id>
Par exemple :
yarn application -kill "application_1499348398273_0003"
Blocage en mode sans échec
Quand vous effectuez le scale-down d’un cluster, HDInsight utilise les interfaces de gestion d’Apache Ambari pour désactiver tout d’abord les nœuds Worker supplémentaires. Les nœuds répliquent leurs blocs HDFS vers d’autres nœuds Worker en ligne. Après cela, HDInsight met à l’échelle le cluster en toute sécurité. HDFS bascule en mode sans échec pendant l’opération de mise à l’échelle. HDFS est censée sortir du mode sans échec une fois la mise à l’échelle terminée. Dans certains cas, toutefois, HDFS se bloque en mode sans échec pendant une opération de mise à l’échelle en raison de la réplication incomplète du bloc de fichiers.
Par défaut, HDFS est configuré avec un paramètre dfs.replication de valeur 1, qui contrôle le nombre de copies disponibles de chaque bloc de fichiers. Chaque copie d’un bloc de fichiers est stockée sur un nœud différent du cluster.
Quand le nombre attendu de copies de bloc n’est pas disponible, HDFS bascule en mode sans échec et Ambari génère des alertes. HDFS peut basculer en mode sans échec pour une opération de mise à l’échelle. Le cluster risque d’être bloqué en mode sans échec si le nombre requis de nœuds n’est pas détecté pour la réplication.
Exemples d’erreurs lorsque le mode sécurisé est activé
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Vous pouvez examiner les journaux d’activité du nœud de nom dans le dossier /var/log/hadoop/hdfs/, aux alentours du moment où le cluster a été mis à l’échelle, pour voir quand il est entré en mode sans échec. Les fichiers journaux sont nommés Hadoop-hdfs-namenode-<active-headnode-name>.*.
La cause principale vient du fait que Hive dépend de fichiers temporaires dans HDFS lors de l’exécution des requêtes. Quand HDFS bascule en mode sans échec, Hive ne peut pas exécuter de requêtes car il ne peut pas écrire dans HDFS. Les fichiers temporaires dans HDFS se trouvent sur le lecteur local monté sur les différentes machines virtuelles du nœud Worker. Les fichiers sont répliqués parmi les autres nœuds Worker à trois réplicas, au minimum.
Guide pratique pour empêcher le blocage de HDInsight en mode sans échec
Il existe plusieurs façons d’empêcher HDInsight de rester en mode sans échec :
- Arrêter tous les travaux Hive avant la descente en puissance de HDInsight. Vous pouvez également planifier le processus de descente en puissance pour d’éviter tout conflit avec les travaux Hive en cours d’exécution.
- Nettoyer manuellement les fichiers du répertoire de travail temporaire
tmpHive dans HDFS avant la descente en puissance. - Effectuer uniquement la descente en puissance de HDInsight à au moins trois nœuds de travail. Éviter de descendre à un nœud de travail.
- Exécuter la commande pour quitter le mode sans échec, si nécessaire.
Les sections suivantes décrivent ces options.
Arrêter tous les travaux Hive
Arrêtez tous les travaux Hive avant la descente en puissance à un nœud de travail. Si votre charge de travail est planifiée, effectuez votre descente en puissance une fois travail Hive terminé.
L’arrêt des travaux Hive avant la mise à l’échelle permet de réduire le nombre de fichiers de travail dans le dossier temp (le cas échéant).
Nettoyer manuellement les fichiers de travail Hive
Si Hive a laissé des fichiers temporaires, vous pouvez nettoyer manuellement ces fichiers avant la descente en puissance pour éviter le mode sans échec.
Vérifiez l’emplacement utilisé pour les fichiers temporaires Hive en examinant la propriété de configuration
hive.exec.scratchdir. Ce paramètre est défini dans/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Arrêtez les services Hive et vérifiez que toutes les requêtes et tous les travaux sont terminés.
Dressez la liste du contenu du répertoire de travail
hdfs://mycluster/tmp/hive/trouvé ci-dessus pour voir s’il contient des fichiers :hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveS’il existe des fichiers, le résultat ressemble à ce qui suit :
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoSi vous savez que Hive a fini d’utiliser ces fichiers, vous pouvez les supprimer. Vérifiez que Hive ne contient aucune requête en cours d’exécution en consultant la page de l’interface utilisateur Yarn Resource Manager.
Exemple de ligne de commande pour supprimer des fichiers de HDFS :
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Mettre à l’échelle HDInsight vers trois nœuds Worker ou plus
Si vos clusters sont fréquemment bloqués en mode sans échec lors d’un scale-down à moins de trois nœuds Worker, conservez au moins trois nœuds Worker.
Avoir trois nœuds Worker est plus coûteux qu’effectuer un scale-down à un seul nœud Worker. Cependant, cette action empêche votre cluster de rester bloqué en mode sans échec.
Mettre à l’échelle HDInsight à un seul nœud Worker
Même quand le cluster est mis à l’échelle à un seul nœud, le nœud Worker 0 continue d’exister. Le nœud Worker 0 ne peut jamais être désactivé.
Exécuter la commande pour quitter le mode sans échec
La dernière option consiste à exécuter la commande pour quitter le mode sans échec. Si HDFS a basculé en mode sans échec en raison de la réplication incomplète des fichiers Hive, exécutez la commande suivante pour quitter le mode sans échec :
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Procéder au scale down d’un cluster Apache HBase
Les serveurs de région sont équilibrés automatiquement quelques minutes après la fin d’une opération de mise à l’échelle. Pour équilibrer manuellement les serveurs de région, procédez comme suit :
Connectez-vous au cluster HDInsight à l’aide de SSH : Pour en savoir plus, voir Utilisation de SSH avec Hadoop Linux sur HDInsight depuis Linux, Unix ou OS X.
Lancez l’interpréteur de commandes HBase :
hbase shellUtilisez la commande suivante pour équilibrer manuellement les serveurs de région :
balancer
Étapes suivantes
Pour obtenir des informations spécifiques sur la mise à l’échelle de votre cluster HDInsight, consultez :