Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le cluster Interactive Query (également appelé Apache Hive LLAP ou Low Latency Analytical Processing) est un type de cluster Azure HDInsight. Interactive Query prend en charge la mise en mémoire cache, ce qui accélère les requêtes Apache Hive et les rend beaucoup plus interactives. Les clients utilisent Interactive Query pour interroger des données stockées dans le stockage Azure et Azure Data Lake Storage de manière extrêmement rapide. Une requête interactive permet facilement aux développeurs et scientifiques des données de travailler avec des données volumineuses (big data) à l’aide des outils décisionnels qu’ils préfèrent. HDInsight Interactive Query prend en charge plusieurs outils pour accéder aux données volumineuses de façon facile.
Les clusters Interactive Query sont différents des clusters Apache Hadoop. Ils contiennent uniquement le service Hive.
Vous pouvez accéder au service Hive dans le cluster Interactive Query uniquement par le biais de la vue Apache Ambari Hive, de Beeline et du pilote ODBC Microsoft Hive. Vous ne pouvez pas y accéder via la console Hive, Templeton, Azure Classic CLI ou Azure PowerShell.
Créer un cluster Interactive Query
Pour obtenir des informations sur la création d’un cluster HDInsight, consultez Créer des clusters Apache Hadoop dans HDInsight. Choisissez le type de cluster Interactive Query.
Important
La taille minimale du nœud principal pour les clusters Interactive Query est Standard_D13_v2. Pour plus d’informations, consultez le Tableau de dimensionnement des machines virtuelles Azure.
Exécuter des requêtes Apache Hive à partir du cluster Interactive Query
Pour exécuter des requêtes Hive, vous disposez des options suivantes :
Pour rechercher la chaîne de connexion Java Database Connectivity (JDBC) :
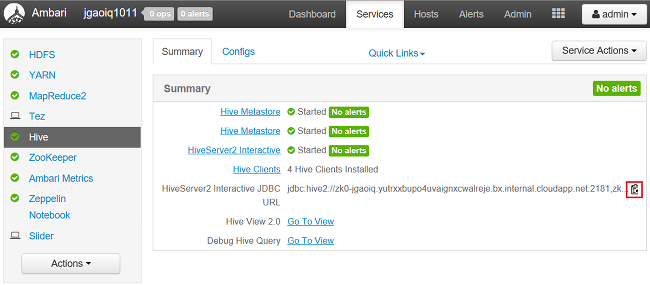
Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, oùCLUSTERNAMEest le nom de votre cluster.Pour copier l’URL, sélectionnez l’icône du Presse-papiers :
Étapes suivantes
- Découvrez comment créer des clusters Interactive Query dans HDInsight.
- Découvrez comment visualiser des Big Data à l’aide de Power BI dans Azure HDInsight.
- Découvrez comment utiliser Apache Zeppelin pour exécuter des requêtes Apache Hive dans Azure HDInsight.