MirrorMaker permet de répliquer des rubriques Apache Kafka avec Kafka sur HDInsight
Découvrez comment utiliser la fonctionnalité de mise en miroir d’Apache Kafka pour répliquer des rubriques sur un cluster secondaire. Vous pouvez exécuter la mise en miroir en tant que processus continu, ou par intermittence, pour migrer des données d’un cluster vers un autre.
Dans cet article, vous allez utiliser la mise en miroir pour répliquer des rubriques entre deux clusters HDInsight. Ces clusters se trouvent dans différents réseaux virtuels dans différents centres de données.
Avertissement
N’utilisez pas la mise en miroir comme moyen d’obtenir une tolérance aux pannes. Le décalage aux éléments d’un sujet diffère entre le cluster principal et le cluster secondaire : les clients ne peuvent donc pas utiliser indifféremment les deux. Si la tolérance de pannes vous préoccupe, définissez la réplication pour les sujets au sein de votre cluster. Pour plus d’informations, consultez Bien démarrer avec Apache Kafka sur HDInsight.
Fonctionnement de la mise en miroir Apache Kafka
La mise en miroir fonctionne à l’aide de l’outil MirrorMaker, qui fait partie de Apache Kafka. MirrorMaker consomme les enregistrements des rubriques du cluster principal, puis crée une copie locale sur le cluster secondaire. MirrorMaker utilise un (ou plusieurs) consommateurs qui lisent le cluster principal, ainsi qu’un producteur qui écrit dans le cluster local (secondaire).
Le programme de mise en miroir le plus utile en cas de récupération d'urgence utilise des clusters Kafka dans différentes régions Azure. Pour ce faire, les réseaux virtuels abritant les clusters sont appairés.
Le diagramme suivant illustre le processus de mise en miroir et le flux de communication entre les clusters :
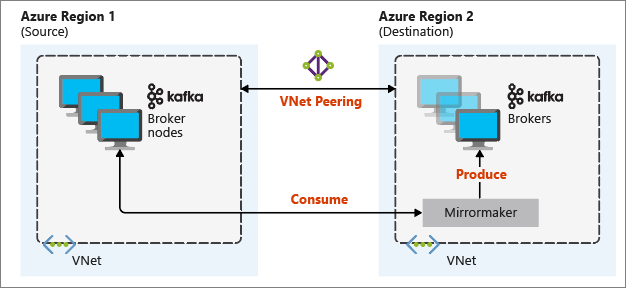
Le cluster principal et le cluster secondaire peuvent comporter un nombre différent de nœuds et de partitions, et les décalages dans les sujets ne sont pas forcément les mêmes. La mise en miroir conserve la valeur clé utilisée pour le partitionnement afin de préserver l’ordre d’enregistrement en fonction de la clé.
Mise en miroir au-delà des limites réseau
Si vous avez besoin d’effectuer une mise en miroir entre des clusters Kafka sur des réseaux différents, vous devez tenir compte des points suivants :
Passerelles : les réseaux doivent être capables de communiquer au niveau TCP/IP.
Adressage de serveur : Vous pouvez choisir d'adresser vos nœuds de cluster à l’aide de leurs adresses IP ou noms de domaine complets.
Adresses IP : Si vous configurez vos clusters Kafka pour la publication d'adresses IP, vous pouvez configurer la mise en miroir à l'aide des adresses IP des nœuds Broker et Zookeeper.
Noms de domaine : Si vous ne configurez pas vos clusters Kafka pour la publication d’adresses IP, vos clusters doivent pouvoir se connecter entre eux à l’aide de noms de domaine complets (FQDN). Cela implique la configuration d’un serveur DNS (Domain Name System) dans chaque réseau pour l’acheminement des demandes vers les autres réseaux. Lorsque vous créez un réseau virtuel Azure, au lieu d’utiliser le DNS automatique fourni avec le réseau, vous devez spécifier un serveur DNS personnalisé et l’adresse IP du serveur. Après avoir créé le réseau virtuel, vous devez créer une machine virtuelle Azure qui utilise cette adresse IP. Ensuite, vous installez et configurez le logiciel DNS.
Important
Créez et configurez le serveur DNS personnalisé avant d’installer HDInsight sur le réseau virtuel. Aucune configuration supplémentaire n’est requise pour HDInsight dans le cadre de l’utilisation du serveur DNS configuré pour le réseau virtuel.
Pour plus d’informations sur la connexion de deux réseaux virtuels Azure, consultez Configurer une connexion.
Architecture de mise en miroir
Cette architecture comporte deux clusters dans différents groupes de ressources et réseaux virtuels : un principal et un secondaire.
Étapes de création
Créez deux groupes de ressources :
Resource group Emplacement kafka-primary-rg USA Centre kafka-secondary-rg Centre-Nord des États-Unis Créez un réseau virtuel kafka-principal-vnet dans kafka-principal-rg. Conservez les paramètres par défaut.
Créez un réseau virtuel kafka-secondary-vnet dans kafka-secondary-rg, également avec les paramètres par défaut.
Créez deux nouveaux clusters Kafka :
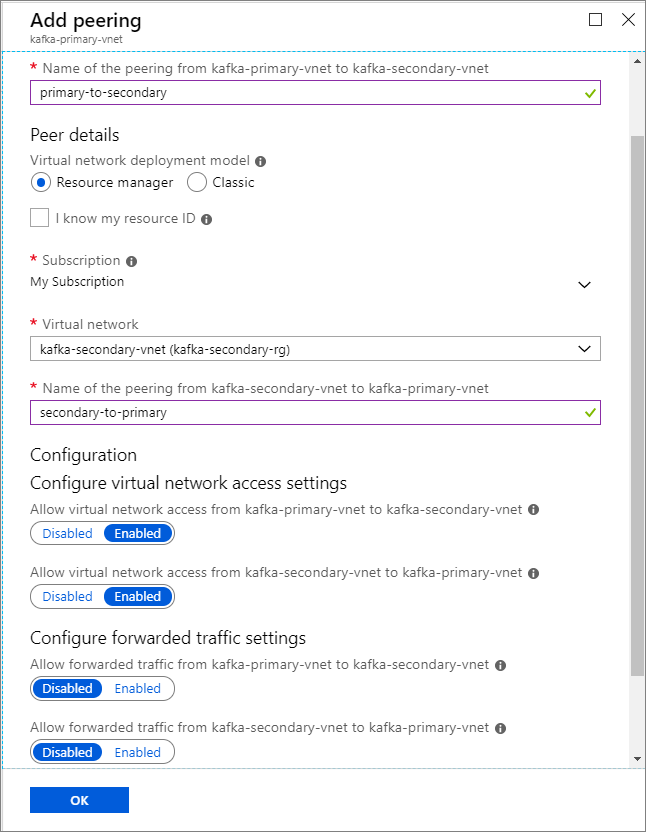
Nom du cluster Resource group Réseau virtuel Compte de stockage kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Créez des peerings de réseaux virtuels. Cette étape permet de créer deux peerings : un entre kafka-primary-vnet et kafka-secondary-vnet et un autre entre kafka-secondary-vnet et kafka-primary-vnet.
Sélectionnez le réseau virtuel kafka-primary-vnet.
Sous Paramètres, sélectionnez Peerings.
Sélectionnez Ajouter.
Dans l'écran Ajouter le peering, entrez les détails comme indiqué dans la capture d’écran suivant.
Configurer la publication d’adresses IP
Configurez la publication d’adresses IP pour permettre à un client de se connecter à l’aide des adresses IP du répartiteur plutôt que des noms de domaine.
Accédez au tableau de bord Ambari pour le cluster principal :
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Sélectionnez Services>Kafka. Sélectionnez l'onglet Configurations .
Ajoutez les lignes de configuration suivantes en bas de la section kafka-env template. Sélectionnez Enregistrer.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesEntrez une note dans l'écran Enregistrer la configuration, puis cliquez sur Enregistrer.
Si vous recevez un avertissement de configuration, sélectionnez Continuer quand même.
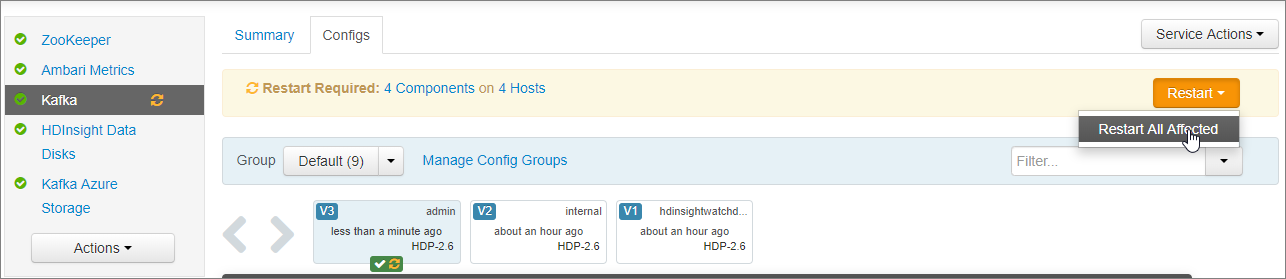
Sélectionnez OK dans Enregistrer les modifications de configuration.
Sélectionnez RedémarrerRedémarrer tous les éléments affectés> dans la notification Redémarrage requis. Sélectionnez ensuite Confirmer le redémarrage de tous.
Configurez Kafka de manière à écouter sur toutes les interfaces réseau
- Restez sur l'onglet Configurations sous Services>Kafka. Dans la section Kafka Broker, définissez la propriété listeners sur
PLAINTEXT://0.0.0.0:9092. - Sélectionnez Enregistrer.
- Sélectionnez Redémarrer, puis >Confirmer le redémarrage de tous.
Enregistrez les adresses IP Broker et Zookeeper pour le cluster principal
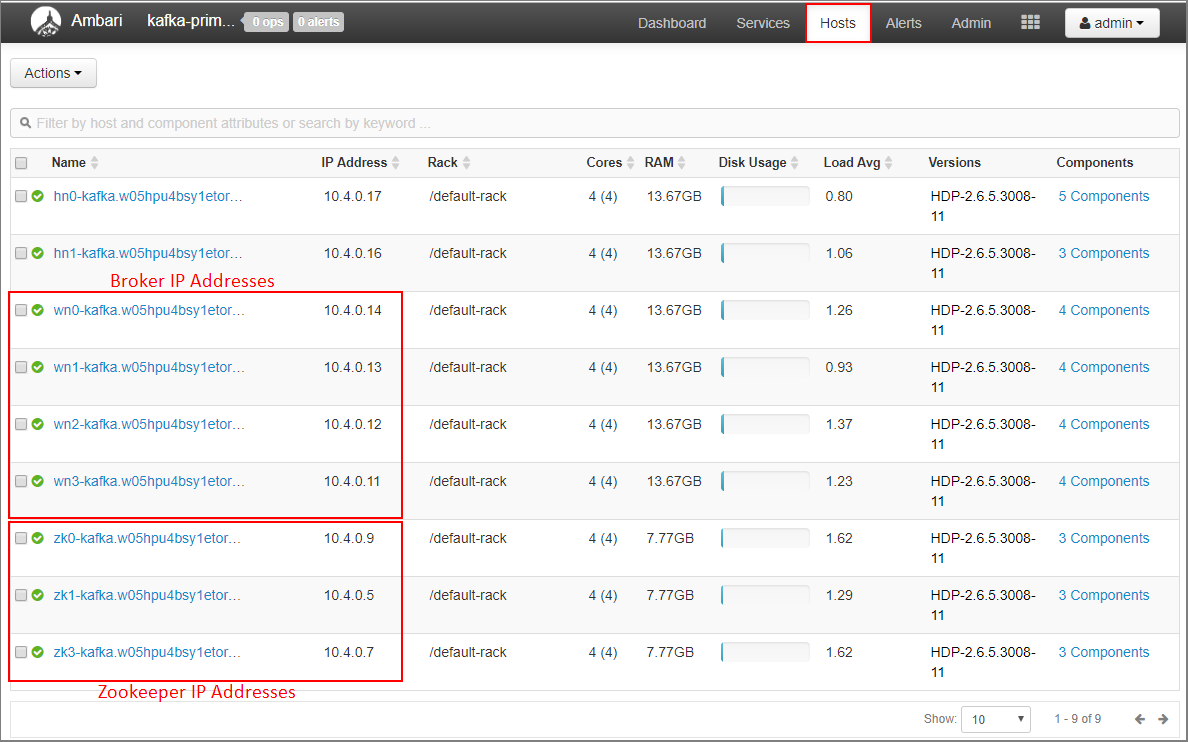
Sélectionnez Hôtes dans le tableau de bord Ambari.
Notez les adresses IP Broker et Zookeeper. Les nœuds Broker portent les deux premières lettres du nom d'hôte, wn, et les nœuds Zookeeper les deux premières lettres du nom d'hôte zk.
Répétez les trois étapes précédentes pour le deuxième cluster kafka-secondary-cluster : configurer la publication d’adresses IP, définissez listeners et notez les adresses IP Broker et Zookeeper.
Création de sujets
Connectez-vous au cluster principal à l'aide de SSH :
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netRemplacez
sshuserpar le nom d’utilisateur SSH que vous avez utilisé lors de la création du cluster. RemplacezPRIMARYCLUSTERpar le nom de base que vous avez utilisé lors de la création du cluster.Pour en savoir plus, voir Utilisation de SSH avec Hadoop Linux sur HDInsight depuis Linux, Unix ou OS X.
Utilisez la commande suivante pour créer deux variables d’environnement avec les hôtes Apache Zookeeper et les hôtes Broker pour le cluster principal. Les chaînes telles que
ZOOKEEPER_IP_ADDRESS1doivent être remplacées par les adresses IP réelles enregistrées précédemment, telles que10.23.0.11et10.23.0.7. Il en va de même pourBROKER_IP_ADDRESS1. Si vous utilisez la résolution de nom de domaine complet avec un serveur DNS personnalisé, suivez ces étapes pour obtenir les noms Broker et Zookeeper :# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Pour créer une rubrique nommée
testtopic, utilisez la commande suivante :/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSExécutez la commande suivante pour vérifier la création du sujet :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSLa réponse contient
testtopic.Utilisez la commande suivante afin d’afficher les informations des hôtes Broker pour ce cluster (qui est le cluster principal) :
echo $PRIMARY_BROKERHOSTSCette commande renvoie des informations semblables au texte suivant :
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Enregistrez ces informations. Elles seront utilisées dans la prochaine section.
Configuration de la mise en miroir
Connectez-vous au cluster secondaire à l’aide d’une autre session SSH :
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netRemplacez
sshuserpar le nom d’utilisateur SSH que vous avez utilisé lors de la création du cluster. RemplacezSECONDARYCLUSTERpar le nom que vous avez utilisé lors de la création du cluster.Pour en savoir plus, voir Utilisation de SSH avec Hadoop Linux sur HDInsight depuis Linux, Unix ou OS X.
Un fichier
consumer.propertiesest utilisé pour configurer la communication avec le cluster principal. Pour créer le fichier, utilisez la commande suivante :nano consumer.propertiesUtilisez les données suivantes comme contenu du fichier
consumer.properties:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupRemplacez
PRIMARY_BROKERHOSTSpar les adresses IP des hôtes Broker du cluster principal.Ce fichier détaille les informations de consommateur à utiliser lors de la lecture du cluster principal Kafka. Pour plus d’informations, consultez Configuration de consommateurs sur
kafka.apache.org.Pour enregistrer le fichier, appuyez sur Ctrl + X, sur Y puis sur Entrée.
Avant de configurer le producteur qui communique avec le cluster secondaire, définissez une variable pour les adresses IP Broker du cluster secondaire. Utilisez les commandes suivantes pour créer cette variable :
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'La commande
echo $SECONDARY_BROKERHOSTSdoit renvoyer des informations semblables aux informations suivantes :10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Un fichier
producer.propertiesest utilisé pour communiquer avec le cluster secondaire. Pour créer le fichier, utilisez la commande suivante :nano producer.propertiesUtilisez les données suivantes comme contenu du fichier
producer.properties:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneRemplacez
SECONDARY_BROKERHOSTSpar les adresses IP Broker utilisées à l’étape précédente.Pour plus d’informations, consultez Configuration producteurs sur
kafka.apache.org.Utilisez les commandes suivantes pour créer une variable d’environnement avec les adresses IP des hôtes Zookeeper pour le cluster secondaire :
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'La configuration par défaut pour Kafka sur HDInsight n’autorise pas la création automatique de rubriques. Vous devez utiliser une des options suivantes avant de commencer le processus de mise en miroir :
Créer les rubriques sur le cluster secondaire : cette option vous permet également de définir le nombre de partitions et le facteur de réplication.
Vous pouvez créer à l’avance les rubriques avec la commande suivante :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSRemplacez
testtopicpar le nom de la rubrique à créer.Configurer le cluster pour la création automatique de rubriques : cette option permet à MirrorMaker de créer automatiquement des rubriques. Notez qu’il peut les créer avec un nombre différent de partitions ou un facteur de réplication différent de celui de la rubrique principale.
Pour configurer le cluster secondaire afin de créer automatiquement des rubriques, procédez comme suit :
- Accédez au tableau de bord Ambari pour le cluster secondaire :
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Sélectionnez Services>Kafka. Sélectionnez l’onglet Configurations.
- Dans le champ Filter (Filtrer), entrez la valeur
auto.create. Cette option filtre la liste des propriétés et affiche le paramètreauto.create.topics.enable. - Remplacez la valeur de
auto.create.topics.enablepartrue, puis sélectionnez Save (Enregistrer). Ajoutez une note, puis sélectionnez à nouveau Save (Enregistrer). - Sélectionnez le service Kafka, choisissez Restart (Redémarrer), puis Restart all affected (Redémarrer tous les éléments affectés). Lorsque vous y êtes invité, sélectionnez Confirm Restart All (Confirmer le redémarrage).
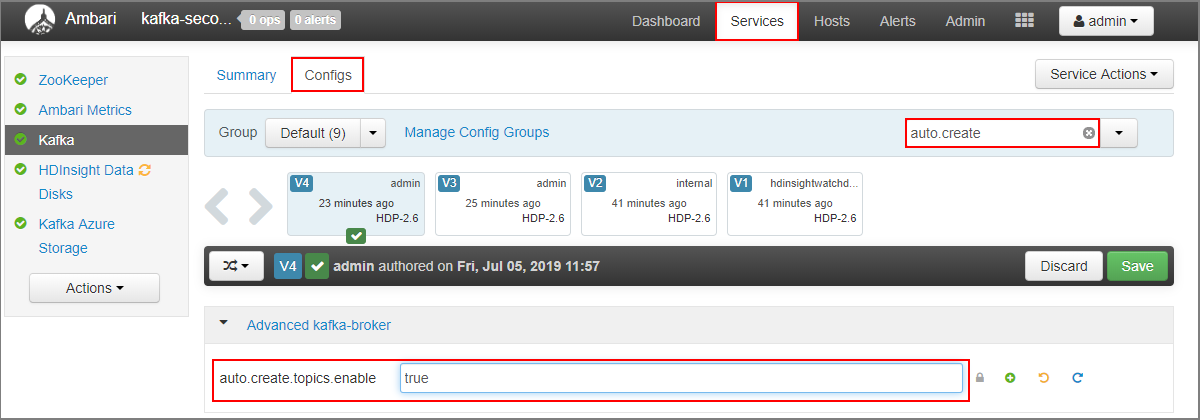
- Accédez au tableau de bord Ambari pour le cluster secondaire :
Lancement de MirrorMaker
Notes
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
À partir de la connexion SSH du cluster secondaire, utilisez la commande suivante pour lancer le processus MirrorMaker :
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Les paramètres utilisés dans cet exemple sont :
Paramètre Description --consumer.configspécifie le fichier qui contient les propriétés du consommateur. Ces propriétés permettent de créer un consommateur qui lit le cluster principal Kafka. --producer.configspécifie le fichier qui contient les propriétés du producteur. Ces propriétés permettent de créer un producteur qui écrit dans le cluster secondaire Kafka. --whitelistliste de sujets que MirrorMaker réplique, du cluster principal vers le cluster secondaire. --num.streamsnombre de threads de consommateur à créer. Le consommateur du nœud secondaire attend maintenant de recevoir des messages.
À partir de la connexion SSH au cluster principal, utilisez la commande suivante pour démarrer un producteur et envoyer des messages à la rubrique :
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicLorsque vous arrivez sur une ligne vide avec un curseur, tapez quelques messages texte. Les messages sont envoyés à la rubrique sur le cluster principal. Lorsque vous avez terminé, utilisez Ctrl + C pour terminer le processus de production.
À partir de la connexion SSH au cluster secondaire, utilisez Ctrl + C pour mettre fin au processus MirrorMaker. Plusieurs secondes peuvent être nécessaires pour terminer le processus. Pour vérifier que les messages ont été répliqués vers le cluster secondaire, utilisez la commande suivante :
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningLa liste des rubriques inclut désormais
testtopic, qui est créé lorsque MirrorMaster reflète la rubrique du cluster principal vers le cluster secondaire. Les messages récupérés de la rubrique sont les mêmes que ceux entrés dans le cluster principal.
Supprimer le cluster
Avertissement
La facturation des clusters HDInsight est calculée au prorata des minutes écoulées, que vous les utilisiez ou non. Veillez à supprimer votre cluster une fois que vous avez terminé de l’utiliser. Consultez Guide pratique pour supprimer un cluster HDInsight.
Les étapes décrites dans cet article ont permis de créer des clusters dans différents groupes de ressources Azure. Pour supprimer toutes les ressources créées, vous pouvez supprimer les deux groupes ressources créés : kafka-principal-rg et kafka-secondary_rg. La suppression de ces groupes de ressources supprime toutes les ressources créées par la suite dans cet article, y compris les clusters, réseaux virtuels et comptes de stockage.
Étapes suivantes
Dans cet article, vous avez appris à utiliser MirrorMaker pour créer un réplica d’un cluster Apache Kafka. Utilisez les liens suivants pour découvrir d’autres façons de travailler avec Kafka :