Tutoriel : Créer une application Scala Maven pour Apache Spark dans HDInsight à l’aide d’IntelliJ
Dans ce tutoriel, vous allez apprendre à créer une application Apache Spark écrite en Scala à l’aide d’Apache Maven avec IntelliJ IDEA. Dans cet article, Apache Maven est utilisé comme système de génération. Le document présente dans un premier temps un archétype Maven existant pour Scala fourni par IntelliJ IDEA. La création d’une application Scala avec IntelliJ IDEA implique les étapes suivantes :
- Utiliser Maven en tant que le système de génération.
- Mettre à jour le fichier de modèle objet du projet (POM) pour résoudre les dépendances de module Spark.
- Écrire votre application dans Scala.
- Générer un fichier jar qui peut être soumis à des clusters HDInsight Spark.
- Exécuter l’application à distance sur le cluster Spark à l’aide de Livy.
Dans ce tutoriel, vous allez apprendre à :
- Installer le plug-in Scala pour IntelliJ IDEA
- Utiliser IntelliJ pour développer une application Scala Maven
- Créer un programme Scala autonome
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
Le SDK Oracle Java. Ce tutoriel utilise Java version 8.0.202.
IDE Java. Cet article utilise IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Consultez Installation d’Azure Toolkit for IntelliJ.
Installer le plug-in Scala pour IntelliJ IDEA
Effectuez les étapes suivantes pour installer le plug-in Scala :
Ouvrez IntelliJ IDEA.
Dans l’écran d’accueil, accédez à Configure>Plugins (Configurer > Plug-ins) pour ouvrir la fenêtre Plugins (Plug-ins).
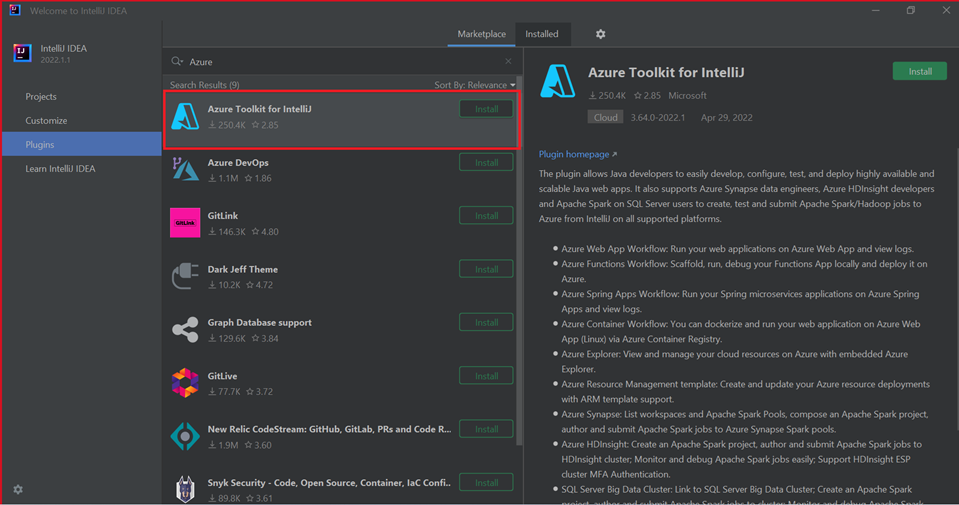
Sélectionnez Installer pour Azure Toolkit for IntelliJ.
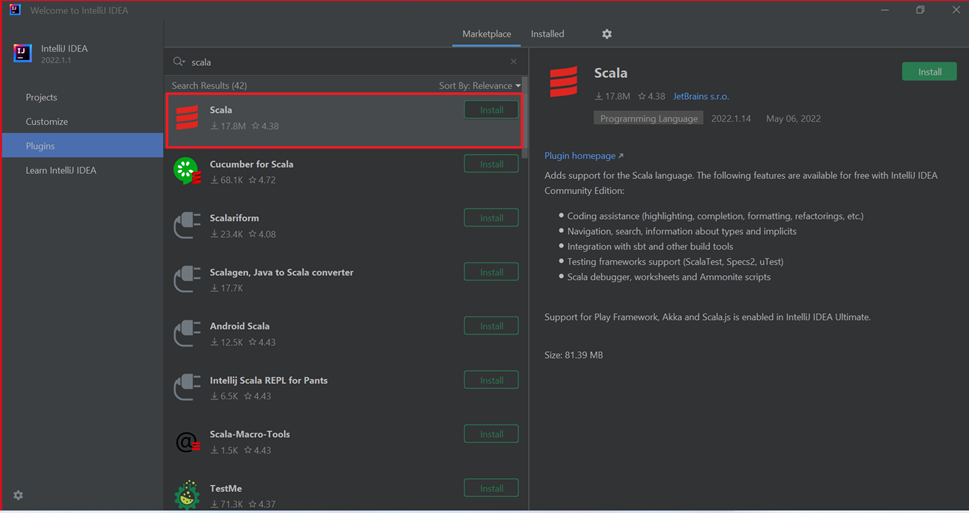
Sélectionnez Install (Installer) pour le plug-in Scala proposé dans la nouvelle fenêtre.
Une fois que le plug-in est bien installé, vous devez redémarrer l’IDE.
Utilisez IntelliJ pour créer l’application
Démarrez IntelliJ IDEA, puis sélectionnez Create New Project (Créer un projet) pour ouvrir la fenêtre New Project (Nouveau projet).
Sélectionnez Apache Spark/HDInsight dans le volet gauche.
Sélectionnez Spark Project (Scala) [Projet Spark (Scala)] dans la fenêtre principale.
Dans la liste déroulante Build tool (Outil de build), sélectionnez une des valeurs suivantes :
- Maven pour la prise en charge de l’Assistant de création de projets Scala.
- SBT pour gérer les dépendances et la génération du projet Scala.
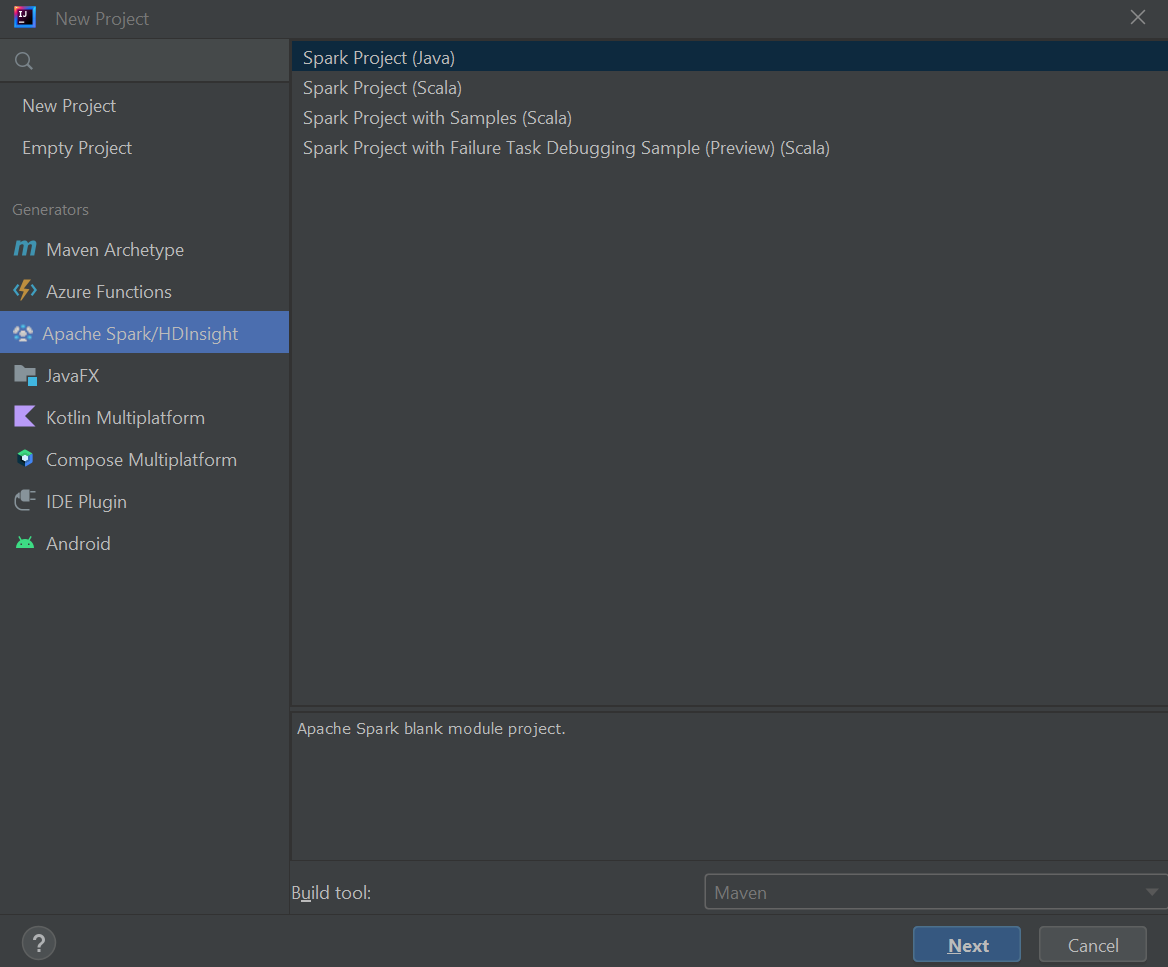
Cliquez sur Suivant.
Dans la fenêtre New Project (Nouveau projet), entrez les informations suivantes :
Propriété Description Nom du projet Entrez un nom. Emplacement du projet Entrez l’emplacement où enregistrer votre projet. Project SDK (SDK du projet) Ce champ est vide si vous utilisez IDEA pour la première fois. Sélectionnez New... (Nouveau) et accédez à votre JDK. Version de Spark L’Assistant de création intègre la version correcte des SDK Spark et Scala. Si la version du cluster Spark est antérieure à la version 2.0, sélectionnez Spark 1.x. Sinon, sélectionnez Spark 2.x. Cet exemple utilise Spark 2.3.0 (Scala 2.11.8) . 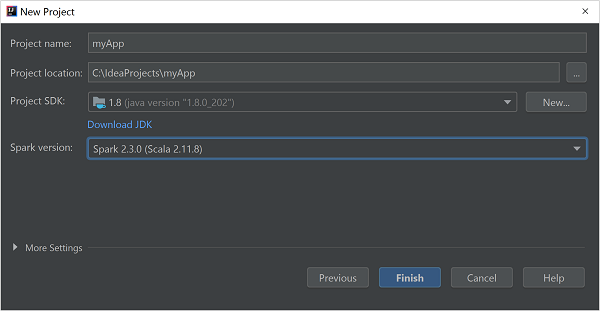
Sélectionnez Terminer.
Créer un programme Scala autonome
Démarrez IntelliJ IDEA, puis sélectionnez Create New Project (Créer un projet) pour ouvrir la fenêtre New Project (Nouveau projet).
Sélectionnez Maven dans le volet gauche.
Spécifiez un projet SDK. Si ce champ est vide, sélectionnez New... (Nouveau), puis accédez au répertoire d’installation de Java.
Cochez la case Create from archetype (Créer à partir d’un archétype).
Dans la liste des archétypes, sélectionnez
org.scala-tools.archetypes:scala-archetype-simple. Cet archétype crée la structure de répertoire appropriée et télécharge les dépendances par défaut requises pour écrire le programme Scala.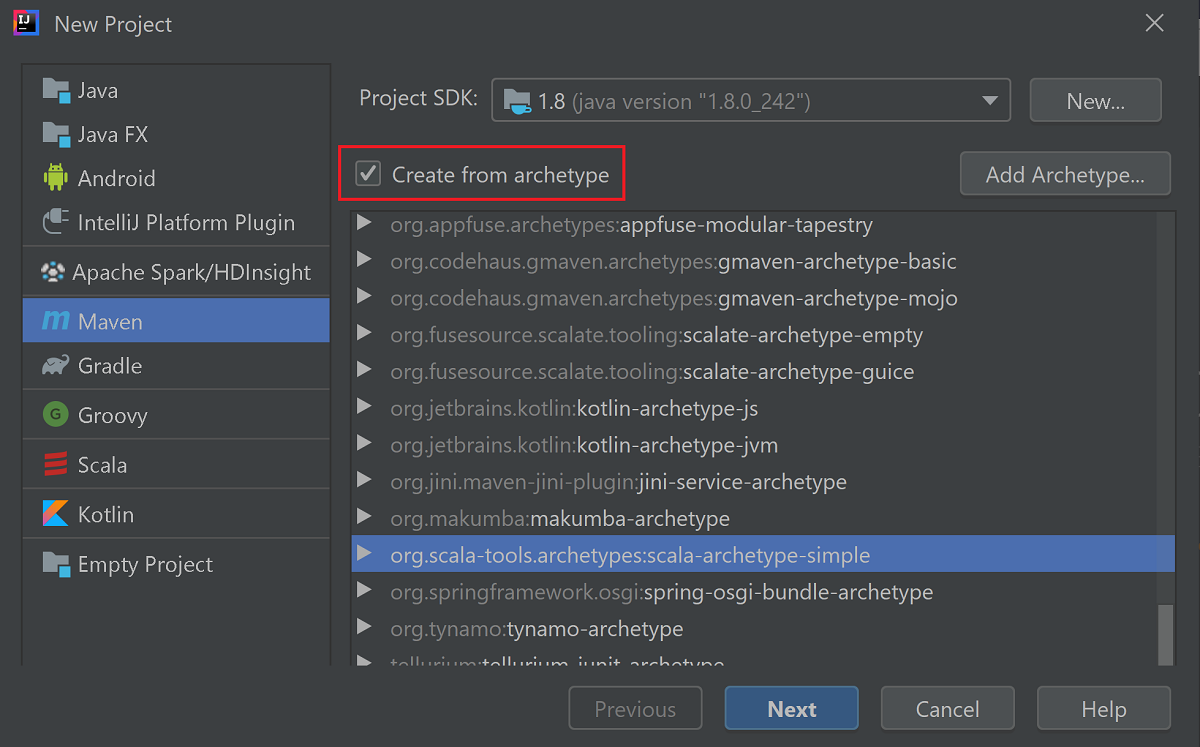
Cliquez sur Suivant.
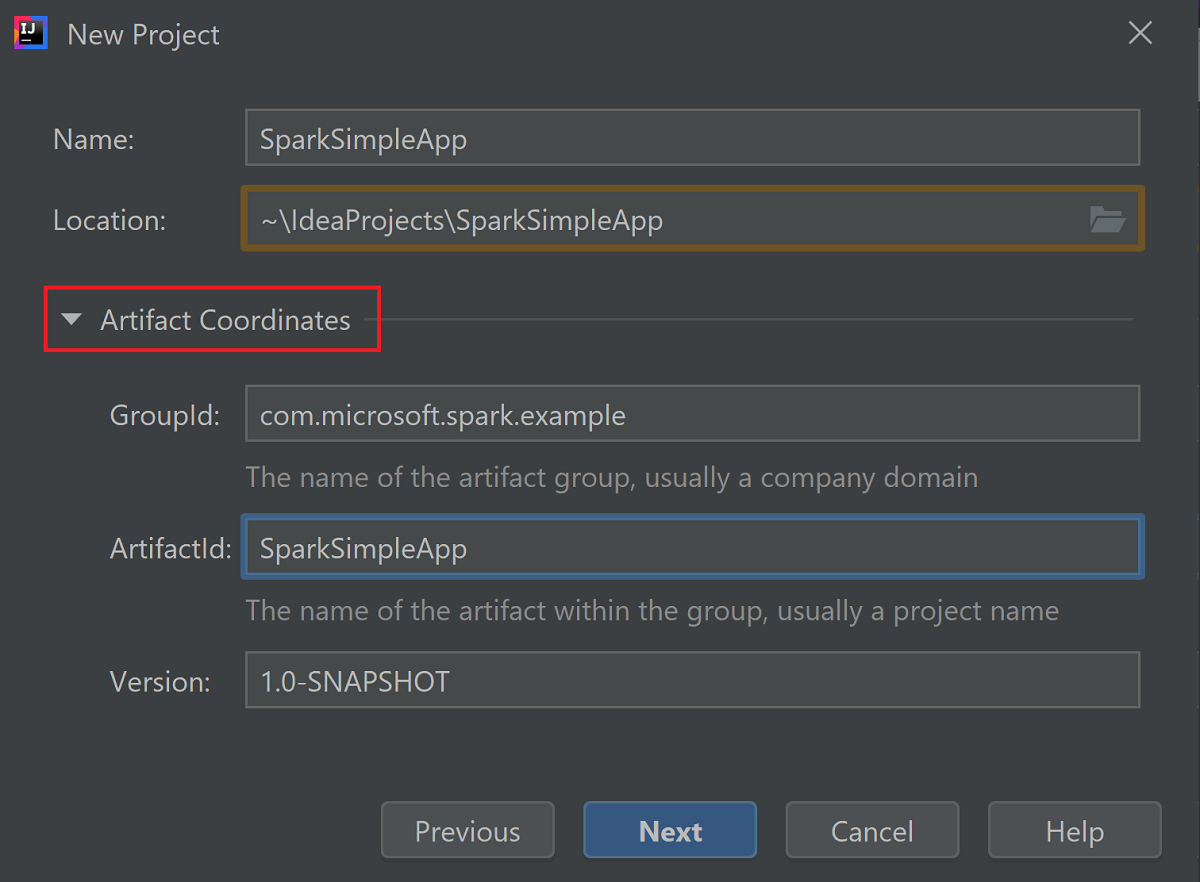
Développez Artifact Coordinates (Coordonnées d’artefact). Spécifiez les valeurs appropriées pour GroupId et ArtifactId. Nom et Emplacement sont renseignés automatiquement. Les valeurs suivantes sont utilisées dans ce didacticiel :
- GroupId : com.microsoft.spark.example
- ArtifactId : SparkSimpleApp
Cliquez sur Suivant.
Vérifiez les paramètres, puis sélectionnez Suivant.
Vérifiez le nom et l’emplacement du projet, puis sélectionnez Terminer. L’importation du projet prend quelques minutes.
Une fois que le projet a été importé, à partir du volet gauche, accédez à SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Cliquez avec le bouton droit sur MySpec, puis sélectionnez Delete... (Supprimer). Vous n’avez pas besoin de ce fichier pour l’application. Sélectionnez OK dans la boîte de dialogue.
Dans les étapes ultérieures, vous mettez à jour le fichier pom.xml pour définir les dépendances de l’application Spark Scala. Pour que ces dépendances soient téléchargées et résolues automatiquement, vous devez configurer Maven.
Dans le menu File (Fichier), sélectionnez Settings (Paramètres) pour ouvrir la fenêtre Settings (Paramètres).
Dans la fenêtre Settings (Paramètres), accédez à Build, Execution, Deployment>Build Tools>Maven>Importing (Build, Exécution, Déploiement > Outils de build > Maven >Importation).
Cochez la case Import Maven projects automatically (Importer les projets Maven automatiquement).
Sélectionnez Apply (Appliquer), puis OK. Vous revenez à la fenêtre du projet.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::À partir du volet gauche, accédez à src>main>scala>com.microsoft.spark.example, puis double-cliquez sur App pour ouvrir App.scala.
Remplacez le code existant par le code suivant et enregistrez les modifications. Ce code lit les données du fichier HVAC.csv (disponible sur tous les clusters HDInsight Spark). Récupère les lignes qui contiennent uniquement un chiffre dans la sixième colonne et écrit la sortie dans /HVACOut sous le conteneur de stockage par défaut du cluster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }Dans le volet gauche, double-cliquez sur pom.xml.
Ajoutez les segments suivants à
<project>\<properties>:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Ajoutez les segments suivants à
<project>\<dependencies>:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Créez le fichier .jar IntelliJ IDEA permet de créer le fichier JAR en tant qu’artefact d'un projet. Procédez comme suit.
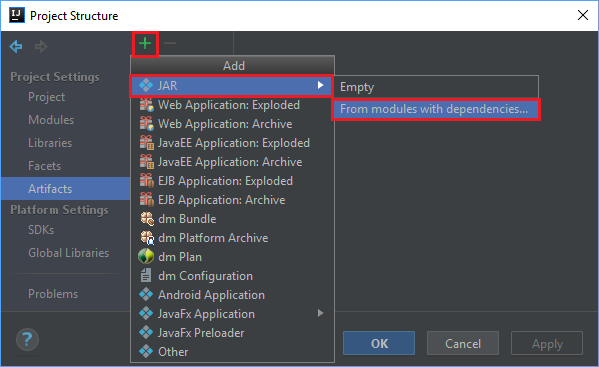
Dans le menu File (Fichier), sélectionnez Project Structure... (Structure du projet).
À partir de la fenêtre Project Structure (Structure du projet), accédez à Artifacts>le signe +>JAR>From modules with dependencies... (À partir de modules avec des dépendances).
Dans la fenêtre Create JAR from Modules (Créer un fichier JAR à partir de modules), sélectionnez l’icône de dossier dans la zone de texte Main Class (Classe principale).
Dans la fenêtre Select Main Class (Sélectionner une classe principale), sélectionnez la classe qui s’affiche par défaut, puis sélectionnez OK.
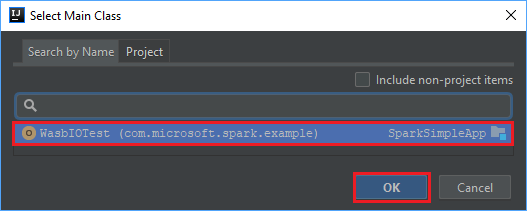
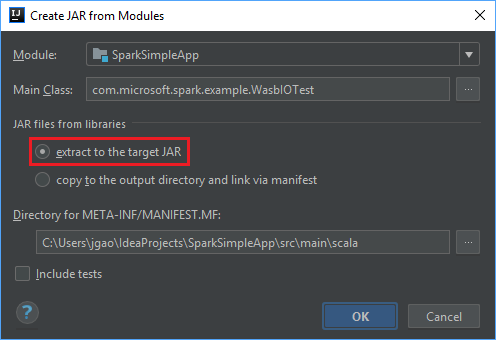
Dans la fenêtre Create JAR from Modules (Créer un fichier JAR à partir de modules), assurez-vous que l’option Extract to the target JAR (Extraire vers le fichier JAR cible) est sélectionnée, puis sélectionnez OK. Ce paramètre crée un fichier JAR unique contenant toutes les dépendances.
L’onglet Output Layout (Disposition de la sortie) répertorie tous les fichiers jar inclus dans le cadre du projet Maven. Vous pouvez sélectionner et supprimer ceux sur lesquels l’application Scala n’a aucune dépendance directe. Pour l’application que vous créez ici, vous pouvez tous les supprimer sauf le dernier (SparkSimpleApp compile output). Sélectionnez les fichiers JAR à supprimer, puis sélectionnez le signe moins - .
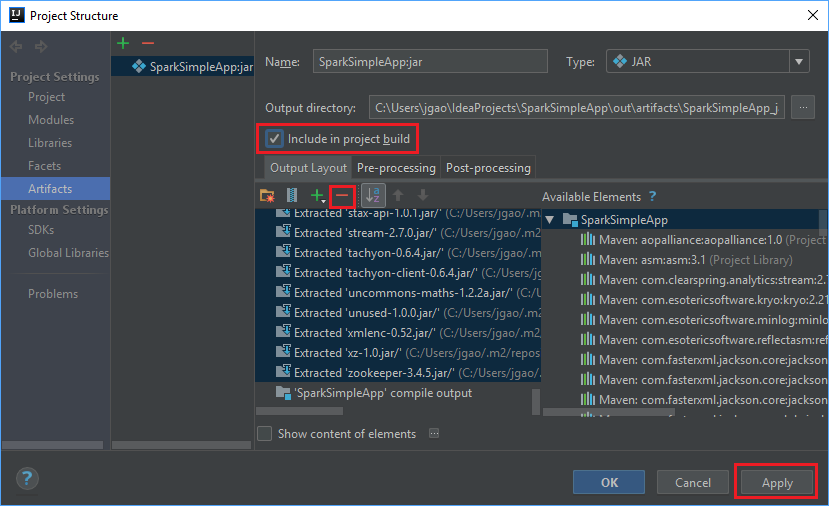
Vérifiez que la case Include in project build (Inclure dans la build du projet) est cochée. Cette option garantit la création du fichier jar lors de chaque génération ou mise à jour du projet. Sélectionnez Apply (Appliquer), puis OK.
Pour créer le fichier JAR, accédez à Build>Build Artifacts>Build (Build > Générer les artefacts > Générer). Le projet est compilé en 30 secondes environ. Le fichier JAR de sortie est créé sous \out\artifacts.
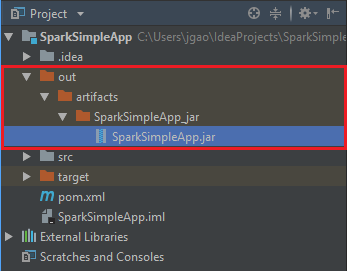
Exécuter l’application sur le cluster Apache Spark
Pour exécuter l’application sur le cluster, vous pouvez procéder comme suit :
Copiez le fichier jar de l’application sur l’objet blob de Stockage Azure associé au cluster. Pour ce faire, vous pouvez utiliser l’utilitaire en ligne de commande AzCopy. De nombreux autres clients permettent également de charger des données. Pour en savoir plus à leur sujet, consultez Chargement de données pour les tâches Apache Hadoop dans HDInsight.
Utilisez Apache Livy pour soumettre une tâche d’application à distance au cluster Spark. Les clusters Spark sur HDInsight incluent Livy qui expose des points de terminaison REST permettant d’envoyer à distance des travaux Spark. Pour plus d’informations, consultez Envoi de tâches Apache Spark à distance en utilisant Apache Livy avec les clusters Spark sur HDInsight.
Nettoyer les ressources
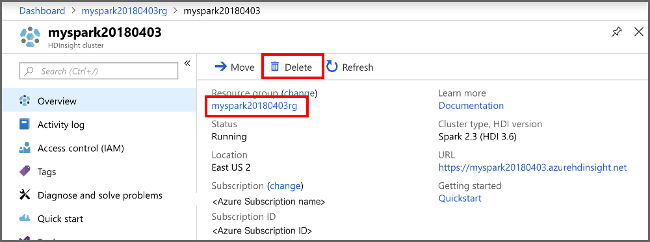
Si vous ne comptez pas continuer à utiliser cette application, effectuez les étapes suivantes pour supprimer le cluster que vous avez créé :
Connectez-vous au portail Azure.
Dans la zone Recherche située en haut, tapez HDInsight.
Sous Services, sélectionnez Clusters HDInsight.
Dans la liste des clusters HDInsight qui s’affiche, sélectionnez les points de suspension ... à côté du cluster que vous avez créé pour ce tutoriel.
Sélectionnez Supprimer. Sélectionnez Oui.
Étape suivante
Dans cet article, vous avez appris à créer une application Apache Spark Scala. Passez à l’article suivant pour savoir comment exécuter cette application sur un cluster HDInsight Spark en utilisant Livy.