Noyaux pour Jupyter Notebook sur les clusters Apache Spark dans Azure HDInsight
Les clusters Spark HDInsight fournissent des noyaux utilisables avec Jupyter Notebook sur Apache Spark pour tester des applications. Un noyau est un programme qui exécute et interprète votre code. Les trois noyaux sont les suivants :
- PySpark, pour les applications écrites en Python2. (Applicable uniquement pour les clusters de version Spark 2.4)
- PySpark3, pour les applications écrites en Python3.
- Spark, pour les applications écrites en Scala.
Dans cet article, vous allez apprendre à utiliser ces noyaux et découvrir les avantages de leur utilisation.
Prérequis
Un cluster Apache Spark dans HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
Créer un Jupyter Notebook sur Spark HDInsight
Dans le portail Azure, sélectionnez votre projet Spark. Pour obtenir des instructions, consultez la page Énumération et affichage des clusters. La page Vue d’ensemble s’ouvre.
Dans la zone Tableaux de bord du cluster de la page Vue d’ensemble, sélectionnez Jupyter Notebook. Si vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster.
Remarque
Vous pouvez également atteindre Jupyter Notebook sur le cluster Spark en ouvrant l’URL suivante dans votre navigateur. Remplacez CLUSTERNAME par le nom de votre cluster.
https://CLUSTERNAME.azurehdinsight.net/jupyterSélectionnez Nouveau, puis Pyspark, PySpark3 ou Spark pour créer un notebook. Utilisez le noyau Spark pour les applications Scala, le noyau PySpark pour les applications Python2 et le noyau PySpark3 pour les applications Python3.

Remarque
Pour Spark 3.1, seul PySpark3 ou Spark est disponible.
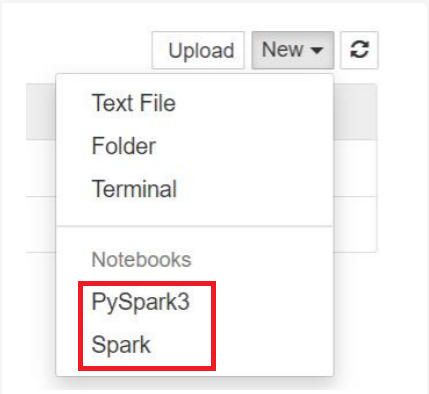
- Un bloc-notes s’ouvre avec le noyau que vous avez sélectionné.
Avantages de l’utilisation des noyaux
Voici quelques avantages liés à l’utilisation des nouveaux noyaux avec Jupyter Notebook sur des clusters Spark HDInsight.
Contextes prédéfinis. Avec les noyaux PySpark, PySpark3 ou Spark, vous n’avez pas besoin de définir les contextes Spark ou Hive explicitement avant de commencer à utiliser vos applications. Ces contextes sont disponibles par défaut. Ces contextes sont les suivants :
sc : pour le contexte Spark
sqlContext : pour le contexte Hive
Par conséquent, vous n’avez pas à exécuter d’instructions telles que les suivantes pour définir les contextes :
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)En revanche, vous pouvez utiliser directement les contextes prédéfinis dans votre application.
Commandes magiques de cellule. Le noyau PySpark fournit certaines « commandes magiques » prédéfinies, qui sont des commandes spéciales que vous pouvez appeler avec
%%(par exemple,%%MAGIC<args>). La commande magique doit se trouver au tout début d’une cellule de code et autoriser plusieurs lignes de contenu. Le mot magic doit être le premier mot de la cellule. Ajouter quoi que ce soit avant la commande magique, même des commentaires, provoque une erreur. Pour plus d’informations sur les commandes magiques, cliquez ici.Le tableau suivant répertorie les différentes commandes magiques disponibles par le biais des noyaux.
Commande magique Exemple Description help %%helpGénère une table de toutes les commandes magiques disponibles, accompagnées d’un exemple et d’une description info %%infoGénère des informations de session pour le point de terminaison Livy actuel CONFIGURER %%configure -f{"executorMemory": "1000M""executorCores": 4}Configure les paramètres de création d’une session. L’indicateur de forçage ( -f) est obligatoire si une session a déjà été créée, afin de garantir que la session est supprimée et recréée. Consultez la section POST /sessions Request Body de Livy pour obtenir la liste des paramètres valides. Les paramètres doivent être passés en tant que chaîne JSON et être spécifiés sur la ligne suivant la commande magique, comme indiqué dans l’exemple de colonne.sql %%sql -o <variable name>
SHOW TABLESExécute une requête Hive sur sqlContext. Si le paramètre -oest passé, le résultat de la requête est conservé dans le contexte Python %%local en tant que trame de données Pandas .local %%locala=1Tout le code dans les lignes suivantes est exécuté localement. Le code doit être un code Python2 valide, peu importe quel noyau vous utilisez. Donc, même si vous avez sélectionné les noyaux PySpark3 ou Spark en créant le notebook, si vous utilisez la commande magique %%localdans une cellule, cette cellule doit uniquement comporter un code Python2 valide.logs %%logsGénère les journaux d’activité de la session Livy en cours. supprimer %%delete -f -s <session number>Supprime une session spécifique du point de terminaison Livy actuel. Vous ne pouvez pas supprimer la session qui est démarrée pour le noyau lui-même. cleanup %%cleanup -fSupprime toutes les sessions pour le point de terminaison Livy actuel, y compris la session de ce bloc-notes. L’indicateur de forçage -f est obligatoire. Notes
Outre les commandes magiques ajoutées par le noyau PySpark, vous pouvez également utiliser les commandes magiques IPython intégrées, notamment
%%sh. Vous pouvez utiliser la commande magique%%shpour exécuter des scripts et des blocs de code sur le nœud principal du cluster.Visualisation automatique. Le noyau Pyspark visualise automatiquement la sortie des requêtes Hive et SQL. Vous pouvez choisir entre plusieurs types de visualisations, notamment tableau, secteurs, courbes, aires et barres.
Paramètres pris en charge avec la commande magique %%sql
La commande magique %%sql prend en charge différents paramètres qui vous permettent de contrôler le type de sortie que vous recevez quand vous exécutez des requêtes. Le tableau suivant répertorie les paramètres de sortie.
| Paramètre | Exemple | Description |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Utilisez ce paramètre pour conserver le résultat de la requête dans le contexte Python %%local en tant que trame de données Pandas . Le nom de la variable dataframe est le nom de variable que vous spécifiez. |
| -q | -q |
Utilisez ce paramètre pour désactiver les visualisations pour la cellule. Si vous ne voulez pas visualiser automatiquement le contenu d’une cellule et préférez simplement capturer le contenu comme une trame de données, utilisez -q -o <VARIABLE>. Si vous souhaitez désactiver les visualisations sans capturer les résultats (par exemple, pour exécuter une requête SQL, comme une instruction CREATE TABLE), utilisez -q sans spécifier d’argument -o. |
| -M | -m <METHOD> |
METHOD prend la valeur take ou sample (take est la valeur par défaut). Si la méthode est take , le noyau sélectionne des éléments à partir du haut du jeu de données de résultats spécifié par la valeur MAXROWS (décrite plus bas dans ce tableau). Si la méthode est sample, le noyau échantillonne de façon aléatoire les éléments du jeu de données en fonction du paramètre -r (décrit ci-après dans ce tableau). |
| -r | -r <FRACTION> |
Ici, FRACTION est un nombre à virgule flottante compris entre 0,0 et 1,0. Si l’exemple de méthode de la requête SQL est sample, le noyau échantillonne de façon aléatoire la fraction spécifiée des éléments du jeu de résultats. Par exemple, si vous exécutez une requête SQL avec les arguments -m sample -r 0.01, 1 % des lignes de résultat sont échantillonnées de façon aléatoire. |
| -n | -n <MAXROWS> |
MAXROWS est une valeur entière. Le noyau limite le nombre de lignes de la sortie au nombre défini par MAXROWS. Si MAXROWS est un nombre négatif comme -1, le nombre de lignes dans le jeu de résultats n’est pas limité. |
Exemple :
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
L’instruction ci-dessus effectue les actions suivantes :
- Elle sélectionne tous les enregistrements présents dans hivesampletable.
- Comme nous utilisons le paramètre -q, elle désactive la visualisation automatique.
- Comme nous utilisons
-m sample -r 0.1 -n 500, elle échantillonne de façon aléatoire 10 % des lignes présentes dans hivesampletable et limite la taille du jeu de résultats à 500 lignes. - Enfin, comme nous avons utilisé
-o query2, elle enregistre également la sortie dans une trame de données appelée query2.
Points à prendre en compte lors de l'utilisation des nouveaux noyaux
Quel que soit le noyau que vous utilisez, laisser les blocs-notes s’exécuter consomme vos ressources de cluster. Étant donné que les contextes sont prédéfinis, le simple fait de quitter les notebooks avec ces noyaux n’arrête pas le contexte. Par conséquent, les ressources du cluster restent en cours d’utilisation. Une bonne pratique consiste à utiliser l’option Fermer et arrêter à partir du menu Fichier du notebook lorsque vous avez fini d’utiliser le notebook. Cette fermeture supprime le contexte puis ferme le bloc-notes.
Où sont stockés les blocs-notes ?
Si votre cluster utilise le stockage Azure comme compte de stockage par défaut, les notebooks Jupyter Notebook sont enregistrés dans le compte de stockage sous le dossier /HdiNotebooks. Les blocs-notes, les fichiers texte et les dossiers que vous créez dans Jupyter sont accessibles à partir du compte de stockage. Par exemple, si vous utilisez Jupyter pour créer un dossier myfolder et un notebook myfolder/mynotebook.ipynb, vous pouvez accéder à ce notebook dans /HdiNotebooks/myfolder/mynotebook.ipynb au sein du compte de stockage. L’inverse est également vrai : si vous chargez un bloc-notes directement dans votre compte de stockage dans /HdiNotebooks/mynotebook1.ipynb, le bloc-notes est également accessible à partir de Jupyter. Les blocs-notes sont conservés dans le compte de stockage même après la suppression du cluster.
Notes
Les clusters HDInsight utilisant Azure Data Lake Storage comme stockage par défaut ne stockent pas les bloc-notes dans le stockage associé.
Les blocs-notes sont enregistrés dans le compte de stockage dans un mode compatible avec Apache Hadoop HDFS. Si vous utilisez SSH dans le cluster, vous pouvez exécuter des commandes de gestion des fichiers :
| Commande | Description |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Répertorier tous les éléments du répertoire racine : tout ce qui se trouve dans ce répertoire est visible pour Jupyter à partir de la page d’accueil |
hdfs dfs –copyToLocal /HdiNotebooks |
# Télécharger le contenu du dossier HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Télécharger un bloc-notes exemple. ipynb dans le dossier racine afin qu’il soit visible à partir de Jupyter |
Que le cluster utilise le stockage Azure ou Azure Data Lake Storage comme compte de stockage par défaut, les blocs-notes sont aussi enregistrés sur le nœud principal du cluster à l’emplacement /var/lib/jupyter.
Navigateur pris en charge
Les notebooks Jupyter Notebook sur clusters Spark HDInsight sont pris en charge uniquement sur Google Chrome.
Suggestions
Les nouveaux noyaux sont en phase d’évolution et gagneront en maturité avec le temps. Les API pourront donc évoluer au fur et à mesure des évolutions des noyaux. Nous aimerions recevoir vos commentaires concernant l'utilisation de ces nouveaux noyaux. Ce retour nous est utile pour préparer la version finale de ces noyaux. Vous pouvez laisser vos commentaires dans la section Commentaires en bas de cet article.
Étapes suivantes
- Vue d’ensemble : Apache Spark sur Azure HDInsight
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)