Gérer en toute sécurité l’environnement Python sur Azure HDInsight avec une action de script
HDInsight dispose de deux installations Python intégrées dans le cluster Spark, Anaconda Python 2.7 et Python 3.5. Les clients peuvent avoir besoin de personnaliser l’environnement Python, par exemple en installant des packages Python externes. Nous décrivons ici la meilleure pratique de gestion sûre d’environnements Python pour des clusters Apache Spark sur HDInsight.
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight. Si vous n’avez pas encore de cluster Spark sur HDInsight, vous pouvez exécuter des actions de script lors de la création du cluster. Consultez la documentation sur Guide d’utilisation des actions de script personnalisées.
Prise en charge des logiciels open source utilisés sur les clusters HDInsight
Le service Microsoft Azure HDInsight utilise un environnement de technologies open source formées autour d’Apache Hadoop. Microsoft Azure fournit un niveau général de prise en charge pour les technologies open source. Pour plus d’informations, voir le Site web de la FAQ du support Azure. Le service HDInsight fournit un niveau supplémentaire de prise en charge pour les composants intégrés.
Deux types de composant open source sont disponibles dans le service HDInsight :
| Composant | Description |
|---|---|
| Intégré | Ces composants sont préinstallés sur les clusters HDInsight et fournissent les fonctionnalités principales du cluster. Par exemple, Apache Hadoop YARN ResourceManager, le langage de requête Apache Hive (HiveQL) et la bibliothèque Mahout appartiennent à cette catégorie. La liste complète des composants de cluster est disponible dans la page Nouveautés des versions de cluster Apache Hadoop fournies par HDInsight. |
| Custom | En tant qu’utilisateur du cluster, vous pouvez installer ou utiliser dans votre charge de travail tout composant qui est disponible dans la communauté ou que vous avez créé. |
Important
Les composants fournis avec le cluster HDInsight sont entièrement pris en charge. Le support Microsoft vous aide à isoler et à résoudre les problèmes liés à ces composants.
Les composants personnalisés bénéficient d’un support commercialement raisonnable pour vous aider à résoudre le problème. La prise en charge de Microsoft peut être en mesure de résoudre le problème, SINON vous pourrez avoir besoin d’associer les chaînes disponibles pour les technologies open source lorsqu’il est possible de recourir à une expertise reconnue concernant cette technologie. Il existe par exemple de nombreux sites communautaires qu’il est possible d’utiliser, comme : Page de questions Microsoft Q&A sur HDInsight, https://stackoverflow.com. Par ailleurs, des projets Apache ont des sites de projet sur https://apache.org.
Présentation de l’installation par défaut de Python
Anaconda est installé sur les clusters HDInsight Spark. Il existe deux installations Python dans le cluster : Anaconda Python 2.7 et Python 3.5. Le tableau suivant présente les paramètres Python par défaut pour Spark, Livy et Jupyter.
| Setting | Python 2.7 | Python 3.5 |
|---|---|---|
| Path | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Version de Spark | Défini par défaut sur 2.7 | Peut remplacer la configuration par 3.5 |
| Version de Livy | Défini par défaut sur 2.7 | Peut remplacer la configuration par 3.5 |
| Jupyter | Noyau PySpark | Noyau PySpark3 |
Pour la version Spark 3.1.2, le noyau Apache PySpark est supprimé et un nouvel environnement Python 3.8 est installé sous /usr/bin/miniforge/envs/py38/bin, qui est utilisé par le noyau PySpark3. Les variables d’environnement PYSPARK_PYTHON et PYSPARK3_PYTHON sont mises à jour avec les éléments suivants :
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Installer en toute sécurité des packages Python externes
Le cluster HDInsight dépend de l’environnement Python intégré, Python 2.7 et Python 3.5. L’installation directe de packages personnalisés dans ces environnements intégrés par défaut peut entraîner des modifications inattendues de la version de la bibliothèque. Et endommager davantage le cluster. Pour installer en toute sécurité des packages Python externes personnalisés pour vos applications Spark, suivez les étapes suivantes.
Créez un environnement virtuel Python à l’aide de Conda. Un environnement virtuel fournit un espace isolé pour vos projets sans interrompre les autres. Lorsque vous créez l’environnement virtuel Python, vous pouvez spécifier la version de Python que vous souhaitez utiliser. Vous devez toujours créer un environnement virtuel, même si vous souhaitez utiliser Python 2.7 et 3.5. Cette exigence permet de s’assurer que l’environnement par défaut du cluster n’est pas endommagé. Exécutez des actions de script sur votre cluster pour tous les nœuds avec le script suivant pour créer un environnement virtuel Python.
--prefixspécifie un chemin d’accès à l’emplacement d’un environnement virtuel Conda. Plusieurs configurations doivent être modifiées en fonction du chemin d’accès spécifié ici. Dans cet exemple, nous utilisons py35new, car le cluster a déjà un environnement virtuel nommé PY35.python=spécifie la version de Python pour l’environnement virtuel. Dans cet exemple, nous utilisons la version 3.5, car elle est déjà intégrée au cluster. Vous pouvez également utiliser d’autres versions de Python pour créer l’environnement virtuel.anacondaspécifie le package_spec en tant qu’anaconda pour installer les packages Anaconda dans l’environnement virtuel.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesInstallez des packages Python externes dans l’environnement virtuel créé, si nécessaire. Exécutez des actions de script sur votre cluster pour tous les nœuds avec le script suivant pour installer des packages Python externes. Vous devez disposer du privilège sudo ici pour pouvoir écrire des fichiers dans le dossier de l’environnement virtuel.
Recherchez dans l’index des packages pour obtenir la liste complète des packages disponibles. Vous pouvez également obtenir une liste des packages disponibles à partir d’autres sources. Par exemple, vous pouvez installer les packages mis à disposition via conda-forge.
Utilisez la commande suivante si vous souhaitez installer une bibliothèque avec sa dernière version :
Utilisez le canal Conda :
seabornest le nom du package que vous souhaitez installer.-n py35newspécifie le nom de l’environnement virtuel qui vient d’être créé. Veillez à modifier le nom correspondant en fonction de la création de votre environnement virtuel.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesOu utilisez le référentiel PyPi, et modifiez
seabornetpy35newen conséquence :sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Utilisez la commande suivante si vous souhaitez installer une bibliothèque avec une version spécifique :
Utilisez le canal Conda :
numpy=1.16.1représente le nom du package et la version que vous souhaitez installer.-n py35newspécifie le nom de l’environnement virtuel qui vient d’être créé. Veillez à modifier le nom correspondant en fonction de la création de votre environnement virtuel.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesOu utilisez le référentiel PyPi, et modifiez
numpy==1.16.1etpy35newen conséquence :sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Si vous ne connaissez pas le nom de l’environnement virtuel, vous pouvez utiliser SSH pour accéder au nœud principal du cluster et exécuter
/usr/bin/anaconda/bin/conda info -epour afficher tous les environnements virtuels.Modifiez les configurations Spark et Livy et pointez sur l’environnement virtuel créé.
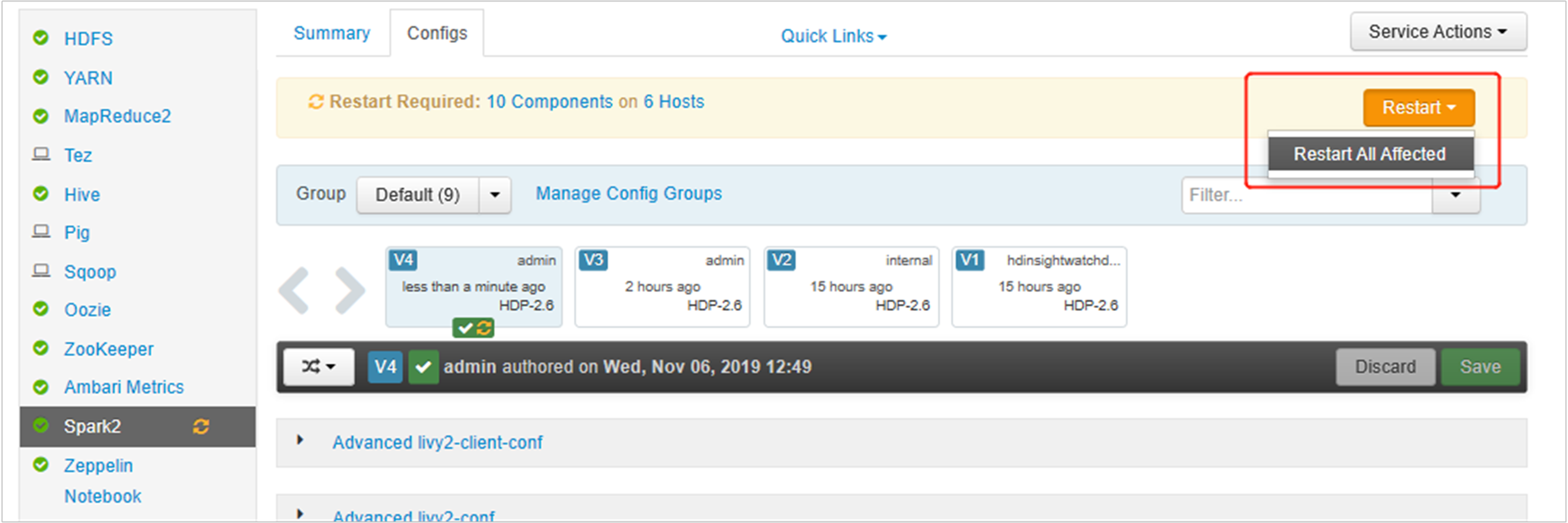
Ouvrez l’interface utilisateur Ambari, accédez à la page Spark 2, onglet Configurations.
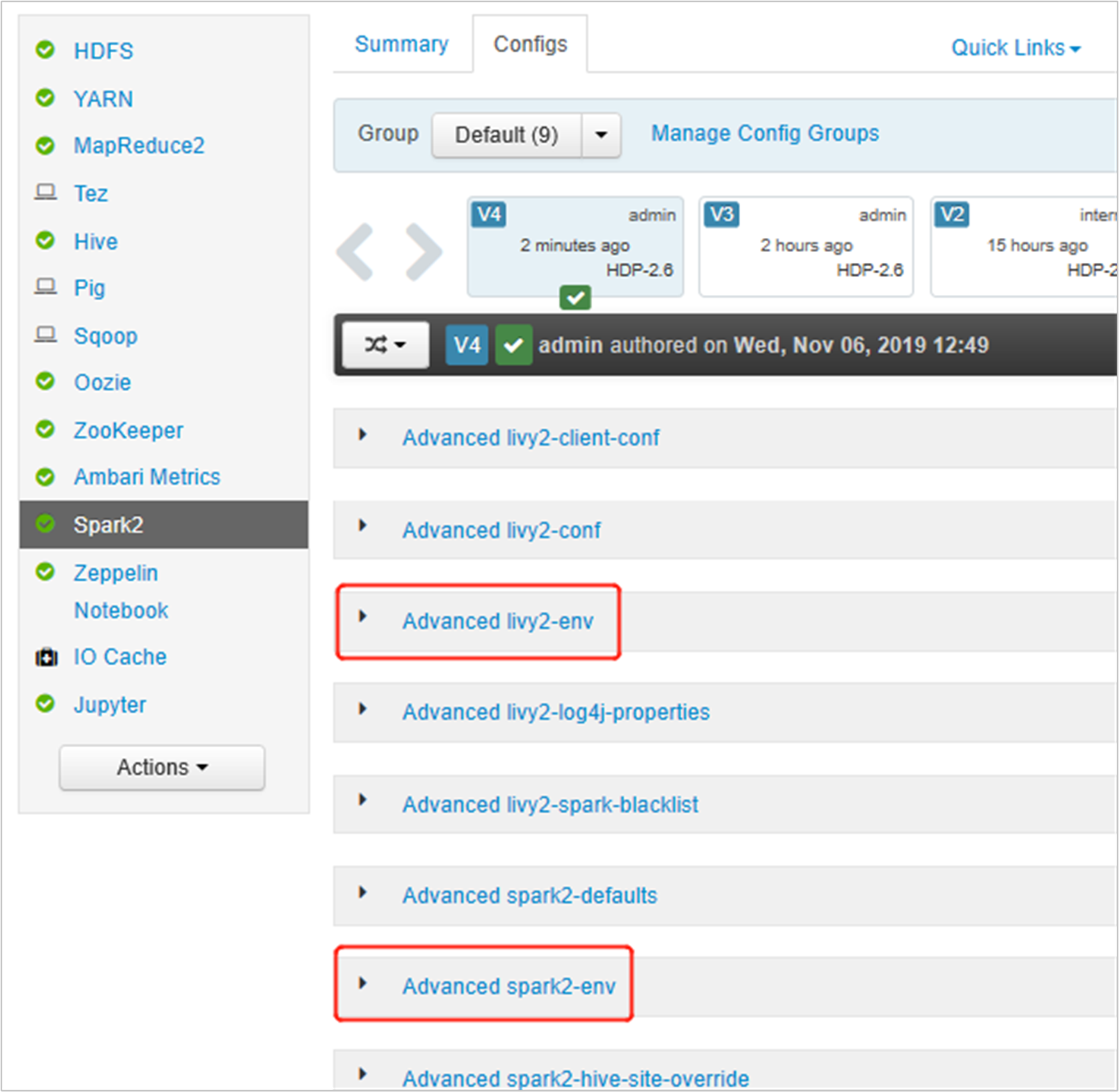
Développez Advanced livy2-env, puis ajoutez les instructions suivantes en bas. Si vous avez installé l’environnement virtuel avec un préfixe différent, modifiez le chemin d’accès correspondant.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python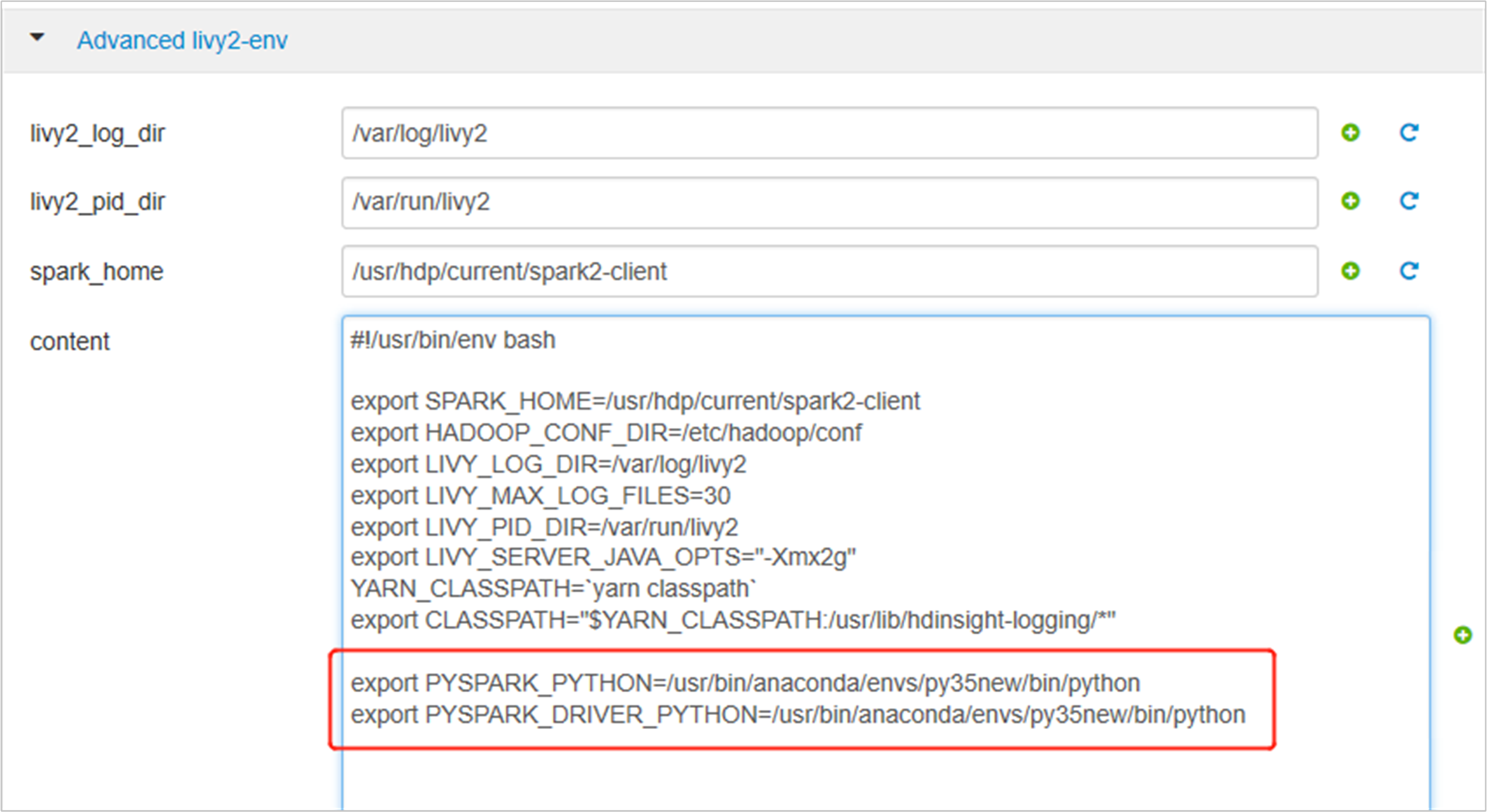
Développez spark2-env Avancé, remplacez l’instruction export PYSPARK_PYTHON existante en bas. Si vous avez installé l’environnement virtuel avec un préfixe différent, modifiez le chemin d’accès correspondant.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}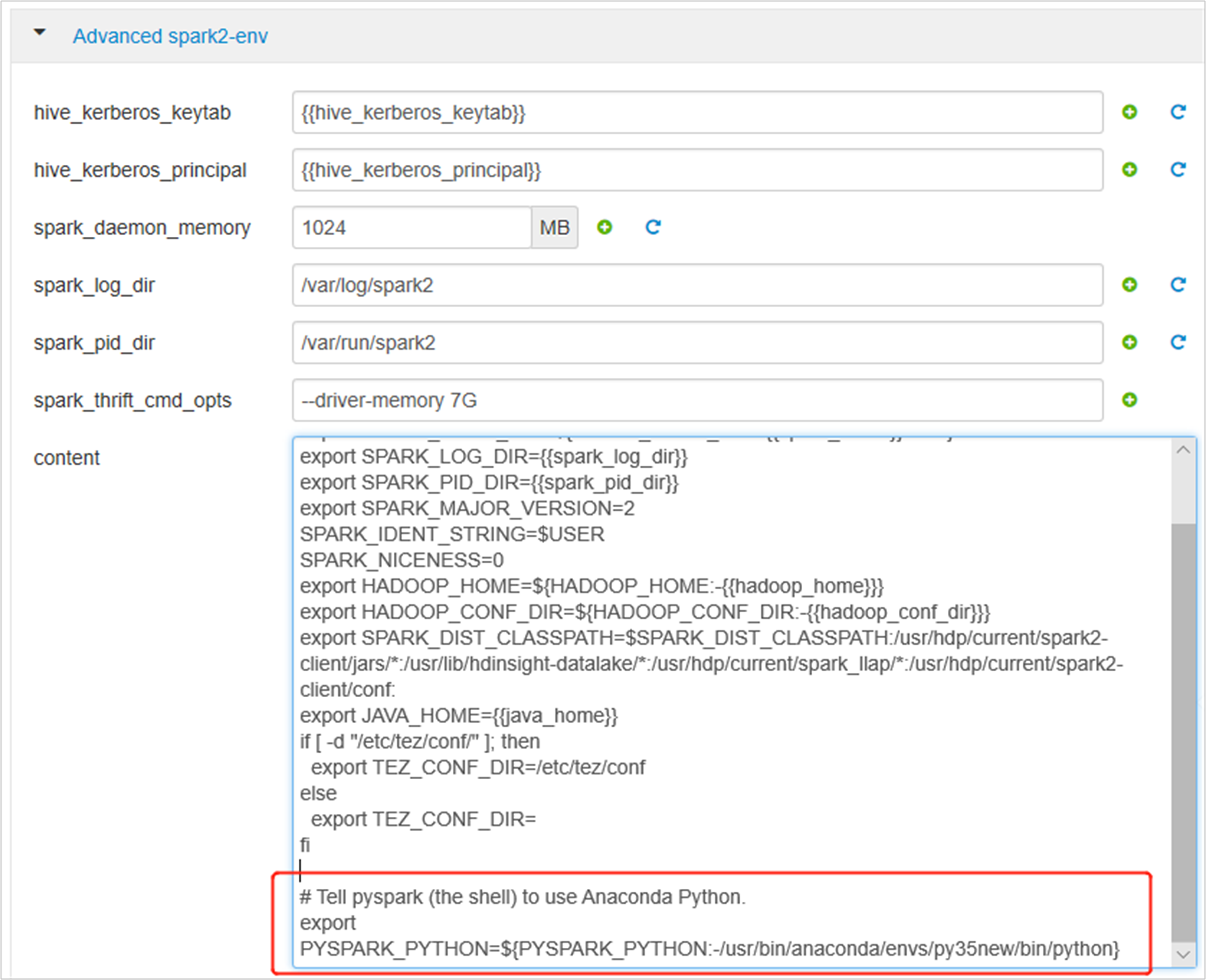
Enregistrez les modifications, puis redémarrez les services affectés. Ces modifications nécessitent un redémarrage du service Spark 2. L’interface utilisateur Ambari affiche un rappel de redémarrage obligatoire. Cliquez sur Redémarrer pour redémarrer tous les services affectés.
Définissez deux propriétés sur votre session Spark pour vous assurer que le travail pointe vers la configuration Spark mise à jour :
spark.yarn.appMasterEnv.PYSPARK_PYTHONetspark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.À l’aide du terminal ou d’un notebook, utilisez la fonction
spark.conf.set.spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Si vous utilisez
livy, ajoutez les propriétés suivantes au corps de la demande :"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Si vous souhaitez utiliser le nouvel environnement virtuel créé sur Jupyter. Modifiez les configurations Jupyter et redémarrez Jupyter. Exécutez des actions de script sur tous les nœuds d’en-tête avec l’instruction suivante pour associer Jupyter au nouvel environnement virtuel créé. Veillez à modifier le chemin d’accès au préfixe que vous avez spécifié pour votre environnement virtuel. Après l’exécution de cette action de script, redémarrez le service Jupyter via l’interface utilisateur Ambari pour rendre cette modification disponible.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonVous pouvez confirmer deux fois l’environnement Python dans Jupyter Notebook en exécutant le code :