Configurer des stratégies Apache Ranger pour Spark SQL dans HDInsight avec le Pack Sécurité Entreprise
Cet article explique comment configurer des stratégies Apache Ranger pour Spark SQL avec le Pack Sécurité Entreprise dans HDInsight.
Dans cet article, vous apprendrez comment :
- Créer des stratégies Apache Ranger.
- Vérifier les stratégies Ranger appliquées.
- Appliquer les instructions pour définir Apache Ranger pour Spark SQL.
Prérequis
- Un cluster Apache Spark dans HDInsight version 5.1 avec le Pack Sécurité Entreprise
Se connecter à l’interface utilisateur d’administration Apache Ranger
À partir d’un navigateur, connectez-vous à l’interface utilisateur d’administration Ranger avec l’URL
https://ClusterName.azurehdinsight.net/Ranger/.Remplacez
ClusterNamepar le nom de votre cluster Spark.Connectez-vous avec vos informations d’identification d’administrateur Microsoft Entra. Les informations d’identification d’administrateur Microsoft Entra ne sont pas les mêmes que les informations d’identification du cluster HDInsight ou que les informations d’identification Secure Shell (SSH) du nœud HDInsight Linux.

Créer des utilisateurs du domaine
Pour plus d’informations sur la création d’utilisateurs de domaine sparkuser, consultez Créer un cluster HDInsight avec ESP. Dans un scénario de production, les utilisateurs de domaine viennent de votre locataire Microsoft Entra.
Créer une stratégie Ranger
Dans cette section, vous créez deux stratégies Ranger :
- Une stratégie d’accès pour accéder à
hivesampletableà partir de Spark SQL - Une stratégie de masquage pour obscurcir les colonnes dans
hivesampletable
Créer une stratégie d’accès Ranger
Ouvrez l’interface utilisateur d’administration Ranger.
Sous HADOOP SQL, sélectionnez hive_and_spark.
Sous l’onglet Accès, sélectionnez Ajouter une nouvelle stratégie.

Saisissez les valeurs suivantes :
Propriété Valeur Nom de la stratégie read-hivesampletable-all database default table hivesampletable N° * Sélectionner un utilisateur sparkuserAutorisations select 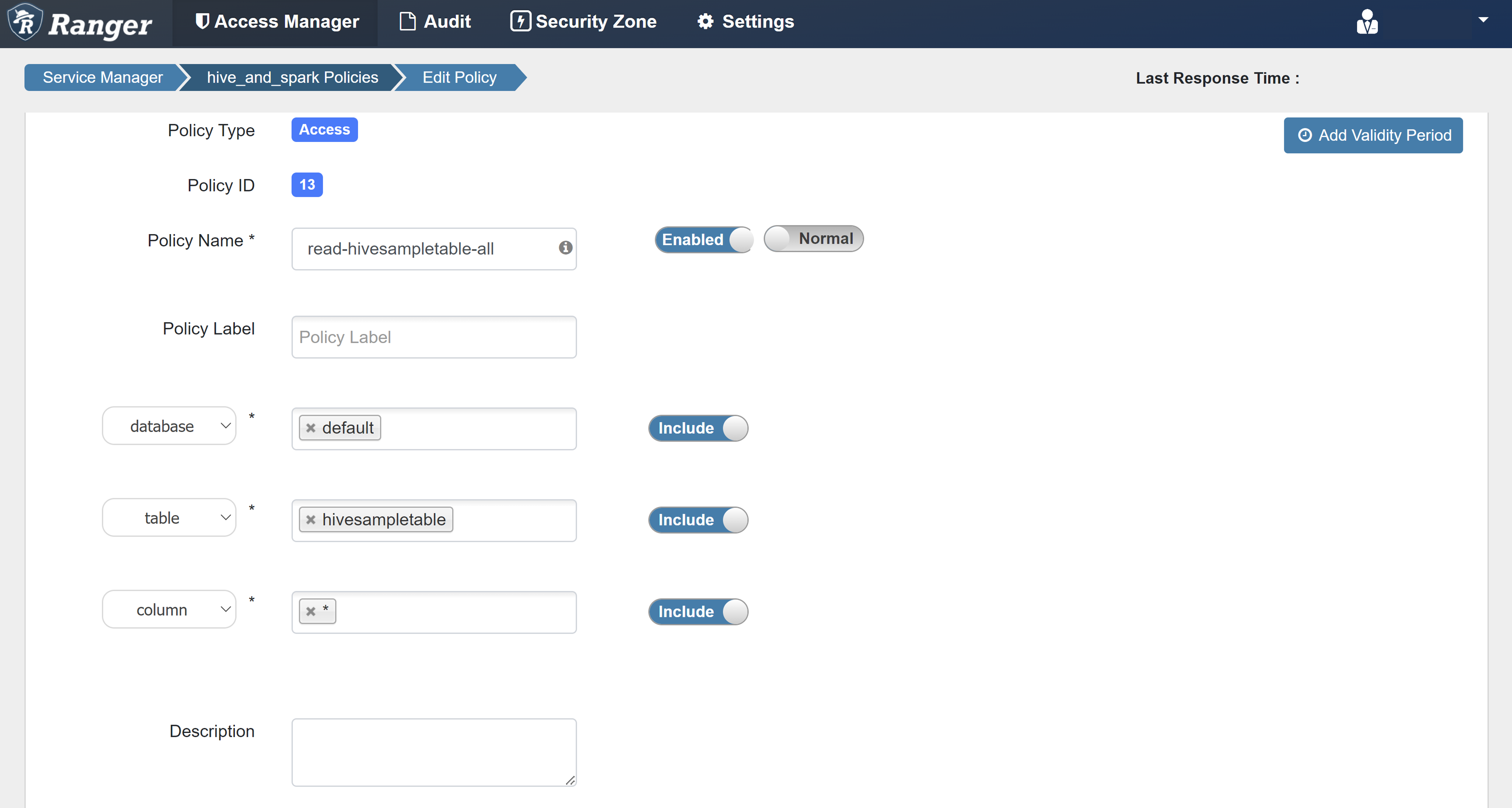
Si un utilisateur de domaine n’est pas automatiquement renseigné pour Sélectionnez un utilisateur, attendez quelques instants que Ranger se synchronise avec Microsoft Entra ID.
Sélectionnez Ajouter pour enregistrer la stratégie.
Ouvrez le notebook Zeppelin et exécutez la commande suivante pour vérifier la stratégie :
%sql select * from hivesampletable limit 10;Voici le résultat avant l’application d’une stratégie :

Voici le résultat après l’application d’une stratégie :





Créer une stratégie de masquage Ranger
L’exemple suivant explique comment créer une stratégie pour masquer une colonne :
Sous l’onglet Masquage, sélectionnez Ajouter une nouvelle stratégie.

Saisissez les valeurs suivantes :
Propriété Valeur Nom de la stratégie mask-hivesampletable Base de données Hive default Table Hive hivesampletable Colonne Hive devicemake Sélectionner un utilisateur sparkuserTypes d’accès select Sélectionner l’option Masquage Hash 
Sélectionnez Save (Enregistrer) pour enregistrer la stratégie.
Ouvrez le notebook Zeppelin et exécutez la commande suivante pour vérifier la stratégie :
%sql select clientId, deviceMake from hivesampletable;



Remarque
Par défaut, les stratégies pour Hive et Spark SQL sont communes dans Ranger.
Appliquer les instructions pour configurer Apache Ranger pour Spark SQL
Les scénarios suivants explorent les instructions de création d’un cluster Spark HDInsight 5.1 en utilisant une nouvelle base de données Ranger et une base de données Ranger existante.
Scénario 1 : Utiliser une nouvelle base de données Ranger pour créer un cluster Spark HDInsight 5.1
Quand vous utilisez une nouvelle base de données Ranger pour créer un cluster, le dépôt Ranger approprié contenant les stratégies Ranger pour Hive et Spark est créé avec le nom hive_and_spark dans le service Hadoop SQL dans la base de données Ranger.

Si vous modifiez les stratégies, elles sont appliquées à Hive et Spark.
Tenez compte de ces points :
Si vous avez deux bases de données metastore du même nom que celui utilisé pour les catalogues Hive (par exemple, DB1) et Spark (par exemple, DB1) :
- Si Spark utilise le catalogue Spark (
metastore.catalog.default=spark), les stratégies sont appliquées à la base de données DB1 du catalogue Spark. - Si Spark utilise le catalogue Hive (
metastore.catalog.default=hive), les stratégies sont appliquées à la base de données DB1 du catalogue Hive.
Du point de vue de Ranger, il n’y a aucun moyen de différencier DB1 entre les catalogues Hive et Spark.
Dans ce cas, nous vous recommandons de choisir entre :
- Utiliser le catalogue Hive pour Hive et Spark.
- Maintenir des noms de base de données, table et colonne différents pour les catalogues Hive et Spark, afin que les stratégies ne soient pas appliquées aux bases de données des deux catalogues.
- Si Spark utilise le catalogue Spark (
Si vous utilisez le catalogue Hive pour Hive et Spark, considérez l’exemple suivant.
Supposons que vous créez une table nommée table1 en utilisant Hive avec l’utilisateur xyz actuel. Il crée un fichier HDFS (Hadoop Distributed File System) nommé table1.db dont le propriétaire est l’utilisateur xyz.
Imaginez maintenant que vous utilisez l’utilisateur abc pour démarrer la session Spark SQL. Dans cette session de l’utilisateur abc, si vous essayez d’écrire quelque chose dans table1, cela est voué à l’échec parce que le propriétaire de la table est xyz.
Dans ce cas, nous vous recommandons d’utiliser le même utilisateur dans Hive et Spark SQL pour mettre à jour la table. Cet utilisateur doit avoir des privilèges suffisants pour effectuer les opérations de mise à jour.
Scénario 2 : Utiliser une base de données Ranger existante (avec des stratégies existantes) pour créer un cluster Spark HDInsight 5.1
Quand vous créez un cluster HDInsight 5.1 en utilisant une base de données Ranger existante, un dépôt Ranger est recréé dans cette base de données avec le nom du nouveau cluster dans ce format : hive_and_spark.

Supposons que vous avez déjà défini les stratégies dans le dépôt Ranger sous le nom oldclustername_hive dans la base de données Ranger existante au sein du service Hadoop SQL. Vous voulez partager les mêmes stratégies dans le nouveau cluster Spark HDInsight 5.1. Pour atteindre cet objectif, utilisez les étapes suivantes.
Remarque
Un utilisateur avec des privilèges Administrateur Ambari peut effectuer des mises à jour de configuration.
Ouvrez l’interface utilisateur Ambari à partir de votre nouveau cluster HDInsight 5.1.
Accédez au service Spark3, puis à Configurations.
Ouvrez la configuration Advanced ranger-spark-security.

ou vous pouvez également ouvrir cette configuration dans /etc/spark3/conf en utilisant SSH.
Modifiez deux configurations (ranger.plugin.spark.service.name et ranger.plugin.spark.policy.cache.dir) pour qu’elles pointent vers l’ancien dépôt de stratégies oldclustername_hive, puis enregistrez les configurations.
Ambari :

Fichier XML :

Redémarrez les services Ranger et Spark à partir d’Ambari.
Ouvrez l’interface utilisateur de l’administrateur Ranger, puis cliquez sur le bouton Modifier sous le service HADOOP SQL.

Pour le service oldclustername_hive, ajoutez l’utilisateur rangersparklookup dans les listes policy.download.auth.users et tag.download.auth.users, puis cliquez sur Enregistrer.






Les stratégies sont appliquées aux bases de données du catalogue Spark. Si vous voulez accéder aux bases de données dans le catalogue Hive :
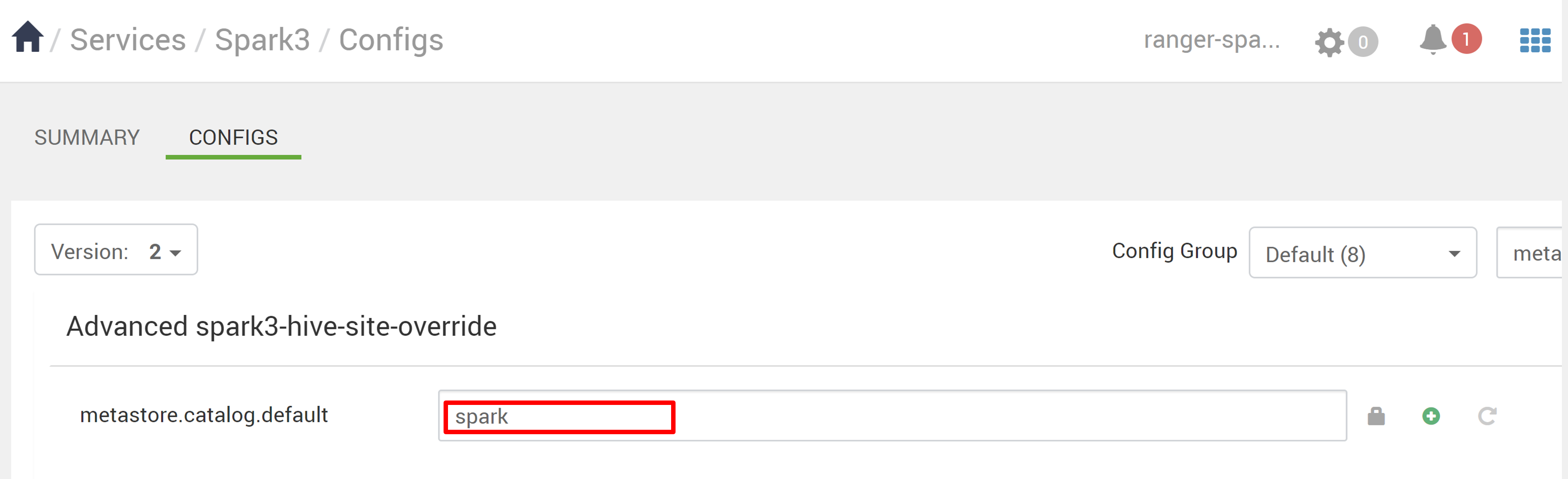
Dans Ambari, accédez à Spark3>Configs.
Remplacez le metastore.catalog.default spark par hive.

Problèmes connus
- L’intégration d’Apache Ranger à Spark SQL ne fonctionne pas si l’administrateur Ranger est inactif.
- Dans les journaux d’audit Ranger, quand vous pointez sur la colonne Ressource, elle n’affiche pas la requête entière que vous avez exécutée.