Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() IoT Edge 1.1
IoT Edge 1.1
Important
IoT Edge 1.1 date de fin de support était le 13 décembre 2022. Consultez la page Politique de support Microsoft pour plus d’informations sur la prise en charge de ce produit, de ce service, de cette technologie ou de cette API. Pour plus d’informations sur la mise à jour vers la dernière version d’IoT Edge, consultez Mettre à jour IoT Edge.
Fréquemment, les applications IoT souhaitent tirer parti du cloud intelligent et de la périphérie intelligente. Dans ce tutoriel, nous vous présentons l’apprentissage d’un modèle Machine Learning avec des données collectées à partir d’appareils IoT dans le cloud, en déployant ce modèle sur IoT Edge et en conservant et en affinant régulièrement le modèle.
Remarque
Les concepts de cet ensemble de tutoriels s’appliquent à toutes les versions d’IoT Edge, mais l’exemple d’appareil que vous créez pour essayer le scénario exécute IoT Edge version 1.1.
L’objectif principal de ce tutoriel est d’introduire le traitement des données IoT avec le Machine Learning, en particulier sur la périphérie. Bien que nous touchions de nombreux aspects d’un flux de travail d’apprentissage automatique général, ce didacticiel n’est pas destiné à une introduction approfondie au Machine Learning. En ce qui concerne le cas d’usage, nous n’essayons pas de créer un modèle hautement optimisé pour le cas d’usage. Nous n’avons qu’à illustrer le processus de création et d’utilisation d’un modèle viable pour le traitement des données IoT.
Cette section du didacticiel traite des points suivants :
- Conditions préalables à l’exécution des parties suivantes du didacticiel.
- Public cible du didacticiel.
- Le cas d’usage que le tutoriel simule.
- Le processus global que le tutoriel suit pour répondre au cas d’usage.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit Azure avant de commencer.
Conditions préalables
Pour suivre le tutoriel, vous devez accéder à un abonnement Azure dans lequel vous avez des droits pour créer des ressources. Plusieurs des services utilisés dans ce didacticiel entraîneront des frais Azure. Si vous n’avez pas encore d’abonnement Azure, vous pourrez peut-être commencer avec un compte Gratuit Azure.
Vous avez également besoin d’une machine avec PowerShell installée où vous pouvez exécuter des scripts pour configurer une machine virtuelle Azure en tant que machine de développement.
Dans ce document, nous utilisons l’ensemble d’outils suivant :
Azure IoT Hub pour la capture de données
Azure Notebooks en tant que serveur frontal principal pour la préparation des données et l’expérimentation de Machine Learning. L’exécution de code Python dans un notebook sur un sous-ensemble des exemples de données est un excellent moyen d’obtenir un traitement itératif et interactif rapide pendant la préparation des données. Les notebooks Jupyter peuvent également être utilisés pour préparer les scripts à exécuter à grande échelle dans un serveur principal de calcul.
Azure Machine Learning en tant que back-end pour le Machine Learning à grande échelle et pour la génération d’images Machine Learning. Nous conduisons le back-end Azure Machine Learning à l’aide de scripts préparés et testés dans des notebooks Jupyter.
Azure IoT Edge pour l'application hors réseau d'une image d'apprentissage automatique
Évidemment, il existe d’autres options disponibles. Dans certains scénarios, par exemple, IoT Central peut être utilisé comme alternative sans code pour capturer des données d’entraînement initiales à partir d’appareils IoT.
Public et rôles cibles
Cet ensemble d’articles est destiné aux développeurs sans expérience antérieure dans le développement IoT ou le Machine Learning. Le déploiement du Machine Learning à la périphérie nécessite une connaissance de la connexion d’un large éventail de technologies. Par conséquent, ce tutoriel couvre un scénario complet de bout en bout pour illustrer une façon de joindre ces technologies ensemble pour une solution IoT. Dans un environnement réel, ces tâches peuvent être distribuées entre plusieurs personnes ayant des spécialisations différentes. Par exemple, les développeurs se concentrent sur le code de l’appareil ou du cloud, tandis que les scientifiques des données ont conçu les modèles d’analyse. Pour permettre à un développeur individuel de suivre avec succès ce tutoriel, nous avons fourni des conseils supplémentaires avec des insights et des liens vers plus d’informations que nous espérons suffisantes pour comprendre ce qui est fait, ainsi que pourquoi.
Vous pouvez également collaborer avec des collègues de différents rôles pour suivre le tutoriel ensemble, en mettant pleinement à profit votre expertise et en apprenant en équipe comment les choses s'articulent.
Dans les deux cas, pour orienter le ou les lecteurs, chaque article de ce didacticiel indique le rôle de l’utilisateur. Ces rôles sont les suivants :
- Développement cloud (y compris un développeur cloud travaillant dans une capacité DevOps)
- Analytique des données
Cas d’usage : Maintenance prédictive
Nous avons basé ce scénario sur un cas d’usage présenté à la Conférence sur les prognostiques et la gestion de la santé (PHM08) en 2008. L’objectif est de prédire la durée de vie utile restante (RUL) d’un ensemble de moteurs d’avion turbofan. Ces données ont été générées à l’aide de C-MAPSS, la version commerciale du logiciel MAPSS (Modular Aero-Propulsion System Simulation). Ce logiciel fournit un environnement flexible de simulation de moteur turbofan pour simuler facilement les paramètres d’intégrité, de contrôle et de moteur.
Les données utilisées dans ce tutoriel sont extraites du jeu de données de simulation de dégradation du moteur Turbofan.
Du fichier Lisez-moi :
Scénario expérimental
Les jeux de données se composent de plusieurs séries chronologiques multivariées. Chaque jeu de données est divisé en sous-ensembles d’apprentissage et de test. Chaque série chronologique provient d’un moteur différent, c’est-à-dire que les données peuvent être considérées comme provenant d’une flotte de moteurs du même type. Chaque moteur commence par des degrés différents d’usure initiale et de variation de fabrication qui est inconnu de l’utilisateur. Cette usure et cette variante sont considérées comme normales, c’est-à-dire qu’elle n’est pas considérée comme une condition d’erreur. Il existe trois paramètres opérationnels qui ont un effet substantiel sur les performances du moteur. Ces paramètres sont également inclus dans les données. Les données sont contaminées par le bruit du capteur.
Le moteur fonctionne normalement au début de chaque série chronologique et développe une erreur à un moment donné pendant la série. Dans l'ensemble d’entraînement, le défaut augmente en grandeur jusqu’à la défaillance du système. Dans le jeu de tests, la série chronologique se termine un certain temps avant l’échec du système. L’objectif de la concurrence est de prédire le nombre de cycles opérationnels restants avant l’échec dans le jeu d’essais, c’est-à-dire le nombre de cycles opérationnels après le dernier cycle que le moteur continuera à fonctionner. Fournit également un vecteur des vraies valeurs de durée de vie restante (RUL) pour les données de test.
Étant donné que les données ont été publiées pour un concours, plusieurs approches pour dériver des modèles Machine Learning ont été publiées indépendamment. Nous avons constaté que l’étude d’exemples est utile pour comprendre le processus et le raisonnement impliqués dans la création d’un modèle Machine Learning spécifique. Voir par exemple :
Modèle de prédiction des défaillances du moteur d’avion par l’utilisateur GitHub jancervenka.
Dégradation du moteur turbofan par l’utilisateur GitHub hankroark.
Processus
L’image ci-dessous illustre les étapes approximatives que nous suivons dans ce tutoriel :
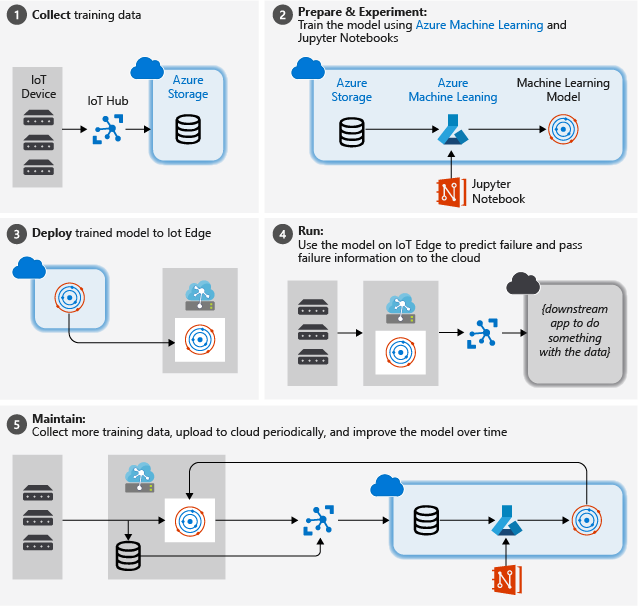
Collecter des données d’apprentissage : le processus commence par collecter des données d’apprentissage. Dans certains cas, les données ont déjà été collectées et sont disponibles dans une base de données ou sous forme de fichiers de données. Dans d’autres cas, en particulier pour les scénarios IoT, les données doivent être collectées à partir d’appareils et de capteurs IoT et stockées dans le cloud.
Nous partons du principe que vous n’avez pas de collection de moteurs turbofan. Les fichiers projet incluent donc un simulateur d’appareil simple qui envoie les données de l’appareil nasa au cloud.
Préparez des données. Dans la plupart des cas, les données brutes collectées à partir d’appareils et de capteurs nécessitent une préparation pour le Machine Learning. Cette étape peut impliquer le nettoyage des données, le reformatage des données ou le prétraitement pour injecter des informations supplémentaires dont l'apprentissage automatique peut tirer parti.
Pour nos données de machine de moteur d’avion, la préparation des données implique le calcul des temps d’échec explicites pour chaque point de données de l’échantillon en fonction des observations réelles sur les données. Ces informations permettent à l’algorithme Machine Learning de rechercher des corrélations entre les modèles de données de capteur réels et le temps de vie restant attendu du moteur. Cette étape est hautement spécifique au domaine.
Créez un modèle Machine Learning. En fonction des données préparées, nous pouvons maintenant expérimenter différents algorithmes et paramétrages machine learning pour entraîner des modèles et comparer les résultats entre eux.
Dans ce cas, pour les tests, nous comparons le résultat prédit calculé par le modèle avec le résultat réel observé sur un ensemble de moteurs. Dans Azure Machine Learning, nous pouvons gérer les différentes itérations de modèles que nous créons dans un registre de modèles.
Déployez le modèle. Une fois que nous avons un modèle qui répond à nos critères de réussite, nous pouvons passer au déploiement. Cela implique d’encapsuler le modèle dans une application de service web qui peut être alimentée avec des données à l’aide d’appels REST et de retourner des résultats d’analyse. L’application de service web est ensuite empaquetée dans un conteneur Docker, qui peut à son tour être déployée dans le cloud ou en tant que module IoT Edge. Dans cet exemple, nous nous concentrons sur le déploiement sur IoT Edge.
Conservez et affinez le modèle. Notre travail n’est pas effectué une fois le modèle déployé. Dans de nombreux cas, nous voulons continuer à collecter des données et à charger régulièrement ces données dans le cloud. Nous pouvons ensuite utiliser ces données pour réentraîner et affiner notre modèle, que nous pouvons ensuite redéployer sur IoT Edge.
Nettoyer les ressources
Ce tutoriel fait partie d’un ensemble où chaque article s’appuie sur le travail effectué dans les précédents. Veuillez patienter pour nettoyer les ressources jusqu’à ce que vous mettez fin au didacticiel final.
Étapes suivantes
Ce tutoriel est divisé en sections suivantes :
- Configurez votre machine de développement et vos services Azure.
- Générez les données d’apprentissage pour le module Machine Learning.
- Entraîner et déployer le module Machine Learning.
- Configurez un appareil IoT Edge pour qu’il agisse comme une passerelle transparente.
- Créez et déployez des modules IoT Edge.
- Envoyez des données à votre appareil IoT Edge.
Passez à l’article suivant pour configurer une machine de développement et approvisionner des ressources Azure.