Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
APPLIES TO :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Le Machine Learning automatisé, également appelé Machine Learning automatisé ou AutoML, automatise les tâches itératives et fastidieuses du développement de modèles Machine Learning. Avec le ML automatisé, les scientifiques des données, les analystes et les développeurs peuvent créer des modèles Machine Learning à grande échelle avec efficacité et productivité, tout en conservant la qualité du modèle. Le Machine Learning automatisé dans Azure Machine Learning se base sur une innovation de la division Microsoft Research.
- Pour les clients expérimentés en codage, installez le SDK Python d’Azure Machine Learning. Faites vos premiers pas avec le Tutoriel : Effectuer l’apprentissage d’un modèle de détection d’objet (préversion) avec AutoML et Python.
Comment fonctionne AutoML ?
Pendant l’apprentissage, Azure Machine Learning crée un certain nombre de pipelines en parallèle qui testent différents algorithmes et paramètres pour vous. Le service effectue une itération via des algorithmes ML associés à des sélections de fonctionnalités. Chaque itération produit un modèle avec un score d’entraînement. Mieux le score de la métrique que vous souhaitez optimiser, mieux le modèle correspond à vos données. Le processus s’arrête une fois qu’il répond aux critères de sortie définis dans l’expérience.
Azure Machine Learning vous permet de concevoir et d’exécuter vos expériences d’entraînement de Machine Learning automatisé en effectuant les étapes suivantes :
Identifiez le problème ML à résoudre : classification, prévision, régression, vision par ordinateur ou NLP.
Choisissez une expérience web sans code studio ou une expérience web sans code studio : les utilisateurs qui préfèrent une première expérience de code peuvent utiliser Azure Machine Learning SDKv2 ou Azure Machine Learning CLIv2. Faites vos premiers pas avec le Tutoriel : Effectuer l’apprentissage d’un modèle de détection d’objet avec AutoML et Python. Les utilisateurs qui préfèrent une expérience limitée ou sans code peuvent utiliser l’interface web d’Azure Machine Learning studio à l’adresse https://ml.azure.com. Faites vos premiers pas avec le Tutoriel : Créer un modèle de classification avec le ML automatisé dans Azure Machine Learning.
Spécifiez la source des données d’entraînement étiquetées : apportez vos données à Azure Machine Learning de plusieurs façons différentes.
Configurez les paramètres machine learning automatisés : définissez le nombre d’itérations sur différents modèles, les paramètres d’hyperparamètres, les options avancées de prétraitement et de caractérisation, ainsi que les métriques à évaluer lors de la détermination du meilleur modèle.
Soumettre le travail d’entraînement.
Passez en revue les résultats.
Le diagramme suivant illustre ce processus.
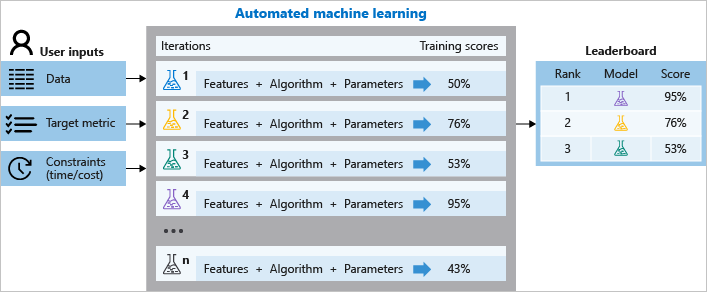
Vous pouvez également inspecter les informations de travaux journalisées qui contiennent les indicateurs de performance collectées pendant le travail. Le travail de formation produit un objet sérialisé Python (fichier .pkl) contenant le modèle et le prétraitement des données.
Bien que la création de modèles soit automatisée, vous pouvez également découvrir l’importance ou la pertinence des fonctionnalités pour les modèles générés.
Quand utiliser AutoML : classification, régression, prévision, vision par ordinateur et NLP
Utilisez le ML automatisé lorsque vous souhaitez qu’Azure Machine Learning effectue l’apprentissage et l’optimisation d’un modèle à l’aide de la métrique cible que vous spécifiez. Le ML automatisé démocratise le processus de développement de modèle Machine Learning et permet à ses utilisateurs, quelle que soit leur expertise en science des données, d’identifier un pipeline machine learning de bout en bout pour tout problème.
Les professionnels et développeurs du Machine Learning de différents secteurs peuvent utiliser le Machine Learning automatisé pour ce qui suit :
- Implémenter des solutions ML sans disposer d’une connaissance approfondie de la programmation.
- Économiser du temps et des ressources.
- Appliquer les meilleures pratiques en matière de science des données
- Fournir une résolution de problème agile.
Catégorisation
La classification est un type d’apprentissage supervisé dans lequel des modèles apprennent à utiliser des données de formation et appliquent celui-ci à de nouvelles données. Azure Machine Learning offre des caractérisations spécifiquement pour ces tâches, telles que des caractériseurs de réseau neuronal profond pour la classification. Pour plus d’informations sur les options de caractérisation, consultez Caractérisation des données. Vous trouverez également la liste des algorithmes pris en charge par AutoML dans Algorithmes pris en charge.
L’objectif principal des modèles de classification est de prédire les catégories dans lesquelles les nouvelles données sont classées, sur la base des enseignements tirés de leurs données d’apprentissage. Les exemples de classification courants incluent la détection des fraudes, la reconnaissance de l’écriture manuscrite et la détection d’objets.
Consultez un exemple de classification et de Machine Learning automatisé dans ce notebook Python : Marketing bancaire.
régression ;
À l’instar de la classification, les tâches de régression sont également une tâche d’apprentissage supervisé courante. Azure Machine Learning offre une caractérisation propre aux problèmes de régression. Apprenez-en davantage sur les optons de caractérisation. Vous trouverez également la liste des algorithmes pris en charge par AutoML dans Algorithmes pris en charge.
À la différence d’une classification dans laquelle les valeurs de sortie prédites sont catégoriques, les modèles de régression prédisent des valeurs de sortie numériques en fonction de prédictions indépendantes. Dans une régression, l’objectif est d’aider à établir la relation entre ces variables de prédiction indépendantes en estimant l’impact d’une variable sur les autres. Par exemple, le modèle peut prédire le coût de l’automobile basé sur des caractéristiques telles que la consommation de carburant et la cote de sécurité.
Pour obtenir un exemple de régression et de Machine Learning automatisé pour les prédictions, consultez les notebooks Python suivants :Performances du matériel.
Prévision de série chronologique
L’établissement de prévisions fait partie intégrante de toute entreprise, qu’il s’agisse du chiffre d’affaires, de l’inventaire, des ventes ou de la demande des clients. Utilisez le ML automatisé pour combiner des techniques et des approches et obtenir une prévision de série chronologique de haute qualité recommandée. Pour obtenir la liste des algorithmes pris en charge par AutoML, consultez Algorithmes pris en charge.
Une expérience de série chronologique automatisée traite le problème comme un problème de régression multivarié. Les valeurs de série chronologique passées « pivotent » afin de devenir d’autres dimensions pour le régresseur, avec d’autres prédicteurs. Contrairement aux méthodes de séries chronologiques classique, cette méthode présente l’avantage d’incorporer naturellement plusieurs variables contextuelles et leurs relations entre elles pendant la formation. Le Machine Learning automatisé effectue l’apprentissage d’un modèle unique, mais souvent ramifié en interne, pour tous les éléments du jeu de données et les horizons de prédiction. Plus de données sont ainsi disponibles pour estimer les paramètres du modèle et la généralisation en séries invisibles devient possible.
La configuration de prévisions avancée inclut les éléments suivants :
- Détection et caractérisation des congés
- Série chronologique et apprenants DNN (Auto-ARIMA, Prophet, ForecastTCN)
- Prise en charge de nombreux modèles via le regroupement
- Validation croisée à origine dynamique
- Décalages configurables
- Caractéristiques des agrégations des périodes mobiles
Pour obtenir un exemple de prévision et d’apprentissage automatique automatisé, consultez ce notebook Python : Demande énergétique.
Vision par ordinateur
La prise en charge des tâches de vision par ordinateur vous permet de générer facilement des modèles formés sur des données d’image pour des scénarios tels que la classification d’images et la détection d’objets.
Grâce à cette fonctionnalité, vous pouvez :
- Réalisez une intégration fluide à la fonctionnalité d’étiquetage des données Azure Machine Learning.
- Utilisez des données étiquetées pour générer des modèles d’image.
- Optimiser les performances du modèle en spécifiant l’algorithme du modèle et en réglant les hyperparamètres
- Télécharger ou déployer le modèle obtenu en tant que service web dans Azure Machine Learning
- Rendre les modèles opérationnels à grande échelle, en tirant parti des fonctionnalités d’Azure Machine Learning MLOps et Pipelines ML.
Vous pouvez créer des modèles AutoML pour les tâches de vision à l’aide du Kit de développement logiciel (SDK) Python Azure Machine Learning. Vous pouvez accéder aux travaux, modèles et sorties d’expérimentation résultants à partir de l’interface utilisateur d’Azure Machine Learning Studio.
Découvrez comment configurer l’apprentissage AutoML pour les modèles de vision par ordinateur.
 Image provenant de : http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Image provenant de : http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
La fonctionnalité de ML automatisé pour les images prend en charge les tâches de vision par ordinateur suivantes :
| Tâche | Descriptif |
|---|---|
| Classification d’images multiclasse | Tâches où une image est classifiée avec une seule étiquette d’un ensemble de classes. Par exemple, chaque image est classifiée par exemple en tant qu’image de chat, de chien ou de canard. |
| Classification d’images multiétiquette | Tâches où une image peut avoir une ou plusieurs étiquettes d’un ensemble d’étiquettes. Par exemple, une image peut avoir les étiquettes chat et chien. |
| Détection d’objets | Tâches permettant d’identifier des objets dans une image et de localiser chaque objet avec un rectangle englobant. On peut par exemple rechercher tous les chiens et tous les chats dans une image et les entourer d’un cadre englobant. |
| Segmentation d’instances | Tâches permettant d’identifier des objets dans une image au niveau des pixels, en dessinant un polygone autour de chaque objet dans l’image. |
Traitement du langage naturel : NLP
La prise en charge des tâches de traitement en langage naturel (NLP) dans ml automatisé vous permet de générer facilement des modèles formés sur des données de texte pour les scénarios de classification de texte et de reconnaissance d’entité nommée. Vous pouvez créer des modèles de machine learning automatisé formés pour le traitement du langage naturel (NLP) via le Kit de développement logiciel (SDK) Python Azure Machine Learning. Vous pouvez accéder aux travaux, modèles et sorties d’expérimentation résultants à partir de l’interface utilisateur d’Azure Machine Learning Studio.
La fonction NLP prend en charge les éléments suivants :
- Formation NLP avec réseau neuronal profond de bout en bout avec les derniers modèles BERT pré-formés
- Intégration transparente avec l’étiquetage des données Azure Machine Learning
- Utiliser des données étiquetées pour générer des modèles NLP
- Prise en charge multilingue avec 104 langues
- Entraînement distribué avec Horovod
Découvrez comment configurer la formation par ML automatisé pour les modèles de NLP.
Formation, validation et test des données
Avec le ML automatisé, vous fournissez les données de formation pour former des modèles ML, et vous pouvez spécifier le type de validation de modèle à effectuer. Le ML automatisé effectue une validation de modèle dans le cadre de la formation. Autrement dit, le ML automatisé utilise les données de validation pour ajuster les hyperparamètres du modèle en fonction de l’algorithme appliqué afin de trouver la combinaison qui correspond le mieux aux données d’apprentissage. Toutefois, les mêmes données de validation sont utilisées pour chaque itération de paramétrage, ce qui introduit le biais de l’évaluation du modèle, puisque le modèle continue à s’améliorer et à s’ajuster par rapport aux données de validation.
Pour vous aider à confirmer que ce biais n’est pas appliqué au modèle recommandé final, le ML automatisé prend en charge l’utilisation de données de test pour évaluer le modèle final que le ML automatisé recommande à la fin de votre expérience. Lorsque vous fournissez des données de test dans le cadre de votre configuration d’expérimentation AutoML, ce modèle recommandé est testé par défaut à la fin de votre expérience (préversion).
Important
Le test de vos modèles avec un jeu de données de test pour évaluer les modèles générés est une fonctionnalité en préversion. Cette capacité est une fonctionnalité en préversion expérimentale qui peut évoluer à tout moment.
Découvrez comment Configurer les expériences AutoML pour utiliser des données de test (préversion) avec le kit de développement logiciel (SDK) ou avec Azure Machine Learning Studio.
Ingénierie des caractéristiques
L’ingénierie des fonctionnalités utilise la connaissance du domaine des données pour créer des fonctionnalités qui aident les algorithmes ML à mieux apprendre. Dans Azure Machine Learning, les techniques de mise à l’échelle et de normalisation aident à l’ingénierie des fonctionnalités. Collectivement, ces techniques et l’ingénierie de caractéristiques sont appelées caractérisation.
Pour les expériences de Machine Learning automatisées, la caractérisation se produit automatiquement, mais vous pouvez également la personnaliser en fonction de vos données. En savoir plus sur la caractérisation incluse (kit de développement logiciel (SDK) v1) et comment AutoML permet d’empêcher le surajustement et le déséquilibrage des données dans vos modèles.
Remarque
Les étapes de caractérisation de Machine Learning automatisée, telles que la normalisation des fonctionnalités, la gestion des données manquantes et la conversion de texte en texte numérique, font partie du modèle sous-jacent. Lorsque vous utilisez le modèle pour les prédictions, les mêmes étapes de caractérisation appliquées pendant l’entraînement sont automatiquement appliquées à vos données d’entrée.
Personnaliser la caractérisation
Vous pouvez également utiliser d’autres techniques d’ingénierie de fonctionnalités, telles que l’encodage et les transformations.
Activez ce paramètre avec :
Azure Machine Learning Studio : Activez Caractérisation automatique dans la section Afficher des configurations supplémentairesen suivant ces étapes.
Kit de développement logiciel (SDK) Python : spécifiez la caractérisation dans votre objet AutoML Job. En savoir plus sur l’activation de la caractérisation.
Modèles d’ensemble
Le Machine Learning automatisé prend en charge les modèles ensemblistes, qui sont activés par défaut. L’apprentissage d’ensemble améliore les résultats du Machine Learning et les performances prédictives en combinant plusieurs modèles au lieu d’utiliser des modèles uniques. Les itérations d’ensembles apparaissent comme les dernières itérations de votre tâche. Le Machine Learning automatisé utilise des méthodes ensemblistes de vote et d’empilement pour combiner les modèles :
- Vote : prédictions basées sur la moyenne pondérée des probabilités de classe prédites (pour les tâches de classification) ou des cibles de régression prédites (pour les tâches de régression).
- Empilement : combine des modèles hétérogènes et entraîne un métamodèle basé sur la sortie des modèles individuels. Actuellement, les métamodèles par défaut sont LogisticRegression pour les tâches de classification, et ElasticNet pour les tâches de régression et de prévision.
L’algorithme de sélection de l’ensemble Caruana avec initialisation d’ensemble trié détermine les modèles à utiliser dans l’ensemble. Pour résumer, cet algorithme initialise l’ensemble avec un maximum de cinq modèles ayant obtenu les meilleurs scores, puis vérifie que ces scores se situent dans une marge de plus ou moins 5 % par rapport au meilleur score, afin d’éviter un ensemble de niveau médiocre. Ensuite, pour chaque itération d’ensemble, un nouveau modèle est ajouté à l’ensemble existant et le score est calculé. Si un nouveau modèle améliore le score d’ensemble existant, l’ensemble est mis à jour pour inclure le nouveau modèle.
Pour savoir comment modifier les paramètres par défaut de l’ensemble au niveau du Machine Learning automatisé, consultez Package AutoML.
AutoML et ONNX
Avec Azure Machine Learning, vous pouvez utiliser le Machine Learning automatisé pour générer un modèle Python et le convertir au format ONNX. Une fois que les modèles sont au format ONNX, vous pouvez les exécuter sur différentes plateformes et appareils. Apprenez-en davantage sur l’accélération des modèles ML avec ONNX.
Découvrez comment convertir au format ONNX dans cet exemple de notebook Jupyter. Découvrez quels sont les algorithmes pris en charge dans ONNX.
Le runtime ONNX prenant également en charge C#, vous pouvez utiliser le modèle généré automatiquement dans vos applications C# sans avoir besoin de recodage ou des latences réseau introduites par les points de terminaison REST. En savoir plus sur l’utilisation d’un modèle ONNX AutoML dans une application .NET avec ML.NET et sur l’inférence de modèles ONNX avec l’API C# du runtime ONNX.
Étapes suivantes
Utilisez les ressources suivantes pour vous familiariser avec AutoML.
Tutoriels et articles pratiques
Les tutoriels sont des exemples illustrant de bout en bout des scénarios d’utilisation d’AutoML.
Pour une première expérience de code, suivez le tutoriel suivant : Entraîner un modèle de détection d’objet avec AutoML et Python.
Pour une expérience avec peu de code ou sans code, consultez le Tutoriel : Formation d’un modèle de classification sans code avec AutoML dans Azure Machine Learning studio.
Les articles pratiques fournissent plus de détails sur les fonctionnalités des offres ML automatisées. Par exemple,
Configurez les paramètres pour des expériences d’entraînement automatique
Découvrez comment effectuer l’apprentissage des modèles de vision par ordinateur avec Python.
Découvrez comment afficher le code généré depuis vos modèles de ML automatisé (kit de développement logiciel (SDK) v1).
Exemples de blocs-notes Jupyter
Passez en revue les exemples de code détaillé et les cas d’usage disponibles dans le dépôt GitHub d’exemples de blocs-notes pour le Machine Learning automatisé.
Référence du Kit de développement logiciel (SDK) Python
Approfondissez votre connaissance des modèles de conception et des spécifications de classe du kit de développement logiciel (SDK) en consultant la documentation de référence sur les classes AutoML Job.
Remarque
Des fonctionnalités de Machine Learning automatisé sont également disponible dans d’autres solutions Microsoft telles que ML.NET, HDInsight, Power BI et SQL Server.