Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article compare le Deep Learning au Machine Learning et décrit comment ils s’intègrent dans la catégorie plus large de l’IA. Découvrez les solutions d’apprentissage profond que vous pouvez créer sur Azure Machine Learning, par exemple, pour la détection des fraudes, la reconnaissance vocale et faciale, l’analyse des sentiments et la prévision de séries chronologiques.
Pour obtenir des conseils sur le choix des algorithmes pour vos solutions, consultez l’Aide-mémoire de l’algorithme Machine Learning.
Les modèles foundry dans Azure Machine Learning sont des modèles d’apprentissage profond préentraînés qui peuvent être affinés pour des cas d’usage spécifiques. Pour plus d’informations, consultez Explorer les modèles Microsoft Foundry dans Azure Machine Learning et Comment utiliser des modèles de base Open Source organisés par Azure Machine Learning.
Deep Learning, Machine Learning et intelligence artificielle
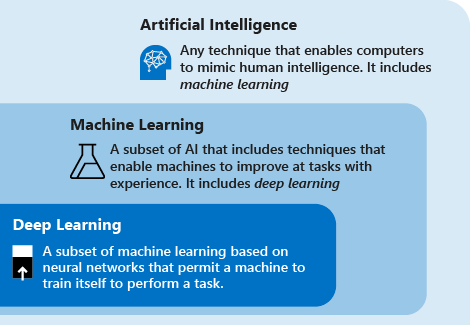
Les définitions suivantes décrivent les relations entre le Deep Learning, le Machine Learning, l’IA :
Le Deep Learning, ou apprentissage profond, est un sous-ensemble du Machine Learning, ou apprentissage automatique, basé sur des réseaux neuronaux artificiels. Le processus d’apprentissage est qualifié de profond parce que la structure des réseaux neuronaux artificiels se compose de plusieurs couches d’entrée, de sortie et masquées. Chaque couche contient des unités qui transforment les données d’entrée en informations que la couche suivante peut utiliser une tâche prédictive spécifique. En raison de cette structure, un ordinateur peut apprendre par le biais de son propre traitement des données.
Le Machine Learning est un sous-ensemble d’intelligence artificielle qui utilise des techniques (telles que le Deep Learning) qui permettent aux machines d’utiliser l’expérience pour améliorer leur capacité à effectuer des tâches. Le processus d’apprentissage se compose des étapes suivantes :
- Alimenter un algorithme en données (Dans cette étape, vous pouvez fournir des informations supplémentaires au modèle, par exemple, en effectuant une extraction de fonctionnalités.)
- Utilisez ces données pour entraîner un modèle.
- Tester et déployer le modèle.
- Utiliser le modèle déployé pour effectuer une tâche prédictive automatisée (en d’autres termes, appeler et utiliser le modèle déployé pour recevoir les prédictions retournées par le modèle).
L’IA est une technique qui permet aux ordinateurs d’imiter l’intelligence humaine. Cette technique inclut le Machine Learning.
L’IA générative est un sous-ensemble d’IA qui utilise des techniques (telles que l’apprentissage profond) pour générer du nouveau contenu. Par exemple, vous pouvez utiliser l’IA générative pour créer des images, du texte ou de l’audio. Ces modèles utilisent des quantités massives de connaissances préentraînées pour générer ce contenu.
Les techniques de Machine Learning et de Deep Learning vous permettent de créer des systèmes informatiques et des applications qui effectuent des tâches généralement associées à l’intelligence humaine. Ces tâches incluent la reconnaissance d’images, la reconnaissance vocale et la traduction linguistique.
Techniques du Deep Learning et du Machine Learning
Maintenant que vous avez une compréhension de base de la façon dont le Machine Learning diffère du Deep Learning, comparons les deux techniques. Dans le Machine Learning, l’algorithme doit être informé de la façon d’effectuer une prédiction précise en consommant plus d’informations. (Par exemple, en effectuant une extraction de fonctionnalités.) Dans le deep learning, l’algorithme peut apprendre à effectuer une prédiction précise par le biais de son propre traitement des données, car il utilise la structure de réseau neuronal artificiel.
Le tableau suivant compare les deux techniques de manière plus détaillée :
| Apprentissage automatique | Apprentissage approfondi | |
|---|---|---|
| Nombre de points de données | Peut utiliser de petites quantités de données pour faire des prédictions. | A besoin de grandes quantités de données d’entraînement pour effectuer des prédictions. |
| Dépendances matérielles | Peut fonctionner sur des machines bas de gamme. Ne nécessite pas beaucoup de puissance de calcul. | Nécessite des machines haut de gamme. Effectue fondamentalement un grand nombre d’opérations de multiplication de matrices. Un GPU peut optimiser efficacement ces opérations. |
| Processus de personnalisation | Nécessite que les caractéristiques soient identifiées et créées avec précision par les utilisateurs. | Apprend des caractéristiques de haut niveau à partir de données, et crée de nouvelles caractéristiques de façon autonome. |
| Approche d’apprentissage | Scinde le processus d’apprentissage en étapes plus petites. Combine ensuite les résultats de chaque étape dans une seule sortie. | Parcourt le processus d’apprentissage en résolvant le problème de bout en bout. |
| Temps de formation | Nécessite relativement peu de temps pour apprendre, de quelques secondes à quelques heures. | Nécessite généralement un temps d’entraînement assez long, car un algorithme de deep learning implique de nombreuses couches. |
| Sortie | La sortie est généralement une valeur numérique, telle qu’une note ou une classification. | La sortie peut avoir plusieurs formats, comme un texte, un score ou un son. |
Qu’est-ce que l’apprentissage de transfert ?
La formation de modèles Deep Learning nécessite souvent de grandes quantités de données de formation, des ressources de calcul haut de gamme (GPU, TPU) et un temps de formation plus long. Lorsque vous n’en disposez pas, vous pouvez raccourcir le processus d’entraînement à l’aide d’une technique appelée apprentissage de transfert.
L’apprentissage de transfert est une technique qui applique les connaissances acquises lors de la résolution d’un problème à un problème différent, mais connexe.
En raison de la structure des réseaux neuronaux, le premier ensemble de couches contient généralement des caractéristiques de niveau inférieur, tandis que le dernier ensemble de couches contient des caractéristiques de niveau supérieur qui sont plus proches du domaine en question. En réutilisant les couches finales dans un nouveau domaine ou problème, vous pouvez réduire considérablement le temps, les données et les ressources de calcul nécessaires à la formation du nouveau modèle. Par exemple, si vous avez déjà un modèle qui reconnaît les voitures, vous pouvez réaffecter ce modèle en utilisant l’apprentissage de transfert pour également reconnaître les camions, les motos et d’autres types de véhicules.
Pour savoir comment appliquer l’apprentissage de transfert pour la classification d’images à l’aide d’une infrastructure open source dans Azure Machine Learning, consultez Entraîner un modèle PyTorch d’apprentissage profond à l’aide de l’apprentissage par transfert.
Cas d’utilisation du Deep Learning
En raison de la structure de réseau neuronal artificiel, l’apprentissage profond excelle à identifier les modèles dans des données non structurées telles que des images, du son, de la vidéo et du texte. Pour cette raison, le Deep Learning transforme rapidement de nombreux secteurs, donc ceux de la santé, de l’énergie, des finances et des transports. Ces secteurs repensent actuellement leurs processus métier traditionnels.
Certaines applications courantes du Deep Learning sont décrites dans les paragraphes suivants. Dans Azure Machine Learning, vous pouvez utiliser un modèle que vous avez créé à partir d’une infrastructure open source ou générer le modèle à l’aide des outils fournis.
Reconnaissance d’entité nommée
La reconnaissance d’entité nommée est une méthode de deep learning qui prend du texte en entrée et le transforme en une classe prédéfinie. Ces nouvelles informations peuvent être un code postal, une date ou un ID de produit. Elles peuvent ensuite être stockées dans un schéma structuré afin d’établir une liste d’adresses ou de servir de référence pour un moteur de validation d’identité.
Détection d’objets
le Deep Learning est souvent utilisé pour la détection d’objets. La détection d’objets permet d’identifier les objets d’une image (tels que des voitures ou des personnes) et de fournir un emplacement spécifique pour chaque objet avec un cadre englobant.
La détection d’objets est déjà utilisée dans les secteurs du jeu, de la distribution, du tourisme et des véhicules autonomes.
Génération de légende d’image
À l’instar de la reconnaissance d’image, la génération de légende d’image consiste à générer une légende décrivant le contenu d’une image. Lorsque vous pouvez détecter et étiqueter des objets dans des photos, l’étape suivante consiste à convertir ces étiquettes en phrases descriptives.
Les applications de légendage d’images utilisent habituellement des réseaux neuronaux convolutifs pour identifier les objets dans les images, puis un réseau neuronal récurrent pour convertir les étiquettes en phrases cohérentes.
Traduction automatique
La traduction automatique consiste à traduire des mots ou des phrases d’une langue dans une autre langue. La traduction automatique existe depuis longtemps, mais le deep learning produit des résultats impressionnants dans deux domaines particuliers : la traduction automatique de texte (et la reconnaissance vocale) et la traduction automatique d’images.
Avec une transformation appropriée des données, un réseau neuronal est capable de comprendre du texte, du son et des images. La traduction automatique permet d’identifier des extraits de son dans des fichiers audio volumineux, ainsi que de transcrire de la parole ou des images en texte.
Analytique de texte
L’analyse de texte basée sur des méthodes d’apprentissage profond implique l’analyse de grandes quantités de données textuelles (par exemple, des documents médicaux ou des reçus de frais), la reconnaissance des modèles et la création d’informations organisées et concises.
Les organisations utilisent l’apprentissage profond pour effectuer une analyse de texte pour détecter les transactions internes et la conformité aux réglementations gouvernementales. Un autre exemple courant est la fraude à l’assurance : l’analyse de texte est souvent utilisée pour analyser un grand nombre de documents afin de reconnaître les chances qu’une demande d’assurance soit frauduleuse.
Réseaux neuronaux artificiels
Les réseaux neuronaux artificiels sont formés par couches de nœuds connectés. Les modèles de Deep Learning utilisent des réseaux neuronaux comportant grand nombre de couches.
Les sections suivantes décrivent certaines topologies de réseau neuronal artificiel populaires.
Réseau neuronal feedforward
Le réseau neuronal feedforward est le type de réseau neuronal artificiel le plus simple. Dans un réseau feedforward, les informations circulent dans une seule direction, de la couche d’entrée vers la couche de sortie. Les réseaux neuronaux feedforward transforment une entrée en la faisant passer par une série de couches masquées. Chaque couche est constituée d’un ensemble de neurones, et chaque couche est entièrement connectée à tous les neurones de la couche avant elle. La dernière couche entièrement connectée (couche de sortie) représente les prédictions générées.
Réseau de neurones récurrents (RNN)
Les réseaux neuronaux récurrents sont un type de réseau neuronal artificiel largement utilisé. Ces réseaux enregistrent la sortie d’une couche et la renvoient à la couche d’entrée pour aider à prédire le résultat de la couche. Les réseaux neuronaux récurrents ont de fortes capacités d’apprentissage. Ils sont largement utilisés pour accomplir des tâches complexes comme la prévision de séries chronologiques, l’apprentissage d’écriture manuscrite et la reconnaissance linguistique.
Réseau neuronal convolutif (CNN)
Un réseau neuronal convolutif est un réseau neuronal artificiel particulièrement efficace qui présente une architecture unique. Les couches sont organisées en trois dimensions : largeur, hauteur et profondeur. Les neurones d’une couche ne sont pas connectés à tous les neurones de la couche suivante, mais uniquement à une petite région de neurones de celle-ci. Le résultat final est réduit à un seul vecteur de notes de probabilité, organisées dans la dimension de la profondeur.
Les réseaux neuronaux convolutionnels sont utilisés dans des domaines tels que la reconnaissance vidéo, la reconnaissance d’images et les systèmes de recommandation.
Réseaux antagonistes génératifs (GAN)
Les réseaux antagonistes génératifs sont des modèles génératifs dont l'apprentissage a pour but de générer du contenu réaliste tel que des images. Ils sont constitués de deux réseaux appelés générateur et discriminateur. L'apprentissage de ces deux réseaux s'effectue simultanément. Pendant l'apprentissage, le générateur utilise un bruit aléatoire pour générer de nouvelles données synthétiques qui ressemblent à des données réelles. Le discriminateur prend la sortie du générateur comme entrée et utilise des données réelles pour déterminer si le contenu généré est réel ou synthétique. Chaque réseau est en concurrence avec l’autre. Le générateur essaie de générer du contenu synthétique indistinguishable à partir du contenu réel, et le discriminateur essaie de classer correctement les entrées comme réelles ou synthétiques. La sortie est ensuite utilisée pour mettre à jour les pondérations des deux réseaux afin de les aider à mieux atteindre leurs objectifs respectifs.
Les réseaux contradictoires génératifs sont utilisés pour résoudre des problèmes tels que la traduction d’image à image et la progression de l’âge.
Transformateurs
Les transformateurs sont des architectures de modèle qui conviennent à la résolution de problèmes contenant des séquences, telles que des données de texte ou de série chronologique. Ils sont constitués de deux couches : l'encodeur et le décodeur. L’encodeur prend une entrée et la mappe avec une représentation numérique contenant des informations telles que le contexte. Le décodeur utilise les informations de l'encodeur pour produire une sortie telle qu'un texte traduit. Ce qui différencie les transformateurs des autres architectures contenant des encodeurs et des décodeurs, ce sont les sous-couches d'attention. L’attention consiste à se concentrer sur des parties spécifiques d’une entrée en fonction de l’importance de leur contexte par rapport à d’autres entrées dans une séquence. Par exemple, lorsqu’un modèle résume un article d’actualité, toutes les phrases ne sont pas pertinentes pour décrire l’idée principale. En se concentrant sur les mots clés de l'article, le résumé peut se faire en une seule phrase, le titre.
Les transformateurs sont utilisés pour résoudre les problèmes de traitement du langage naturel tels que la traduction, la génération de texte, la réponse aux questions et le résumé du texte.
Exemples d’implémentations connues des transformateurs :
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT-2 (Generative Pre-trained Transformer 2)
- GPT-3 (Generative Pre-trained Transformer 3)
Étapes suivantes
Les articles suivants décrivent d’autres options d’utilisation de modèles d’apprentissage profond open source dans Azure Machine Learning :