Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’une des plus grandes difficultés avec les pratiques de débogage de modèle actuelles est l’utilisation de métriques agrégées pour scorer des modèles sur un jeu de données de référence. La justesse des modèles risque de ne pas être uniforme pour les différents sous-groupes de données, et il risque d’y avoir des cohortes d’entrée pour lesquelles le modèle échoue plus souvent. Les conséquences directes de ces défaillances sont un manque de fiabilité et de sécurité, l’apparition de problèmes d’impartialité et une perte de confiance dans le machine learning en général.

L’analyse des erreurs s’éloigne des métriques de justesse agrégées. Elle expose la distribution des erreurs aux développeurs de manière transparente, et leur permet d’identifier et de diagnostiquer efficacement les erreurs.
Le composant Analyse des erreurs du tableau de bord IA responsable fournit aux utilisateurs du machine learning une compréhension plus approfondie de la distribution des défaillances de modèle, et les aide à identifier rapidement les cohortes de données erronées. Ce composant identifie les cohortes de données présentant un taux d’erreur plus élevé que le taux d’erreur global de référence. Il contribue à la phase d’identification du workflow de cycle de vie des modèles via :
- Un arbre de décision qui révèle les cohortes avec des taux d’erreur élevés.
- Carte thermique qui visualise la façon dont les caractéristiques d’entrée affectent le taux d’erreur parmi les cohortes.
Des écarts dans les erreurs peuvent se produire lorsque le système sous-performe pour des groupes démographiques spécifiques ou des cohortes d’entrée rarement observées dans les données d’entraînement.
Les fonctionnalités de ce composant proviennent du package Error Analysis, qui génère des profils d’erreur de modèle.
Utilisez l’analyse des erreurs lorsque vous devez :
- Acquérir une compréhension approfondie de la manière dont les défaillances de modèle sont distribuées dans un jeu de données et dans plusieurs dimensions d’entrée et de caractéristique.
- Décomposer les métriques de performances agrégées pour découvrir automatiquement les cohortes erronées afin de documenter vos étapes d’atténuation ciblées.
Arborescence d’erreurs
Souvent, les schémas d’erreurs sont complexes et impliquent plus d’une ou deux caractéristiques. Les développeurs risquent de rencontrer des difficultés à explorer toutes les combinaisons possibles de caractéristiques pour découvrir des poches de données cachées présentant des défaillances critiques.
Pour alléger la charge, la visualisation de l’arborescence binaire partitionne automatiquement les données de référence en sous-groupes interprétables qui présentent des taux d’erreur étonnamment élevés ou bas. En d’autres termes, l’arborescence utilise les caractéristiques d’entrée pour séparer au maximum l’erreur du modèle de la réussite. Pour chaque nœud qui définit un sous-groupe de données, les utilisateurs peuvent investiguer les informations suivantes :
- Taux d’erreur : Portion des instances du nœud pour lesquelles le modèle est incorrect. Il est illustré par l’intensité de la couleur rouge.
- Couverture des erreurs : Portion de toutes les erreurs présentes dans le nœud. Elle est illustrée par le taux de remplissage du nœud.
- Représentation des données : Nombre d’instances dans chaque nœud de l’arborescence d’erreurs. Elle est illustrée par l’épaisseur du bord entrant du nœud, ainsi que le nombre total d’instances qu’il contient.

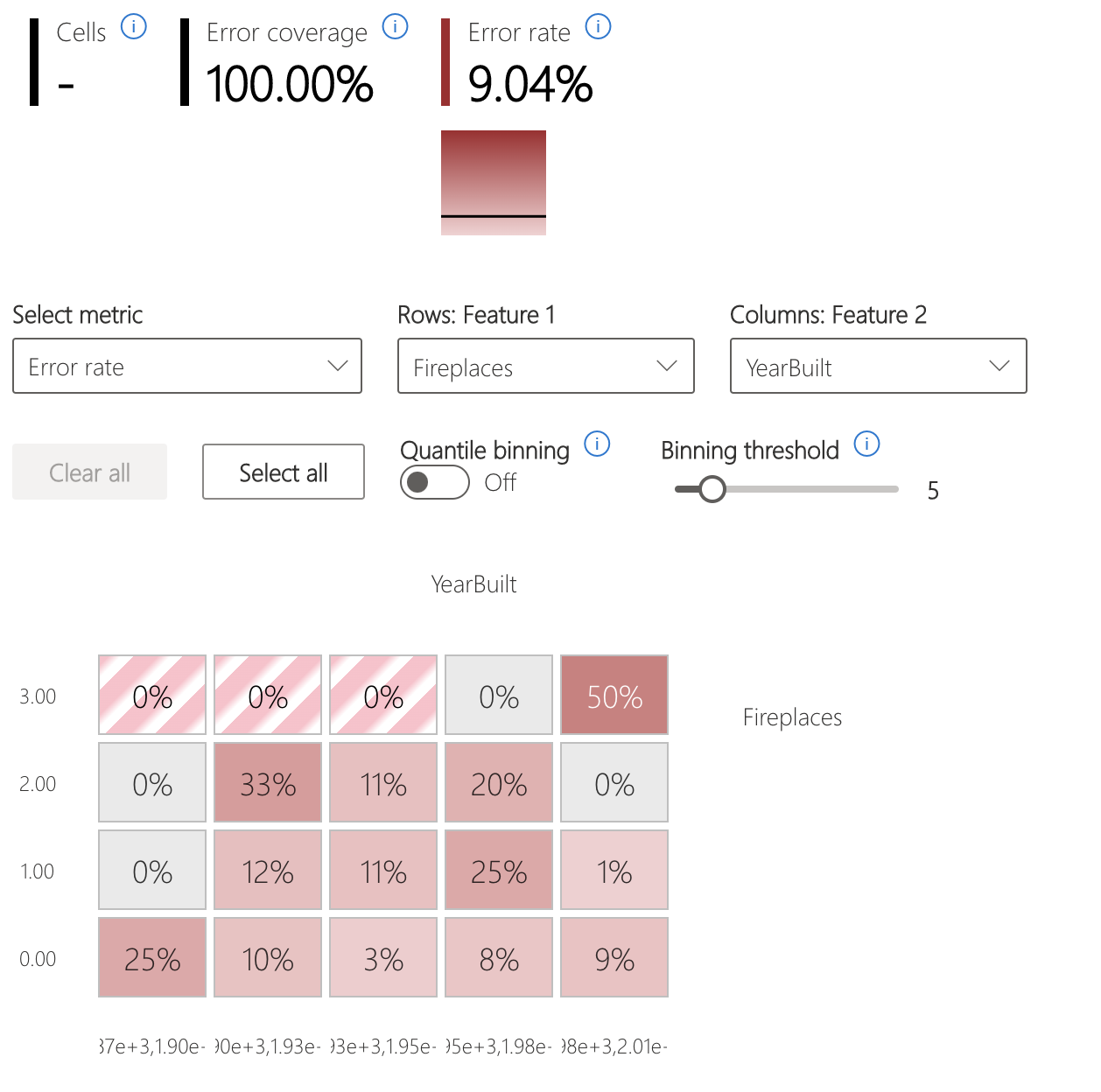
Carte thermique des erreurs
La vue segmente les données selon une grille unidimensionnelle ou bidimensionnelle de caractéristiques d’entrée. Les utilisateurs peuvent choisir les caractéristiques d’entrée intéressantes pour l’analyse.
La carte thermique visualise les cellules avec beaucoup d’erreurs en utilisant une couleur rouge plus foncée pour attirer l’attention de l’utilisateur sur ces régions. Cette fonctionnalité est particulièrement bénéfique lorsque les thèmes d’erreur diffèrent selon les partitions, ce qui se produit souvent en pratique. Dans cette vue d’identification des erreurs, l’analyse est fortement orientée par les utilisateurs et leurs connaissances ou hypothèses sur les caractéristiques susceptibles d’être les plus importantes pour comprendre les défaillances.
Étapes suivantes
- Découvrez comment générer le tableau de bord d’IA responsable par le biais de CLIv2 et SDKv2 ou de l’interface utilisateur d’Azure Machine Learning studio.
- Explorez les visualisations d’analyse des erreurs prises en charge.
- Découvrez comment générer une carte de performance d’IA responsable basée sur des insights observées dans le tableau de bord d’IA responsable.