Autorisation sur les points de terminaison de traitement par lots
Les points de terminaison par lots prennent en charge l’authentification Microsoft Entra ou aad_token. Cela signifie que pour appeler un point de terminaison par lots, l’utilisateur doit présenter un jeton d’authentification Microsoft Entra valide à l’URI du point de terminaison par lots. L’autorisation est appliquée au niveau du point de terminaison. L’article suivant explique comment interagir correctement avec les points de terminaison par lots et les exigences de sécurité associées.
Fonctionnement de l’autorisation
Pour appeler un point de terminaison par lots, l’utilisateur doit présenter un jeton Microsoft Entra valide représentant un principal de sécurité. Ce principal peut être un principal d’utilisateur ou un principal de service. Dans tous les cas, une fois qu’un point de terminaison est appelé, un travail de déploiement par lots est créé sous l’identité associée au jeton. L’identité a besoin des autorisations suivantes pour créer un travail :
- Lisez les points de terminaison/déploiements par lots.
- Créez des travaux dans les points de terminaison/déploiement d’inférence par lots.
- Créez des expériences/exécutions.
- Lisez et écrivez à partir de/vers des banques de données.
- Répertorie les secrets de la banque de données.
Consultez Configurer RBAC pour l’appel de points de terminaison par lot pour obtenir une liste détaillée des autorisations RBAC.
Important
L’identité utilisée pour appeler un point de terminaison par lots peut ne pas être utilisée pour lire les données sous-jacentes en fonction de la configuration de la banque de données. Pour plus d’informations, consultez Configurer des clusters de calcul pour l’accès aux données.
Comment exécuter des travaux à l’aide de différents types d’informations d’identification
Les exemples suivants montrent différentes façons de démarrer des travaux de déploiement par lots à l’aide de différents types d’informations d’identification :
Important
Quand vous travaillez sur des espaces de travail acceptant les liaisons privées, les points de terminaison par lots ne peuvent pas être appelés à partir de l’interface utilisateur dans Azure Machine Learning studio. Utilisez plutôt Azure Machine Learning CLI v2 pour la création de travaux.
Prérequis
- Cet exemple suppose que vous disposez d’un modèle correctement déployé en tant que point de terminaison par lots. En particulier, nous utilisons le classifieur de condition cardiaque créé dans le tutoriel Utilisation de modèles MLflow dans les déploiements par lots.
Exécution de travaux à l’aide des informations d’identification de l’utilisateur
Dans ce cas, nous allons exécuter un point de terminaison par lots en utilisant l’identité de l’utilisateur actuellement connecté. Suivez ces étapes :
Utilisez Azure CLI pour vous connecter à l’aide de l’authentification interactive ou par code d’appareil :
az loginUne fois authentifié, utilisez la commande suivante pour exécuter un travail de déploiement par lots :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Exécuter des travaux en utilisant un principal de service
Dans ce cas, nous allons exécuter un point de terminaison par lots en utilisant un principal de service déjà créé dans Microsoft Entra ID. Vous devez créer un secret pour effectuer l’authentification. Procédez comme suit :
Créez un secret à utiliser pour l’authentification comme expliqué dans Option 3 : créer une clé secrète client.
Pour vous authentifier à l’aide d’un principal de service, utilisez la commande suivante. Pour plus de détails, consultez Se connecter avec Azure CLI.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>Une fois authentifié, utilisez la commande suivante pour exécuter un travail de déploiement par lots :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
Exécution de travaux à l’aide d’une identité managée
Vous pouvez utiliser des identités managées pour appeler le point de terminaison et les déploiements par lots. Notez que cette identité managée n’appartient pas au point de terminaison par lots. Il s’agit de l’identité utilisée pour exécuter le point de terminaison et donc créer un programme de traitement par lots. Les identités affectées par l’utilisateur et affectées par le système peuvent être utilisées dans ce scénario.
Sur les ressources configurées pour des identités managées pour les ressources Azure, vous pouvez vous connecter avec l’identité managée. La connexion avec l’identité de la ressource s’effectue via l’indicateur --identity. Pour plus de détails, consultez Se connecter avec Azure CLI.
az login --identity
Une fois authentifié, utilisez la commande suivante pour exécuter un travail de déploiement par lots :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Configurer RBAC pour l’appel de points de terminaison par lot
Les points de terminaison par lot exposent une API durable que les consommateurs peuvent utiliser pour générer des travaux. L’appelant demande l’autorisation appropriée pour pouvoir générer ces travaux. Vous pouvez utiliser l’un des rôles de sécurité intégrés ou créer un rôle personnalisé à cet effet.
Pour appeler un point de terminaison par lot, vous avez besoin des actions explicites suivantes accordées à l’identité utilisée pour appeler les points de terminaison. Pour obtenir des instructions sur l’attribution d’un rôle Azure, consultez Étapes d’attribution d’un rôle Azure.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
Configurer des clusters de calcul pour l’accès aux données
Les points de terminaison par lots garantissent que seuls les utilisateurs autorisés sont en mesure d’appeler des déploiements par lots et de générer des travaux. Toutefois, selon la façon dont les données d’entrée sont configurées, d’autres informations d’identification peuvent être utilisées pour lire les données sous-jacentes. Utilisez le tableau ci-dessous pour comprendre les informations d’identification utilisées :
| Type d'entrée des données | Informations d’identification dans la banque | Informations d’identification utilisées | Accès accordé par |
|---|---|---|---|
| Banque de données | Oui | Informations d’identification de la banque de données dans l’espace de travail | Clé d’accès ou SAP |
| Ressource de données | Oui | Informations d’identification de la banque de données dans l’espace de travail | Clé d’accès ou SAP |
| Banque de données | Non | Identité du travail + identité managée du cluster de calcul | RBAC |
| Ressource de données | Non | Identité du travail + identité managée du cluster de calcul | RBAC |
| Stockage Blob Azure | Ne pas appliquer | Identité du travail + identité managée du cluster de calcul | RBAC |
| Azure Data Lake Storage Gen1 | Ne pas appliquer | Identité du travail + identité managée du cluster de calcul | POSIX |
| Azure Data Lake Storage Gen2 | Ne pas appliquer | Identité du travail + identité managée du cluster de calcul | POSIX et RBAC |
Pour ces éléments de la table où l’identité du travail + identité managée du cluster de calcul sont affichées, l’identité managée du cluster de calcul est utilisée pour le montage et la configuration des comptes de stockage. Toutefois, l’identité de la tâche est encore utilisée afin de lire les données sous-jacentes, ce qui vous permet d’obtenir un contrôle d’accès granulaire. Cela signifie que, pour lire correctement les données du stockage, l’identité managée du cluster de calcul sur lequel le déploiement s’exécute doit disposer au moins d’un accès Lecteur de données blob de stockage au compte de stockage.
Pour configurer le cluster de calcul pour l’accès aux données, procédez comme suit :
Accédez à Azure Machine Learning Studio.
Accédez au calcul, puis aux clusters de calcul, puis sélectionnez le cluster de calcul que votre déploiement utilise.
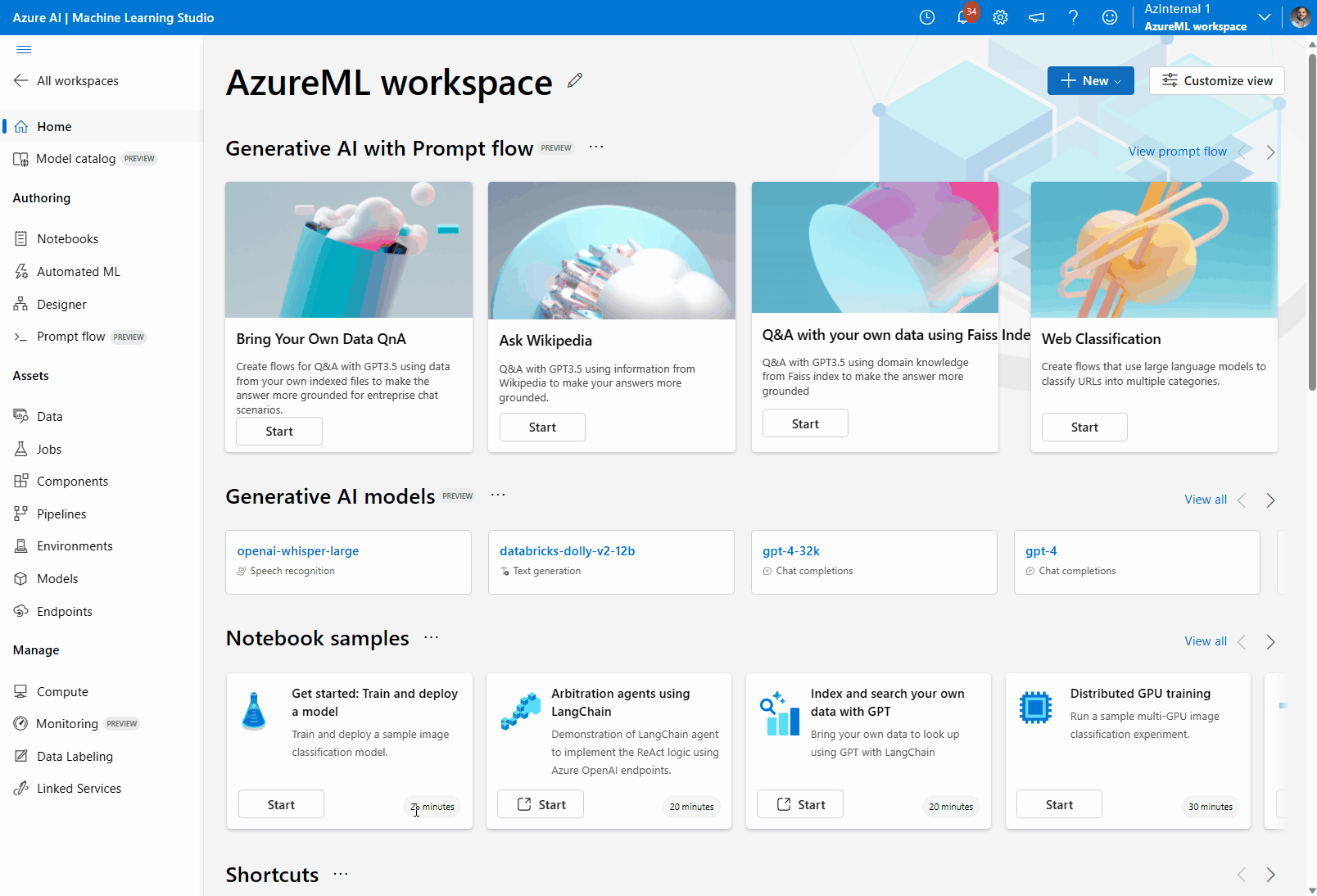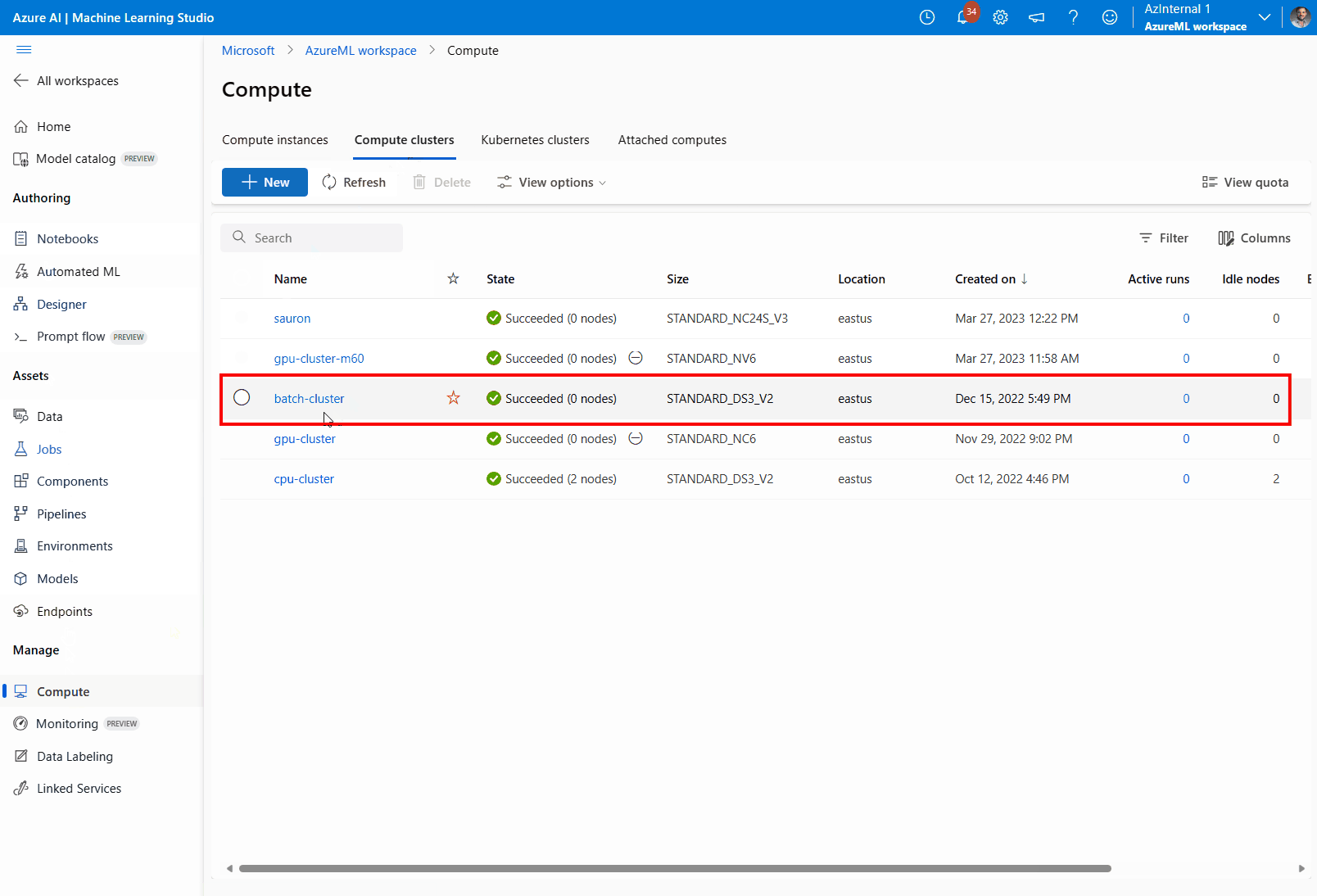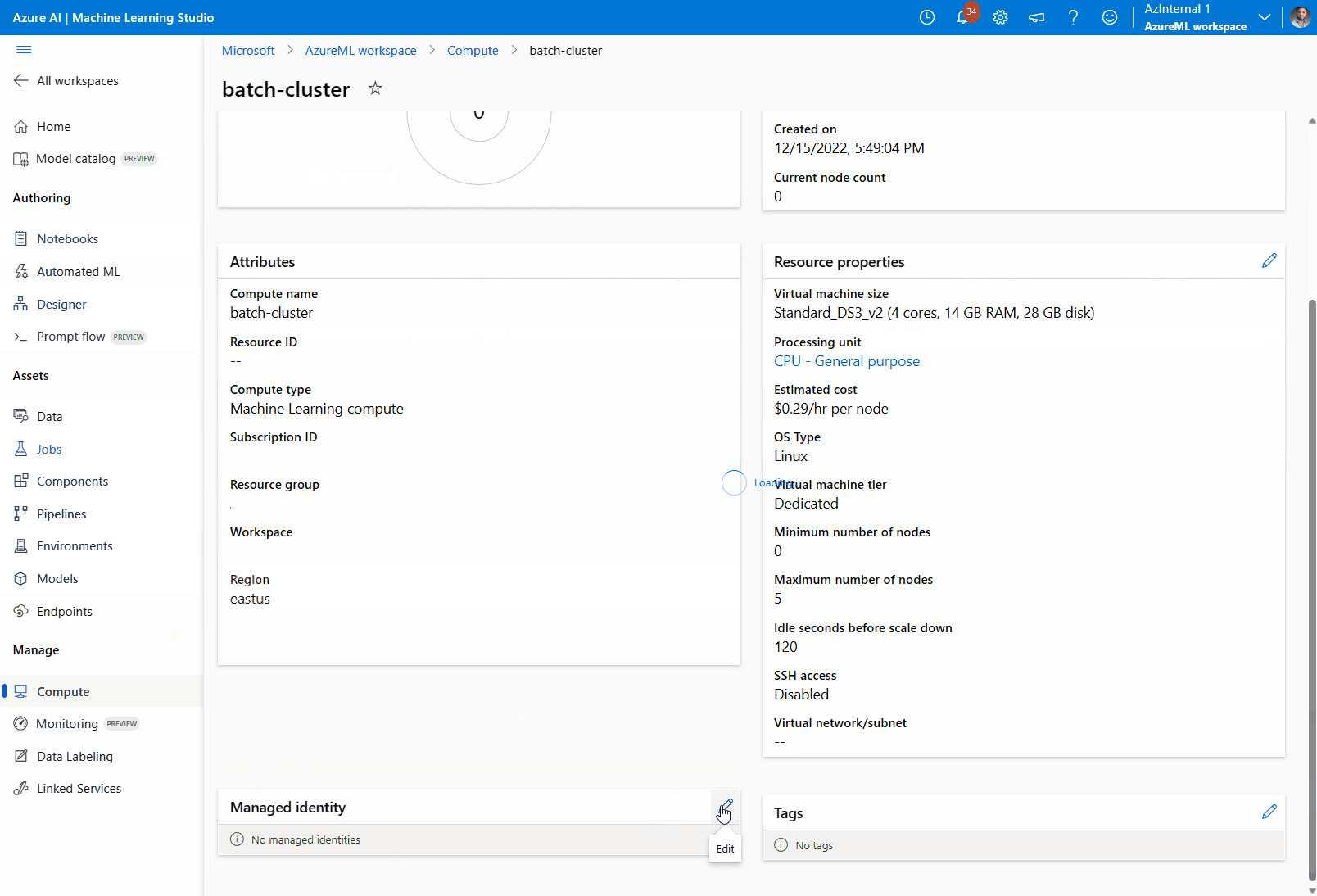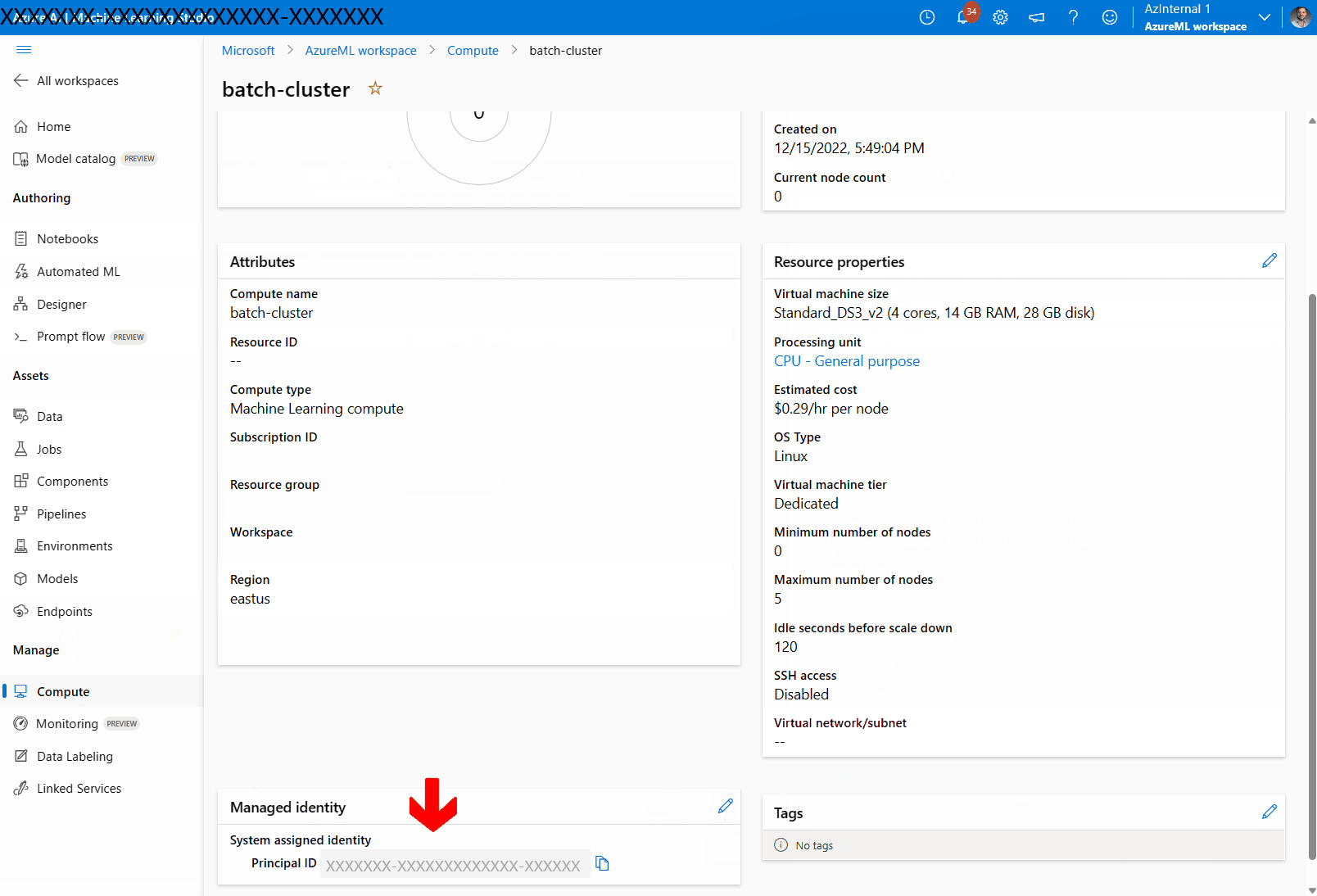
Attribuez une identité managée au cluster de calcul :
Dans la section Identité managée, vérifiez si le calcul a une identité managée attribuée. Si ce n’est pas le cas, sélectionnez l’option Modification.
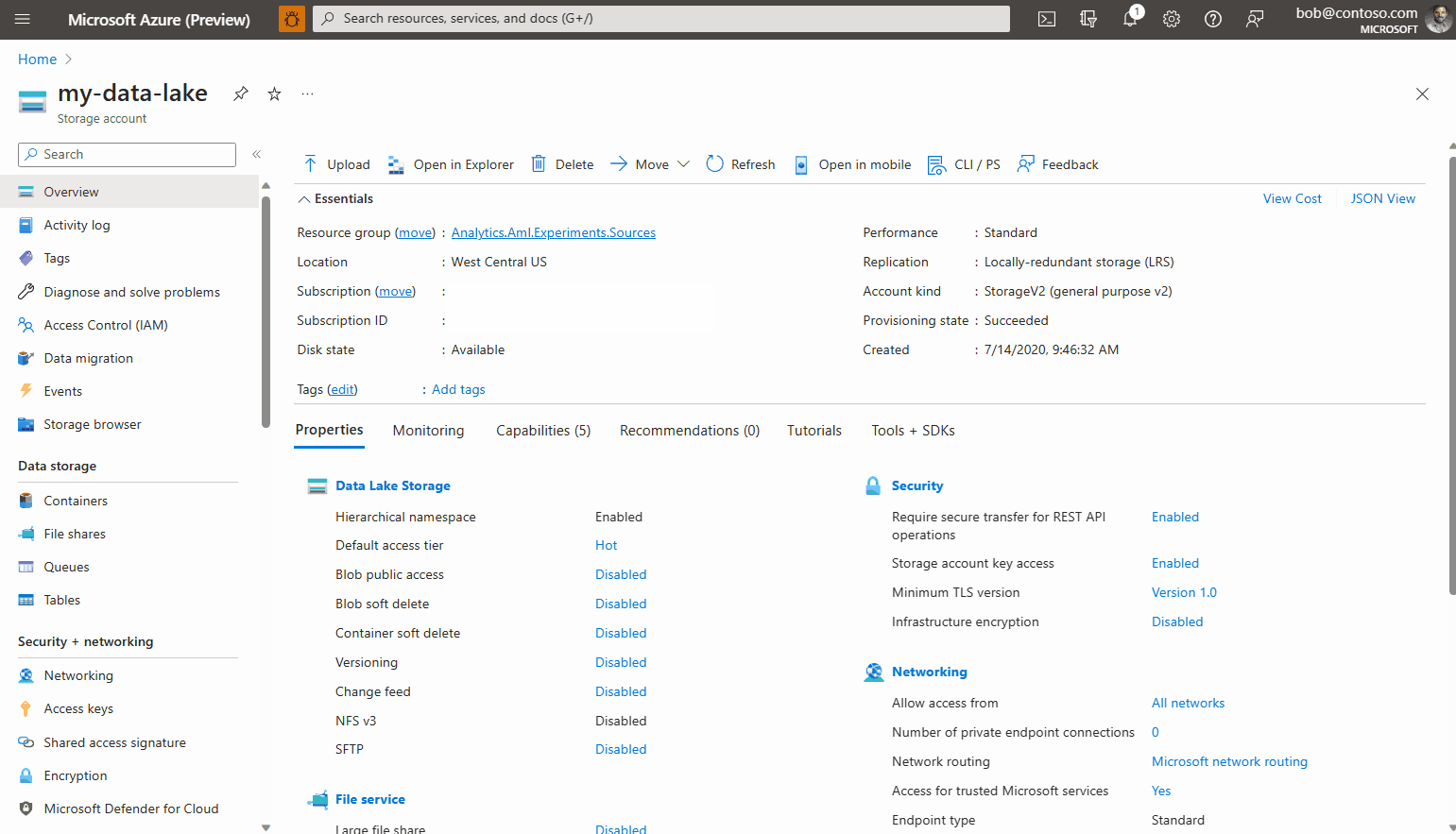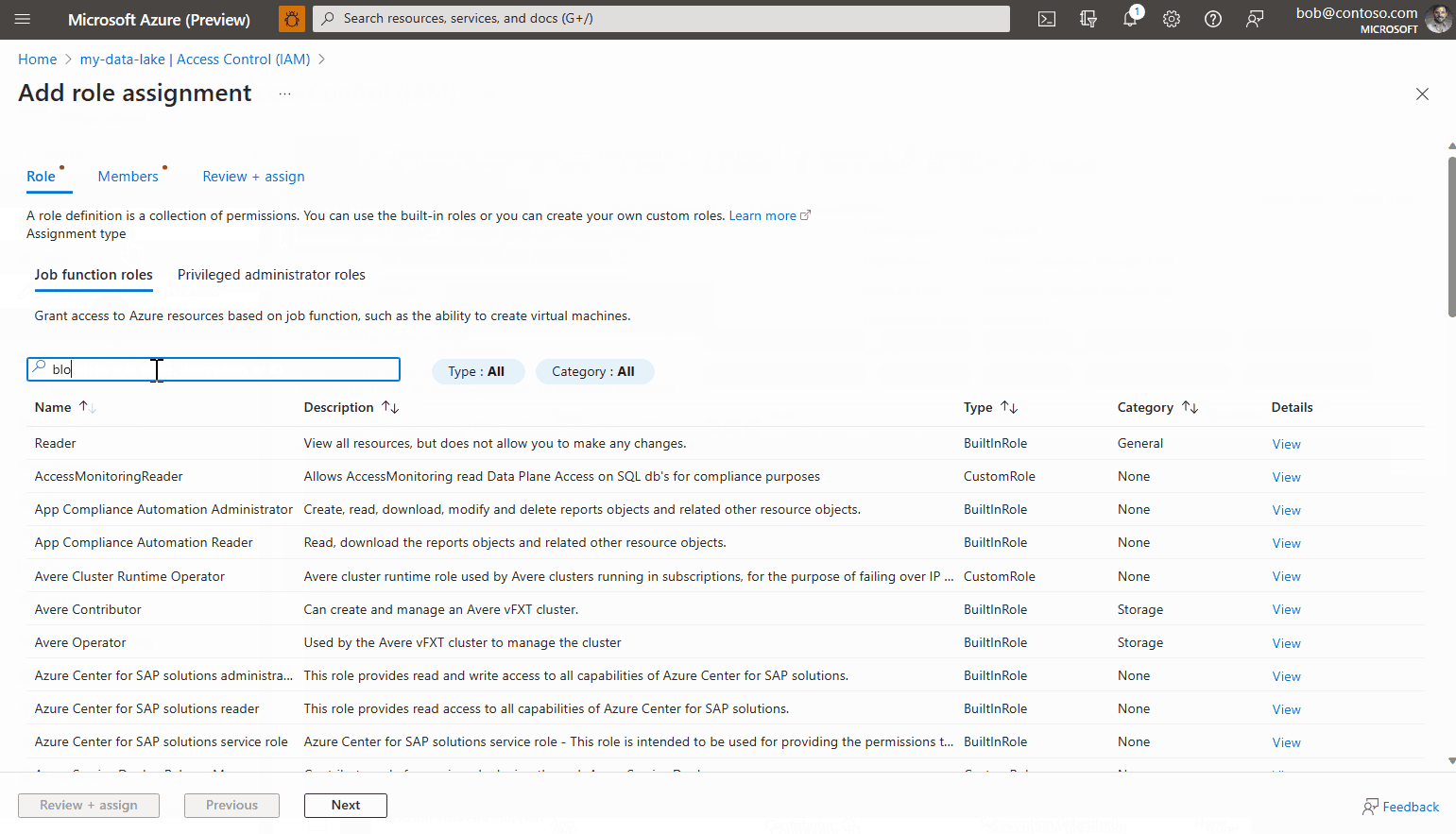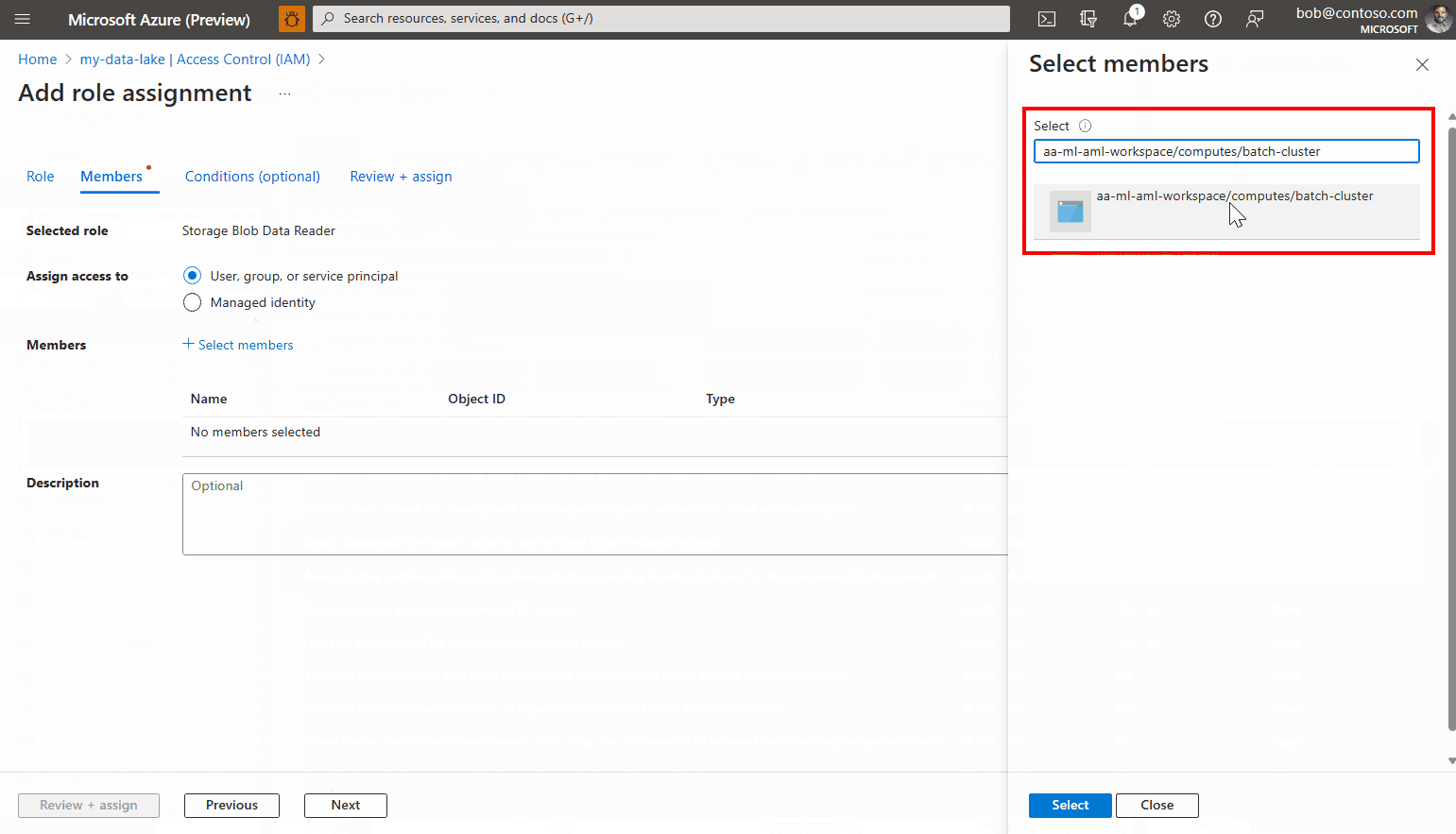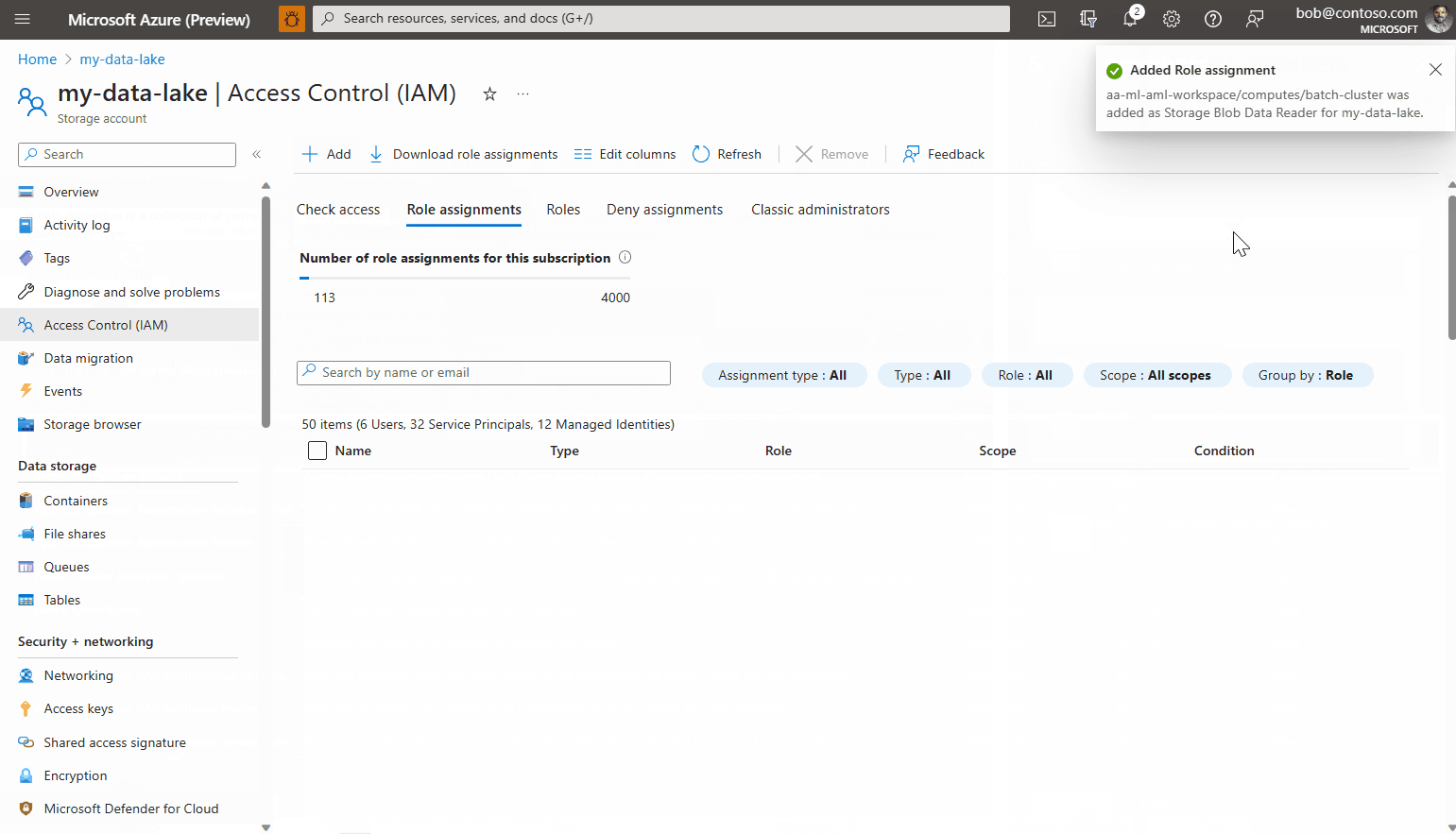
Sélectionnez Attribuer une identité managée et configurez-la si nécessaire. Vous pouvez utiliser une identité managée affectée par le système ou une identité managée affectée par l’utilisateur. Si vous utilisez une identité managée affectée par le système, elle est nommée « [workspace name]/computes/[compute cluster name] ».
Enregistrez les modifications.
Accédez au Portail Azure et accédez au compte de stockage associé où se trouvent les données. Si votre entrée de données est une ressource de données ou un magasin de données, recherchez le compte de stockage où ces ressources sont placées.
Attribuez le niveau d’accès Lecteur de données blob du stockage dans le compte de stockage :
Accédez à la section Contrôle d’accès (IAM).
Sélectionnez l’onglet Attribution de rôle, puis cliquez sur Ajouter une >attribution de rôle.
Recherchez le rôle nommé Lecteur de données Blob du stockage, sélectionnez-le, puis cliquez sur Suivant.
Cliquez sur Sélectionner des membres.
Recherchez l’identité managée que vous avez créée. Si vous utilisez une identité managée affectée par le système, elle est nommée « [workspace name]/computes/[compute cluster name] ».
Ajoutez le compte et terminez l’Assistant.
Votre point de terminaison est prêt à recevoir des travaux et des données d’entrée à partir du compte de stockage sélectionné.