Créer et exécuter des pipelines de Machine Learning avec le kit SDK Azure Machine Learning
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Dans cet article, vous allez apprendre à créer et exécuter un pipeline Machine Learning à l’aide du Kit de développement logiciel (SDK) Azure Machine Learning. Les pipelines ML vous permettent de créer un workflow qui associe plusieurs phases ML. Publiez ensuite ce pipeline pour y accéder ou le partager par la suite avec d’autres utilisateurs. Suivez les pipelines ML pour voir comment votre modèle s’exécute dans la réalité et pour détecter une dérive de données. Les pipelines ML sont idéaux pour les scénarios de scoring par lots car ils utilisent différents calculs, réutilisent les étapes au lieu de les réexécuter et partagent les flux de travail ML avec d’autres.
Cet article n’est pas un tutoriel. Pour obtenir de l’aide sur la création de votre premier pipeline, consultez Didacticiel : Créer un pipeline Azure Machine Learning pour le scoring par lots ou Utiliser le ML automatisé dans un pipeline Azure Machine Learning dans Python.
Vous pouvez utiliser un autre type de pipeline appelé pipeline Azure pour l’automatisation CI/CD des tâches de ML, mais ce type de pipeline n’est pas stocké dans votre espace de travail. Comparez ces différents pipelines.
Les pipelines ML que vous créez sont visibles par les membres de votre espace de travail d’Azure Machine Learning.
Les pipelines ML s’exécutent sur des cibles de calcul (consultez Qu’est-ce qu’une cible de calcul dans Azure Machine Learning ?). Les pipelines peuvent lire et écrire des données à partir/vers les emplacements de Stockage Azure pris en charge.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Prérequis
Un espace de travail Azure Machine Learning. Créer des ressources d’espace de travail.
Configurez votre environnement de développement pour installer le SDK Azure Machine Learning ou utilisez une instance de calcul Azure Machine Learning avec le SDK déjà installé.
Commencez par attacher votre espace de travail :
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Configurer des ressources Machine Learning
Créez les ressources requises pour exécuter un pipeline ML :
Configurez un magasin de données permettant d’accéder aux données requises pour les étapes du pipeline.
Configurez un objet
Datasetqui pointe vers les données persistantes qui se trouvent dans un magasin de données ou qui sont accessibles à partir de ce biais. Configurez un objetOutputFileDatasetConfigpour les données temporaires passées entre les étapes du pipeline.Configurez les cibles de calcul sur lesquelles vous souhaitez que les étapes du pipeline s’exécutent.
Configurer un magasin de données
Le magasin de données stocke les données accessibles par le pipeline. Chaque espace de travail dispose d’un magasin de données par défaut. Vous pouvez inscrire des magasins de données supplémentaires.
Lorsque vous créez votre espace de travail, des éléments Azure Files et de stockage d’objets Blob Azure sont joints à l’espace de travail. Une banque de données par défaut est inscrite pour se connecter au stockage d’objets blob Azure. Pour en savoir plus , voir Quand utiliser des fichiers Azure, des objets blob Azure, des fichiers Azure ou des disques Azure.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Les étapes consomment généralement des données et produisent des données de sortie. Une étape peut créer des données telles qu’un modèle, un répertoire avec un modèle et des fichiers dépendants ou des données temporaires. Ces données sont ensuite mises à disposition des autres étapes du pipeline. Pour en savoir plus sur la connexion de votre pipeline à vos données, consultez les articles Comment accéder aux données et Comment inscrire des jeux de données.
Configurer des données avec des objets Dataset et OutputFileDatasetConfig
Le meilleur moyen de fournir des données à un pipeline est un objet DataSet. L’objet Dataset pointe vers les données qui se trouvent dans un magasin de données ou qui sont accessibles par ce biais ou à une URL web. La classe Dataset étant abstraite, vous allez créer une instance de FileDataset (faisant référence à un ou plusieurs fichiers) ou un TabularDataset créé à partir d’un ou de plusieurs fichiers avec des colonnes de données délimitées.
Vous créez un Dataset à l’aide de méthodes comme from_file ou from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Les données intermédiaires (ou la sortie d’une étape) sont représentées par un objet OutputFileDatasetConfig. output_data1 est généré en tant que sortie d’une étape. Si vous le souhaitez, ces données peuvent être inscrites en tant que jeu de données en appelant register_on_complete. Si vous créez un OutputFileDatasetConfig dans une étape et l’utilisez en tant qu’entrée pour une autre étape, cette dépendance de données entre les étapes crée un ordre d’exécution implicite dans le pipeline.
Les objetsOutputFileDatasetConfig retournent un répertoire et, par défaut, écrivent la sortie dans le magasin de données par défaut de l’espace de travail.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Important
Les données intermédiaires stockées à l’aide de OutputFileDatasetConfig ne sont pas automatiquement supprimées par Azure.
Vous devez supprimer programmatiquement les données intermédiaires à la fin de l’exécution d’un pipeline, utiliser un magasin de données avec une stratégie de conservation des données courte ou effectuer régulièrement un nettoyage manuel.
Conseil
Chargez uniquement les fichiers en rapport avec le travail en cours. Toute modification apportée aux fichiers dans le répertoire de données sera considérée comme une raison de réexécuter l’étape lors de la prochaine exécution du pipeline, même si la réutilisation est spécifiée.
Configurer une cible de calcul
Dans Azure Machine Learning, le calcul des termes (ou la cible de calcul) fait référence aux machines ou aux clusters qui effectuent les étapes de calculs de votre pipeline Machine Learning. Consultez Cibles de calcul pour effectuer l’entraînement des modèles pour obtenir la liste complète des cibles de calcul et Créer des cibles de calcul pour savoir comment les créer et les joindre à votre espace de travail. Le processus de création et/ou d’attachement d’une cible de calcul est le même, qu’il s’agisse d’effectuer l’apprentissage d’un modèle ou d’exécuter une étape de pipeline. Une fois que vous avez créé et joint votre cible de calcul, utilisez l’objet ComputeTarget dans votre étape de pipeline.
Important
L’exécution d’opérations de gestion sur les cibles de calcul n’est pas prise en charge au sein des travaux distants. Les pipelines de Machine Learning étant envoyés sous forme de travail distant, n’effectuez pas d’opérations de gestion sur les cibles de calcul au sein du pipeline.
Capacité de calcul Azure Machine Learning
Vous pouvez créer une capacité de calcul Azure Machine Learning pour exécuter vos étapes. Le code pour les autres cibles de calcul est très similaire avec des paramètres légèrement différents selon le type.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Configurer l’environnement d’exécution d’apprentissage
L’étape suivante consiste à s’assurer que l’exécution de l’apprentissage à distance englobe toutes les dépendances qu’exigent les étapes d’apprentissage. Les dépendances et le contexte du runtime sont définis en créant et en configurant un objet RunConfiguration.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Le code ci-dessus présente deux options pour la gestion des dépendances. Comme présenté, avec USE_CURATED_ENV = True, la configuration est basée sur un environnement organisé. Les environnements organisés sont préparés avec des bibliothèques interdépendantes communes et peuvent être plus rapides à mettre en ligne. Les environnements organisés comportent des images Docker prédéfinies dans le Registre de conteneurs Microsoft. Pour plus d’informations, consultez Environnements organisés Azure Machine Learning.
Le chemin emprunté si vous remplacez USE_CURATED_ENV par False affiche le modèle pour la définition explicite de vos dépendances. Dans ce scénario, une nouvelle image Docker personnalisée sera créée et inscrite dans un Azure Container Registry au sein de votre groupe de ressources (consultez Présentation des registres de conteneurs Docker privés dans Azure). La création et l’inscription de cette image peuvent prendre du temps.
Composer les étapes de votre pipeline
Une fois que vous avez créé la ressource et l’environnement de calcul, vous êtes prêt à définir les étapes de votre pipeline. De nombreuses étapes intégrées sont disponibles via le kit de développement logiciel (SDK) Azure Machine Learning, comme vous pouvez le voir dans la documentation de référence pour le package azureml.pipeline.steps. La classe la plus flexible est PythonScriptStep, qui exécute un script Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Le code ci-dessus illustre une étape initiale de pipeline classique. Votre code de préparation des données se trouve dans un sous-répertoire (dans cet exemple, "prepare.py" dans le répertoire "./dataprep.src"). Dans le cadre du processus de création du pipeline, ce répertoire est compressé et chargé dans le compute_target et l’étape exécute le script spécifié comme valeur pour script_name.
La valeurs arguments spécifient les entrées et sorties de l’étape. Dans l’exemple ci-dessus, les données de ligne de base sont le jeu de données my_dataset. Les données correspondantes sont téléchargées vers la ressource de calcul, car le code les spécifie comme as_download(). Le script prepare.py effectue toutes les tâches de transformation de données appropriées pour la tâche en cours et renvoie les données à output_data1, de type OutputFileDatasetConfig. Pour plus d’informations, consultez Déplacement de données au sein d’un pipeline ML et vers un autre pipeline ML (Python).
L’étape s’exécute sur la machine définie par compute_target à l’aide de la configuration aml_run_config.
La réutilisation des résultats précédents (allow_reuse) est essentielle lors de l’utilisation des pipelines dans un environnement de collaboration. En effet, cela permet de supprimer les réexécutions inutiles et ainsi d’offrir une grande souplesse. La réutilisation est le comportement par défaut quand le nom du script, les entrées et les paramètres d’une étape restent les mêmes. Lorsque la réutilisation est autorisée, les résultats de l’exécution précédente sont envoyés immédiatement à l’étape suivante. Si allow_reuse a la valeur False, une nouvelle exécution sera toujours générée pour cette étape pendant l’exécution du pipeline.
Il est possible de créer un pipeline en une seule étape, mais vous choisirez presque toujours de fractionner votre processus global en plusieurs étapes. Par exemple, vous pouvez avoir des étapes pour la préparation des données, la formation, la comparaison des modèles et le déploiement. Par exemple, vous pouvez imaginer qu’après la data_prep_step spécifiée ci-dessus, l’étape suivante peut être une formation :
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Le code ci-dessus est similaire au code de l’étape de préparation des données. Le code de formation se trouve dans un répertoire distinct de celui du code de préparation des données. La sortie OutputFileDatasetConfig de l’étape de préparation des données, output_data1, est utilisée comme entrée à l’étape de formation. Un nouvel objet OutputFileDatasetConfig, training_results, est créé pour contenir les résultats d’une étape de comparaison ou de déploiement ultérieure.
Pour obtenir d’autres exemples de code, consultez Comment générer un pipeline ML en deux étapes et Comment écrire des données dans des magasins de données à la fin de l’exécution.
Après avoir défini vos étapes, vous générez le pipeline à l’aide de tout ou partie de ces étapes.
Notes
Aucune donnée ni fichier n’est téléchargé sur Azure Machine Learning lorsque vous définissez les étapes ou générez le pipeline. Les fichiers sont chargés quand vous appelez Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Utiliser un jeu de données
Les jeux de données créés depuis Stockage Blob Azure, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database et Azure Database pour PostgreSQL peuvent être utilisés comme entrée pour n'importe quelle étape de pipeline. Vous pouvez écrire la sortie dans un objet DataTransferStep ou DatabricksStep ou bien, si vous souhaitez écrire les données dans un magasin de données spécifique, utilisez OutputFileDatasetConfig.
Important
L’écriture de données de sortie dans un magasin de données à l’aide de OutputFileDatasetConfig est prise en charge uniquement pour un objet blob Azure, un partage de fichiers Azure et les magasins de données ADLS Gen 1 ou Gen 2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Vous récupérez ensuite le jeu de données dans votre pipeline à l’aide du dictionnaire Run.input_datasets.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
La ligne Run.get_context() mérite d’être soulignée. Cette fonction récupère un Run représentant l’exécution expérimentale en cours. Dans l’exemple ci-dessus, nous l’utilisons pour récupérer un jeu de données enregistré. Une autre utilisation courante de l’objet Run consiste à récupérer à la fois l’expérimentation elle-même et l’espace de travail dans lequel elle réside :
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Pour plus d’informations, notamment sur les autres façons de transmettre et d’accéder aux données, consultez Déplacement de données au sein d’un pipeline ML et vers un autre pipeline ML (Python).
Mise en cache et réutilisation
Pour optimiser et personnaliser le comportement de vos pipelines, vous pouvez effectuer quelques opérations autour de la mise en cache et de la réutilisation. Par exemple, vous pouvez choisir :
- De désactiver la réutilisation par défaut de la sortie d’exécution de l’étape en définissant
allow_reuse=Falsependant la définition de l’étape. La réutilisation est essentielle lors de l’utilisation des pipelines dans un environnement de collaboration. En effet, cela permet de supprimer les exécutions inutiles et ainsi d’offrir une grande souplesse. Toutefois, vous pouvez refuser la réutilisation. - De forcer la régénération de sortie pour toutes les étapes dans une exécution avec
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Par défaut, allow_reuse pour les étapes est activé et le source_directory spécifié dans la définition de l’étape est haché. Par conséquent, si le script pour une étape donnée reste le même (script_name, entrées et les paramètres) et que rien d’autre n’a changé dans le source_directory, la sortie d’une exécution d’étape précédente est réutilisée, le travail n’est pas envoyé pour le calcul et les résultats de l’exécution précédente sont immédiatement disponibles pour l’étape suivante à la place.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Notes
Si les noms des entrées de données sont modifiés, l’étape est réexécutée, même si les données soulignées n’ont pas changées. Vous devez explicitement définir le champ name des données d’entrée (data.as_input(name=...)). Si vous ne définissez pas explicitement cette valeur, le champ name est défini sur un guid aléatoire et les résultats de l’étape ne sont pas réutilisés.
Envoyer le pipeline
Lorsque vous envoyez le pipeline, Azure Machine Learning vérifie les dépendances pour chaque étape et charge un instantané du répertoire source que vous avez spécifié. Si aucun répertoire source n’est spécifié, le répertoire local actuel est chargé. La capture instantanée est également stockée dans le cadre de l’expérience dans votre espace de travail.
Important
Pour empêcher que les fichiers inutiles soient inclus dans l’instantané, créez un fichier « ignore» (.gitignore ou .amlignore) dans le répertoire. Ajoutez dans ce fichier les fichiers et répertoires à exclure. Pour plus d’informations sur la syntaxe à utiliser dans ce fichier, consultez syntaxe et modèles pour .gitignore. Le fichier .amlignore utilise la même syntaxe. Si les deux fichiers existent, le fichier .amlignore est utilisé, et non le fichier .gitignore.
Pour plus d’informations, consultez Instantanés.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
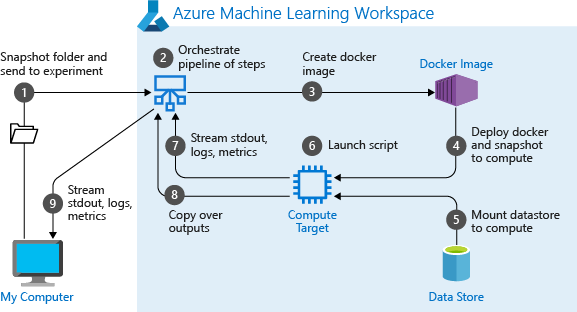
Lorsque vous exécutez un pipeline pour la première fois, Azure Machine Learning :
Télécharge l’instantané du projet sur la cible de calcul à partir du stockage d’objets Blob associé à l’espace de travail.
Génère une image docker correspondant à chaque étape du pipeline.
Télécharge l’image Docker de chaque étape sur la cible de calcul à partir du registre de conteneurs.
Configure l’accès aux objets
DatasetetOutputFileDatasetConfig. Pour le mode d’accèsas_mount(), FUSE est utilisé pour fournir un accès virtuel. Si le montage n’est pas pris en charge ou si l’utilisateur spécifié y accède en tant queas_upload(), les données sont alors copiées sur la cible de calcul.Exécute l’étape dans la cible de calcul spécifiée dans la définition de l’étape.
Crée les artefacts tels que les journaux d’activité, stdout et stderr,les métriques mesures et la sortie spécifiée par l’étape. Ces artefacts sont ensuite téléchargés et conservés dans le magasin de données par défaut de l’utilisateur.
Pour plus d’informations, consultez la référence Experiment class (Classe Experiment).
Utiliser les paramètres de pipeline pour les arguments qui changent au temps de l’inférence
Parfois, les arguments des étapes individuelles au sein d’un pipeline se rapportent à la période de développement et d’apprentissage : par exemples les taux d’apprentissage et d’inertie ou les chemins d’accès aux fichiers de données ou de configuration. Toutefois, quand un modèle est déployé, vous souhaitez transmettre dynamiquement les arguments sur lesquels vous inférez (c’est-à-dire la requête que vous avez générée pour que le modèle réponde !). Vous devez définir ces types de paramètres de pipeline d’arguments. Pour effectuer cette opération dans Python, utilisez la classe azureml.pipeline.core.PipelineParameter, comme indiqué dans l’extrait de code suivant :
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Fonctionnement des environnements Python avec les paramètres de pipeline
Comme indiqué précédemment dans Configurer l’environnement d’exécution d’apprentissage, l’état de l’environnement et les dépendances de la bibliothèque Python sont spécifiés à l’aide d’un objet Environment. En règle générale, vous pouvez spécifier un(e) Environment existant(e) en faisant référence à son nom et, éventuellement, à une version :
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Toutefois, si vous choisissez d’utiliser des objets PipelineParameter pour définir dynamiquement des variables au moment de l’exécution pour vos étapes de pipeline, vous ne pouvez pas utiliser cette technique pour faire référence à un(e) Environment existant(e). Au lieu de cela, si vous souhaitez utiliser des objets PipelineParameter, vous devez définir le champ environment du/de la RunConfiguration sur un objet Environment. Il vous incombe de vous assurer que ce/cette Environment a ses dépendances sur les packages Python externes correctement définis.
Afficher les résultats d’un pipeline
Consultez la liste de tous vos pipelines et les détails relatifs à leur exécution dans le studio :
Connectez-vous à Azure Machine Learning Studio.
Sur la gauche, sélectionnez Pipelines pour voir toutes vos exécutions de pipeline.
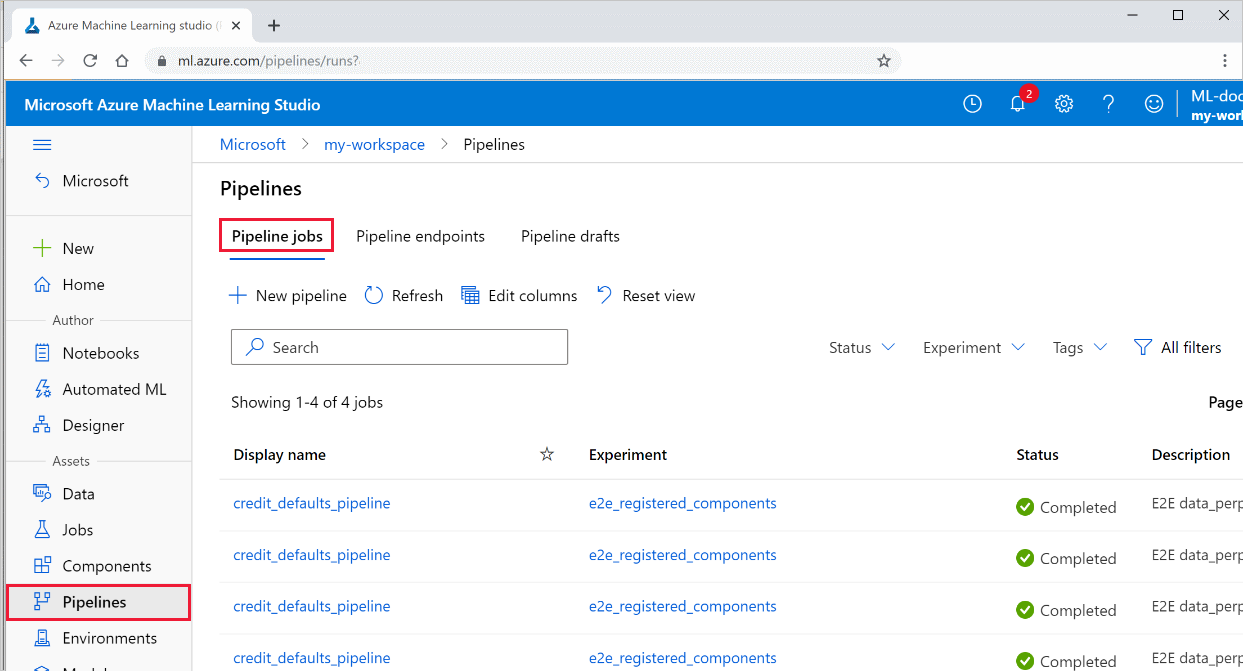
Sélectionnez un pipeline spécifique pour afficher les résultats de l’exécution.
Intégration et suivi Git
Lorsque vous lancez une exécution d’entraînement où le répertoire source est un répertoire Git local, les informations relatives au répertoire sont stockées dans l’historique des exécutions. Pour plus d’informations, consultez Obtenir une intégration pour Azure Machine Learning.
Étapes suivantes
- Pour partager votre pipeline avec des collègues ou des clients, consultez Publier des pipelines Machine Learning
- Utilisez ces notebooks Jupyter sur GitHub pour explorer plus en détail les pipelines Machine Learning
- Consultez l’aide de référence du SDK pour les packages azureml-pipelines-core et azureml-pipelines-steps
- Consultez le guide pratique pour obtenir des conseils sur le débogage et la résolution des problèmes de pipelines.
- Découvrez comment exécuter des notebooks dans l’article Utiliser des notebooks Jupyter pour explorer ce service.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour