Ingestion des données avec Azure Data Factory
Dans cet article, vous allez découvrir les options disponibles pour la création d’un pipeline d’ingestion de données avec Azure Data Factory. Ce pipeline Azure Data Factory est utilisé pour ingérer des données à utiliser avec Azure Machine Learning. Data Factory vous permet d’extraire, de transformer et de charger (ETL) facilement des données. Une fois les données transformées et chargées dans le stockage, elles peuvent être utilisées pour entraîner vos modèles Machine Learning dans Azure Machine Learning.
Une transformation simple des données peut être effectuée avec les activités et les instruments Data Factory natifs, tels que le flux de données. Lorsqu’il s’agit de scénarios plus compliqués, les données peuvent être traitées avec du code personnalisé. Par exemple, le code Python ou R.
Comparer les pipelines d’ingestion des données Azure Data Factory
Il existe plusieurs techniques courantes d’utilisation de Data Factory pour transformer des données lors de l’ingestion. Chaque technique présente des avantages et des inconvénients qui permettent de déterminer si elle est adaptée à un cas d’usage spécifique :
| Technique | Avantages | Inconvénients |
|---|---|---|
| Data Factory + Fonctions Azure | Convient uniquement au traitement de courte durée | |
| Data Factory + composant personnalisé | ||
| Data Factory + notebook Azure Databricks |
Azure Data Factory avec des fonctions Azure
Azure Functions vous permet d’exécuter de petits morceaux de code (« fonctions ») sans vous préoccuper de l’infrastructure de l’application. Dans cette option, les données sont traitées avec du code Python personnalisé enveloppé dans une fonction Azure.
La fonction est appelée à l’aide de l’activité Azure Data Factory Azure Functions. Cette approche est une bonne option pour les transformations légères de données.
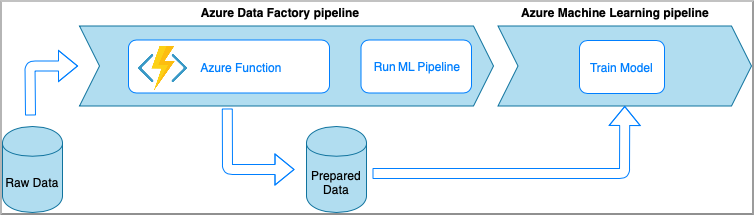
- Avantages :
- Les données sont traitées sur un calcul serverless avec une latence relativement faible
- Le pipeline Data Factory peut appeler une fonction Azure durable qui peut implémenter un workflow sophistiqué de transformation des données
- Les détails de la transformation de données sont extraits par la fonction Azure qui peut être réutilisée et appelée à partir d’autres emplacements
- Inconvénients :
- Les fonctions Azure Functions doivent être créées avant d’être utilisées avec ADF
- Azure Functions n’est utile que pour le traitement de données de courte durée
Azure Data Factory avec une activité Composant personnalisé
Dans cette option, les données sont traitées avec du code Python personnalisé enveloppé dans un fichier exécutable. Il est appelé à l’aide d’une activité Azure Data Factory Composant personnalisé. Cette approche est plus adaptée aux données volumineuses que la technique précédente.
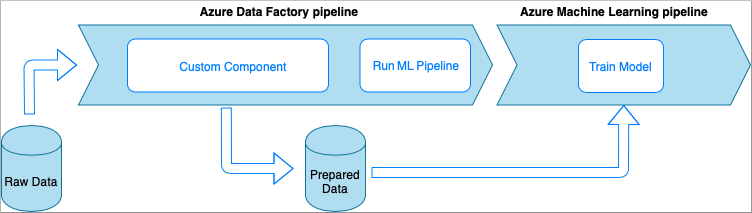
- Avantages :
- Les données sont traitées sur le pool Azure Batch, qui permet un calcul parallèle à grande échelle et à haute performance
- Peut être utilisée pour exécuter des algorithmes lourds et traiter de grandes quantités de données
- Inconvénients :
- Le pool Azure Batch doit être créé avant d’être utilisé avec Data Factory
- Repose sur l’ingénierie liée à l’enveloppement du code Python dans un fichier exécutable. Complexité de la gestion des dépendances et des paramètres entrée/sortie
Azure Data Factory avec un notebook Python Azure Databricks
Azure Databricks est une plateforme d’analytique basée sur Apache Spark dans le cloud Microsoft.
Dans cette technique, la transformation des données est effectuée par un notebook Python exécuté sur un cluster Azure Databricks. C’est probablement l’approche la plus courante qui tire parti de toute la puissance d’un service Azure Databricks. Elle est conçue pour le traitement des données distribuées à grande échelle.
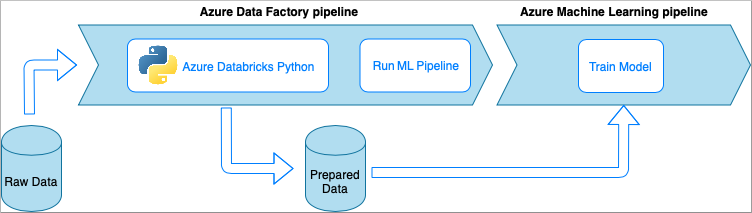
- Avantages :
- Les données sont transformées sur le service Azure de traitement des données le plus puissant, qui est assisté par l’environnement Apache Spark.
- Prise en charge native de Python avec les infrastructures et bibliothèques de science des données, notamment TensorFlow, PyTorch etscikit-learn.
- Il n’est pas nécessaire d’envelopper le code Python dans des fonctions ou des modules exécutables. Le code fonctionne comme tel quel.
- Inconvénients :
- L’infrastructure Azure Databricks doit être créée avant d’être utilisée avec Data Factory
- Peut coûter cher en fonction de la configuration Azure Databricks
- La rotation des clusters de calcul à partir du mode « froid » prend un certain temps, ce qui confère une latence élevée à la solution
Consommer des données dans Azure Machine Learning
Le pipeline Data Factory enregistre les données préparées dans votre stockage cloud (par exemple, un blob Azure ou un lac de données Azure).
Consommez vos données préparées dans Azure Machine Learning de la manière suivante :
- En appelant un pipeline Azure Machine Learning à partir de votre pipeline Data Factory.
OR - Création d’un magasin de données Azure Machine Learning.
Appeler un pipeline Azure Machine Learning à partir de Data Factory
Cette méthode est recommandée pour les workflows Machine Learning Operations (MLOps). Si vous ne voulez pas configurer un pipeline Azure Machine Learning, consultez Lire des données directement à partir du stockage.
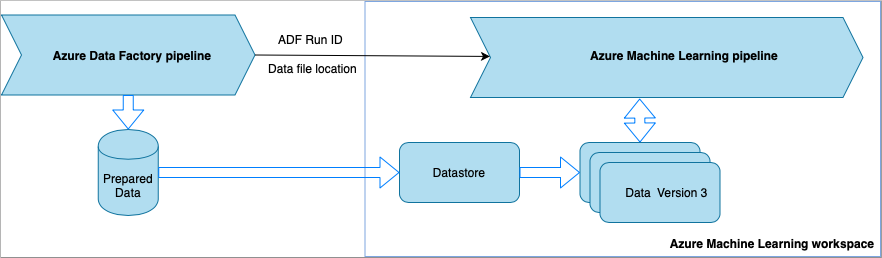
À chaque exécution du pipeline Data Factory :
- Les données sont enregistrées à un emplacement différent dans le stockage.
- Pour transmettre l’emplacement à Azure Machine Learning, le pipeline Data Factory appelle un pipeline Azure Machine Learning. Lors de l’appel du pipeline ML, l’emplacement des données et l’ID de tâche sont envoyés en tant que paramètres.
- Le pipeline ML peut ensuite créer un magasin de données et un jeu de données Azure Machine Learning avec l’emplacement des données. Pour plus d’informations, consultez Exécuter des pipelines Azure Machine Learning dans Data Factory.
Conseil
Les jeux de données prennent en charge le contrôle de version, de sorte que le pipeline ML peut inscrire une nouvelle version du jeu de données qui pointe vers les données les plus récentes à partir du pipeline ADF.
Une fois que les données sont accessibles par le biais d’un magasin de données ou d’un jeu de données, vous pouvez les utiliser pour effectuer l’apprentissage d’un modèle ML. Le processus d’apprentissage peut faire partie du même pipeline ML appelé à partir d’ADF. Il peut également s’agir d’un processus distinct, tel que l’expérimentation dans un notebook Jupyter.
Étant donné que les jeux de données prennent en charge le contrôle de version et que chaque tâche à partir du pipeline crée une nouvelle version, il est facile de comprendre quelle version des données a été utilisée pour effectuer l’apprentissage d’un modèle.
Lire des données directement à partir du stockage
Si vous ne voulez pas créer un pipeline ML, vous pouvez accéder aux données directement à partir du compte de stockage dans lequel vos données préparées sont enregistrées avec un magasin de données et un jeu de données Azure Machine Learning.
Le code Python suivant montre comment créer un magasin de données qui se connecte au stockage Azure DataLake Generation 2. Découvrez-en plus sur les magasins de données et l’emplacement des autorisations du principal de service.
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Ensuite, créez un jeu de données pour référencer les fichiers que vous voulez utiliser dans votre tâche de Machine Learning.
Le code suivant crée un TabularDataset à partir d’un fichier csv, prepared-data.csv. Découvrez-en plus sur les types de jeux de données et les formats de fichiers acceptés.
S’APPLIQUE À : SDK Python azureml v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
À partir de là, utilisez prepared_dataset pour référencer vos données préparées, comme dans vos scripts d’entraînement. Découvrez comment entraîner des modèles avec des jeux de données dans Azure Machine Learning.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour