Utiliser Azure Machine Learning avec le package open source Fairlearn pour évaluer l’impartialité des modèles Machine Learning (version préliminaire)
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Ce guide pratique explique comment utiliser le package Python open source Fairlearn avec Azure Machine Learning pour accomplir les tâches suivantes :
- Évaluer l’impartialité des prédictions de votre modèle. Pour en savoir plus sur l’impartialité de l’apprentissage automatique, consultez l’article Impartialité dans les modèles d’apprentissage automatique.
- Charger, répertorier et télécharger des informations d’évaluation de l’impartialité vers/à partir de Azure Machine Learning Studio.
- Afficher un tableau de bord d’évaluation de l’impartialité dans Azure Machine Learning Studio pour interagir avec les informations d’impartialité de votre modèle.
Notes
L’évaluation de l’impartialité n’est pas un exercice purement technique. Ce package peut vous aider à évaluer l’impartialité d’un modèle Machine Learning, mais vous seul pouvez le configurer et prendre des décisions quant à la façon dont il fonctionne. Bien que ce package aide à identifier des métriques quantitatives pour évaluer l’impartialité, les développeurs de modèles d’apprentissage automatique doivent également effectuer une analyse qualitative pour évaluer l’impartialité de leurs propres modèles.
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Kit de développement logiciel (SDK) pour l’impartialité d’Azure Machine Learning
Le Kit de développement logiciel (SDK) pour l’impartialité d’Azure Machine Learning, azureml-contrib-fairness, intègre le package Python open source, Fairlearn, dans Azure Machine Learning. Pour en savoir plus sur l’intégration de Fairlearn dans Azure Machine Learning, consultez ces exemples de bloc-notes. Pour plus d’informations sur Fairlearn, consultez l’exemple de guide et des exemples de bloc-notes.
Utilisez les commandes suivantes pour installer les packages azureml-contrib-fairness et fairlearn :
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Les versions ultérieures de Fairlearn devraient également fonctionner dans l’exemple de code suivant.
Charger les informations d’impartialité pour un modèle unique
L’exemple suivant explique comment utiliser le package d’impartialité. Nous allons charger des informations sur l’impartialité du modèle dans Azure Machine Learning et afficher le tableau de bord d’évaluation de l’impartialité dans Azure Machine Learning Studio.
Effectuez l’apprentissage d’un exemple de modèle dans un bloc-notes Jupyter.
Pour le jeu de données, nous utilisons le jeu de données bien connu Adult Census, que nous récupérons sur OpenML. Nous prétendons avoir un problème de décision concernant un prêt avec l’étiquette indiquant si une personne a remboursé un prêt précédent. Nous allons effectuer l’apprentissage d’un modèle permettant de prédire si des personnes jusque-là inconnues rembourseront un prêt. Un tel modèle pourrait être utilisé pour prendre des décisions en matière de prêt.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Connectez-vous à Azure Machine Learning et inscrivez votre modèle.
Le tableau de bord d’impartialité peut s’intégrer avec des modèles inscrits ou non inscrits. Inscrivez votre modèle dans Azure Machine Learning en procédant comme suit :
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Précalculez les métriques d’impartialité.
Créez un dictionnaire de tableau de bord à l’aide du package
metricsde Fairlearn. La méthode_create_group_metric_setutilise des arguments similaires à ceux du constructeur de tableau de bord, à ceci près que les caractéristiques sensibles sont passées en tant que dictionnaire (pour s’assurer que les noms sont disponibles). Nous devons également spécifier le type de prédiction (en l’occurrence, classification binaire) lors de l’appel de cette méthode.# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Chargez les métriques d’impartialité précalculées.
À présent, importez le package
azureml.contrib.fairnesspour effectuer le chargement :from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idCréez une expérience, une exécution, puis chargez le tableau de bord :
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Vérifiez le tableau de bord d’impartialité d’Azure Machine Learning Studio.
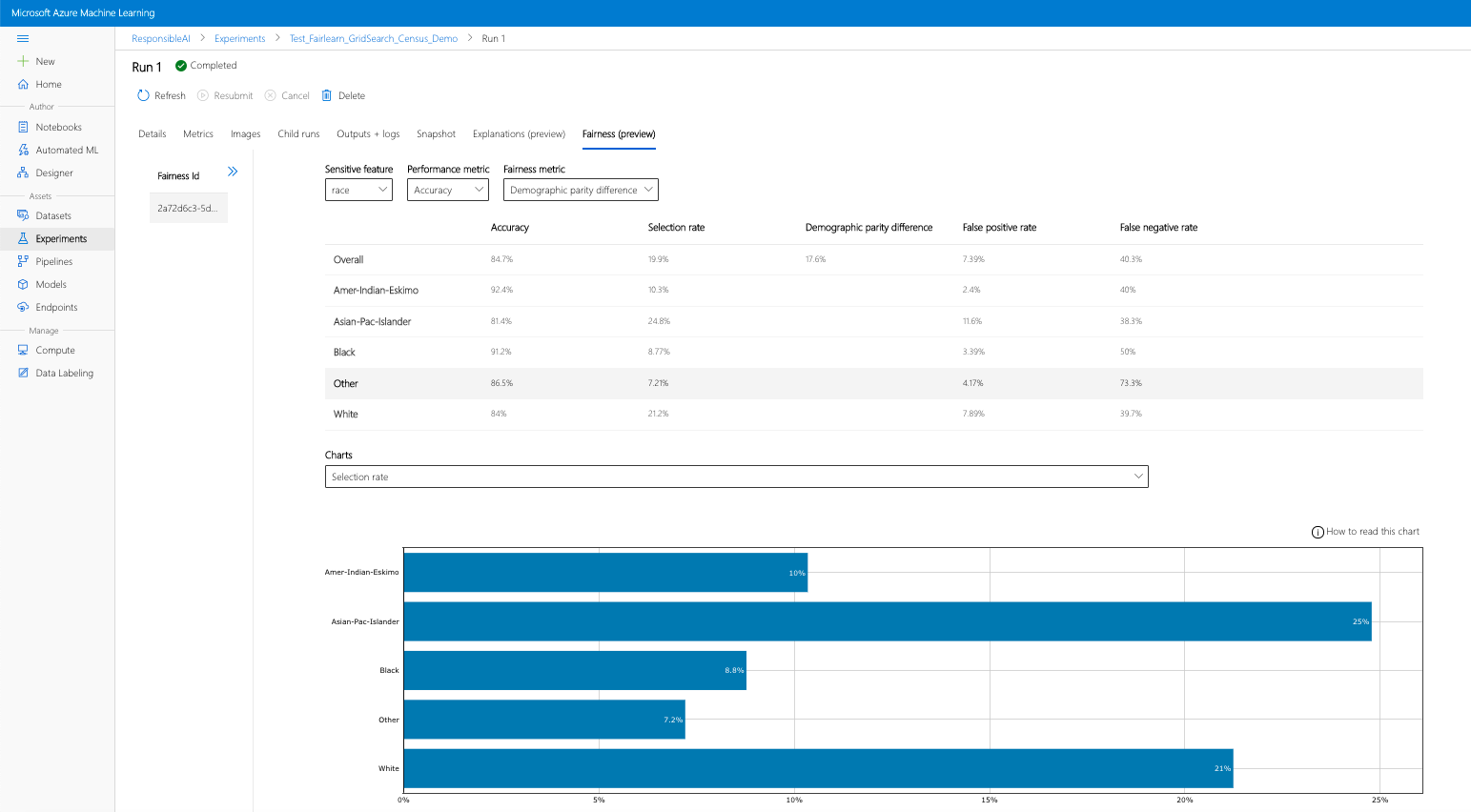
Si vous suivez les étapes précédentes (chargement des informations d’impartialité générées dans Azure Machine Learning), vous pouvez afficher le tableau de bord d’impartialité dans Azure Machine Learning Studio. Ce tableau de bord est le même que le tableau de bord de visualisation fourni dans Fairlearn, ce qui vous permet d’analyser les disparités entre les sous-groupes sensibles de votre fonctionnalité (par exemple, mâle ou femelle). Suivez un de ces parcours pour accéder au tableau de bord de visualisation dans Azure Machine Learning Studio :
- Volet Tâches (préversion)
- Sélectionnez Tâches dans le volet gauche pour afficher la liste des expériences que vous avez exécutées sur Azure Machine Learning.
- Sélectionnez une expérience particulière pour afficher toutes les exécutions de cette expérience.
- Sélectionnez une exécution, puis l’onglet Impartialité pour afficher le tableau de bord de visualisation des explications.
- Une fois arrivé dans l’onglet Impartialité, cliquez sur un ID d’impartialité dans le menu de droite.
- Configurez votre tableau de bord en sélectionnant l’attribut sensible, la mesure des performances et la métrique d’impartialité qui vous intéressent pour atterrir sur la page d’évaluation de l’impartialité.
- Passez d’un type de tableau à l’autre pour observer à la fois les préjudices liés à l’allocation et ceux liés à la qualité du service.

- Volet Modèles
- Si vous avez inscrit votre modèle d’origine en suivant les étapes précédentes, vous pouvez sélectionner Modèles dans le volet gauche pour l’afficher.
- Sélectionnez un modèle, puis l’onglet Impartialité pour afficher le tableau de bord de visualisation des explications.
Pour en savoir plus sur le tableau de bord de visualisation et son contenu, consultez le guide de l’utilisateur de Fairlearn.


Charger des informations d’impartialité pour plusieurs modèles
Pour comparer plusieurs modèles et voir en quoi l’évaluation de leur impartialité diffère, vous pouvez passer plusieurs modèles au tableau de bord de visualisation et comparer leurs compromis entre performances et impartialité.
Effectuez l’apprentissage de votre modèles.
Nous créons maintenant un deuxième classifieur, basé sur un estimateur de machine à vecteurs de support, puis chargeons un dictionnaire de tableau de bord d’impartialité à l’aide du package
metricsde Fairlearn. Nous partons du principe que le modèle précédemment formé est toujours disponible.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Inscrivez vos modèles.
Ensuite, inscrivez les deux modèles auprès d’Azure Machine Learning. Pour plus de commodité, stockez les résultats dans un dictionnaire qui mappe l’
iddu modèle inscrit (une chaîne au formatname:version) au modèle de prédiction :model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorChargez le tableau de bord Fairlearn localement
Avant de charger les informations d’impartialité dans Azure Machine Learning, vous pouvez examiner ces prédictions dans un tableau de bord d’impartialité appelé localement.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Précalculez les métriques d’impartialité.
Créez un dictionnaire de tableau de bord à l’aide du package
metricsde Fairlearn.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Chargez les métriques d’impartialité précalculées.
À présent, importez le package
azureml.contrib.fairnesspour effectuer le chargement :from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idCréez une expérience, une exécution, puis chargez le tableau de bord :
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Comme dans la section précédente, vous pouvez suivre l’un des chemins décrits ci-dessus (via Expériences ou Modèles) dans Azure Machine Learning Studio pour accéder au tableau de bord de visualisation et comparer les deux modèles en termes d’impartialité et de performances.
Charger des informations d’impartialité non atténuées et atténuées
Vous pouvez utiliser les algorithmes d’atténuation de Fairlearn, comparer leurs modèles atténués générés au modèle non atténué d’origine, et parcourir les compromis entre performances et impartialité parmi les modèles comparés.
Pour voir un exemple illustrant l’utilisation de l’algorithme d’atténuation Grid Search (qui crée une collection de modèles atténués avec différents compromis d’impartialité et de performances), consultez cet exemple de notebook.
Le chargement des informations sur l’impartialité de plusieurs modèles dans une seule exécution permet de comparer les modèles sur le plan de l’impartialité et des performances. Vous pouvez cliquer sur l’un des modèles affichés dans le tableau de comparaison des modèles pour voir les informations détaillées sur l’impartialité du modèle en question.

Étapes suivantes
En savoir plus sur l’impartialité des modèles
Consultez les exemples de blocs-notes d’impartialité d’Azure Machine Learning