Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
APPLIES TO : Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Dans cet article, vous apprenez :
- Comment lire des données à partir du stockage Azure dans un travail Azure Machine Learning.
- Comment écrire des données à partir de votre travail Azure Machine Learning dans un stockage Azure.
- Différence entre les modes montage et téléchargement.
- Comment utiliser l’identité de l’utilisateur et l’identité managée pour accéder aux données.
- Paramètres de montage disponibles dans un travail.
- Paramètres de montage optimaux pour des scénarios courants.
- Comment accéder aux ressources de données V1.
Prérequis
Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Le kit de développement logiciel (SDK) Azure Machine Learning pour Python v2.
Le package Python azure-identity (
pip install azure-identity).Azure CLI avec l’extension ml v2 (
az extension add -n ml).Un espace de travail Azure Machine Learning.
Cible de calcul Azure Machine Learning (par exemple, un cluster de calcul nommé
cpu-cluster).
Démarrage rapide
Avant d’explorer les options détaillées disponibles lorsque vous accédez aux données, nous décrivons d’abord les extraits de code pertinents pour l’accès aux données.
Lire des données à partir du stockage Azure dans un travail Azure Machine Learning
Dans cet exemple, vous envoyez un travail Azure Machine Learning qui accède aux données à partir d’un compte de stockage blob public . Toutefois, vous pouvez adapter l’extrait de code pour accéder à vos propres données dans un compte de stockage Azure privé. Mettez à jour le chemin d’accès comme décrit ici. Azure Machine Learning gère en toute transparence l’authentification auprès du stockage cloud, avec le passthrough Microsoft Entra. Lorsque vous envoyez un travail, vous pouvez choisir :
- Identité de l’utilisateur : passez votre identité Microsoft Entra pour accéder aux données
- Identité managée : Utilisez l’identité managée de la cible de calcul pour accéder aux données
- Aucune : Ne spécifiez pas d’identité pour accéder aux données. Utilisez Aucune lors de l’utilisation de magasins de données basés sur des informations d’identification (clé/jeton SAS) ou lors de l’accès à des données publiques
Conseil
Si vous utilisez des clés ou des jetons SAP pour vous authentifier, nous vous recommandons de créer un magasin de données Azure Machine Learning. Le runtime se connecte automatiquement au stockage sans exposer vos informations d’identification.
from azure.ai.ml import command, Input, MLClient
from azure.ai.ml.entities import Data, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Écrire des données à partir de votre travail Azure Machine Learning dans un stockage Azure
Dans cet exemple, vous envoyez un travail Azure Machine Learning qui écrit des données dans votre magasin de données Azure Machine Learning par défaut. Vous pouvez éventuellement définir la valeur name de votre ressource de données pour créer une ressource de données dans la sortie.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Runtime de données Azure Machine Learning
Lorsque vous envoyez un travail, le runtime de données Azure Machine Learning contrôle le chargement des données depuis l’emplacement de stockage vers la cible de calcul. Le runtime de données Azure Machine Learning est optimisé pour que les tâches d’apprentissage automatique soient rapides et efficaces. Voici les principaux avantages :
- Les chargements de données sont écrits en langage Rust, connu pour sa vitesse élevée et son importante efficacité de mémoire. Pour les téléchargements de données simultanés, Rust évite les problèmes de GIL (Global Interpreter Lock) Python
- Poids léger ; Rust n’a aucune dépendance vis-à-vis d’autres technologies, par exemple JVM. Par conséquent, le runtime s’installe rapidement et ne draine pas les ressources supplémentaires (processeur, mémoire) sur la cible de calcul
- Chargement de données multiprocessus (parallèle)
- Prérécupération des données en tant que tâche en arrière-plan sur un ou plusieurs processeurs, pour permettre une meilleure utilisation des GPU lors de l’apprentissage profond
- Gestion de l’authentification fluide au stockage cloud
- Fournit des options pour monter des données (transmission en continu) ou télécharger toutes les données. Pour plus d’informations, consultez les sections Montage (transmission en continu) et Téléchargement.
- Intégration transparente avec fsspec : interface pythonique unifiée pour les systèmes de fichiers locaux, distants et incorporés et le stockage d’octets.
Conseil
Nous vous suggérons d’appliquer le runtime de données Azure Machine Learning au lieu de créer votre propre fonctionnalité de montage/téléchargement dans votre code d’entraînement (client). Nous avons observé des contraintes de débit de stockage lorsque le code client utilise Python pour télécharger des données à partir du stockage, en raison des problèmes liés au verrou d’interpréteur global (GIL).
Chemins
Lorsque vous fournissez une entrée ou une sortie de données à un travail, vous devez spécifier un path paramètre qui pointe vers l’emplacement des données. Ce tableau présente les différents emplacements de données pris en charge par Azure Machine Learning et fournit des path exemples de paramètres :
| Emplacement | Exemples | Entrée | Output |
|---|---|---|---|
| Chemin sur votre ordinateur local | ./home/username/data/my_data |
O | N |
| Chemin d’accès sur un serveur HTTP(S) public | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
O | N |
| Chemin dans Stockage Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, uniquement pour l’authentification basée sur l’identité | N |
| Un chemin sur un magasin de données Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
O | O |
| Un chemin vers une ressource de données | azureml:<my_data>:<version> |
O | N, mais vous pouvez utiliser name et version créer une ressource de données à partir de la sortie |
Modes
Lorsque vous exécutez un travail avec des entrées/sorties de données, vous pouvez choisir parmi ces options de mode :
ro_mount: montez l’emplacement de stockage en lecture seule sur la cible de calcul de disque local (SSD).rw_mount: montez l’emplacement de stockage en lecture-écriture sur la cible de calcul de disque local (SSD).download: téléchargez les données à partir de l’emplacement de stockage sur la cible de calcul de disque local (SSD).upload: chargez des données à partir de la cible de calcul vers l’emplacement de stockage.eval_mount/eval_download: ces modes sont propres à MLTable. Dans certains scénarios, un fichier MLTable peut générer des fichiers qui peuvent se trouver dans un compte de stockage différent de celui qui héberge le fichier MLTable. Ou un MLTable peut créer un sous-ensemble des données qui se trouvent dans la ressource de stockage ou les lire de manière aléatoire. Cette vue du sous-ensemble/shuffle devient visible uniquement lorsque le runtime de données Azure Machine Learning évalue le fichier MLTable. Par exemple, ce diagramme montre comment un MLTable utilisé aveceval_mountoueval_downloadpeut prendre des images à partir de deux conteneurs de stockage différents et d’un fichier d’annotations situé dans un autre compte de stockage, puis monter/télécharger sur le système de fichiers de la cible de calcul distante.
Le dossier
camera1, le dossiercamera2et le fichierannotations.csvsont ensuite accessibles sur le filesystem de la cible de calcul dans la structure du dossier :/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: vous souhaitez peut-être lire des données directement à partir d’un URI via d’autres API plutôt que de passer par le runtime de données Azure Machine Learning. Par exemple, vous pourriez vouloir accéder aux données d’un compartiment s3 (avec une URL de style hébergement virtuel ou chemin d’accèshttps) à l’aide du client boto s3. Vous pouvez obtenir l’URI de l’entrée sous forme de chaîne avec le modedirect. Vous voyez le mode direct utilisé dans les travaux Spark, car les méthodesspark.read_*()savent comment traiter les URI. Pour les travaux autres que Spark, il vous incombe de gérer les informations d’identification d’accès. Par exemple, vous devez utiliser explicitement le MSI de calcul ou l’accès broker.

Ce tableau présente les modes possibles pour différentes combinaisons de type/mode/entrée/sortie :
| Type | Entrée/sortie | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Entrée | ✓ | ✓ | ✓ | ||||
uri_file |
Entrée | ✓ | ✓ | ✓ | ||||
mltable |
Entrée | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Output | ✓ | ✓ | |||||
uri_file |
Output | ✓ | ✓ | |||||
mltable |
Output | ✓ | ✓ | ✓ |
Téléchargement
En mode téléchargement, toutes les données d’entrée sont copiées sur le disque local (SSD) de la cible de calcul. Le runtime de données Azure Machine Learning démarre le script d’apprentissage utilisateur une fois toutes les données copiées. Lorsque le script utilisateur démarre, il lit les données du disque local comme n’importe quel autre fichier. Une fois le travail terminé, les données sont supprimées du disque de la cible de calcul.
| Avantages | Inconvénients |
|---|---|
| Lorsque la formation commence, toutes les données sont disponibles sur le disque local (SSD) de la cible de calcul pour le script d’apprentissage. Aucune interaction stockage/réseau Azure n’est requise. | Le jeu de données doit être entièrement adapté à un disque de la cible de calcul. |
| Une fois le script utilisateur démarré, il n’existe aucune dépendance quant à la fiabilité du stockage/réseau. | L’intégralité du jeu de données est téléchargée (si l’apprentissage doit sélectionner de façon aléatoire uniquement une petite partie des données, une grande partie du téléchargement est alors gaspillée). |
| Le runtime de données Azure Machine Learning peut mettre en parallèle le téléchargement (différence significative sur de nombreux petits fichiers) et le débit réseau/stockage maximal. | Le travail attend que toutes les données soient téléchargées sur le disque local de la cible de calcul. Pour un travail d’apprentissage profond soumis, les GPU sont inactifs jusqu’à ce que les données soient prêtes. |
| Aucune surcharge inévitable ajoutée par la couche FUSE (aller-retour : appel de l’espace de l’utilisateur dans le script de l’utilisateur → noyau → démon fusible de l’espace de l’utilisateur → noyau → réponse au script de l’utilisateur dans l’espace de l’utilisateur) | Les modifications de stockage ne sont pas répercutées sur les données une fois le téléchargement terminé. |
Quand utiliser le téléchargement
- Les données sont suffisamment petites pour tenir sur le disque de la cible de calcul sans interférer avec d’autres apprentissages
- L’apprentissage utilise une grande partie ou la totalité du jeu de données
- L’apprentissage lit plusieurs fois les fichiers d’un jeu de données
- L’apprentissage doit passer à des positions aléatoires d’un fichier volumineux
- Vous pouvez attendre que toutes les données soient téléchargées avant de commencer l’apprentissage
Paramètres de téléchargement disponibles
Vous pouvez régler les paramètres de téléchargement avec ces variables d’environnement dans votre travail :
| Nom de variable d'environnement | Type | Valeur par défaut | Descriptif |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Nombre de threads simultanés que le téléchargement peut utiliser |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Nombre de nouvelles tentatives de stockage/requête http individuelles après des erreurs temporaires. |
Dans votre travail, vous pouvez modifier les valeurs par défaut ci-dessus en définissant les variables d’environnement, par exemple :
Par souci de concision, nous montrons uniquement comment définir les variables d’environnement dans le travail.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Télécharger les métriques de performances
La taille de la machine virtuelle de votre cible de calcul a un effet sur le temps de téléchargement de vos données. Plus précisément :
- Nombre de cœurs. Plus il y a de cœurs disponibles, plus l’accès est simultané et donc plus le téléchargement est rapide.
- Bande passante réseau attendue. Chaque machine virtuelle dans Azure a un débit maximal à partir de la carte d’interface réseau (NIC).
Remarque
Pour les machines virtuelles GPU A100, le runtime de données Azure Machine Learning peut saturer la carte d’interface réseau lors du téléchargement des données vers la cible de calcul (environ 24 Gbits/s) : Débit théorique maximal possible.
Ce tableau présente les performances de téléchargement que le runtime de données Azure Machine Learning peut gérer pour un fichier de 100 Go sur une machine virtuelle Standard_D15_v2 (20 cœurs, débit réseau de 25 Gbits/s) :
| Structure des données | Télécharger uniquement (secondes) | Télécharger et calculer MD5 (secondes) | Débit atteint (Gbit/s) |
|---|---|---|---|
| Fichiers de 10 x 10 Go | 55,74 | 260,97 | 14,35 Gbits/s |
| Fichiers de 100 x 1 Go | 58,09 | 259,47 | 13,77 Gbit/s |
| Fichiers de 1 x 100 Go | 96,13 | 300,61 | 8,32 Gbit/s |
Nous pouvons voir qu’un fichier plus volumineux, divisé en fichiers plus petits, peut améliorer les performances de téléchargement en raison du parallélisme. Nous recommandons d’éviter que les fichiers soient trop petits (inférieurs à 4 Mo), car le temps consacré aux soumissions de requêtes de stockage augmente, par rapport au temps consacré au téléchargement de la charge utile. Pour plus d’informations, consultez Problème liés à de nombreux petits fichiers.
Montage (transmission en continu)
En mode montage, la capacité de données Azure Machine Learning utilise la fonctionnalité Linux FUSE (filesystem dans l’espace de l’utilisateur) pour créer un filesystem émulé. Plutôt que de télécharger toutes les données sur le disque local (SSD) de la cible de calcul, le runtime peut réagir aux actions de script de l’utilisateur en temps réel. Par exemple, « open file », « read 2-Ko chunk from position X », « list directory content ».
| Avantages | Inconvénients |
|---|---|
| Les données qui dépassent la capacité du disque local de la cible de calcul peuvent être utilisées (non limitées par le matériel de calcul) | Surcharge ajoutée du module FUSE Linux. |
| Aucun délai au début de l’apprentissage (contrairement au mode téléchargement). | La dépendance au comportement du code de l’utilisateur (si le code d’entraînement qui lit de façon séquentielle de petits fichiers dans un montage à thread unique demande également des données à partir du stockage, il peut ne pas maximiser le débit de réseau ou de stockage). |
| Paramètres supplémentaires disponibles à régler pour un scénario d’utilisation. | Aucune prise en charge de Windows. |
| Seules les données nécessaires à l’apprentissage sont lues à partir du stockage. |
Quand utiliser le montage
- Les données sont volumineuses et ne tiennent pas sur le disque local cible de calcul.
- Chaque nœud de calcul d’un cluster n’a pas besoin de lire l’intégralité du jeu de données (fichier aléatoire ou lignes dans la sélection de fichiers csv, etc.).
- Les retards dans l’attente du téléchargement de toutes les données avant le démarrage de l’apprentissage peuvent constituer un problème (temps d’inactivité du GPU).
Paramètres de montage disponibles
Vous pouvez régler les paramètres de montage avec ces variables d’environnement dans votre travail :
| Nom de la variable d’environnement | Type | Valeur par défaut | Descriptif |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Non défini (le cache n’expire jamais) | Délai nécessaire en millisecondes pour conserver les résultats de l’appel getattrdans le cache et éviter à nouveau les requêtes ultérieures de ces informations à partir du stockage. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 Mo | Conçu pour une configuration système, afin de maintenir un calcul sain. Quelles que soient les valeurs des autres paramètres, le runtime de données Azure Machine Learning n’utilise pas les derniersRESERVED_FREE_DISK_SPACE octets d’espace disque. |
DATASET_MOUNT_CACHE_SIZE |
usize | Illimité | Contrôle la quantité d’espace disque que le montage peut utiliser. Une valeur positive définit la valeur absolue en octets. Une valeur négative définit la quantité d’espace disque à laisser libre. Ce tableau fournit davantage d’options de cache de disque. Prend en charge les modificateurs KB, MB et GB pour des raisons pratiques. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1,0 | Le montage du volume lance le nettoyage du cache lorsque le cache est rempli par AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Doit être comprise entre 0 et 1. Définir cette valeur comme < 1 déclenche le nettoyage du cache en arrière-plan plus tôt.
AVAILABLE_CACHE_SIZE n’est pas une variable d’environnement que vous pouvez modifier ou afficher directement. Dans ce contexte, elle fait référence au « nombre d’octets que le système calcule comme étant disponible pour la mise en cache ». Cette valeur dépend de facteurs tels que la taille du disque, la quantité d’espace disque nécessaire pour l’intégrité du système et les configurations définies dans les variables d’environnement (comme DATASET_RESERVED_FREE_DISK_SPACE et DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Le nettoyage du cache tente de libérer au moins (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) d’un espace de cache. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 Mo | Taille du bloc de lecture en transmission en continu. Lorsque le fichier est suffisamment volumineux, demandez au moins DATASET_MOUNT_READ_BLOCK_SIZE de données à partir du stockage et du cache, même lorsque l’opération de lecture demandée par fuse en concerne moins. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Nombre de blocs à prérécupérer (bloc de lecture k déclenche la prérécupération en arrière-plan des blocs k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Nombre de threads de prérécupération en arrière-plan. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | faux | Activer la mise en cache basée sur les blocs. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 Mo | S’applique uniquement à la mise en cache basée sur les blocs. La taille de la mise en cache basée sur les blocs de RAM peut être utilisée. La valeur 0 désactive complètement la mise en cache de la mémoire. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | vrai | S’applique uniquement à la mise en cache basée sur les blocs. Lorsqu’elle est définie sur true, la mise en cache basée sur les blocs utilise le disque dur local pour mettre en cache les blocs. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MO | S’applique uniquement à la mise en cache basée sur les blocs. La mise en cache basée sur les blocs écrit le bloc mis en cache sur un disque local en arrière-plan. Ce paramètre contrôle la quantité de mémoire que le montage peut utiliser pour stocker les blocs qui attendent d’être vidés dans le cache du disque local. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
S’applique uniquement à la mise en cache basée sur les blocs. Nombre de threads en arrière-plan que la mise en cache basée sur les blocs utilise pour écrire des blocs téléchargés sur le disque local de la cible de calcul. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Délai en secondes pour que unmount termine (normalement) toutes les opérations en attente (par exemple, les appels de vidage) avant de mettre fin de force à la boucle de message de montage. |
Dans votre travail, vous pouvez modifier les valeurs par défaut ci-dessus en définissant les variables d’environnement, par exemple :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Mode ouverture basé sur les blocs
Le mode ouverture basé sur les blocs divise chaque fichier en blocs d’une taille prédéfinie (à l’exception du dernier bloc). Une requête de lecture à partir d’une position spécifiée demande un bloc correspondant à partir du stockage et retourne immédiatement les données demandées. Une lecture déclenche également la prérécupération en arrière-plan de N blocs suivants, à l’aide de plusieurs threads (optimisés pour la lecture séquentielle). Les blocs téléchargés sont mis en cache dans un cache à deux couches (RAM et disque local).
| Avantages | Inconvénients |
|---|---|
| Livraison rapide des données vers le script d’apprentissage (moins de blocage des blocs qui n’ont pas encore été demandés). | Les lectures aléatoires peuvent gaspiller des blocs prérécupérés. |
| Plus de travail est déchargé sur les threads d’arrière-plan (prérécupération/mise en cache). L’apprentissage peut ensuite continuer. | Surcharge supplémentaire pour naviguer entre les caches, par rapport aux lectures directes à partir d’un fichier sur le cache d’un disque local (par exemple, en mode cache de l’intégralité du fichier). |
| Seules les données demandées (plus la prérécupération) sont lues à partir du stockage. | |
| Pour les données suffisamment petites, un cache rapide basé sur la RAM est utilisé. |
Quand utiliser le mode d’ouverture basé sur les blocs
Recommandé pour la plupart des scénarios sauf lorsque vous avez besoin de lectures rapides à partir d’emplacements de fichiers aléatoires. Dans ce cas, utilisez le Mode d’ouverture du cache de l’intégralité du fichier.
Mode d’ouverture du cache de l’intégralité du fichier
Lorsqu’un fichier se trouvant sous un dossier de montage est ouvert (par exemple, f = open(path, args)) en mode intégralité du fichier, l’appel est bloqué jusqu’à ce que l’intégralité du fichier soit téléchargée dans le dossier du cache de la cible de calcul sur le disque. Tous les appels de lecture suivants redirigent vers le fichier mis en cache, de sorte qu’aucune interaction de stockage n’est nécessaire. Si le cache ne dispose pas de suffisamment d’espace disponible pour contenir le fichier actif, le montage tente de nettoyer en supprimant du cache le fichier le moins récemment utilisé. Dans les cas où le fichier ne peut pas tenir sur le disque (par rapport aux paramètres de cache), le runtime de données revient en mode transmission en continu.
| Avantages | Inconvénients |
|---|---|
| Aucune dépendance de fiabilité/débit de stockage après l’ouverture du fichier. | L’appel ouvert est bloqué jusqu’à ce que l’intégralité du fichier soit téléchargée. |
| Lectures aléatoires rapides (lecture de blocs à partir d’emplacements aléatoires du fichier). | L’intégralité du fichier est lue à partir du stockage, même si certaines parties du fichier peuvent ne pas être nécessaires. |
Quand utiliser cette fonctionnalité ?
Lorsque des lectures aléatoires de fichiers relativement volumineux dépassant 128 Mo sont nécessaires.
Usage
Définissez la variable d’environnement DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED sur false dans votre travail :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montage : Liste des fichiers
Lorsque vous travaillez avec des millions de fichiers, évitez une liste récursive, par exemple ls -R /mnt/dataset/folder/. Une liste récursive déclenche de nombreux appels à répertorier le contenu du répertoire parent. Elle nécessite ensuite un appel récursif distinct au contenu de chaque répertoire, à tous les niveaux enfants. En règle générale, Le Stockage Azure autorise uniquement 5 000 éléments à retourner par demande de liste unique. Il en résulte qu’une liste récursive d’un million de dossiers contenant chacun 10 fichiers nécessite 1,000,000 / 5000 + 1,000,000 = 1,000,200 requêtes de stockage. En comparaison, 1 000 dossiers avec 10 000 fichiers n’auraient besoin que de 1 001 requêtes à stocker pour une liste récursive.
Le montage Azure Machine Learning gère la liste de manière paresseuse. Par conséquent, pour répertorier de nombreux petits fichiers, il est préférable d’utiliser un appel itératif à la bibliothèque de client (par exemple, os.scandir() dans Python) plutôt qu’un appel à la bibliothèque de client qui retourne la liste complète (par exemple, os.listdir() dans Python). Un appel itératif à la bibliothèque de client retourne un générateur, ce qui signifie qu’il n’a pas besoin d’attendre que l’intégralité de la liste entière se charge. Il peut alors se poursuivre plus rapidement.
Ce tableau compare le délai nécessaire aux fonctions os.scandir() et os.listdir() de Python pour répertorier un dossier contenant environ 4 millions de fichiers dans une structure plate :
| Métrique | os.scandir() |
os.listdir() |
|---|---|---|
| Délai d’obtention de la première entrée (secondes) | 0.67 | 553,79 |
| Délai d’obtention des 50 000 premières entrées (s) | 9,56 | 562,73 |
| Délai d’obtention de toutes les entrées (secondes) | 558,35 | 582,14 |
Paramètres de montage optimaux des scénarios courants
Dans certains scénarios courants, nous présentons les paramètres de montage optimaux que vous devez définir dans votre travail Azure Machine Learning.
Lecture séquentielle en une seule fois d’un fichier volumineux (lignes de traitement dans un fichier csv)
Incluez ces paramètres de montage dans la section environment_variables de votre travail Azure Machine Learning :
Remarque
Pour utiliser le calcul serverless, supprimez compute="cpu-cluster", dans ce code.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Lecture en une seule fois d’un fichier volumineux à partir de plusieurs threads (traitement d’un fichier csv partitionné en plusieurs threads)
Incluez ces paramètres de montage dans la section environment_variables de votre travail Azure Machine Learning :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lecture de millions de petits fichiers (images) à partir de plusieurs threads en une seule fois (apprentissage en une seule époque des images)
Incluez ces paramètres de montage dans la section environment_variables de votre travail Azure Machine Learning :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lecture de millions de petits fichiers (images) à partir de plusieurs threads en plusieurs fois (apprentissage en plusieurs époques des images)
Incluez ces paramètres de montage dans la section environment_variables de votre travail Azure Machine Learning :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Lecture d’un fichier volumineux avec des recherches aléatoires (comme le traitement de la base de données de fichiers à partir d’un dossier monté)
Incluez ces paramètres de montage dans la section environment_variables de votre travail Azure Machine Learning :
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnostic et résolution des goulots d’étranglement liés au chargement des données
Lorsqu’un travail Azure Machine Learning s’exécute avec des données, le mode d’une entrée détermine comment les octets sont lus à partir du stockage et mis en cache sur le disque SSD local de la cible de calcul. Pour le mode de téléchargement, tous les caches de données sont enregistrés sur le disque avant que l'exécution du code utilisateur ne commence. Plusieurs facteurs affectent les vitesses de téléchargement maximales :
- Nombre de threads parallèles
- Nombre de fichiers
- Taille du fichier
Pour le mode de montage, le code utilisateur doit commencer à ouvrir des fichiers avant que les données ne commencent à être mises en cache. Différents paramètres de montage entraînent un comportement de lecture et de mise en cache différent. Différents facteurs affectent la vitesse de chargement des données à partir du stockage :
- Localisation des données à calculer : Vos emplacements cibles de stockage et de calcul doivent être identiques. Si vos cibles de stockage et de calcul se trouvent dans des régions différentes, les performances se dégradent, car les données doivent être transférées entre les régions. Pour plus d’informations sur la manière de garantir la colocalisation de vos données avec le calcul, consultez Colocaliser des données avec le calcul.
-
Taille de la cible de calcul : Les petits calculs ont un nombre de cœurs inférieur (moins de parallélisme) et une bande passante réseau attendue inférieure par rapport à des tailles de calcul plus grandes. Les deux facteurs affectent les performances de chargement des données.
- Par exemple, si vous utilisez une petite taille de machine virtuelle, par
Standard_D2_v2exemple (2 cœurs, 1 500 Mbits/s de carte réseau), et que vous essayez de charger 50 000 Mo (50 Go) de données, le meilleur temps de chargement de données réalisable serait d’environ 270 secondes (en supposant que vous saturez la carte réseau à 187,5 Mo/s débit). En revanche, unStandard_D5_v2(16 cœurs, 12 000 Mbits/s) charge les mêmes données en environ 33 secondes (en supposant que vous saturez la carte réseau à un débit de 1500 Mo/s).
- Par exemple, si vous utilisez une petite taille de machine virtuelle, par
- Niveau de stockage : Dans la plupart des scénarios, y compris les modèles LLM (Large Language Models), le stockage standard offre le meilleur profil coût/performances. Toutefois, si vous avez de nombreux petits fichiers, le stockage Premium offre un meilleur profil coût/performances. Pour plus d’informations, consultez Options de stockage Azure.
- Charge de stockage : Si le compte de stockage est soumis à une charge élevée (par exemple, de nombreux nœuds GPU dans un cluster demandant des données), vous risquez d’atteindre la capacité de sortie du stockage. Pour plus d'informations, consultez la page Charge de stockage. Si vous avez de nombreux petits fichiers qui nécessitent un accès en parallèle, vous pouvez atteindre les limites de requêtes de stockage. Consultez les informations à jour sur les limites de la capacité de sortie et des requêtes de stockage dans Cibles de mise à l’échelle pour des comptes de stockage standard.
- Modèle d’accès aux données en code utilisateur : Lorsque vous utilisez le mode montage, les données sont extraites en fonction des actions d’ouverture/de lecture de votre code. Par exemple, lors de la lecture de sections aléatoires d’un fichier volumineux, les paramètres de prérécupération des données par défaut des montages peuvent entraîner des téléchargements de blocs qui ne seront pas lus. Vous devrez peut-être régler certains paramètres pour atteindre le débit maximal. Pour plus d’informations, consultez Paramètres de montage optimaux pour des scénarios courants.
Utilisation des journaux pour diagnostiquer les problèmes
Pour accéder aux journaux du runtime de données à partir de votre travail :
- Sélectionnez l’onglet Sorties + Journaux dans la page du travail.
- Sélectionnez le dossier system_logs, puis le dossier data_capability.
- Vous devriez voir deux fichiers journaux :
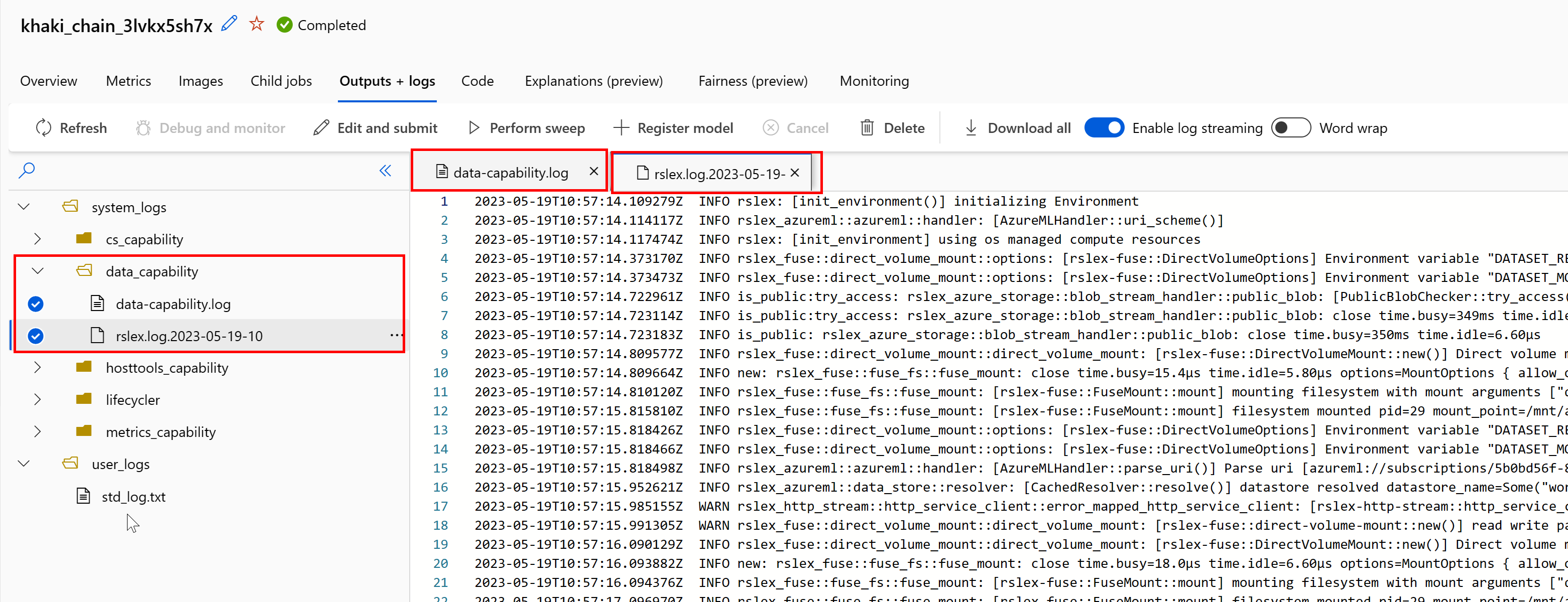

Le fichier journal data-capability.log présente des informations générales liées au temps passé sur les tâches de chargement de données clés. Par exemple, lorsque vous téléchargez des données, le runtime consigne les heures de début et de fin de l’activité de téléchargement :
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Si le débit de téléchargement ne représente qu'une fraction de la bande passante réseau prévue pour la taille de machine virtuelle, vous pouvez examiner le fichier journal rslex.log.<TIMESTAMP>. Ce fichier contient toute la journalisation fine du runtime basé sur Rust, par exemple, la parallélisation :
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Le fichier rslex.log fournit des détails sur toute la copie de fichier, que vous choisissiez ou non les modes montage ou téléchargement. Il décrit également les paramètres (variables d’environnement) utilisés. Pour commencer le débogage, vérifiez si vous avez défini les Paramètres de montage optimaux des scénarios courants.
Analyser le stockage Azure
Dans le portail Azure, vous pouvez sélectionner votre compte de stockage, puis Métriques pour consulter les métriques de stockage :

Vous tracez ensuite successE2ELatency et SuccessServerLatency. Si les métriques présentent une SuccessE2ELatency élevée et une SuccessServerLatency faible, le nombre de threads dont vous disposez est limité ou vos ressources telles que le processeur, la mémoire ou la bande passante réseau sont faibles, vous devriez :
- Utilisez la vue d’analyse d’Azure Machine Learning studio pour vérifier l’utilisation du processeur et de la mémoire de votre travail. Si vos ressources en processeur et en mémoire sont faibles, envisagez d’augmenter la taille de la machine virtuelle de la cible de calcul.
- Envisagez d’augmenter
RSLEX_DOWNLOADER_THREADSsi vous téléchargez et que vous n’utilisez pas le processeur et la mémoire. Si vous utilisez un montage, vous devez augmenterDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTpour effectuer plus de prérécupérations et augmenterDATASET_MOUNT_READ_THREADSpour effectuer plus de threads de lecture.
Si les métriques présentent une SuccessE2ELatency faible et une SuccessServerLatency faible, mais que le client rencontre une latence élevée, il y a un délai dans la requête de stockage qui atteint le service. Vous devez vérifier :
- Si le nombre de threads utilisés pour le montage/téléchargement (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) est trop faible par rapport au nombre de cœurs disponibles sur la cible de calcul. Si le paramètre est trop faible, augmentez le nombre de threads. - Si le nombre de nouvelles tentatives de téléchargement (
AZUREML_DATASET_HTTP_RETRY_COUNT) est trop élevé. Si c’est le cas, diminuez le nombre de nouvelles tentatives.
Analyser l’utilisation du disque pendant un travail
À partir d’Azure Machine Learning studio, vous pouvez également analyser les E/S et l’utilisation du disque de la cible de calcul pendant l’exécution de votre travail. Accédez à votre travail et sélectionnez l’onglet Analyse. Cet onglet fournit des aperçus des ressources de votre travail sur une plage dynamique de 30 jours. Exemple :

Remarque
L’analyse du travail prend uniquement en charge les ressources de calcul gérées par Azure Machine Learning. Les travaux avec un runtime de moins de 5 minutes n’ont pas suffisamment de données pour remplir cette vue.
Le runtime de données Azure Machine Learning n’utilise pas les derniers RESERVED_FREE_DISK_SPACE octets d’espace disque pour maintenir le calcul sain (la valeur par défaut est 150MB). Si votre disque est plein, votre code écrit des fichiers sur le disque sans déclarer les fichiers en tant que sortie. Par conséquent, vérifiez votre code pour vous assurer que les données ne sont pas écrites par erreur sur un disque temporaire. Si vous devez écrire des fichiers sur un disque temporaire et que cette ressource est pleine, envisagez de suivre les points suivants :
- Augmentation de la taille de la machine virtuelle à une machine virtuelle disposant d’un disque temporaire plus volumineux
- Définition d’une durée de vie des données mises en cache (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) pour supprimer définitivement vos données du disque
Colocaliser des données avec le calcul
Attention
Si votre stockage et votre calcul se trouvent dans des régions différentes, vos performances se dégradent, car les données doivent être transférées entre les régions. Cela augmente les coûts. Assurez-vous que votre compte de stockage et vos ressources de calcul se trouvent dans la même région.
Si vos données et votre espace de travail Azure Machine Learning sont stockés dans différentes régions, nous vous recommandons de copier les données vers un compte de stockage se trouvant dans la même région à l’aide de l’utilitaire azcopy. AzCopy utilise des API serveur à serveur, de sorte que les données sont copiées directement entre les serveurs de stockage. Ces opérations de copie n’utilisent pas la bande passante réseau de votre ordinateur. Vous pouvez augmenter le débit de ces opérations avec la variable d’environnement AZCOPY_CONCURRENCY_VALUE. Pour plus d’informations, consultez Augmenter la concurrence.
Charge de stockage
Un compte de stockage unique peut être limité lorsqu’il est soumis à une charge élevée, comme dans les cas suivants :
- Votre travail utilise de nombreux nœuds GPU
- Votre compte de stockage compte de nombreux utilisateurs/applications simultanés qui accèdent aux données lorsque vous exécutez votre travail
Cette section présente les calculs permettant de déterminer si la limitation peut constituer un problème pour votre charge de travail et comment aborder les réductions de limitation.
Calculer les limites de bande passante
Un compte de stockage Azure a une limite de sortie par défaut de 120 Gbits/s. Les machines virtuelles Azure ont des bandes passantes réseau différentes, ce qui a un effet sur le nombre théorique de nœuds de calcul nécessaires pour atteindre la capacité de sortie maximale par défaut du stockage :
| Taille | Carte GPU | Processeurs virtuels | Mémoire : Gio | Stockage temporaire (SSD) en Gio | Nombre de cartes GPU | Mémoire GPU : Gio | Bande passante réseau attendue (Gbits/s) | Max. par défaut de sortie du compte de stockage (Gbit/s)* | Nombre de nœuds pour atteindre la capacité de sortie par défaut |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6 000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6 400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Les deux références SKU A100/V100 ont une bande passante réseau maximale par nœud de 24 Gbits/s. Si chaque nœud lisant des données à partir d’un seul compte pouvait lire une quantité de données proche du maximum théorique de 24 Gbits/s, la capacité de sortie serait atteinte avec cinq nœuds. L’utilisation de six nœuds de calcul ou plus commencerait à dégrader le débit des données sur tous les nœuds.
Important
Si votre charge de travail a besoin de plus de six nœuds d’A100/V100, ou si vous pensez que vous dépasserez la capacité de sortie par défaut du stockage (120Gbit/s), contactez le support (via le portail Azure) et demandez une augmentation de la limite de sortie de stockage.
Mise à l’échelle de plusieurs comptes de stockage
Vous risquez de dépasser la capacité maximale de sortie du stockage et/ou d’atteindre les limites du taux de requête. Si ces problèmes surviennent, nous vous suggérons de contacter d’abord le service d’assistance, afin d’augmenter ces limites sur le compte de stockage.
Si vous ne pouvez pas augmenter la limite maximale de capacité de sortie ou de débit de requêtes, vous devez envisager de répliquer les données sur plusieurs comptes de stockage. Copiez les données sur plusieurs comptes avec Azure Data Factory, Explorateur Stockage Azure ou azcopy, puis montez tous les comptes dans votre travail d’apprentissage. Seules les données accédées sur un montage sont téléchargées. Par conséquent, votre code d’apprentissage peut lire le RANK à partir de la variable d’environnement et choisir parmi les multiples montages d’entrées à partir duquel lire. Votre définition de travail passe dans une liste de comptes de stockage :
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Votre code d’apprentissage Python peut ensuite utiliser RANK pour obtenir le compte de stockage spécifique à ce nœud :
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problème lié à de nombreux petits fichiers
La lecture de fichiers à partir du stockage implique d’effectuer des requêtes pour chaque fichier. Le nombre de requêtes par fichier varie en fonction de la taille des fichiers et des paramètres du logiciel qui gère les lectures de fichiers.
Les fichiers sont lus en blocs de taille de 1 à 4 Mo. Les fichiers plus petits qu’un bloc sont lus avec une seule requête (GET file.jpg 0-4 Mo) et les fichiers plus grands qu’un bloc font l’objet d’une requête par bloc (GET file.jpg 0-4 Mo, GET file.jpg 4 à 8 Mo). Ce tableau montre que les fichiers plus petits qu’un bloc de 4 Mo entraînent davantage de requêtes de stockage que les fichiers plus volumineux :
| Nombre de fichiers | Taille du fichier | Taille totale des données | Taille de bloc | Nombre de requêtes de stockage |
|---|---|---|---|---|
| 2 000 000 | 500 Ko | 1 To | 4 Mo | 2 000 000 |
| 1 000 | 1 Go | 1 To | 4 Mo | 256 000 |
Pour les petits fichiers, l’intervalle de latence implique principalement la gestion des requêtes de stockage, plutôt que les transferts de données. Par conséquent, nous vous recommandons ce qui suit pour augmenter la taille du fichier :
- Pour les données non structurées (images, vidéo, etc.), archive (zip/tar) petits fichiers ensemble, pour les stocker sous forme de fichier plus volumineux qui peut être lu en plusieurs blocs. Ces fichiers archivés plus volumineux peuvent être ouverts dans la ressource de calcul, et PyTorch Archive DataPipes peut extraire les fichiers plus petits.
- Pour les données structurées (CSV, parquet, etc.), examinez votre processus ETL afin de vous assurer qu’il fusionne les fichiers pour augmenter la taille. Spark dispose des méthodes
repartition()etcoalesce()pour augmenter la taille des fichiers.
Si vous ne pouvez pas augmenter la taille de vos fichiers, étudiez vos options de stockage Azure.
Options de stockage Azure
Le stockage Azure offre deux niveaux : Standard et Premium :
| Stockage | Scénario |
|---|---|
| Blob Azure - Standard (HDD) | Vos données sont structurées en objets blob plus volumineux ( images, vidéos, etc.). |
| Blob Azure - Premium (SSD) | Taux de transaction élevés, objets plus petits ou exigences de latence de stockage constamment faibles |
Conseil
Pour de « nombreux » petits fichiers (magnitude en Ko), nous vous recommandons d’utiliser premium (SSD), car le coût de stockage est inférieur aux coûts d’exécution du calcul GPU.
Lire des éléments de données de la version 1
Cette section explique comment lire des entités de données FileDataset et TabularDataset V1 dans un travail V2.
Lire un FileDataset
Dans l’objet Input, spécifiez type en tant que AssetTypes.MLTABLE et mode en tant que InputOutputModes.EVAL_MOUNT :
Remarque
Pour utiliser le calcul serverless, supprimez compute="cpu-cluster", dans ce code.
Pour plus d’informations sur l’objet MLClient, ses options d’initialisation et la manière de se connecter à un espace de travail, consultez Se connecter à un espace de travail.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Lire un TabularDataset
Dans l’objet Input, spécifiez type en tant que AssetTypes.MLTABLE et mode en tant que InputOutputModes.DIRECT :
Remarque
Pour utiliser le calcul serverless, supprimez compute="cpu-cluster", dans ce code.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Nettoyage
Si vous avez créé des ressources Azure pour ce didacticiel dont vous n’avez plus besoin, supprimez-les pour éviter les coûts :
Mettez à l’échelle votre cluster de calcul jusqu’à zéro nœud ou supprimez-le si vous n’en avez plus besoin :
az ml compute update --name cpu-cluster --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME> --min-instances 0Supprimez les ressources de données de sortie ou les conteneurs de stockage que vous avez créés lors du test.