Évaluer les résultats de l’expérience de Machine Learning automatisé
Cet article explique comment évaluer et comparer les modèles entraînés par votre expérience de Machine Learning automatisé. Au cours d’une expérience de Machine Learning automatisé, de nombreuses tâches sont créées, et chacune d’elles crée un modèle. Pour chaque modèle, le Machine Learning automatisé génère des métriques et des graphiques d’évaluation qui vous aident à mesurer les performances du modèle. Vous pouvez en outre générer un tableau de bord d'IA responsable pour effectuer une évaluation holistique et un débogage du meilleur modèle recommandé par défaut. Cela inclut des informations telles que les explications du modèle, l'explorateur d'équité et de performance, l'explorateur de données, l'analyse des erreurs de modèle. En savoir plus sur la façon dont vous pouvez générer un tableau de bord d'IA responsable.
Par exemple, le Machine Learning automatisé génère les graphiques suivants basés sur le type d’expérimentation.
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. La préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail en production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Prérequis
- Un abonnement Azure. (Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer)
- Une expérience Azure Machine Learning créée avec l’une des options suivantes :
- Azure Machine Learning Studio (aucun code requis)
- Le kit SDK Python d’Azure Machine Learning
Afficher les résultats de la tâche
Une fois votre expérience ML automatisé terminée, vous trouverez un historique des tâches via :
- Un navigateur avec Azure Machine Learning Studio
- Un notebook Jupyter utilisant le widget JobDetails Jupyter
Les étapes et la vidéo suivantes vous montrent comment afficher l’historique des exécutions et les graphiques ainsi que les métriques d’évaluation du modèle dans Studio :
- Connectez-vous au studio et accédez à votre espace de travail.
- Dans le menu de gauche, sélectionnez Emplois.
- Sélectionnez votre expérience dans la liste des expériences.
- Dans le tableau en bas de la page, sélectionnez une tâche de ML automatisé.
- Dans l’onglet Modèles, sélectionnez le Nom de l’algorithme du modèle que vous voulez évaluer.
- Dans l’onglet Métriques , utilisez les cases à cocher à gauche pour afficher les métriques et les graphiques.
Métriques de classification
Le ML automatisé calcule les métriques de performances pour chaque modèle de classification généré pour votre expérience. Ces métriques sont basées sur l’implémentation scikit-learn.
De nombreuses métriques de classification sont définies pour une classification binaire sur deux classes et nécessitent une moyenne de ces classes afin de générer un score pour la classification multiclasse. Scikit-learn offre plusieurs méthodes de calcul de la moyenne, dont trois s’appuient sur le ML automatisé : macro, micro et pondérée.
- Macro : calculer la métrique pour chaque classe et prendre la moyenne non pondérée
- Micro : calculer globalement la métrique en comptant le total des vrais positifs, des faux négatifs et des faux positifs (indépendamment des classes).
- Pondérée : calculer la métrique pour chaque classe et prendre la moyenne pondérée en fonction du nombre d’échantillons par classe.
Bien que chaque méthode de calcul de la moyenne présente ses avantages, il convient de considérer le déséquilibre des classes lors de la sélection de la méthode appropriée. Si les classes comportent un nombre différent d’échantillons, il peut être plus intéressant d’utiliser une macro moyenne dans laquelle les classes minoritaires sont affectées d’une pondération égale à celle des classes majoritaires. En savoir plus sur les métriques binaires et les métriques multiclasses dans le ML automatisé.
Le tableau suivant récapitule les métriques de performances de modèle calculées par le ML automatisé pour chaque modèle de classification généré pour votre expérience. Pour plus d’informations, consultez la documentation relative à scikit-learn dans le champ Calcul de chaque métrique.
Notes
Pour plus d’informations sur les métriques pour les modèles de classification d’images, consultez la section des métriques d’image.
| Métrique | Description | Calcul |
|---|---|---|
| AUC | « AUC » est Area under the Receiver Operating Characteristic Curve (la zone sous la courbe caractéristique de fonctionnement du récepteur). Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] Les noms de métriques pris en charge incluent, AUC_macro est la moyenne arithmétique de l’AUC pour chaque classe.AUC_micro est calculé en comptant le total des vrais positifs, des faux négatifs et des faux positifs. AUC_weighted est la moyenne arithmétique du score pour chaque classe, pondérée par le nombre d’instances « true » dans chaque classe. AUC_binary, valeur d’AUC en traitant une classe spécifique comme classe true et en combinant toutes les autres classes comme classe false. |
Calcul |
| accuracy | La précision représente le taux de prédictions qui correspondent exactement aux étiquettes de classes réelles. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] |
Calcul |
| average_precision | La précision moyenne résume la courbe précision-rappel comme moyenne pondérée des précisions atteintes à chaque seuil, avec l’augmentation du rappel du seuil précédent utilisé comme pondération. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] Les noms de métriques pris en charge incluent, average_precision_score_macro est la moyenne arithmétique du score de précision moyen de chaque classe.average_precision_score_micro est calculé en comptant le total des vrais positifs, des faux négatifs et des faux positifs.average_precision_score_weighted est la moyenne arithmétique du score de précision moyen pour chaque classe, pondérée par le nombre d’instances « true » dans chaque classe. average_precision_score_binary, valeur de la précision moyenne en traitant une classe spécifique comme classe true et en combinant toutes les autres classes comme classe false. |
Calcul |
| balanced_accuracy | La précision équilibrée est la moyenne arithmétique du rappel pour chaque classe. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] |
Calcul |
| f1_score | Le score F1 est la moyenne harmonique de la précision et du rappel. Il s’agit d’une métrique équilibrée de faux positifs et de faux négatifs. Toutefois, elle ne prend pas en compte les vrais négatifs. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] Les noms de métriques pris en charge incluent, f1_score_macro est la moyenne arithmétique du score F1 pour chaque classe. f1_score_micro est calculé en comptant le total des vrais positifs, des faux négatifs et des faux positifs. f1_score_weighted : moyenne pondérée par fréquence de classe du score F1 pour chaque classe. f1_score_binary, valeur de F1 en traitant une classe spécifique comme classe true et en combinant toutes les autres classes comme classe false. |
Calcul |
| log_loss | Il s’agit de la fonction de perte utilisée dans la régression logistique (multinomiale) et les extensions de celle-ci, comme les réseaux neuronaux, définie comme la probabilité logarithmique négative des étiquettes réelles, étant données les prédictions d’un classifieur probabiliste. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) |
Calcul |
| norm_macro_recall | Le rappel macro normalisé représente un rappel macro moyen et normalisé, de sorte que la performance aléatoire affiche un score de 0 et la performance parfaite un score de 1. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] |
(recall_score_macro - R) / (1 - R) où R est la valeur attendue de recall_score_macro pour les prédictions aléatoires.R = 0.5 pour la classification binaire. R = (1 / C) pour les problèmes de classification de classe C. |
| matthews_correlation | Le coefficient de corrélation Matthews est une métrique équilibrée de précision, qui peut être utilisé même si une classe contient beaucoup plus d’échantillons qu’une autre. Un coefficient de 1 indique une prédiction parfaite, 0 une prédiction aléatoire, et-1 une prédiction inverse. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [-1, 1] |
Calcul |
| précision | La précision est la capacité d’un modèle à éviter d’étiqueter des échantillons négatifs comme positifs. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] Les noms de métriques pris en charge incluent, precision_score_macro est la moyenne arithmétique de la précision pour chaque classe. precision_score_micro est calculé globalement en comptant le total des vrais positifs et des faux positifs. precision_score_weighted est la moyenne arithmétique de la précision pour chaque classe, pondérée par le nombre d’instances « true » dans chaque classe. precision_score_binary, valeur de la précision en traitant une classe spécifique comme classe true et en combinant toutes les autres classes comme classe false. |
Calcul |
| rappel | Le rappel est la capacité d’un modèle à détecter tous les échantillons positifs. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] Les noms de métriques pris en charge incluent, recall_score_macro est la moyenne arithmétique du rappel pour chaque classe. recall_score_micro : calculé globalement en comptant le total des vrais positifs, des faux négatifs et des faux positifs.recall_score_weighted est la moyenne arithmétique du rappel pour chaque classe, pondérée par le nombre d’instances « true » dans chaque classe. recall_score_binary, valeur du rappel en traitant une classe spécifique comme classe true et en combinant toutes les autres classes comme classe false. |
Calcul |
| weighted_accuracy | La précision pondérée est la précision avec laquelle chaque échantillon est pondéré par le nombre total d’échantillons appartenant à la même classe. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [0, 1] |
Calcul |
Métriques de classification binaires et multiclasses
Le ML automatisé détecte automatiquement si les données sont binaires et permet également aux utilisateurs d’activer des métriques de classification binaire même si les données sont multiclasses en spécifiant une classe true. Les mesures de classification multi-classes sont rapportées si un ensemble de données comporte deux classes ou plus. Les métriques de classification binaire sont signalées uniquement lorsque les données sont binaires.
Notez que les métriques de classification multi-classe sont destinées à la classification multi-classe. Lorsqu'elles sont appliquées à un ensemble de données binaires, ces métriques ne traitent aucune classe comme la classe true, comme on peut s'y attendre. Les métriques qui sont clairement destinées à la multiclasse sont suivies d’un suffixe micro, macro ou weighted. average_precision_score, f1_score, precision_score, recall_score et AUC en sont des exemples. Par exemple, au lieu de calculer le rappel comme tp / (tp + fn), le rappel multiclasse pondéré (micro, macro ou weighted) fait la moyenne des deux classes d’un jeu de données de classification binaire. Cela revient à calculer le rappel pour la classe true et la classe false séparément, puis à obtenir la moyenne des deux.
En outre, bien que la détection automatique de la classification binaire soit prise en charge, il est recommandé de toujours spécifier la classe true manuellement pour s’assurer que les métriques de classification binaire sont calculées pour la bonne classe.
Pour activer les métriques pour les jeux de données de classification binaire lorsque le jeu de données lui-même est multiclasse, les utilisateurs n’ont qu’à spécifier la classe à traiter comme classe true, et ces métriques sont calculées.
Matrice de confusion
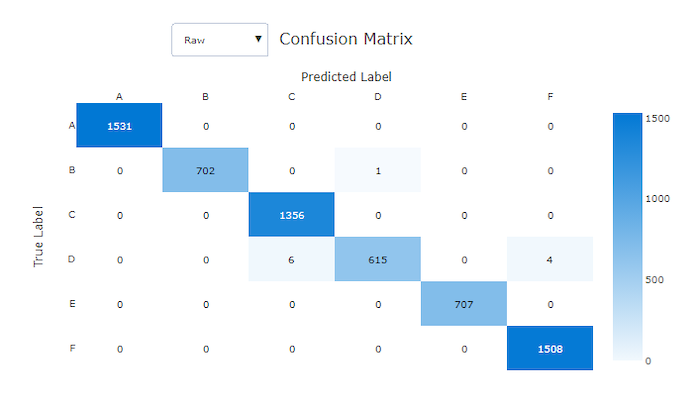
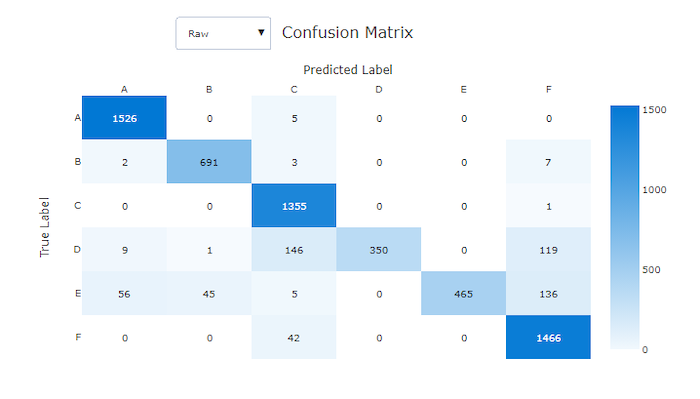
Les matrices de confusion fournissent un visuel de la manière dont un modèle de Machine Learning génère des erreurs systématiques dans ses prédictions pour les modèles de classification. Le terme « confusion » dans le nom provient d’un modèle « confus » ou d’un mauvais étiquetage des échantillons. Une cellule à la ligne i et dans la colonne j d’une matrice de confusion contient le nombre d’échantillons dans le jeu de données d’évaluation qui appartiennent à la classe C_i et qui sont classifiés par le modèle en tant que classe C_j.
Dans Studio, une cellule plus sombre indique un plus grand nombre d’échantillons. La sélection de la vue normalisée dans la liste déroulante normalise les données de chaque ligne de la matrice afin d’afficher le pourcentage de classe C_i prédit comme étant une classe C_j. La vue brute par défaut offre l’avantage de pouvoir vérifier si le modèle a mal classifié les échantillons de la classe minoritaire en raison d’un déséquilibre dans la distribution des classes réelles, un problème courant dans les jeux de données déséquilibrés.
Dans un bon modèle, la matrice de confusion affiche la plupart des échantillons le long de la diagonale.
Matrice de confusion pour un bon modèle
Matrice de confusion pour un mauvais modèle
Courbe ROC
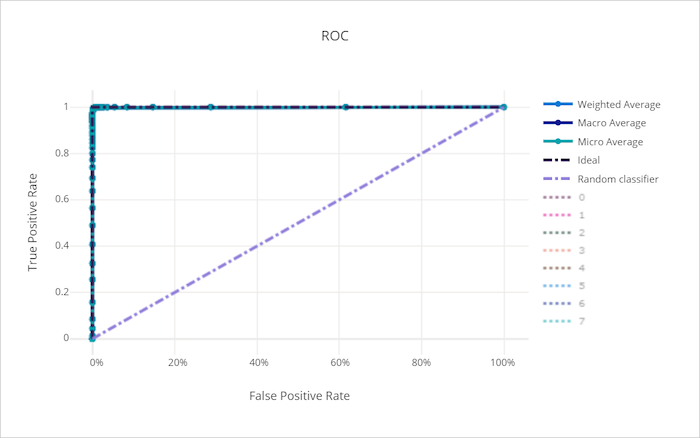
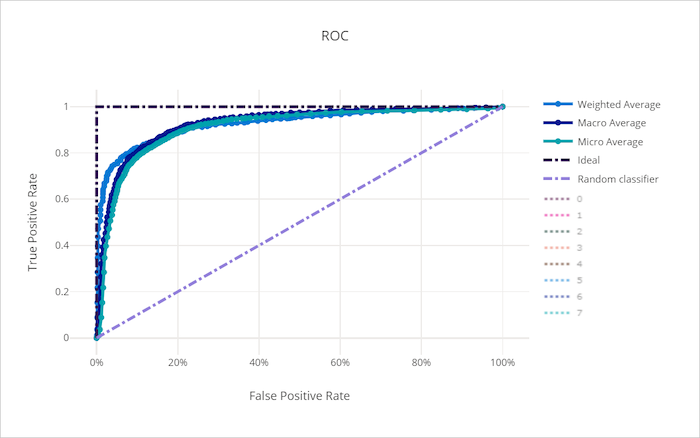
La courbe ROC (receiver operating characteristic) trace la relation entre le taux de vrais positifs (TPR) et le taux de faux positifs (FPR), à mesure que le seuil de décision varie. La courbe ROC peut être moins intéressante lors de l’apprentissage de modèles sur des jeux de données avec un déséquilibre de classe élevé, car la classe majoritaire peut être submergée par les classes minoritaires.
La zone sous la courbe (AUC) peut être interprétée comme la proportion d’échantillons correctement classés. Plus précisément, la valeur AUC représente la probabilité que le classifieur classe un échantillon positif choisi de façon aléatoire à un rang plus élevé qu’un échantillon négatif choisi de façon aléatoire. La forme de la courbe donne une indication de la relation entre les valeurs TPR et FPR en tant que fonction du seuil de classification ou de la limite de décision.
Une courbe qui approche l’angle supérieur gauche du graphique atteint une valeur TPR de 100 % et une valeur FPR de 0 %, ce qui correspond au meilleur modèle possible. Un modèle aléatoire produit une courbe ROC le long de la ligne y = x, de l’angle inférieur gauche à l’angle supérieur droit. Un modèle pire qu’aléatoire aurait une courbe ROC qui passe sous la ligne y = x.
Conseil
Pour les expériences de classification, chacun des graphiques en courbes produits pour les modèles ML automatisés peut être utilisé pour évaluer le modèle par classe ou la moyenne de toutes les classes. Vous pouvez basculer entre ces différentes vues en cliquant sur les étiquettes de classe dans la légende à droite du graphique.
Courbe ROC pour un bon modèle
Courbe ROC pour un mauvais modèle
Courbe de rappel de précision
La courbe de rappel de précision dessine la relation qui existe entre la précision et le rappel à mesure que le seuil de décision varie. Le rappel est la capacité d’un modèle à détecter tous les échantillons positifs, tandis que la précision est la capacité d’un modèle à éviter d’étiqueter des échantillons négatifs comme positifs. Certains problèmes qui affectent l’entreprise peuvent nécessiter un rappel plus élevé et une plus grande précision selon l’importance relative d’éviter les faux négatifs et les faux positifs.
Conseil
Pour les expériences de classification, chacun des graphiques en courbes produits pour les modèles ML automatisés peut être utilisé pour évaluer le modèle par classe ou la moyenne de toutes les classes. Vous pouvez basculer entre ces différentes vues en cliquant sur les étiquettes de classe dans la légende à droite du graphique.
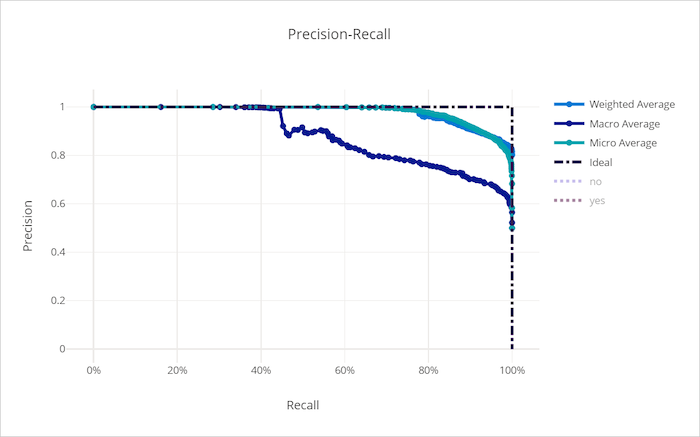
Courbe de rappel-précision pour un bon modèle
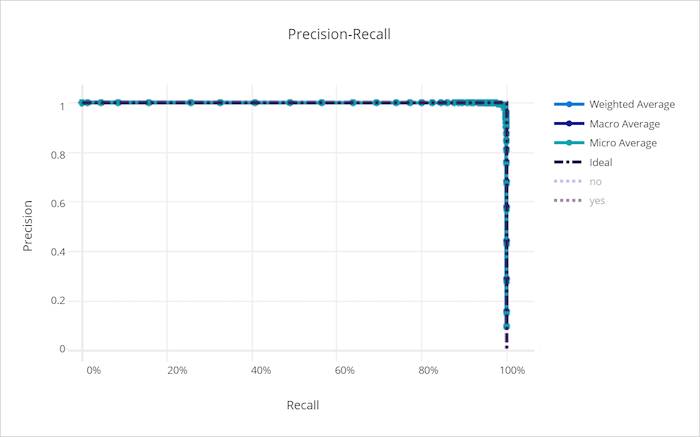
Courbe de rappel de précision pour un mauvais modèle
Courbe de gains cumulés
La courbe de gains cumulés trace le pourcentage d’échantillons positifs correctement classés en fonction du pourcentage d’échantillons considérés dans l’ordre de probabilité prédite.
Pour calculer le gain, triez tout d’abord tous les échantillons de la probabilité la plus élevée à la probabilité la plus faible prédites par le modèle. Prenez ensuite x% des prédictions affichant la confiance la plus élevée. Divisez le nombre d’échantillons positifs détectés dans x% par le nombre total d’échantillons positifs pour obtenir le gain. Le gain cumulatif représente le pourcentage d’échantillons positifs que nous détectons en considérant un pourcentage des données les plus susceptibles d’appartenir à la classe positive.
Un modèle parfait classe tous les échantillons positifs au-dessus de tous les échantillons négatifs, ce qui donne une courbe de gains cumulés composée de deux segments droits. Le premier segment est une ligne avec une pente 1 / x de (0, 0) à (x, 1), où x est la fraction d’échantillons qui appartiennent à la classe positive (1 / num_classes si les classes sont équilibrées). Le second segment est une ligne horizontale de (x, 1) à (1, 1). Dans le premier segment, tous les échantillons positifs sont classés correctement et le gain cumulatif passe à 100% dans les x% premiers exemples pris en compte.
Le modèle aléatoire avec base de référence a une courbe de gains cumulés qui suit y = x où, pour x% exemples considérés, seuls x% échantillons positifs totaux environ ont été détectés. Un modèle parfait pour un jeu de données équilibré a une courbe moyenne micro et une ligne moyenne macro avec une pente num_classes jusqu’à ce que le gain cumulatif soit de 100 %, puis qui devient horizontale jusqu’à que ce le pourcentage de données soit de 100.
Conseil
Pour les expériences de classification, chacun des graphiques en courbes produits pour les modèles ML automatisés peut être utilisé pour évaluer le modèle par classe ou la moyenne de toutes les classes. Vous pouvez basculer entre ces différentes vues en cliquant sur les étiquettes de classe dans la légende à droite du graphique.
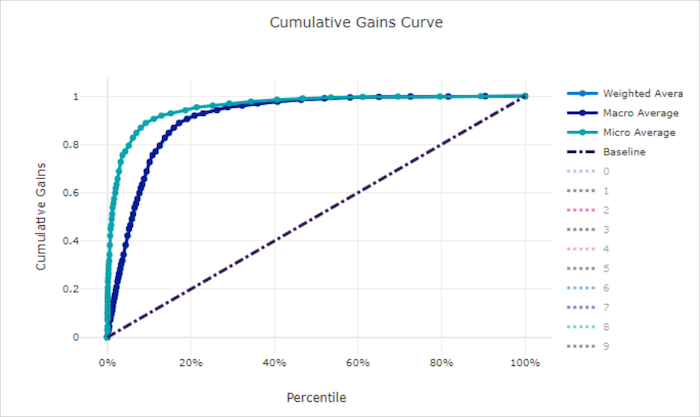
Courbe de gains cumulés pour un bon modèle
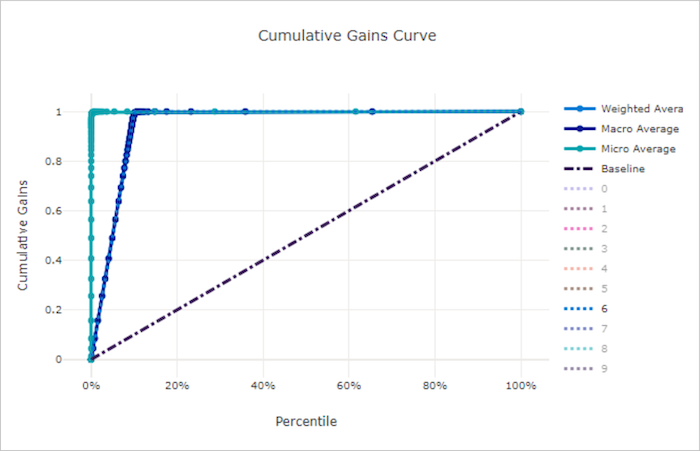
Courbe des gains cumulés pour un mauvais modèle
Courbe d’élévation
La courbe d’élévation montre dans quelle mesure un modèle est plus performant qu’un modèle aléatoire. L’élévation est définie comme le rapport entre le gain cumulé et le gain cumulatif d’un modèle aléatoire (qui devrait toujours être égal à 1).
Cette performance relative prend en compte le fait que la classification est plus difficile lorsque vous augmentez le nombre de classes. (Un modèle aléatoire prédit de manière incorrecte une fraction plus élevée d’échantillons d’un jeu de données avec 10 classes par rapport à un jeu de données avec deux classes)
La courbe d’élévation de ligne de base représente la ligne y = 1 dans laquelle les performances du modèle sont cohérentes avec celles d’un modèle aléatoire. En général, la courbe d’élévation d’un bon modèle est plus haute sur ce graphique et plus éloignée de l’axe des x, ce qui indique que lorsque le modèle affiche ses prédictions les plus fiables, il est beaucoup plus performant que le modèle aléatoire.
Conseil
Pour les expériences de classification, chacun des graphiques en courbes produits pour les modèles ML automatisés peut être utilisé pour évaluer le modèle par classe ou la moyenne de toutes les classes. Vous pouvez basculer entre ces différentes vues en cliquant sur les étiquettes de classe dans la légende à droite du graphique.
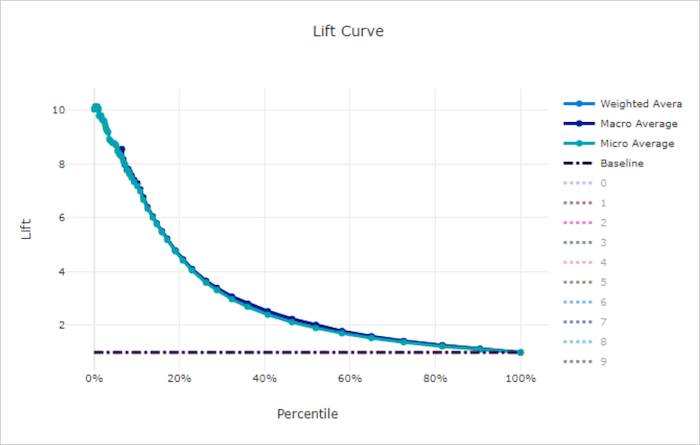
Courbe d’élévation pour un bon modèle
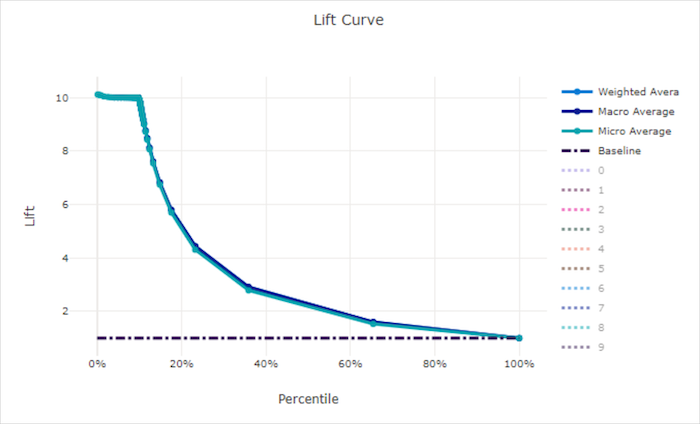
Courbe d’élévation pour un mauvais modèle
Courbe d’étalonnage
La courbe d’étalonnage trace la confiance d’un modèle dans ses prédictions par rapport à la proportion d’échantillons positifs à chaque niveau de confiance. Un modèle bien étalonné va correctement classer 100 % des prédictions auxquelles il affecte une confiance de 100 %, 50 % des prédictions auxquelles il affecte une confiance de 50 %, 20 % des prédictions auxquelles il affecte une confiance de 20 %, et ainsi de suite. Un modèle parfaitement étalonné a une courbe d’étalonnage qui suit la ligne y = x, dans laquelle le modèle prédit parfaitement la probabilité que les échantillons appartiennent à chaque classe.
Un modèle trop confiant prédit excessivement des probabilités proches de zéro et un, étant rarement incertain quant à la classe de chaque exemple, et la courbe d’étalonnage ressemblera à un « S » inversé. Un modèle sous-confiant attribue une probabilité inférieure en moyenne à la classe qu’il prédit, et la courbe d’étalonnage associée ressemble à un « S ». La courbe d’étalonnage ne représente pas la capacité d’un modèle à être correctement classifié, mais plutôt sa capacité à attribuer correctement un niveau de confiance à ses prédictions. Un mauvais modèle peut toujours afficher une bonne courbe d’étalonnage si le modèle attribue correctement une faible confiance et une haute incertitude.
Notes
La courbe d’étalonnage est sensible au nombre d’échantillons, donc un petit jeu de validation peut produire des résultats difficiles à interpréter. Cela ne signifie pas nécessairement que le modèle n’est pas correctement étalonné.
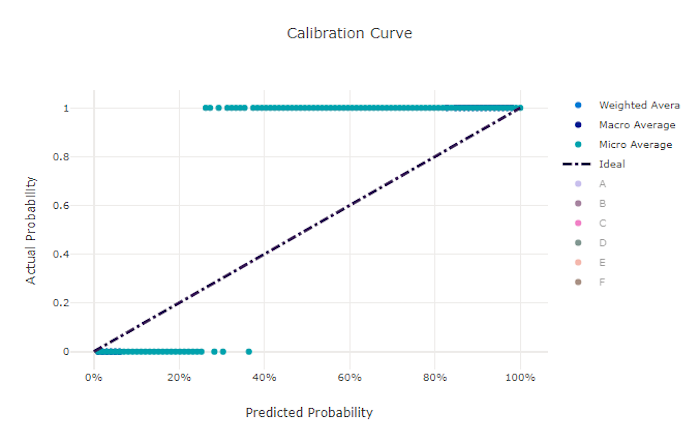
Courbe d’étalonnage pour un bon modèle
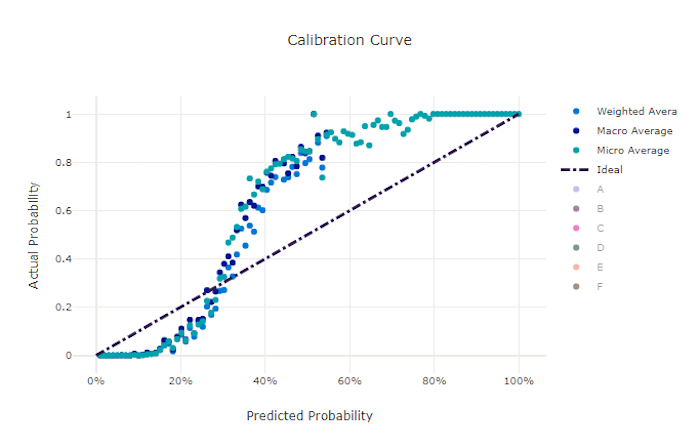
Courbe d’étalonnage pour un mauvais modèle
Métriques de régression/prévision
Le ML automatisé calcule les mêmes métriques de performances pour chaque modèle généré, qu’il s’agisse d’une expérience de régression ou de prévision. Ces mesures sont également soumises à la normalisation pour permettre une comparaison entre les modèles formés sur des données avec des plages différentes. Pour plus d’informations, consultez Normalisation des métriques.
Le tableau suivant récapitule les métriques de performance de modèle générées pour les expériences de régression et de prévision. Comme les métriques de classification, ces métriques sont également basées sur des implémentations scikit learn. La documentation scikit learn correspondante est liée en conséquence, dans le champ Calcul.
| Métrique | Description | Calcul |
|---|---|---|
| explained_variance | La variance expliquée évalue dans quelle mesure un modèle tient compte de la variation dans la variable cible. C’est le pourcentage de diminution de la variance des données d’origine par rapport à la variance des erreurs. Lorsque la moyenne des erreurs est 0, elle est égale au coefficient de détermination (voir r2_score dans le graphique suivant). Objectif : plus la valeur est proche de 1, mieux c’est Plage : (-inf, 1] |
Calcul |
| mean_absolute_error | L’erreur d’absolue moyenne est la valeur attendue de la valeur absolue de la différence entre la cible et la prédiction. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) Types : mean_absolute_error normalized_mean_absolute_error est la valeur mean_absolute_error divisée par la plage des données. |
Calcul |
| mean_absolute_percentage_error | L’erreur de pourcentage absolue moyenne (MAPE) mesure la différence moyenne entre une valeur prédite et la valeur réelle. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) |
|
| median_absolute_error | L’erreur absolue médiane est la médiane de toutes les différences absolues entre la cible et la prédiction. Cette perte est robuste pour les valeurs hors norme. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) Types : median_absolute_errornormalized_median_absolute_error est la valeur median_absolute_error divisée par la plage des données. |
Calcul |
| r2_score | R2 (le coefficient de détermination) mesure la réduction proportionnelle de l’erreur carrée moyenne (MSE) par rapport à la variance totale des données observées. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [-1, 1] Remarque : R2 comprend souvent la plage [-inf, 1]. L’erreur carrée moyenne peut être plus grande que la variance observée ; par conséquent, R2 peut avoir des valeurs négatives arbitrairement grandes, en fonction des données et des prédictions de modèle. Les clips Machine Learning automatisé ont signalé des scores R2 à -1, par conséquent, une valeur de -1 pour R2 signifie probablement que le véritable score R2 est inférieur à -1. Tenez compte des autres valeurs de métriques et des propriétés des données lors de l’interprétation d’un score R2 négatif. |
Calcul |
| root_mean_squared_error | L’erreur quadratique moyenne racine (RMSE) est la racine carrée de la différence quadratique attendue entre la cible et la prédiction. Pour un estimateur non biaisé, la valeur RMSE est égale à l’écart type. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) Types : root_mean_squared_error normalized_root_mean_squared_error est la valeur root_mean_squared_error divisée par la plage des données. |
Calcul |
| root_mean_squared_log_error | L’erreur logarithmique quadratique moyenne racine est la racine carrée de l’erreur logarithmique quadratique attendue. Objectif : Plus la valeur est proche de 0, mieux c’est Plage : [0, inf) Types : root_mean_squared_log_error normalized_root_mean_squared_log_error est la valeur root_mean_squared_log_error divisée par la plage des données. |
Calcul |
| spearman_correlation | La corrélation de Spearman est une mesure non paramétrique de la monotonie de la relation entre deux jeux de données. Contrairement à la corrélation de Pearson, la corrélation de Spearman ne part pas du principe que les deux jeux de données sont normalement distribués. Comme d’autres coefficients de corrélation, la corrélation de Spearman varie entre -1 et 1, 0 impliquant l’absence de corrélation. Les corrélations de -1 ou 1 impliquent une relation monotone exacte. La corrélation de Spearman est une métrique de corrélation de l’ordre de classement, ce qui signifie que les modifications apportées aux valeurs prédites ou réelles ne changeront pas le résultat Spearman si elles ne modifient pas l’ordre de classement des valeurs prédites ou réelles. Objectif : plus la valeur est proche de 1, mieux c’est Plage : [-1, 1] |
Calcul |
Normalisation des métriques
Le ML automatisé normalise les métriques de régression et de prévision, ce qui permet une comparaison entre les modèles entraînés sur des données avec des plages différentes. Un modèle formé sur des données avec une plus grande plage affiche une erreur plus élevée que le même modèle formé sur des données avec une plage plus restreinte, sauf si cette erreur est normalisée.
Bien qu’il n’existe pas de méthode standard pour normaliser les métriques d’erreur, le ML automatisé adopte l’approche courante consistant à diviser l’erreur par la plage des données : normalized_error = error / (y_max - y_min)
Remarque
La plage de données n’est pas enregistrée avec le modèle. Si vous procédez à une inférence avec le même modèle sur un jeu de test de données d’exclusion, y_min et y_max peuvent changer en fonction des données de test, et les métriques normalisées ne peuvent pas être utilisées directement pour comparer les performances du modèle sur les jeux de formation et de test. Vous pouvez transmettre la valeur de y_min et y_max de votre jeu de formation pour rendre la comparaison équitable.
Métriques de prévision : normalisation et agrégation
Le calcul des métriques pour l’évaluation des modèles de prévision nécessite des considérations spéciales lorsque les données contiennent plusieurs séries chronologiques. Il existe deux choix naturels pour agréger des métriques sur plusieurs séries :
- Moyenne macro dans laquelle les métriques d’évaluation de chaque série reçoivent un poids égal,
- Une micro moyenne dans laquelle les métriques d’évaluation pour chaque prédiction ont une pondération égale.
Ces cas ont des analogies directes avec la moyenne macro et la moyenne micro dans la classification multiclasse.
La distinction entre la moyenne macro et la moyenne micro peut être importante lors de la sélection d’une métrique principale pour la sélection du modèle. Par exemple, considérez un scénario de vente au détail dans lequel vous souhaitez prévoir la demande pour une sélection de produits de consommation. Certains produits se vendent à des volumes plus élevés que d’autres. Si vous choisissez un RMSE à micro-moyenne comme métrique principale, il est possible que les éléments à volume élevé contribuent à la majorité de l’erreur de modélisation et, par conséquent, dominent la métrique. L’algorithme de sélection de modèle peut favoriser les modèles avec une précision plus élevée sur les éléments à volume élevé que sur les éléments à faible volume. En revanche, un RMSE normalisé à moyenne macro donne aux éléments à faible volume une pondération approximativement égale à celle des éléments à volume élevé.
Le tableau suivant répertorie les métriques de prévision d’AutoML qui utilisent la moyenne macro et la moyenne micro :
| Moyenne des macros | Micro moyenne |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Notez que les métriques macro-moyennes normalisent chaque série séparément. Les métriques normalisées de chaque série sont ensuite calculées en moyenne pour donner le résultat final. Le choix correct de macro et de micro dépend du scénario métier, mais nous vous recommandons généralement d’utiliser normalized_root_mean_squared_error.
Résidus
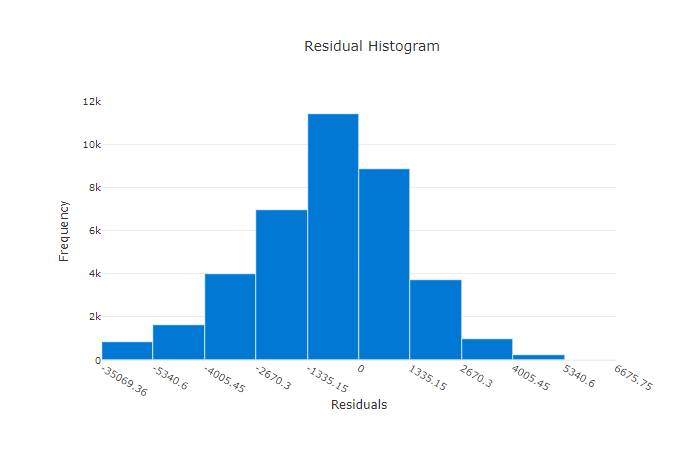
Le graphique des résidus est un histogramme des erreurs de prédiction (résidus) générées pour les expériences de régression et de prévision. Les résidus sont calculés en tant que y_predicted - y_true pour tous les échantillons, puis affichés sous la forme d’un histogramme pour afficher l’écart du modèle.
Dans cet exemple, les deux modèles sont légèrement biaisés pour prédire une valeur inférieure à la valeur réelle. Ce cas n’est pas rare pour un jeu de données avec une distribution asymétrique de cibles réelles, mais c’est le signe de performances de modèle médiocres. Un bon modèle a une distribution résiduelle proche de zéro avec peu de restes aux extrêmes. Un mauvais modèle a une distribution répartie des résidus avec moins d’échantillons autour de zéro.
Graphique des résidus pour un bon modèle
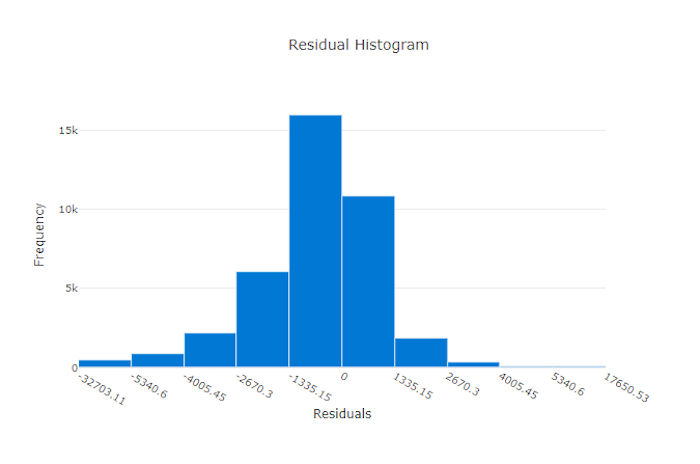
Graphique des résidus pour un mauvais modèle
Prédiction et résultat
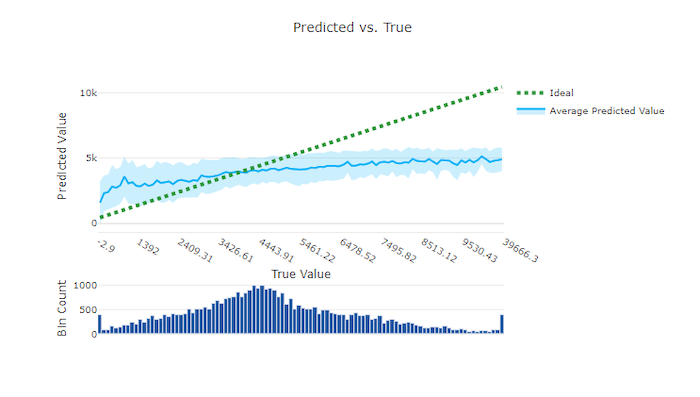
Pour les expériences de régression et de prévision, le graphique de prédiction et résultat trace la relation entre la fonctionnalité cible (valeurs vraies/réelles) et les prédictions du modèle. Les valeurs vraies sont compartimentées le long de l’axe des x et, pour chaque compartiment, la valeur moyenne prédite est tracée avec des barres d’erreur. Cela vous permet de voir si un modèle est biaisé vers la prédiction de certaines valeurs. La ligne affiche la prédiction moyenne et la zone ombrée indique la variance des prédictions autour de cette moyenne.
Souvent, la valeur vraie la plus courante affiche les prédictions les plus précises avec la variance la plus faible. La distance de la courbe de tendance par rapport à la ligne y = x idéale où il y a peu de valeurs vraies est une bonne mesure des performances du modèle sur les valeurs hors norme. Vous pouvez utiliser l’histogramme au bas du graphique pour connaître la distribution réelle des données. L’ajout d’autres exemples de données où la distribution est partiellement allouée peut améliorer les performances du modèle sur les données non visibles.
Dans cet exemple, notez que le meilleur modèle comporte une ligne de prédiction et résultat plus proche de la ligne y = x idéale.
Graphique prédit et graphique réel pour un bon modèle
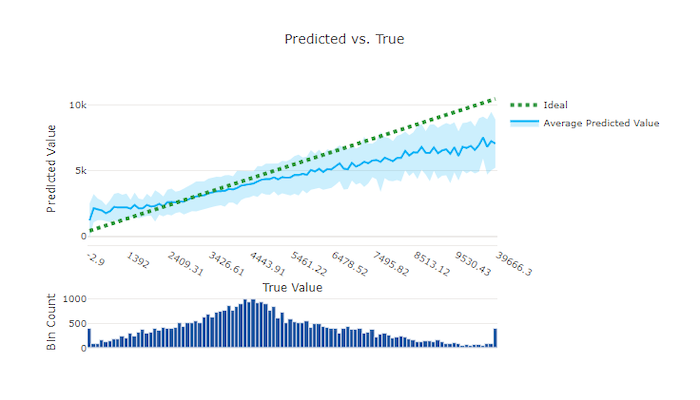
Graphique prédit et réel pour un mauvais modèle
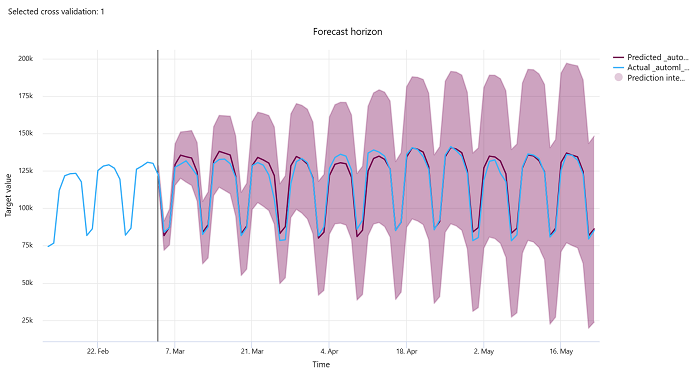
Horizon de prévision
Pour les expériences de prévision, le graphique d’horizon de prévision trace la relation entre la valeur prédite par les modèles et les valeurs réelles mappées au fil du temps par pli de validation croisée, jusqu’à cinq plis. L’axe X mappe l’heure en fonction de la fréquence que vous avez fournie pendant la configuration de la formation. La ligne verticale du graphique marque le point d’horizon de prévision, également appelé ligne d’horizon, qui correspond à la période à laquelle vous souhaitez commencer à générer des prédictions. À gauche de la ligne d’horizon de prévision, vous pouvez afficher les données de formation historiques pour mieux visualiser les tendances passées. À droite de l’horizon de prévision, vous pouvez visualiser les prédictions (la ligne violette) par rapport aux valeurs réelles (la ligne bleue) pour les différents plis de validation croisée et identificateurs de série chronologique. La zone violette ombrée indique les intervalles de confiance ou la variance des prédictions autour de cette moyenne.
Vous pouvez choisir les combinaisons d’identificateurs de pli de validation croisée et de série chronologique à afficher en cliquant sur l’icône de crayon de modification dans le coin supérieur droit du graphique. Effectuez une sélection parmi les cinq premiers plis de validation croisée et jusqu’à 20 identificateurs de série chronologique différents pour visualiser le graphique pour vos différentes séries chronologiques.
Important
Ce graphique est disponible dans l’exécution de l’entraînement pour les modèles générés à partir des données d’entraînement et de validation, ainsi que dans la série de tests basée sur des données d’entraînement et des données de test. Nous autorisons jusqu’à 20 points de données avant et jusqu’à 80 points de données après l’origine de la prévision. Pour les modèles DNN, ce graphique de l’exécution d’entraînement montre les données de la dernière époque, c’est-à-dire une fois l’entraînement du modèle complètement terminé. Ce graphique de la série de tests peut avoir un décalage avant la ligne d’horizon si les données de validation ont été fournies explicitement pendant l’exécution de l’entraînement. Cela est dû au fait que les données d’entraînement et les données de test sont utilisées dans la série de tests en laissant de côté les données de validation, ce qui se traduit par un écart.
Métriques pour les modèles d’image (préversion)
Le ML automatisé utilise les images du jeu de données de validation pour évaluer les performances du modèle. Les performances du modèle sont mesurées au niveau de l’époque pour comprendre la progression de la formation. Une époque s’écoule lorsqu’un jeu de données entier effectue un aller-retour par le réseau neuronal exactement une fois.
Métriques de classification d’images
La principale métrique d’évaluation est l’exactitude pour les modèles de classification binaire et multiclasse et IoU (Intersection over Union) pour les modèles de classification multiétiquette. Les métriques de classification pour les modèles de classification d’images sont identiques à celles définies dans la section sur les métriques de classification. Les valeurs de perte associées à une époque sont également journalisées, ce qui permet de suivre la progression de la formation et de déterminer si le modèle est surajusté ou sous-ajusté.
Chaque prédiction d’un modèle de classification est associée à un score de confiance, qui indique le niveau de confiance avec lequel la prédiction a été effectuée. Par défaut, les modèles de classification d’images multi-étiquettes sont évalués avec un seuil de score de 0,5, ce qui signifie que seules les prédictions ayant au moins ce niveau de confiance sont considérées comme une prédiction positive pour la classe associée. La classification multiclasse n’utilise pas de seuil de score ; au lieu de cela, la classe avec le score de confiance maximal est considérée comme la prédiction.
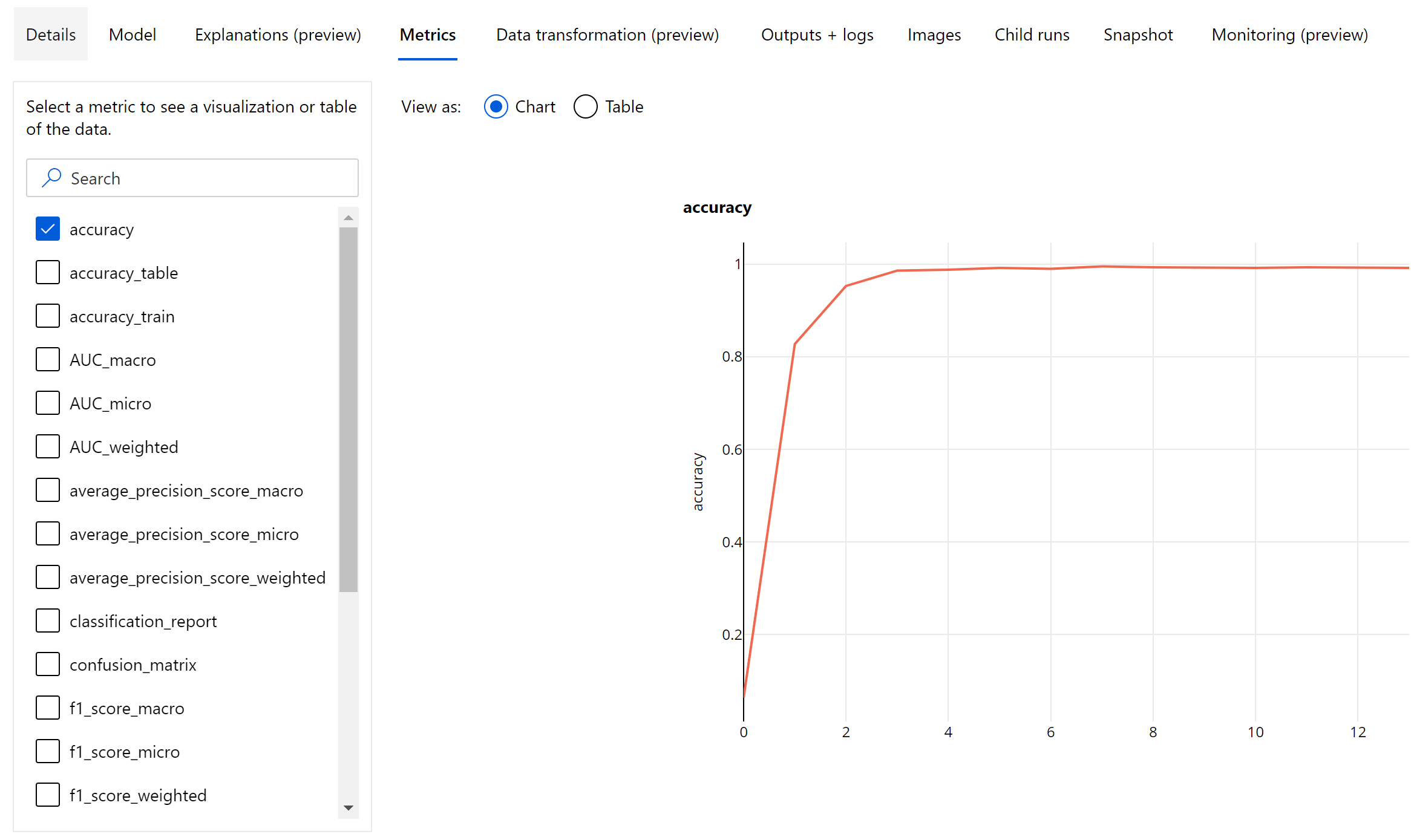
Métriques au niveau de l’époque pour la classification d’images
Contrairement aux métriques de classification pour les jeux de données tabulaires, les modèles de classification d’images consignent toutes les métriques de classification au niveau de l’époque, comme indiqué ci-dessous.
Métriques récapitulatives pour la classification d’images
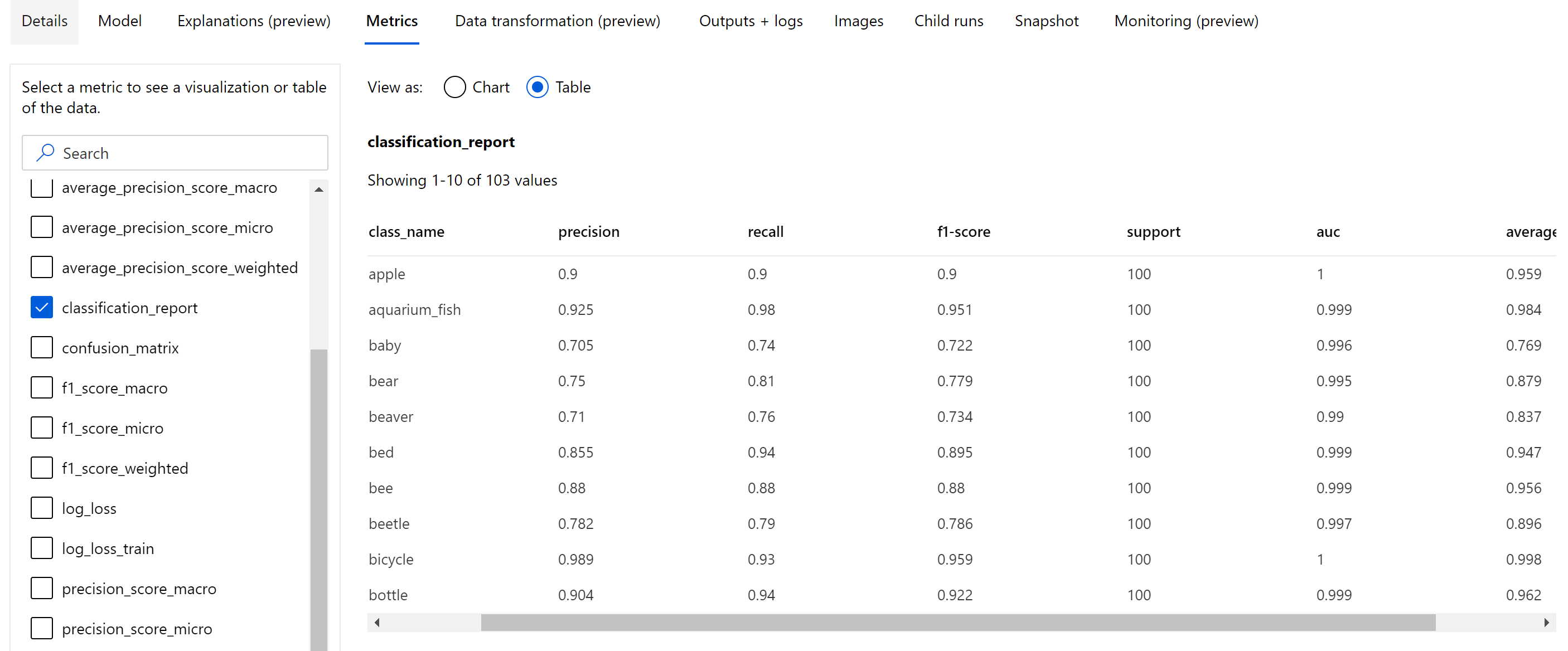
Outre les métriques scalaires qui sont consignées au niveau de l’époque, le modèle de classification d’images consigne également des métriques récapitulatives telles que la matrice de confusion, des graphiques de classification, y compris la courbe ROC, la courbe précision-rappel et le rapport de classification pour le modèle de la meilleure époque à laquelle nous obtenons le score de la métrique principale (exactitude) le plus élevé.
Le rapport de classification fournit les valeurs au niveau de la classe pour des métriques telles que precision, recall, f1-score, support, auc et average_precision avec différents niveaux de moyenne (micro, macro et pondéré) comme indiqué ci-dessous. Reportez-vous aux définitions de métriques de la section des métriques de classification.
Métriques de détection d’objet et de segmentation d’instance
Chaque prédiction d’un modèle de détection d’objet image ou de segmentation d’instance est associée à un score de confiance.
Les prédictions dont le score de confiance est supérieur au seuil de score sont générées en tant que prédictions et utilisées dans le calcul de la métrique, dont la valeur par défaut est spécifique au modèle et peut être consultée sur la page Optimisation des hyperparamètres (hyperparamètre box_score_threshold).
Le calcul de métrique d’un modèle de détection d’objet image et de segmentation d’instance est basé sur une mesure de chevauchement définie par une métrique appelée IoU (Intersection over Union) qui est calculée en divisant l’aire de chevauchement entre la vérité de base et les prédictions par l’aire d’union de la vérité de base et des prédictions. L’IoU calculée à partir de chaque prédiction est comparée à un seuil de chevauchement, appelé seuil IoU, qui détermine dans quelle mesure une prédiction doit chevaucher la vérité de base annotée par l’utilisateur pour être considérée comme une prédiction positive. Si l’IoU calculée à partir de la prédiction est inférieure au seuil de chevauchement, la prédiction n’est pas considérée comme une prédiction positive pour la classe associée.
La principale métrique pour l’évaluation des modèles de détection d’objet image et de segmentation d’instance est la précision moyenne (mAP) . La mAP est la valeur moyenne de la précision moyenne (AP) pour toutes les classes. Les modèles de détection d’objet de ML automatisé permettent de calculer la mAP à l’aide des deux méthodes populaires suivantes.
Métriques Pascal VOC :
La mAP de Pascal VOC est la méthode de calcul par défaut de la mAP pour les modèles de détection d’objet et de segmentation d’instance. La méthode mAP de type Pascal VOC calcule l’aire sous une version de la courbe précision-rappel. Tout d’abord, la fonction p(rᵢ), qui est la précision au rappel i, est calculée pour toutes les valeurs de rappel uniques. p(rᵢ) est ensuite remplacée par la précision maximale obtenue pour tout rappel r’ >= rᵢ. La valeur de la précision est monotone et décroissante dans cette version de la courbe. La métrique mAP Pascal VOC est évaluée par défaut avec un seuil IoU de 0,5. Une explication détaillée de ce concept est disponible dans ce blog.
Métriques COCO :
La méthode d’évaluation COCO utilise une méthode d’interpolation de 101 points pour calculer l’AP ainsi qu’une moyenne sur 10 seuils IoU. AP@[.5:.95] correspond à l’AP moyenne pour IoU comprise entre 0,5 et 0,95, avec un pas de 0,05. Le ML automatisé consigne l’ensemble des 12 métriques définies par la méthode COCO, y compris l’AP et l’AR (rappel moyen) à diverses échelles dans les journaux des applications, tandis que l’interface utilisateur des métriques affiche uniquement la mAP à un seuil IoU de 0,5.
Conseil
L’évaluation du modèle de détection d’objet image peut utiliser les métriques COCO si l’hyperparamètre validation_metric_type est défini sur « coco », comme expliqué dans la section sur l’optimisation des hyperparamètres.
Métriques au niveau de l’époque pour la détection d’objet et la segmentation d’instance
Les valeurs de mAP, de précision et de rappel sont journalisées au niveau de l’époque pour les modèles de détection d’objet image ou de segmentation d’instance. Les métriques de mAP, de précision et de rappel sont également journalisées au niveau de la classe avec le nom « per_label_metrics ». Le « per_label_metrics » doit être affiché sous la forme d’un tableau.
Notes
Les métriques au niveau de l’époque pour la précision, le rappel et per_label_metrics ne sont pas disponibles lorsque la méthode « COCO » est utilisée.
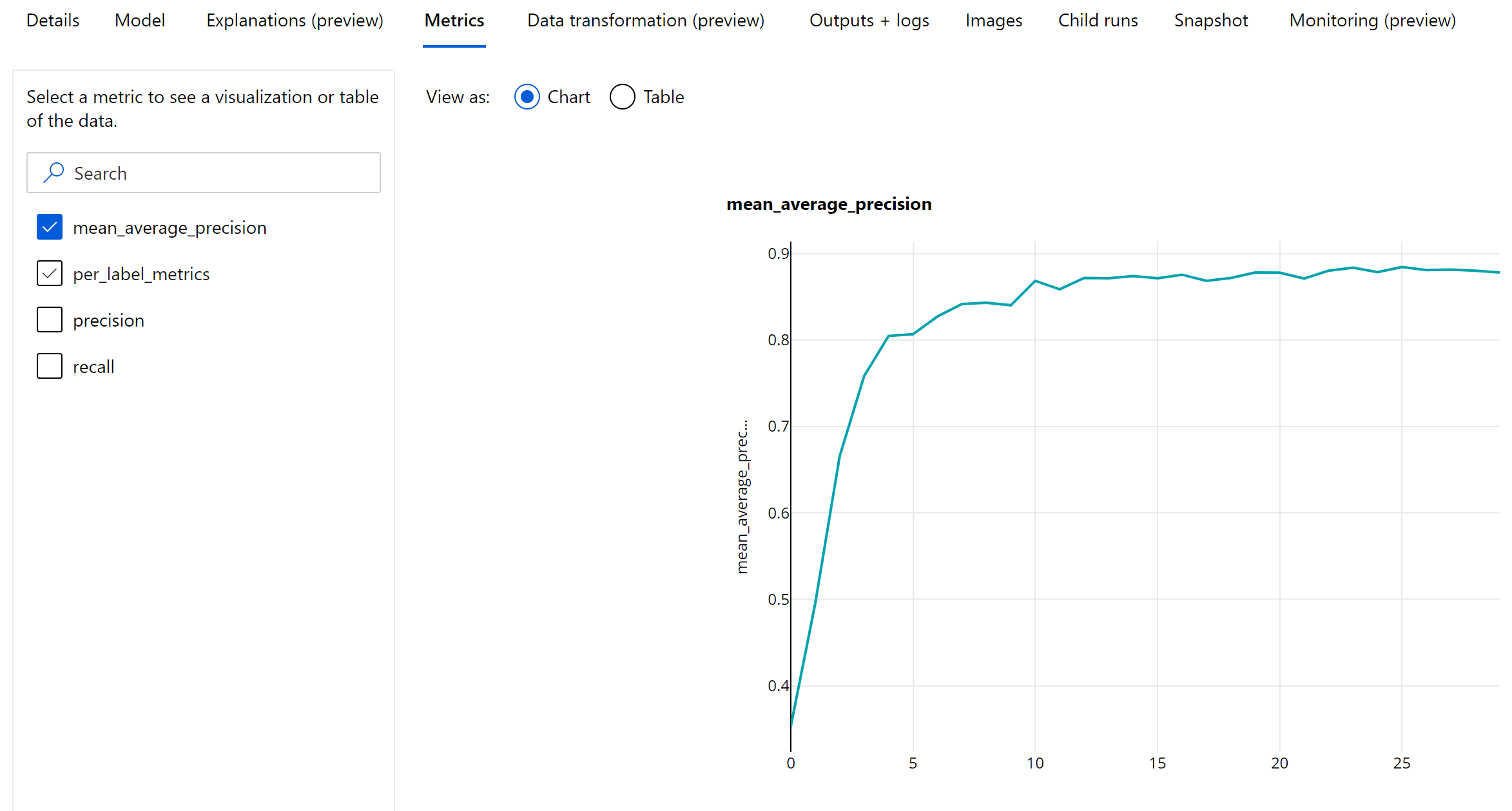
Tableau de bord d'IA responsable pour le meilleur modèle AutoML recommandé (aperçu)
Le tableau de bord de l'IA responsable d'Azure Machine Learning fournit une interface unique pour vous aider à mettre en œuvre l'IA responsable dans la pratique de manière efficace et efficiente. Le tableau de bord d'IA responsable est uniquement pris en charge à l'aide de données tabulaires et n'est pris en charge que sur les modèles de classification et de régression. Il réunit plusieurs outils d’IA responsable matures dans les domaines suivants :
- Performances des modèles et évaluation de l’impartialité
- Exploration des données
- Interprétabilité du machine learning
- Analyse des erreurs
Bien que les métriques et les graphiques d’évaluation du modèle soient bons pour mesurer la qualité générale d’un modèle, des opérations telles que l’inspection de l’équité du modèle, l’affichage de ses explications (également appelées jeux de données caractéristiques d’un modèle utilisé pour effectuer ses prédictions), l’inspection de ses erreurs et des zones aveugles potentielles sont essentielles lors de la pratique d’une IA responsable. C'est pourquoi le ML automatisé fournit un tableau de bord d’IA responsable pour vous aider à observer divers insights pour votre modèle. Découvrez comment afficher le tableau de bord de l'IA responsable dans le studio Azure Machine Learning.
Découvrez comment vous pouvez générer ce tableau de bord via l'interface utilisateur ou le SDK.
Explications des modèles et importance des fonctionnalités
Bien que les métriques et les graphiques d’évaluation des modèles conviennent parfaitement pour mesurer la qualité générale d’un modèle, il est essentiel d’inspecter les fonctionnalités du jeu de données qu’un modèle utilisé pour faire ses prédictions lorsque vous souhaitez mettre en place des pratiques IA responsables. C’est la raison pour laquelle ML automatisé fournit un tableau de bord d’explication des modèles permettant de mesurer et de signaler les contributions relatives des fonctionnalités du jeu de données. Découvrez comment afficher le tableau de bord d’explications dans Azure Machine Learning studio.
Notes
L’interprétabilité, c’est-à-dire la meilleure explication du modèle, n’est pas disponible pour les expériences de prévision de ML automatisé, qui recommandent les algorithmes suivants comme meilleur modèle ou ensemble :
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- Moyenne
- Naive
- Moyenne saisonnière
- Naive saisonnière
Étapes suivantes
- Testez les exemples de notebooks disponibles dans l’explication du modèle de Machine Learning automatisé.
- Pour les questions spécifiques à ML automatisé, contactez askautomatedml@microsoft.com.