LLMOps avec un flux d’invites et Azure DevOps
Les opérations de langage volumineuses, ou LLMOps, sont devenues la pierre angulaire de l’ingénierie rapide efficace et du développement et du déploiement d’applications infusés par LLM. À mesure que la demande d’applications LLM-infusées continue de s’augmenter, les organisations se trouvent en besoin d’un processus cohérent et rationalisé pour gérer leur cycle de vie de bout en bout.
Azure Machine Learning permet l’intégration à Azure DevOps pour automatiser le cycle de vie du développement d’applications infusées par LLM avec un flux d’invites.
Le flux d’invites Azure Machine Learning offre une approche simplifiée et structurée pour le développement d’applications infusées par LLM. Son processus et son cycle de vie bien définis vous guident tout au long du processus de création, de test, d’optimisation et de déploiement de flux, ce qui aboutit à la création de solutions infusées par LLM entièrement fonctionnelles.
Fonctionnalités du flux d’invite LLMOps
LLMOps avec flux rapide est un « modèle et conseils LLMOps » pour vous aider à créer des applications infusées LLM à l’aide du flux rapide. Elle fournit les fonctionnalités suivantes :
L’hébergement de code centralisé : ce référentiel prend en charge l’hébergement de code pour plusieurs flux en fonction du flux rapide, fournissant un référentiel unique pour tous vos flux. Considérez cette plateforme comme un référentiel unique où réside tout votre code de flux rapide. Il s’agit d’une bibliothèque pour vos flux, ce qui facilite la recherche, l’accès et la collaboration sur différents projets.
Gestion de cycle de vie : chaque flux bénéficie de son propre cycle de vie, ce qui permet une transition fluide de l’expérimentation locale au déploiement de production.
Expérimentation de variante et d’hyperparamètre : expérimentez avec plusieurs variantes et hyperparamètres, en évaluant facilement les variantes de flux. Les variantes et les hyperparamètres sont comme des ingrédients dans une recette. Cette plateforme vous permet d’expérimenter différentes combinaisons de variantes sur plusieurs nœuds dans un flux.
Plusieurs cibles de déploiement : le référentiel prend en charge le déploiement de flux vers Azure App Services, Kubernetes, les calculs managés Azure pilotés par la configuration, ce qui garantit que vos flux peuvent être mis à l’échelle selon les besoins. Il génère également des images Docker alimentées avec la session de calcul de flux et vos flux pour un déploiement sur n’importe quel système d’exploitation et plateforme cible prenant en charge Docker.

Déploiement A/B : implémentez en toute transparence des déploiements A/B, ce qui vous permet de comparer facilement différentes versions de flux. Tout comme dans les tests A/B traditionnels pour les sites web, cette plateforme facilite le déploiement A/B pour le flux rapide. Cela signifie que vous pouvez facilement comparer différentes versions d’un flux dans un paramètre réel pour déterminer les performances optimales.
Relations de jeu de données/flux plusieurs à plusieurs : prenez en charge plusieurs jeux de données pour chaque flux standard et d’évaluation, garantissant ainsi la polyvalence dans les tests de flux et l’évaluation. La plateforme est conçue pour prendre en charge plusieurs jeux de données pour chaque flux.
Inscription conditionnelle des données et des modèles : la plateforme crée une nouvelle version du jeu de données dans Azure Machine Learning Data Asset et les flux dans le registre de modèles uniquement lorsqu’une modification est apportée à ces données, et non dans le cas contraire.
Rapports complets : générez des rapports détaillés pour chaque configuration de variante, ce qui vous permet de prendre des décisions éclairées. Fournit une collection de métriques détaillée, des exécutions en bloc d’expérience et de variantes pour toutes les exécutions et expériences, ce qui permet de prendre des décisions pilotées par les données dans des fichiers CSV et HTML.







Autres fonctionnalités de personnalisation :
Offre BYOF (bring-your-own-flows / apportez vos propres flux). Une plateforme complète pour développer plusieurs cas d’usage liés aux applications infusées LLM.
Offre un développement basé sur la configuration. Il n’est pas nécessaire d’écrire un code complet.
Fournit l’exécution à la fois de l’expérimentation rapide et de l’évaluation localement, ainsi que sur le cloud.
Fournit des notebooks pour l’évaluation locale des invites. Fournit une bibliothèque de fonctions pour l’expérimentation locale.
Test de point de terminaison dans le pipeline après le déploiement pour vérifier sa disponibilité et sa préparation.
Fournit une boucle « human-in-loop » facultative pour valider les métriques d’invite avant le déploiement.
LLMOps avec flux rapide fournit des fonctionnalités pour les applications LLM simples et complexes infusées. Entièrement personnalisable selon les besoins de l’application.
Étapes de LLMOps
Le cycle de vie comprend quatre étapes distinctes :
Initialisation : définir clairement l’objectif métier, collecter des exemples de données pertinents, établir une structure d’invite de base et créer un flux qui améliore ses capacités.
Expérimentation : appliquer le flux à des exemples de données, évaluer les performances de l’invite et affiner le flux en fonction des besoins. Itérer de façon continue jusqu’à ce que les résultats soient satisfaisants.
Évaluation et affinage : établissez un point de référence des performances du flux en utilisant un jeu de données plus grand, évaluez l’efficacité de l’invite et effectuez les affinages nécessaires. Passer à l’étape suivante si les résultats répondent aux standards souhaités.
Déploiement : optimiser le flux en matière d’efficacité, le déployer dans un environnement de production, y compris le déploiement A/B, surveiller ses performances, recueillir des commentaires des utilisateurs et utiliser ces informations pour améliorer davantage le flux.
En adhérant à cette méthodologie structurée, les flux d’invites vous permettent de développer en confiance, de tester rigoureusement, d’optimiser et de déployer des flux, ce qui aboutit à la création d’applications d’IA robustes et sophistiquées.
Le modèle de flux d’invites LLMOps formalise cette méthodologie structurée en utilisant l’approche Code first, et vous aide à créer des applications infusées par LLM avec un flux d’invites en utilisant des outils et des processus pertinents pour le flux d’invite. Il offre une gamme de fonctionnalités, incluant l’hébergement de code centralisé, la gestion du cycle de vie, l’expérimentation des variantes et des hyperparamètres, le déploiement A/B, la création de rapports pour toutes les exécutions et les expériences, etc.
Le référentiel pour cet article est disponible sur LLMOps avec le modèle de flux d’invite
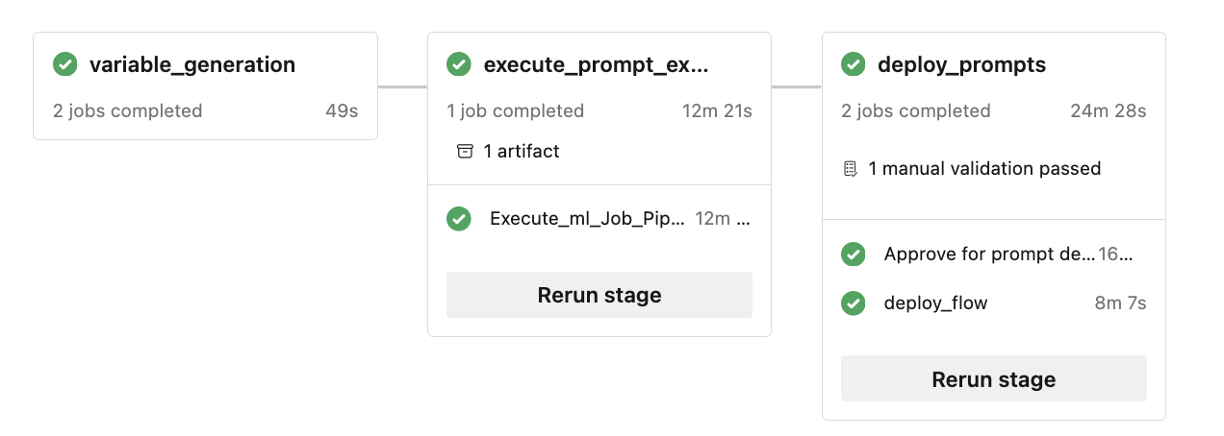
Flux de processus LLMOps

- Il s’agit de l’étape d’initialisation. Ici, les flux sont développés, les données sont préparées et organisées et les fichiers de configuration liés à LLMOps sont mis à jour.
- Après le développement local effectué en utilisant Visual Studio Code avec l’extension de flux d’invites, une demande de tirage est déclenchée de la branche de fonctionnalité à la branche de développement. Cela entraîne l’exécution du pipeline de validation de build. Elle exécute également les flux d’expérimentation.
- La demande de tirage est approuvée manuellement et le code est fusionné à la branche de développement
- Une fois la demande de tirage fusionnée à la branche de développement, le pipeline d’intégration continue pour l’environnement de développement est exécuté. Il exécute les flux d’expérimentation et d’évaluation en séquence et inscrit les flux dans Azure Machine Learning Registry en dehors des autres étapes du pipeline.
- Une fois l’exécution du pipeline d’intégration continue terminée, un déclencheur de déploiement continu garantit l’exécution du pipeline de déploiement continu qui déploie le flux standard à partir d’Azure Machine Learning Registry en tant que point de terminaison en ligne Azure Machine Learning et exécute des tests d’intégration et d’acceptation de build sur le flux déployé.
- Une branche de mise en production est créée à partir de la branche de développement ou une demande de tirage est déclenchée depuis la branche de développement vers la branche de mise en production.
- La demande de tirage est approuvée manuellement et le code est fusionné à la branche de mise en production. Une fois la demande de tirage fusionnée à la branche de mise en production, le pipeline d’intégration continue pour l’environnement prod est exécuté. Il exécute les flux d’expérimentation et d’évaluation en séquence et inscrit les flux dans Azure Machine Learning Registry en dehors des autres étapes du pipeline.
- Une fois l’exécution du pipeline CI terminée, un déclencheur CD assure l’exécution du pipeline CD qui déploie le flux standard depuis le registre Azure Machine Learning en tant que point de terminaison en ligne Azure Machine Learning, et exécute des tests d’intégration et de fumée sur le flux déployé.
Dans cet article, vous pouvez découvrir LLMOps avec des flux d’invites en suivant les exemples de bout en bout que nous avons fournis, ce qui vous aide à créer des applications infusées par LLM en utilisant des flux d’invites et Azure DevOps. Son objectif principal est de fournir de l’aide au développement de ces applications, en tirant parti des fonctionnalités du flux rapide et des LLMOps.
Conseil
Nous vous recommandons de comprendre comment intégrer les opérations des grands modèles de langage avec le flux d’invite.
Important
Le flux de l’invite est actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Prérequis
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
- Un espace de travail Azure Machine Learning.
- Git en cours d’exécution sur votre ordinateur local.
- Une organisation dans Azure DevOps. L’organisation dans Azure DevOps permet de collaborer, de planifier et de suivre votre travail, les défauts du code et les problèmes, et de configurer l’intégration et le déploiement continus.
- L’extension Terraform pour Azure DevOps si vous utilisez Azure DevOps + Terraform pour lancer l’infrastructure
Notes
Git version 2.27 ou ultérieure est obligatoire. Pour plus d’informations sur l’installation de la commande Git, consultez https://git-scm.com/downloads et sélectionnez votre système d’exploitation
Important
Les commandes CLI de cet article ont été testées à l’aide de Bash. Si vous utilisez un autre interpréteur de commandes, vous pouvez rencontrer des erreurs.
Configurer un flux d’invites
Le flux d’invite utilise une ressource de connexions pour se connecter à des points de terminaison comme Azure OpenAI, OpenAI ou Recherche Azure AI, tout en utilisant une session de calcul pour l’exécution des flux. Ces ressources doivent être créées avant d’exécuter les flux dans le flux d’invites.
Configurer des connexions pour le flux rapide
Les connexions peuvent être créées via l’interface utilisateur du portail du flux d’invite ou en utilisant l’API REST. Suivez les instructions pour créer des connexions pour le flux d’invite.
Cliquez sur le lien pour en savoir plus sur les connexions.
Remarque
Les exemples de flux utilisent la connexion « aoai » et la connexion nommée « aoai » doit être créée pour les exécuter.
Configurer un principal de service Azure
Un principal de service Azure est une identité de sécurité utilisée par les applications, les services et les outils d’automatisation pour accéder à des ressources Azure. Il représente une application ou un service qui doit s’authentifier auprès d’Azure et accéder aux ressources en votre nom. Suivez les instructions pour créer un principal de service dans Azure.
Ce principal de service est utilisé ultérieurement pour configurer la connexion du service Azure DevOps et Azure DevOps pour s’authentifier et se connecter aux services Azure. Les travaux exécutés dans le flux d’invites pour experiment and evaluation runs sont sous l’identité de ce principal de service.
Conseil
La configuration fournit des autorisations owner au principal de service.
- La raison en est que le pipeline CD fournit automatiquement l’accès au point de terminaison Azure Machine Learning nouvellement provisionné à l’espace de travail Azure Machine Learning pour lire les informations de connexion.
- Il l’ajoute également à la stratégie Key Vault associée à l’espace de travail Azure Machine Learning avec des autorisations de secret
getetlist.
L’autorisation de propriétaire peut être changée en autorisations de niveau contributor en modifiant le code YAML du pipeline et en supprimant l’étape liée aux autorisations.
Configurer Azure DevOps
Plusieurs étapes doivent être effectuées pour configurer le processus LLMOps en utilisant Azure DevOps.
Créer un projet Azure DevOps
Suivez les instructions pour créer un projet Azure DevOps en utilisant l’interface utilisateur Azure DevOps.
Configurer l’authentification entre Azure DevOps et Azure
Suivez les instructions pour utiliser le principal de service précédemment créé, et pour configurer l’authentification entre Azure DevOps et les services Azure.
Cette étape configure une nouvelle connexion du service Azure DevOps qui stocke les informations du principal de service. Les pipelines du projet peuvent lire les informations de connexion en utilisant le nom de la connexion. Ceci permet de configurer les étapes du pipeline Azure DevOps pour se connecter automatiquement à Azure.
Créer un groupe de variables Azure DevOps
Suivez les instructions pour créer un groupe de variables et ajouter une variable liée à la connexion du service Azure DevOps.
Le nom du principal de service est disponible automatiquement en tant que variable d’environnement pour les pipelines.
Configurer le dépôt et les pipelines Azure DevOps
Ce dépôt utilise deux branches : main et development pour les promotions du code et l’exécution des pipelines à la place des modifications qui y sont apportées au code. Suivez les instructions pour configurer votre propre dépôt local et le dépôt distant afin d’utiliser du code provenant de ce dépôt.
Les étapes impliquent le clonage des branches main et development (main and development branches) depuis le dépôt et l’association du code pour faire référence au nouveau dépôt Azure DevOps. Outre la migration de code, les pipelines – à la fois les pipelines PR et de développement – sont configurés de façon à ce qu’ils soient exécutés automatiquement en fonction de la création de demandes de tirage et des déclencheurs de fusion.
La stratégie de branche pour la branche de développement doit également être configurée pour exécuter le pipeline PR pour les demandes de tirage déclenchées sur une branche de développement à partir d’une branche de fonctionnalité. Le pipeline « dev » est exécuté quand la demande de tirage est fusionnée vers la branche de développement. Le pipeline « dev » est constitué des phases CI et CD.
Il existe également un opérateur humain dans la boucle, implémenté dans les pipelines. Après l’exécution de la phase CI dans le pipeline dev, la phase CD suit, après une approbation manuelle. L’approbation doit se produire depuis l’interface utilisateur d’exécution de la build du pipeline Azure DevOps. Le délai d’expiration par défaut est de 60 minutes, après quoi le pipeline est rejeté et la phase CD ne s’exécute pas. L’approbation manuelle de l’exécution entraîne l’exécution des étapes CD du pipeline. L’approbation manuelle est configurée pour envoyer des notifications à « replace@youremail.com ». Il doit être remplacé par un ID de messagerie approprié.
Tester les pipelines
Suivez les instructions mentionnées pour tester les pipelines.
Les étapes à suivre sont les suivantes :
- Déclenchez une demande de tirage (pull request) depuis une branche de fonctionnalité vers la branche de développement.
- Le pipeline de demande de tirage doit s’exécuter automatiquement à la suite de la configuration de la stratégie de branche.
- La demande de tirage est ensuite fusionnée à la branche de développement.
- Le pipeline « dev » associé est exécuté. Cela entraîne l’exécution d’intégration continue et de déploiement continu complète et entraîne l’approvisionnement ou la mise à jour des points de terminaison Azure Machine Learning existants.
Les résultats des tests doivent être similaires à ceux présentés ici.
Exécution locale
Pour exploiter les fonctionnalités de l’exécution locale, effectuez les étapes d’installation suivantes :
- Cloner le référentiel : commencez par cloner le référentiel du modèle depuis son référentiel GitHub.
git clone https://github.com/microsoft/llmops-promptflow-template.git
- Configurer le fichier env : créez un fichier .env au niveau du dossier le plus haut et fournissez les informations pour les éléments mentionnés. Ajoutez autant de noms de connexion que nécessaire. Tous les exemples de flux de ce référentiel utilisent la connexion AzureOpenAI nommée
aoai. Ajoutez une ligneaoai={"api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}avec des valeurs mises à jour pour api_key et api_base. Si des connexions supplémentaires avec différents noms sont utilisées dans vos flux, elles doivent être ajoutées en conséquence. Actuellement, un flux avec AzureOpenAI comme fournisseur est pris en charge.
experiment_name=
connection_name_1={ "api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}
connection_name_2={ "api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}
- Préparez l’environnement local conda ou virtuel pour installer les dépendances.
python -m pip install promptflow promptflow-tools promptflow-sdk jinja2 promptflow[azure] openai promptflow-sdk[builtins] python-dotenv
Apportez ou écrivez vos flux dans le modèle en fonction de la documentation accessible ici.
Écrivez des scripts Python similaires aux exemples fournis dans le dossier local_execution.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour