Gérer une session de calcul de flux d’invite dans Azure Machine Learning studio
Une session de calcul de flux d’invite fournit les ressources informatiques requis pour l’exécution de l’application, y compris une image Docker qui contient tous les packages de dépendances nécessaires. Cet environnement fiable et scalable permet au flux d’invite d’exécuter efficacement ses tâches et ses fonctions, ce qui garantit une expérience utilisateur fluide.
Autorisations et rôles pour la gestion d’une session de calcul
Pour attribuer des rôles, vous devez disposer des autorisations owner ou Microsoft.Authorization/roleAssignments/write sur la ressource.
Pour les utilisateurs de la session de calcul, attribuez le rôle AzureML Data Scientist dans l’espace de travail. Pour en savoir plus, consultez Gérer l’accès à un espace de travail Azure Machine Learning.
Plusieurs minutes peuvent s’écouler avant que l’attribution de rôle prenne effet.
Démarrer une session de calcul dans Studio
Avant d’utiliser Azure Machine Learning studio pour démarrer une session de calcul, vérifiez que :
- Vous avez le rôle
AzureML Data Scientistdans l’espace de travail. - Le magasin de données par défaut (généralement
workspaceblobstore) dans votre espace de travail est de type blob. - Le répertoire de travail (
workspaceworkingdirectory) existe dans l’espace de travail. - Si vous utilisez un réseau virtuel pour le flux d’invite, vous comprenez bien les considérations exposées dans Isolation réseau dans les flux d’invite.
Démarrer une session de calcul sur une page de flux
Un flux est lié à une session de calcul. Vous pouvez démarrer une session de calcul sur une page de flux.
Cliquez sur Démarrer. Démarrez une session de calcul à l’aide de l’environnement défini dans
flow.dag.yamldans le dossier de flux. Elle s’exécute sur la taille de machine virtuelle de calcul serverless où vous avez suffisamment de quota dans l’espace de travail.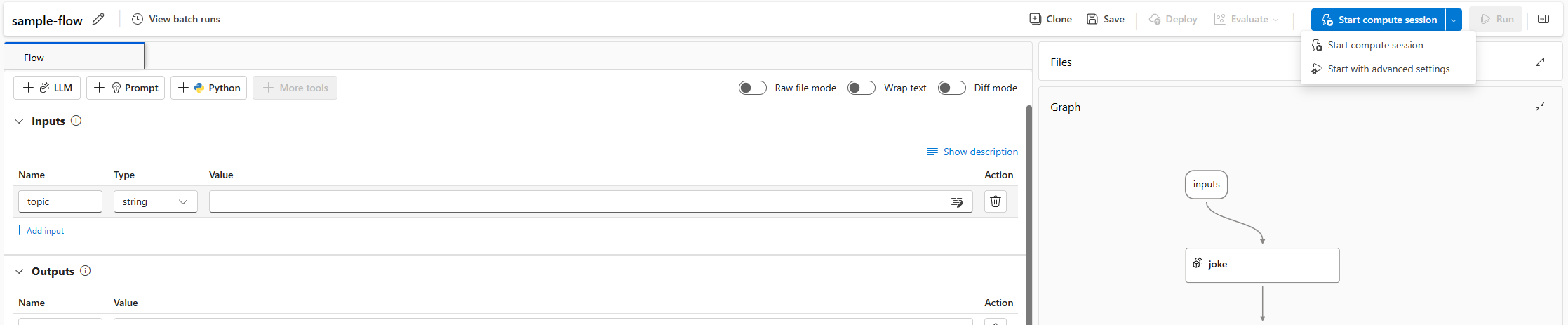
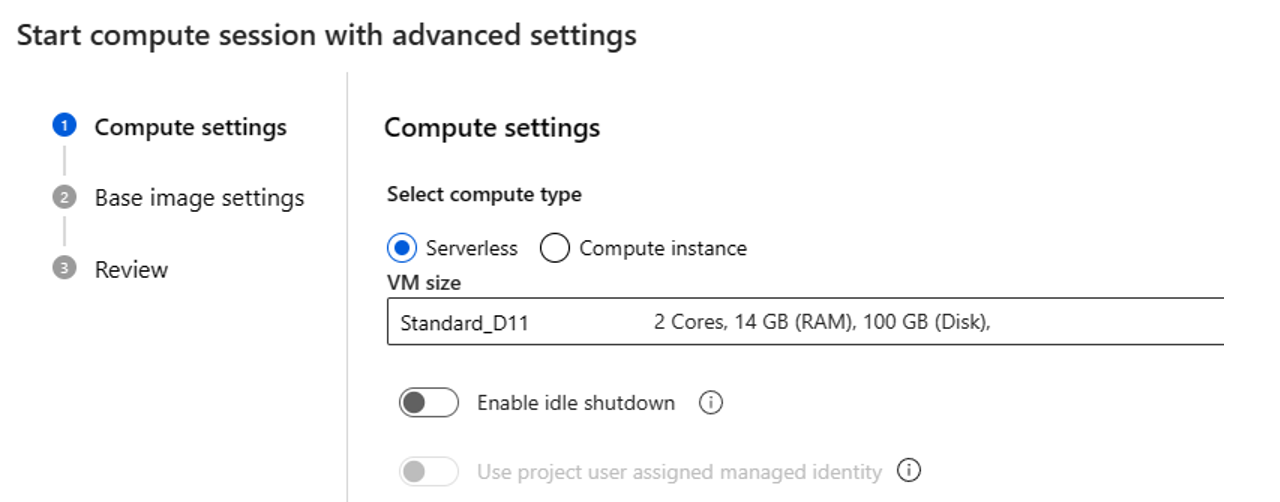
Sélectionnez Commencer avec des paramètres avancés. Dans les paramètres avancés, vous pouvez :
- Sélectionnez le type de calcul. Vous pouvez choisir entre le calcul serverless et l’instance de calcul.
Si vous choisissez le calcul serverless, vous pouvez définir les paramètres suivants :
- Personnalisez la taille de machine virtuelle utilisée par la session de calcul. Choisissez la série de machines virtuelles D ou une série supérieure. Pour plus d’informations, consultez la section Séries et tailles de machines virtuelles prises en charge.
- Personnalisez le temps d’inactivité, ce qui supprime automatiquement la session de calcul si elle n’est pas utilisée.
- Définir l’identité managée affectée par l’utilisateur. La session de calcul utilise cette identité pour extraire une image de base, effectuer une authentification avec connexion et installer des packages. Vérifiez que l’identité managée affectée par l’utilisateur dispose des autorisations suffisantes. Si vous ne définissez pas cette identité, nous utilisons l’identité de l’utilisateur par défaut.
- Vous pouvez utiliser la commande CLI suivante pour attribuer une identité managée affectée par l’utilisateur à l’espace de travail. En savoir plus sur la création et la mise à jour des identités affectées par l’utilisateur pour un espace de travail.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Où le contenu de workspace_update_with_multiple_UAIs.yml est le suivant :
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Conseil
Les attributions de rôles RBAC Azure suivantes sont requises sur votre identité managée affectée par l’utilisateur pour que votre espace de travail Azure Machine Learning accède aux données sur les ressources associées à l’espace de travail.
Ressource Autorisation Espace de travail Azure Machine Learning Contributeur Stockage Azure Contributeur (plan de contrôle) + Contributeur aux données blob de stockage + Contributeur privilégié aux données du fichier de stockage (plan de données, consommer le brouillon de flux dans le partage de fichiers et les données dans l’objet blob) Azure Key Vault (lors de l’utilisation du modèle d’autorisation des stratégies d’accès) Contributeur + toutes les autorisations de stratégie d’accès en plus des opérations de vidage (mode par défaut pour le coffre de clés Azure lié). Azure Key Vault (lors de l’utilisation du modèle d’autorisation RBAC) Contributeur (plan de contrôle) + administrateur Key Vault (plan de données) Azure Container Registry Contributeur Azure Application Insights Contributeur Remarque
L’émetteur de travaux doit disposer d’autorisations
assignsur l’identité managée affectée par l’utilisateur. Vous pouvez attribuer un rôleManaged Identity Operator, car chaque fois que vous créez une session de calcul serverless, il affecte l’identité managée affectée par l’utilisateur au calcul.Si vous choisissez une instance de calcul comme type de calcul, vous ne pouvez définir que le temps d’arrêt inactif.
Comme il s’exécute sur une instance de calcul existante, la taille de machine virtuelle est fixe et ne peut pas changer côté session.
L’identité utilisée pour cette session est également définie dans l’instance de calcul ; par défaut, elle utilise l’identité de l’utilisateur. En savoir plus sur l’affectation d’identité à l’instance de calcul
Pour le temps d’arrêt inactif, cela permet de définir le cycle de vie de la session de calcul. Si la session est inactive pour le temps que vous définissez, elle est supprimée automatiquement. Et si vous avez activé l’arrêt inactif sur l’instance de calcul, il prend effet au niveau du calcul.

En savoir plus sur la création et la gestion d’une instance de calcul.
- Sélectionnez le type de calcul. Vous pouvez choisir entre le calcul serverless et l’instance de calcul.



Utiliser une session de calcul pour envoyer une exécution de flux dans une CLI ou un SDK
Outre Studio, vous pouvez spécifier la session de calcul dans la CLI ou le SDK lorsque vous transmettez une exécution de flux.
Vous pouvez également spécifier le type d’instance ou le nom de l’instance de calcul sous la partie ressource. Si vous ne spécifiez pas le type d’instance ou le nom de l’instance de calcul, Azure Machine Learning choisit un type d’instance (taille de machine virtuelle) en fonction de facteurs tels que le quota, le coût, les performances et la taille du disque. En savoir plus sur calcul serverless.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Envoyez cette exécution via la CLI :
pfazure run create --file run.yml
Remarque
L’arrêt inactif est d’une heure si vous utilisez CLI/SDK pour envoyer une exécution de flux. Vous pouvez accéder à la page de calcul pour publier le calcul.
Fichiers de référence situés en dehors du dossier de flux
Dans certains cas, vous pourriez avoir besoin de référencer un fichier requirements.txt situé en dehors du dossier de flux. Par exemple, votre projet peut être complexe et inclure plusieurs flux, qui partagent le même fichier requirements.txt. Pour ce faire, vous pouvez ajouter le champ additional_includes dans le fichier flow.dag.yaml. La valeur de ce champ correspond à une liste des chemins d’accès de fichier/dossier relatifs au dossier de flux. Par exemple, si le fichier requirements.txt se trouve dans le dossier parent du dossier de flux, vous pouvez ajouter ../requirements.txt au champ additional_includes.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
Le fichier requirements.txt est copié dans le dossier de flux. Utilisez-le pour démarrer votre session de calcul.
Mettre à jour une session de calcul sur la page de flux studio
Sur une page de flux, vous pouvez utiliser les options suivantes pour gérer une session de calcul :
- Modifier les paramètres de la session de calcul : vous modifiez les paramètres de calcul tels que la taille de machine virtuelle et l’identité managée affectée par l’utilisateur pour le calcul serverless. Si vous utilisez une instance de calcul, vous pouvez choisir d’utiliser une autre instance. Vous pouvez également modifier
- modifier l’identité managée affectée par l’utilisateur pour le calcul serverless. Si vous modifiez la taille de machine virtuelle, la session de calcul est réinitialisée avec la nouvelle taille de machine virtuelle. Si vous…
- Installer des packages à partir de requirements.txt : ouvrez
requirements.txtdans l’interface utilisateur du flux d’invite pour y ajouter des packages. - Afficher les packages installés : affiche les packages installés dans la session de calcul. Il s’agit notamment des packages installés dans l’image de base et les packages spécifiés dans le fichier
requirements.txtdu dossier de flux. - Réinitialiser la session de calcul : supprime la session de calcul actuelle et en crée une avec le même environnement. Si vous rencontrez un problème de conflit de packages, vous pouvez essayer cette option.
- Arrêter la session de calcul : supprime la session de calcul actuelle. S’il n’y a aucune session de calcul active sur le calcul sous-jacent, la ressource de calcul serverless est également supprimée.

Vous pouvez également personnaliser l’environnement que vous utilisez pour exécuter ce flux en ajoutant des packages dans le fichier requirements.txt du dossier de flux. Après avoir ajouté d’autres packages dans ce fichier, vous pouvez choisir une de ces options :
- Enregistrer et installer déclenche
pip install -r requirements.txtdans le dossier de flux. Ce processus peut prendre quelques minutes, en fonction des packages que vous installez. - Enregistrer uniquement enregistre simplement le fichier
requirements.txt. Vous pouvez installer les packages ultérieurement vous-même.

Remarque
Vous pouvez changer l’emplacement et même le nom de fichier de requirements.txt, mais veillez dans ce cas à le changer aussi dans le fichier flow.dag.yaml dans le dossier de flux.
N’épinglez pas la version de promptflow et de promptflow-tools dans requirements.txt, car nous les incluons déjà dans l’image de base de la session.
requirements.txt ne prend pas en charge les fichiers wheel locaux. Générez-les dans votre image et mettez à jour l’image de base personnalisée dans flow.dag.yaml. En savoir plus sur la création d’une image de base personnalisée.
Ajouter des packages dans un flux privé dans Azure DevOps
Si vous souhaitez utiliser un flux privé dans Azure DevOps, effectuez les étapes suivantes :
Attribuez une identité managée à l’espace de travail ou à l’instance de calcul.
Utilisez le calcul serverless comme session de calcul. Vous devez attribuer une identité managée affectée par l’utilisateur à l’espace de travail.
Créez une identité managée affectée par l’utilisateur et ajoutez-la dans l’organisation Azure DevOps. Pour plus d’informations, consultez Utiliser des principaux de service et des identités managées.
Remarque
Si le bouton Ajouter des utilisateurs n’est pas visible, il est probable que vous n’avez pas les autorisations nécessaires pour effectuer cette action.
Ajouter ou mettre à jour des identités affectées par l’utilisateur dans un espace de travail.
Remarque
Vérifiez que l’identité managée affectée par l’utilisateur a
Microsoft.KeyVault/vaults/readsur le coffre de clés lié à l’espace de travail.
Utilisez l’instance de calcul comme session de calcul. Vous devez attribuer une identité managée affectée par l’utilisateur à une instance de calcul.
Ajoutez
{private}à l’URL de votre flux privé. Par exemple, si vous voulez installertest_packagedepuistest_feeddans Azure DevOps, ajoutez-i https://{private}@{test_feed_url_in_azure_devops}dansrequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageSpécifiez l’utilisation de l’identité managée affectée par l’utilisateur dans la configuration de la session de calcul.
Si vous utilisez un calcul serverless, spécifiez l’identité managée attribuée par l’utilisateur dans Démarrer avec les paramètres avancés si la session de calcul n’est pas en cours d’exécution, ou utilisez le bouton Modifier les paramètres de la session de calcul si la session de calcul est en cours d’exécution.

Si vous utilisez une instance de calcul, elle utilise l’identité managée affectée par l’utilisateur que vous avez attribuée à l’instance de calcul.

Remarque
Cette approche se concentre principalement sur les tests rapides dans la phase de développement de flux, si vous souhaitez également déployer ce flux en tant que point de terminaison, créez ce flux privé dans votre image et mettez à jour personnaliser l’image de base dans flow.dag.yaml. En savoir plus comment créer des images de base personnalisées
Modifier l’image de base pour la session de calcul
Par défaut, nous utilisons la dernière image de base du flux d’invite. Si vous souhaitez utiliser une autre image de base, vous pouvez créer une image personnalisée.
- Dans Studio, vous pouvez modifier l’image de base dans les paramètres d’image de base sous les paramètres de la session de calcul.

Vous pouvez également spécifier la nouvelle image de base sous
environmentdans le fichierflow.dag.yamldans le dossier de flux.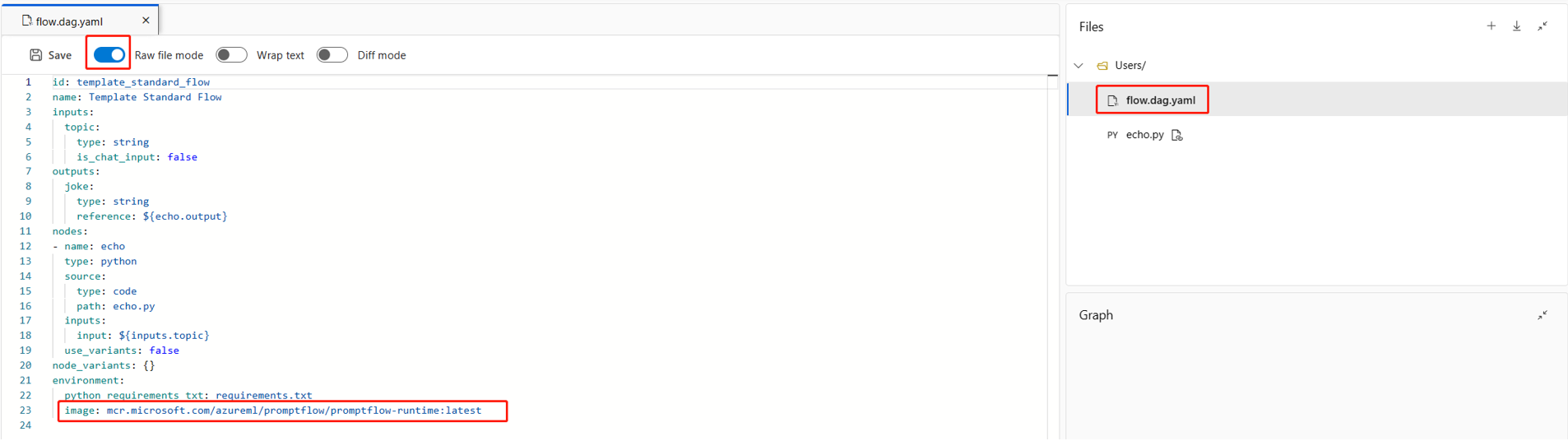
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Pour utiliser la nouvelle image de base, vous devez réinitialiser la session de calcul. Ce processus prend plusieurs minutes, car il extrait la nouvelle image de base et réinstalle les packages.
Gérer l’instance serverless utilisée par la session de calcul
Lorsque vous utilisez le calcul serverless comme session de calcul, vous pouvez gérer l’instance serverless. Affichez l’instance serverless dans l’onglet de liste des sessions de calcul sur la page de calcul.

Vous pouvez également accéder aux flux et aux exécutions s’exécutant sur le calcul dans l’onglet Flux et exécutions actifs. La suppression de l’instance a un impact sur le flux et les exécutions correspondants.

Relation entre la session de calcul, la ressource de calcul, le flux et l’utilisateur
- Un seul utilisateur peut accéder à plusieurs ressources de calcul (serverless ou instance de calcul). En raison de différents besoins, un seul utilisateur peut avoir plusieurs ressources de calcul. Par exemple, un utilisateur peut accéder à plusieurs ressources de calcul avec une taille de machine virtuelle différente ou une identité managée affectée par l’utilisateur différente.
- Une ressource de calcul ne peut être utilisée que par un seul utilisateur. Une ressource de calcul est utilisée comme espace de développement privé d’un seul utilisateur. Plusieurs utilisateurs ne peuvent pas partager les mêmes ressources de calcul.
- Une ressource de calcul peut héberger plusieurs sessions de calcul. Une session de calcul est un conteneur s’exécutant sur une ressource de calcul sous-jacente. Par exemple, la création de flux d’invite n’exige pas trop de ressources de calcul. Par conséquent, une ressource de calcul unique peut héberger plusieurs sessions de calcul à partir du même utilisateur.
- Une session de calcul appartient uniquement à une seule ressource de calcul à la fois. Vous pouvez toutefois la supprimer ou l’arrêter, et la réallouer à d’autres ressources de calcul.
- Un flux ne peut avoir qu’une seule session de calcul. Chaque flux est autonome et définit l’image de base et les packages Python requis dans le dossier de flux de la session de calcul.
Basculer le runtime vers la session de calcul
Les sessions de calcul présentent les avantages suivants par rapport aux runtimes d’instance de calcul :
- Gérez automatiquement le cycle de vie de la session et du calcul sous-jacent. Plus besoin de les créer manuellement et de les gérer.
- Personnalisez facilement les packages en ajoutant des packages dans le fichier
requirements.txtdans le dossier de flux, plutôt que de créer un environnement personnalisé.
Basculez un runtime d’instance de calcul vers une session de calcul en procédant comme suit :
- Préparez votre fichier
requirements.txtdans le dossier de flux. Assurez-vous de ne pas épingler la version depromptflowet depromptflow-toolsdansrequirements.txt, car nous les incluons déjà dans l’image de base. La session de calcul installe les packages dans le fichierrequirements.txtau démarrage. - Si vous créez un environnement personnalisé pour créer un runtime d’instance de calcul, vous pouvez obtenir l’image à partir de la page de détails de l’environnement et la spécifier dans le fichier
flow.dag.yamldu dossier de flux. Pour en savoir plus, consultez la section Modifier l’image de base pour la session de calcul. Vérifiez que vous ou l’identité managée affectée par l’utilisateur associée sur l’espace de travail dispose de l’autorisationacr pullpour l’image.

- Pour la ressource de calcul, vous pouvez continuer à utiliser l’instance de calcul existante si vous souhaitez gérer manuellement le cycle de vie ou essayer le calcul serverless dont le cycle de vie est géré par le système.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour