Paramétrer les invites à l’aide de variantes
Créer une bonne invite est une tâche difficile qui nécessite beaucoup de créativité, de clarté et de pertinence. Une bonne invite peut procurer le résultat attendu à partir d’un modèle de langage pré-entraîné, tandis qu’une mauvaise invite peut entraîner des résultats inexacts, non pertinents ou aberrants. Par conséquent, il est nécessaire de paramétrer les invites pour optimiser leurs performances et leur robustesse pour différents domaines et différentes tâches.
Ainsi, nous présentons le concept de variantes qui peut vous aider à tester le comportement du modèle dans différentes conditions, incluant la formulation, la mise en forme, le contexte, la température ou le top-k, à comparer et à trouver la meilleure invite et la meilleure configuration pour optimiser la précision, la diversité ou la cohérence du modèle.
Dans cet article, nous allons vous montrer comment utiliser des variantes pour paramétrer les invites et évaluer les performances des différentes variantes.
Prérequis
Avant de lire cet article, il est préférable d’étudier :
Comment paramétrer les invites à l’aide de variantes ?
Dans cet article, nous utiliserons l’exemple de flux de classification web.
Ouvrez l’exemple de flux et supprimez le nœud prepare_examples comme point de départ.

Utilisez l’invite suivante comme invite de référence dans le nœud classify_with_llm.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Plusieurs façons d’optimiser ce flux existent, et voici deux directions :
Pour le nœud classify_with_llm : j’ai appris de la communauté et des publications qu’une température plus basse donne une meilleure précision, mais moins de créativité et de surprise, de sorte qu’une température inférieure conviendra aux tâches de classification et que les invites à quelques exemples pourront augmenter les performances du LLM. J’aimerais donc tester le comportement de mon flux lorsque la température passe de 1 à 0, et quand l’invite s’applique à quelques exemples.
Pour le nœud summarize_text_content : je souhaite également tester le comportement de mon flux lorsque je passe de résumé de 100 mots à 300, pour voir si plus de contenu texte peut aider à améliorer les performances.
Créer des variantes
- Sélectionnez le bouton Afficher les variantes en haut à droite du nœud LLM. Le nœud LLM existant est variant_0 et est la variante par défaut.
- Définissez le bouton Cloner sur variant_0 pour générer variant_1, puis vous pouvez configurer les paramètres sur différentes valeurs ou mettre à jour l’invite sur variant_1.
- Répéter l’étape pour créer plus de variantes.
- Sélectionnez Masquer les variantes pour arrêter d’ajouter d’autres variantes. Toutes les variantes sont pliées. La variante par défaut s’affiche pour le nœud.
Pour le nœud classify_with_llm, en fonction de variant_0 :
- Créez variant_1 où la température passe de 1 à 0.
- Créez variant_2 où la température est de 0. Vous pouvez utiliser l’invite suivante, incluant des exemples en quelques coups.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
Pour le nœud summarize_text_content, en fonction de variant_0, vous pouvez créer variant_1 où 100 words mots sont remplacés par 300 mots dans l’invite.
À présent, le flux se présente comme suit : 2 variantes pour le nœud summarize_text_content et 3 pour le nœud classify_with_llm.

Exécuter toutes les variantes avec une seule ligne de données et vérifier les résultats
Pour vous assurer que toutes les variantes peuvent s’exécuter correctement et fonctionner comme attendu, vous pouvez exécuter le flux avec une seule ligne de données à tester.
Notes
À chaque fois, vous ne pouvez sélectionner qu’un seul nœud LLM avec des variantes à exécuter, tandis que les autres nœuds LLM utiliseront la variante par défaut.
Dans cet exemple, nous configurons des variantes pour le nœud summarize_text_content et le nœud classify_with_llm. Vous devez donc exécuter deux fois pour tester toutes les variantes.
- Sélectionnez le bouton Exécuter dans le coin supérieur droit.
- Sélectionnez un nœud LLM avec des variantes. Les autres nœuds LLM utiliseront la variante par défaut.

- Envoyez l’exécution de flux.
- Une fois l’exécution de flux terminée, vous pouvez vérifier le résultat correspondant pour chaque variante.
- Soumettez une autre exécution de flux avec l’autre nœud LLM comportant les variantes et vérifiez les résultats.
- Vous pouvez modifier d’autres données d’entrée (par exemple, utiliser l’URL d’une page Wikipédia) et répéter les étapes ci-dessus pour tester des variantes pour différentes données.

Évaluer les variantes
Lorsque vous exécutez les variantes avec quelques éléments de données uniques et que vous vérifiez les résultats à l’œil nu, la complexité et la diversité des données réelles ne peut pas être reflétée. Le résultat n’étant dans le même temps pas mesurable, il est difficile de comparer l’efficacité des différentes variantes, puis de choisir la meilleure.
Vous pouvez soumettre une exécution par lot, qui vous permet de tester les variantes avec une grande quantité de données et de les évaluer avec des métriques, pour vous aider à trouver le meilleur ajustement.
Vous devez tout d’abord préparer un jeu de données suffisamment représentatif du problème réel que vous souhaitez résoudre avec le flux rapide. Dans cet exemple, il s’agit d’une liste d’URL et de leur classification effective. Nous allons utiliser la précision pour évaluer les performances des variantes.
Sélectionnez Évaluer en haut à droite de la page.
Un Assistant pour Exécuter et évaluer par lot s’ouvre. La première étape consiste à sélectionner un nœud pour exécuter toutes ses variantes.
Pour tester le fonctionnement des différentes variantes pour chaque nœud d’un flux, vous devez exécuter une exécution par lot pour chaque nœud avec des variantes un par un. Cela vous permet d’éviter l’influence des variantes d’autres nœuds et de vous concentrer sur les résultats des variantes de ce nœud. Cela suit la règle de l’expérience contrôlée, qui signifie que vous ne changez qu’une seule chose à la fois et conservez tout le reste identique.
Par exemple, vous pouvez sélectionner le nœud classify_with_llm pour exécuter toutes les variantes. Le nœud summarize_text_content utilise sa variante par défaut pour cette exécution par lot.
Ensuite, dans Paramètres d’exécution par lot, vous pouvez définir le nom de l’exécution par lot, choisir un runtime et charger les données préparées.
Ensuite, dans Paramètres d’évaluation, sélectionnez une méthode d’évaluation.
Ce flux étant destiné à la classification, vous pouvez sélectionner la méthode Évaluation de la précision de la classification pour évaluer la précision.
La précision est calculée en comparant les étiquettes prédites affectées par le flux (prédiction) aux étiquettes réelles des données (vérité terrain) et en comptant le nombre d’étiquettes qui correspondent.
Dans la section Mappage des entrées d’évaluation, vous devez spécifier que la vérité terrain provient de la colonne de catégorie du jeu de données d’entrée, et la prédiction provient de l’une des sorties du flux : catégorie.
Après avoir vérifié tous les paramètres, vous pouvez soumettre l’exécution par lot.
Une fois l’exécution envoyée, sélectionner le lien, puis accéder à la page des détails de l’exécution.
Notes
L’exécution peut durer plusieurs minutes.
Visualiser les sorties
- Une fois l’exécution par lot et l’exécution de l’évaluation terminées, dans la page des détails de l’exécution, sélectionnez les exécutions par lot pour chaque variante, puis sélectionnez Visualiser les sorties. Les métriques de 3 variantes pour le nœud classify_with_llm et les sorties prédites par le LLM pour chaque enregistrement de données s’affichent.
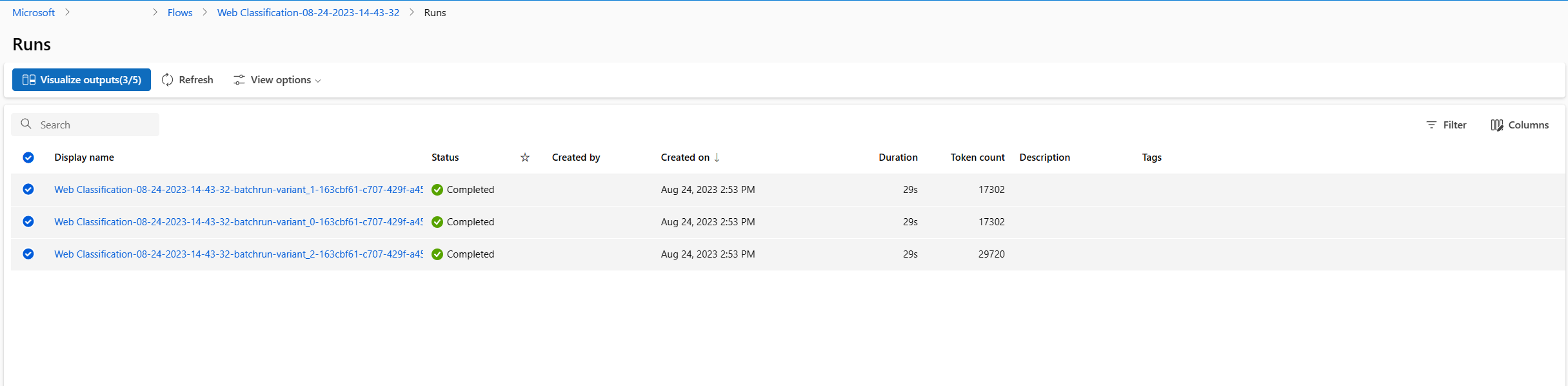
- Une fois que vous avez identifié la meilleure variante, vous pouvez revenir à la page de création de flux et définir cette variante comme variante par défaut du nœud
- Vous pouvez aussi répéter les étapes ci-dessus pour évaluer les variantes du nœud summarize_text_content.
Vous avez maintenant terminé le processus de paramétrage des invites à l’aide de variantes. Vous pouvez appliquer cette technique à votre propre flux rapide pour trouver la meilleure variante pour le nœud LLM.