Hachage des caractéristiques
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning.
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Convertit les données texte en fonctions codées sous forme d'entiers à l'aide de la bibliothèque Vowpal Wabbit.
Catégorie : Analyse de texte
Notes
S’applique à : Machine Learning Studio (classique) uniquement
Des modules par glisser-déposer similaires sont disponibles dans Concepteur Azure Machine Learning.
Vue d’ensemble du module
Cet article explique comment utiliser le module de hachage des fonctionnalités dans Machine Learning Studio (classique), pour transformer un flux de texte anglais en un ensemble de fonctionnalités représentées sous forme d’entiers. Vous pouvez ensuite passer ce jeu de fonctionnalités hachées à un algorithme Machine Learning pour entraîner un modèle d’analyse de texte.
La fonctionnalité de hachage des fonctionnalités fournie dans ce module est basée sur l’infrastructure Vowpal Wabbit. Pour plus d’informations, consultez Train Vowpal Wabbit 7-4 Model ou Train Vowpal Wabbit 7-10 Model.
En savoir plus sur le hachage des fonctionnalités
Le hachage des caractéristiques fonctionne en convertissant des jetons uniques en entiers. Il opère sur les chaînes exactes que vous fournissez en tant qu’entrée et n’effectue aucune analyse linguistique ni prétraitement.
Par exemple, prenez un ensemble de phrases simples en anglais comme celles-ci, suivies d’un score de sentiment. Supposons que vous voulez utiliser ce texte pour générer un modèle.
| TEXTE UTILISATEUR | SENTIMENT |
|---|---|
| I loved this book | 3 |
| I hated this book | 1 |
| This book was great | 3 |
| I love books | 2 |
En interne, le module Feature Hashing crée un dictionnaire de n-grammes. Par exemple, la liste des digrammes pour ce jeu de données ressemblerait à la suivante :
| TERME (digrammes) | FRÉQUENCE |
|---|---|
| This book | 3 |
| I loved | 1 |
| I hated | 1 |
| I love | 1 |
Vous pouvez contrôler la taille des n-grammes à l’aide de la propriété N-grammes. Si vous choisissez les digrammes, les unigrammes sont également calculés. Ainsi, le dictionnaire inclurait également des termes uniques comme ceux-ci :
| Terme (unigrammes) | FRÉQUENCE |
|---|---|
| book | 3 |
| I | 3 |
| books | 1 |
| was | 1 |
Une fois le dictionnaire créé, le module de hachage de fonctionnalité convertit les termes du dictionnaire en valeurs de hachage et calcule si une fonctionnalité a été utilisée dans chaque cas. Pour chaque ligne de données texte, le module génère un ensemble de colonnes, une colonne pour chaque caractéristique hachée.
Par exemple, après le hachage, les colonnes de caractéristiques peuvent ressembler à ceci :
| Rating | Caractéristique de hachage 1 | Caractéristique de hachage 2 | Caractéristique de hachage 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Si la valeur de la colonne est 0, la ligne ne contient pas la fonctionnalité hachée.
- Si la valeur est 1, la ligne contient effectivement la caractéristique.
L’avantage de l’utilisation du hachage de caractéristiques est que vous pouvez représenter des documents texte de longueur variable en tant que vecteurs de caractéristique numérique de longueur égale et obtenir une réduction de la dimensionnalité. En revanche, si vous avez essayé d’utiliser la colonne de texte pour l’apprentissage tel qu’il est, il serait traité comme une colonne de caractéristique catégorielle, avec de nombreuses valeurs distinctes.
Le fait d'avoir des sorties numériques rend également possible l'utilisation de nombreuses méthodes d'apprentissage différentes avec les données, notamment la classification, le regroupement ou l'extraction d'informations. Étant donné que les opérations de recherche peuvent utiliser des hachages d’entiers plutôt que des comparaisons de chaînes, l’obtention des poids des caractéristiques est également beaucoup plus rapide.
Guide pratique pour configurer le hachage des fonctionnalités
Ajoutez le module de hachage des fonctionnalités à votre expérience dans Studio (classique).
Connectez le jeu de données qui contient le texte à analyser.
Conseil
Étant donné que le hachage des caractéristiques n’effectue pas d’opérations lexicales comme la recherche de radical ou la troncation, vous pouvez parfois obtenir de meilleurs résultats en effectuant un prétraitement du texte avant d’appliquer le hachage des caractéristiques. Pour obtenir des suggestions, consultez les sections Bonnes pratiques et notes techniques .
Pour les colonnes cibles, sélectionnez les colonnes de texte que vous souhaitez convertir en fonctionnalités hachées.
Les colonnes doivent être le type de données string et doivent être marquées comme une colonne Feature .
Si vous choisissez plusieurs colonnes de texte à utiliser comme entrées, cela peut avoir un effet énorme sur la dimensionnalité des caractéristiques. Par exemple, si un hachage 10 bits est utilisé pour une seule colonne de texte, la sortie contient 1 024 colonnes. Si un hachage 10 bits est utilisé pour deux colonnes de texte, la sortie contient 2 048 colonnes.
Notes
Par défaut, Studio (classique) marque la plupart des colonnes de texte en tant que fonctionnalités. Par conséquent, si vous sélectionnez toutes les colonnes de texte, vous pouvez obtenir trop de colonnes, y compris beaucoup qui ne sont pas réellement du texte libre. Utilisez l’option Effacer la fonctionnalité dans Modifier les métadonnées pour empêcher la hachage d’autres colonnes de texte.
Utilisez la taille des bits de hachage pour spécifier le nombre de bits à utiliser lors de la création de la table de hachage.
La taille des bits par défaut s’élève à 10. Pour de nombreux problèmes, cette valeur est plus que suffisante, mais si les données suffisent dépend de la taille du vocabulaire n-grammes dans le texte d’apprentissage. Avec un vocabulaire volumineux, davantage d’espace peut être nécessaire pour éviter les collisions.
Nous vous recommandons d’essayer d’utiliser un nombre différent de bits pour ce paramètre et d’évaluer les performances de la solution Machine Learning.
Pour N-grammes, tapez un nombre qui définit la longueur maximale des n-grammes à ajouter au dictionnaire d’entraînement. Un n-gramme est une séquence de n mots, traitée comme une unité unique.
N-grammes = 1 : Unigrammes ou mots simples.
N-grammes = 2 : Bigrams, ou séquences à deux mots, plus unigrammes.
N-grammes = 3 : trigrammes, ou séquences à trois mots, ainsi que bigrams et unigrammes.
Exécutez l’expérience.
Résultats
Une fois le traitement terminé, le module génère un jeu de données transformé dans lequel la colonne de texte d’origine a été convertie en plusieurs colonnes, chacune représentant une caractéristique dans le texte. Selon la taille du dictionnaire, le jeu de données résultant peut être extrêmement volumineux :
| Nom de colonne 1 | Type de colonne 2 |
|---|---|
| TEXTE UTILISATEUR | Colonne de données d’origine |
| SENTIMENT | Colonne de données d’origine |
| TEXTE UTILISATEUR - Caractéristique de hachage 1 | Colonne de caractéristique hachée |
| TEXTE UTILISATEUR - Caractéristique de hachage 2 | Colonne de caractéristique hachée |
| TEXTE UTILISATEUR - Caractéristique de hachage n | Colonne de caractéristique hachée |
| TEXTE UTILISATEUR - Caractéristique de hachage 1 024 | Colonne de caractéristique hachée |
Une fois que vous avez créé le jeu de données transformé, vous pouvez l’utiliser comme entrée du module Entraîner le modèle , avec un bon modèle de classification, tel que machine à vecteurs de prise en charge à deux classes.
Bonnes pratiques
Certaines bonnes pratiques que vous pouvez utiliser lors de la modélisation des données de texte sont illustrées dans le diagramme suivant représentant une expérience
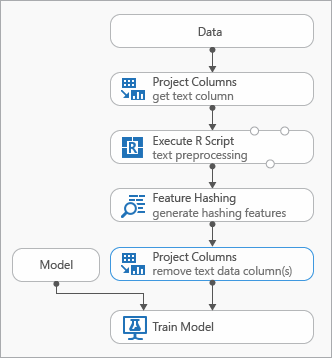
Vous devrez peut-être ajouter un module Execute R Script avant d'utiliser Feature Hashing, afin de prétraiter le texte d'entrée. Avec le script R, vous avez également la possibilité d’utiliser des vocabulaires personnalisés ou des transformations personnalisées.
Vous devez ajouter un module Sélectionner des colonnes dans le jeu de données après le module de hachage de fonctionnalité pour supprimer les colonnes de texte du jeu de données de sortie. Vous n’avez pas besoin des colonnes de texte une fois les fonctionnalités de hachage générées.
Vous pouvez également utiliser le module Modifier les métadonnées pour effacer l’attribut de fonctionnalité de la colonne de texte.
Envisagez également d’utiliser ces options de prétraitement de texte pour simplifier les résultats et améliorer la précision :
- mots cassants
- arrêter la suppression de mot
- normalisation de cas
- suppression de signes de ponctuation et de caractères spéciaux
- Issus.
L’ensemble optimal de méthodes de prétraitement à appliquer dans une solution individuelle dépend du domaine, du vocabulaire et des besoins métier. Nous vous recommandons d’expérimenter vos données pour voir quelles méthodes de traitement de texte personnalisées sont les plus efficaces.
Exemples
Pour obtenir des exemples de l’utilisation du hachage des fonctionnalités pour l’analyse de texte, consultez la galerie Azure AI :
Catégorisation des actualités : utilise le hachage des fonctionnalités pour classifier des articles dans une liste prédéfinie de catégories.
Sociétés similaires : utilise le texte des articles Wikipédia pour catégoriser les entreprises.
Classification de texte : cet exemple en cinq parties utilise du texte provenant de messages Twitter pour effectuer une analyse des sentiments.
Notes techniques
Cette section contient des détails, des conseils et des réponses aux questions fréquentes concernant l’implémentation.
Conseil
En plus d’utiliser le hachage des fonctionnalités, vous pouvez utiliser d’autres méthodes pour extraire des caractéristiques du texte. Exemple :
- Utilisez le module De prétraitement du texte pour supprimer des artefacts tels que des fautes d’orthographe ou pour simplifier le hachage du texte.
- Utilisez Extraire des expressions clés pour utiliser le traitement en langage naturel pour extraire des expressions.
- Utilisez la reconnaissance d’entités nommées pour identifier les entités importantes.
Machine Learning Studio (classique) fournit un modèle de classification de texte qui vous guide tout au long de l’utilisation du module de hachage des fonctionnalités pour l’extraction de fonctionnalités.
Informations d’implémentation
Le module Feature Hashing utilise une infrastructure de machine learning rapide appelée Vowpal Wabbit qui hachage les mots de caractéristique dans des index en mémoire, à l’aide d’une fonction de hachage open source populaire appelée murmurhash3. Cette fonction de hachage est un algorithme de hachage non cryptographique qui mappe des entrées de texte à des entiers. Elle est souvent utilisée car elle fonctionne efficacement dans une distribution aléatoire de clés. Contrairement aux fonctions de hachage de chiffrement, il peut être facilement inversé par un adversaire, afin qu’il ne soit pas adapté à des fins de chiffrement.
L'objectif de hachage consiste à convertir des documents texte de longueur variable en vecteurs de fonctions numériques de longueur égale, pour prendre en charge la réduction de la dimensionnalité et accélérer la recherche du poids des fonctions.
Chaque fonctionnalité de hachage représente une ou plusieurs caractéristiques de texte n-grammes (unigrammes ou mots individuels, bi-grammes, tri-grammes, etc.), en fonction du nombre de bits (représenté sous la forme k) et du nombre de n-grammes spécifiés en tant que paramètres. Il projette des noms de caractéristiques dans le mot non signé de l’architecture de machine à l’aide de l’algorithme murmurhash v3 (32 bits uniquement) qui est ensuite AND-ed avec (2^k)-1. Autrement dit, la valeur hachée est projetée vers le bas jusqu’aux premiers bits d’ordre inférieur k, et les bits restants sont nuls. Si le nombre de bits spécifié est de 14, la table de hachage peut contenir 2 entréesde 14 à 1 (ou 16 383).
Pour de nombreux problèmes, la table de hachage par défaut (bitsize = 10) est plus que suffisante ; toutefois, selon la taille du vocabulaire n-grammes dans le texte d’entraînement, il peut être nécessaire d’avoir plus d’espace pour éviter les collisions. Nous vous recommandons d’essayer d’utiliser un nombre différent de bits pour le paramètre de hachage de bitsize et d’évaluer les performances de la solution Machine Learning.
Entrées attendues
| Nom | Type | Description |
|---|---|---|
| Dataset | Table de données | Jeu de données d'entrée |
Paramètres du module
| Nom | Plage | Type | Default | Description |
|---|---|---|---|---|
| Colonnes cibles | Quelconque | ColumnSelection | StringFeature | Choisissez les colonnes auxquelles le hachage sera appliqué. |
| Taille de bit hachage | [1;31] | Integer | 10 | Tapez le nombre de bits à utiliser pour le hachage des colonnes sélectionnées |
| N-grams | [0;10] | Integer | 2 | Spécifiez le nombre de N-grammes générés pendant le hachage. Par défaut, les unigrammes et les bigrammes sont extraits |
Sorties
| Nom | Type | Description |
|---|---|---|
| Jeu de données transformé | Table de données | Jeu de données de sortie avec des colonnes hachées |
Exceptions
| Exception | Description |
|---|---|
| Erreur 0001 | Une exception se produit si une ou plusieurs colonnes spécifiées du jeu de données sont introuvables. |
| Erreur 0003 | Cette exception se produit si une ou plusieurs entrées sont null ou vide. |
| Erreur 0004 | Une exception se produit si le paramètre est inférieur ou égal à une valeur spécifique. |
| Erreur 0017 | Une exception se produit si une ou plusieurs colonnes spécifiées présentent un type non pris en charge par le module actuel. |
Pour obtenir la liste des erreurs spécifiques aux modules Studio (classique), consultez Machine Learning codes d’erreur.
Pour obtenir la liste des exceptions d’API, consultez Machine Learning codes d’erreur de l’API REST.