Tutoriel : Concepteur – effectuer l’apprentissage d’un modèle de régression sans code
Effectuer l’apprentissage d’un modèle de régression linéaire qui prédit les prix des voitures à l’aide du concepteur Azure Machine Learning. Ce tutoriel est le premier d’une série de deux.
Ce tutoriel utilise le concepteur Azure Machine Learning. Pour plus d’informations, consultez Qu’est-ce que le concepteur Azure Machine Learning ?
Notes
Le concepteur prend en charge deux types de composants, les composants prédéfinis classiques (v1) et les composants personnalisés (v2). Ces deux types de composants ne sont PAS compatibles.
Les composants prédéfinis classiques fournissent principalement des composants prédéfinis utilisés pour le traitement des données et les tâches de Machine Learning traditionnelles telles que la régression et la classification. Ce type de composant continue d’être pris en charge, mais aucun nouveau composant n’est ajouté.
Les composants personnalisés vous permettent d’encapsuler votre propre code en tant que composant. Ils vous permettent de partager des composants dans des espaces de travail et de créer en toute transparence dans des interfaces Studio, CLI v2 et le Kit de développement logiciel (SDK) v2.
Pour les nouveaux projets, nous vous suggérons vivement d’utiliser un composant personnalisé et compatible avec AzureML V2 qui va continuer à recevoir de nouvelles mises à jour.
Cet article s’applique aux composants classiques, prédéfinis et non compatibles avec l’interface CLI v2 et le kit de développement logiciel (SDK) v2.
Dans la première partie du tutoriel, vous allez :
- Créer un pipeline
- Importer des données
- Préparer les données
- Entraîner un modèle Machine Learning
- Évaluer un modèle Machine Learning
Dans la deuxième partie du tutoriel, vous déployez votre modèle en tant que point de terminaison d’inférence en temps réel pour prédire le prix de n’importe quel véhicule en fonction des caractéristiques techniques que vous lui envoyez.
Notes
Une version complète de ce tutoriel est disponible en tant qu’exemple de pipeline.
Pour le trouver, accédez au concepteur dans votre espace de travail. Dans la section Nouveau pipeline, sélectionnez Exemple 1 - Régression : Prédiction du prix de véhicules automobiles (de base) .
Important
Si vous ne voyez pas les éléments graphiques mentionnés dans ce document, tels que les boutons dans Studio ou le concepteur, vous ne disposez peut-être pas du niveau d’autorisations approprié pour l’espace de travail. Contactez votre administrateur d’abonnement Azure pour vérifier que le niveau d’accès est correct. Pour plus d’informations, consultez Gérer les utilisateurs et les rôles.
Créer un pipeline
Les pipelines Azure Machine Learning organisent plusieurs étapes de machine learning et de traitement de données en une même ressource. Les pipelines vous permettent d’organiser, de gérer et de réutiliser des workflows de Machine Learning complexes entre des projets et des utilisateurs.
Pour créer un pipeline Azure Machine Learning, vous devez disposer d’un espace de travail Azure Machine Learning. Dans cette section, vous découvrez comment créer ces deux ressources.
Créer un espace de travail
Vous devez avoir un espace de travail Azure Machine Learning pour utiliser le concepteur. L’espace de travail est la ressource de niveau supérieur pour Azure Machine Learning. Il fournit un emplacement centralisé où vous interagissez avec tous les artefacts que vous créez dans Azure Machine Learning. Pour des instructions sur la création d’un espace de travail, consultez Créer des ressources d’espace de travail.
Notes
Si votre espace de travail utilise un réseau virtuel, vous devez effectuer des étapes de configuration supplémentaires pour utiliser le concepteur. Pour plus d’informations, consultez Utiliser le studio Azure Machine Learning dans un réseau virtuel Azure
Créer le pipeline
Notes
Le concepteur prend en charge deux types de composants, les composants prédéfinis classiques et les composants personnalisés. Ces deux types de composants ne sont pas compatibles.
Les composants prédéfinis classiques fournissent principalement des composants prédéfinis pour le traitement des données et les tâches de Machine Learning traditionnelles telles que la régression et la classification. Ce type de composant continue d’être pris en charge, mais aucun nouveau composant n’est ajouté.
Les composants personnalisés vous permettent de fournir votre propre code en tant que composant. Cela permet le partage entre les espaces de travail et la création transparente dans les interfaces Studio, CLI et SDK.
Cet article s’applique aux composants prédéfinis classiques.
Connectez-vous à ml.azure.com, puis sélectionnez l’espace de travail à utiliser.
Sélectionnez Concepteur ->Composants prédéfinis classiques
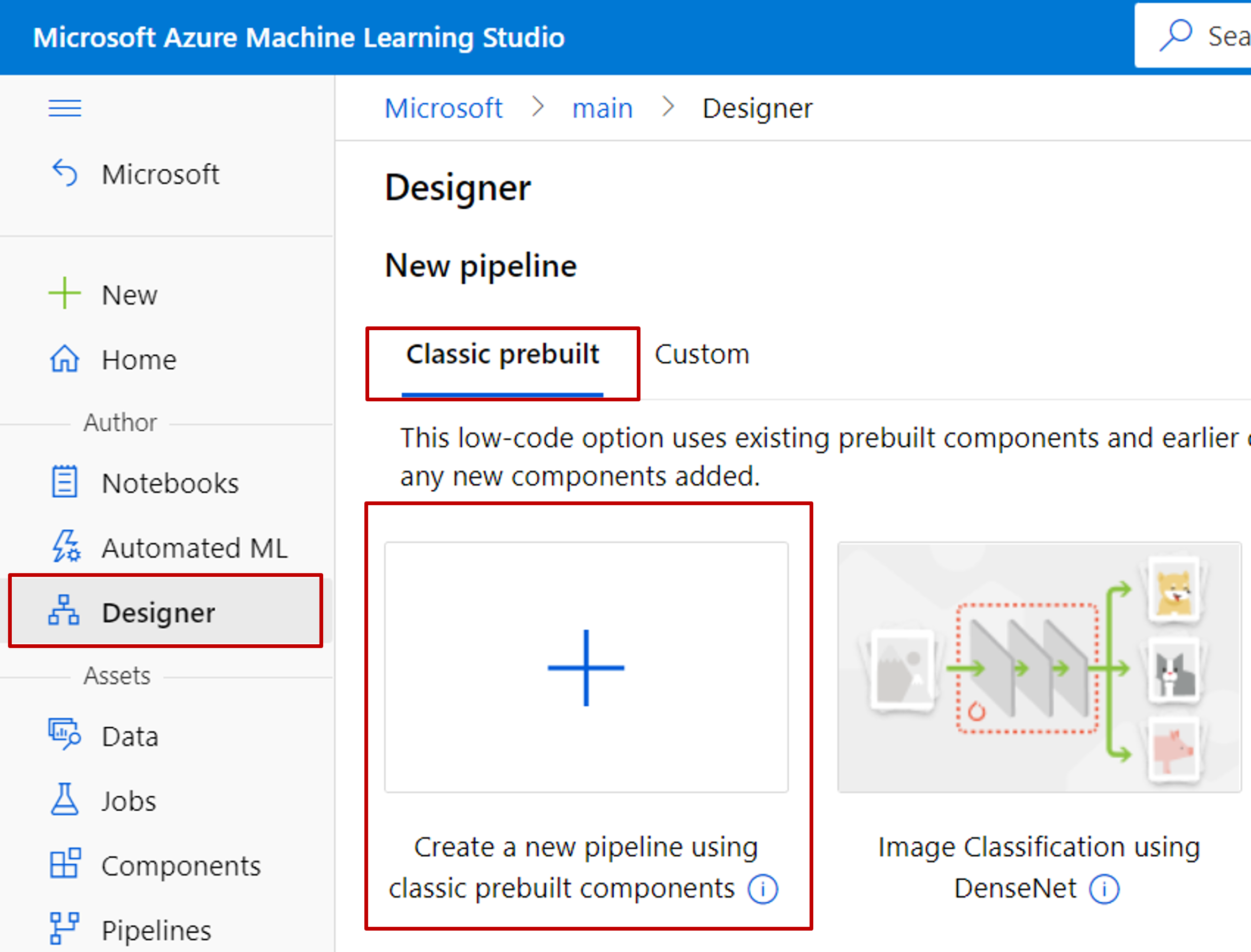
Sélectionnez Créer un pipeline à l’aide de composants prédéfinis classiques.
Cliquez sur l’icône en forme de crayon à côté du nom provisoire de pipeline généré automatiquement, puis renommez-le en Prédiction du prix de véhicules automobiles. Le nom n’a pas besoin d’être unique.
Importer des données
Un certain nombre d’exemples de jeux de données que vous pouvez expérimenter sont inclus dans le concepteur. Pour les besoins de ce tutoriel, vous allez utiliser Automobile price data (Raw) (Données sur le prix des véhicules automobiles [brutes]).
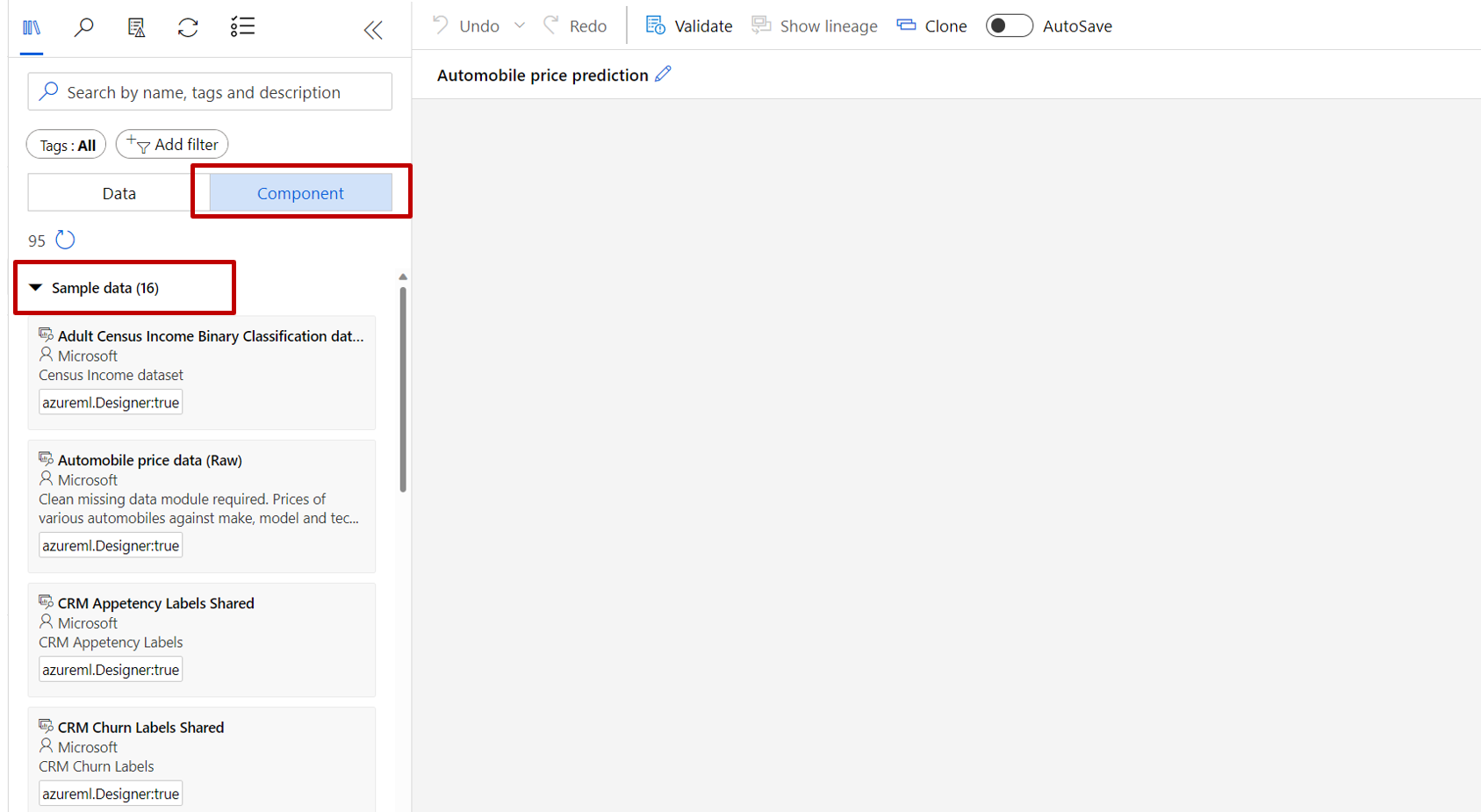
À gauche du canevas du pipeline se trouve une palette de jeux de données et de composants. Sélectionnez Composant ->Exemple de données.
Sélectionnez le jeu de données Automobile price data (raw) (Données sur le prix des automobiles (brut)), puis faites-le glisser vers le canevas.
Visualiser les données
Vous pouvez visualiser les données pour comprendre le jeu de données que vous allez utiliser.
Cliquez avec le bouton droit sur Données sur le prix des véhicules automobiles (brutes), puis sélectionnez Aperçu des données.
Cliquez sur différentes colonnes dans la fenêtre de données pour visualiser des informations les concernant.
Chaque ligne représente un véhicule automobile et chaque colonne représente une variable associée au véhicule automobile. Ce jeu de données contient 205 lignes et 26 colonnes.
Préparer les données
Les jeux de données nécessitent généralement un prétraitement avant l’analyse. Vous avez peut-être remarqué qu’il manquait des valeurs durant l’inspection du jeu de données. Ces valeurs manquantes doivent être nettoyées pour que le modèle puisse analyser les données correctement.
Supprimer une colonne
Quand vous entraînez un modèle, vous devez traiter le problème des données manquantes. Dans ce jeu de données, la colonne normalized-losses (pertes normalisées) a de nombreuses valeurs manquantes : vous allez donc l’exclure du modèle.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Sélectionner les colonnes dans le jeu de données.
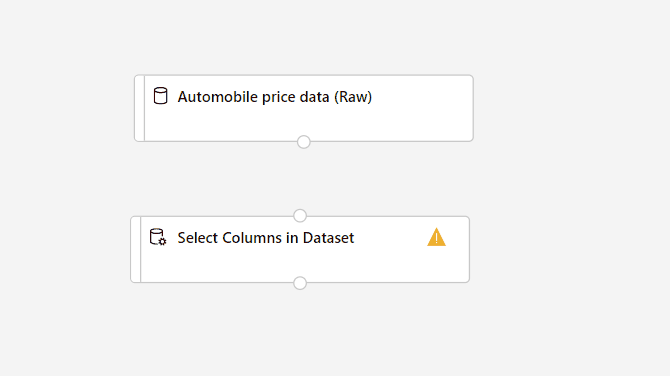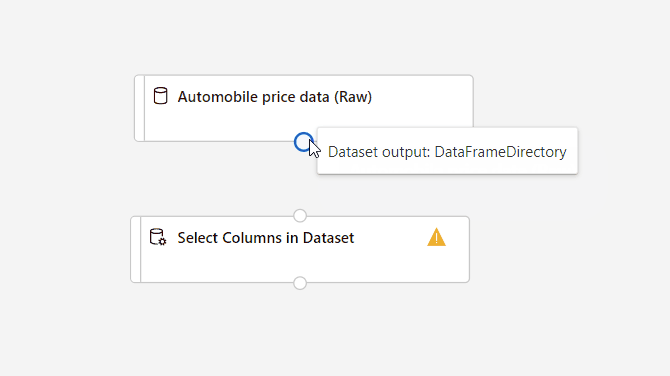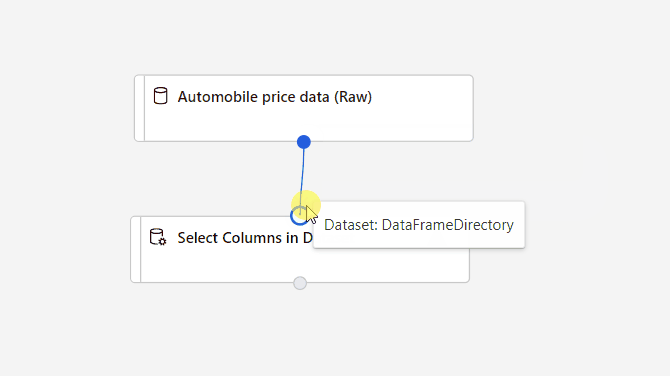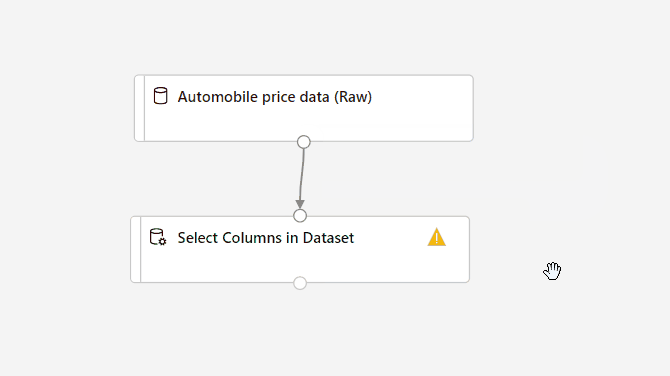
Faites glisser le composant Sélectionner des colonnes dans le jeu de données sur le canevas. Déposez le composant sous le composant du jeu de données.
Connectez le jeu de données Données sur le prix des véhicules automobiles (brutes) au composant Sélectionner des colonnes dans le jeu de données. Faites-le glisser depuis le port de sortie du jeu de données, qui est le petit cercle situé en bas du jeu de données sur le canevas, jusqu’au port d’entrée de Sélectionner des colonnes dans le jeu de données, qui est le petit cercle en haut du composant.
Conseil
Vous créez un flux de données dans votre pipeline lorsque vous connectez le port de sortie d’un composant au port d’entrée d’un autre.
Sélectionnez le composant Sélectionner des colonnes dans le jeu de données.
Cliquez sur l’icône de flèche sous Paramètres à droite du canevas pour ouvrir le volet des détails du composant. Vous pouvez également double-cliquer sur le composant Sélectionner des colonnes dans le jeu de données pour ouvrir le volet des détails.
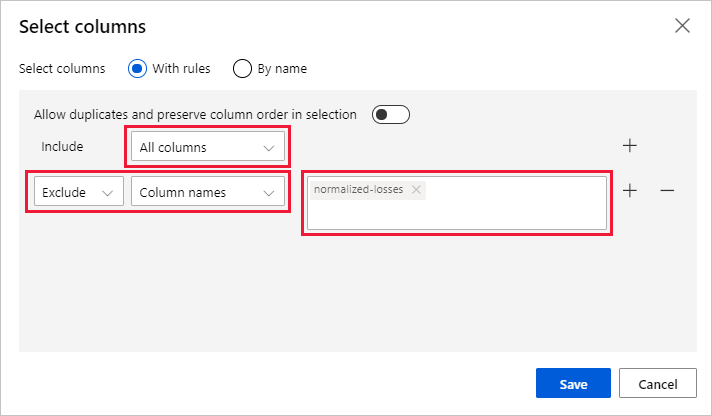
Sélectionnez Modifier la colonne à droite du volet.
Développez la liste déroulante Column names (Noms des colonnes) à côté de Include (Inclure), puis sélectionnez All columns (Toutes les colonnes).
Sélectionnez le signe + pour ajouter une règle.
Dans les menus déroulants, sélectionnez Exclude (Exclure) et Column names (Noms des colonnes).
Entrez normalized-losses (pertes normalisées) dans la zone de texte.
En bas à droite, sélectionnez Enregistrer pour fermer le sélecteur de colonne.
Dans le volet des détails du composant Sélectionner des colonnes dans le jeu de données, développez Informations de nœud.
Sélectionnez la zone de texte Commentaire et entrez Exclure les pertes normalisées.
Les commentaires sont affichés sur le graphe pour vous aider à organiser votre pipeline.
Nettoyage des données manquantes
Il manque encore des valeurs dans votre jeu de données après la suppression de la colonne normalized-losses. Vous pouvez supprimer les données manquantes restantes à l’aide du composant Nettoyage des données manquantes.
Conseil
Le nettoyage des valeurs manquantes dans les données d’entrée est une condition préalable à l’utilisation de la plupart des composants du concepteur.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Nettoyer les données manquantes.
Faites glisser le composant Nettoyage des données manquantes jusqu’au canevas du pipeline. Connectez-le au composant Sélectionner des colonnes dans le jeu de données.
Sélectionnez le composant Clean Missing Data.
Cliquez sur l’icône de flèche sous Paramètres à droite du canevas pour ouvrir le volet des détails du composant. Vous pouvez également double-cliquer sur le composant Nettoyer les données manquantes pour ouvrir le volet des détails.
Sélectionnez Modifier la colonne à droite du volet.
Dans la fenêtre Columns to be cleaned (Colonnes à nettoyer) qui s’affiche, développez le menu déroulant en regard d’Include (inclure). Sélectionnez All columns (Toutes les colonnes).
Sélectionnez Enregistrer.
Dans le volet des détails du composant Nettoyer les données manquantes, sous Mode de nettoyage, sélectionnez Supprimer la ligne entière.
Dans le volet des détails du composant Nettoyer les données manquantes, développez Informations de nœud.
Sélectionnez la zone de texte Commentaire et entrez Supprimer les lignes de valeur manquantes.
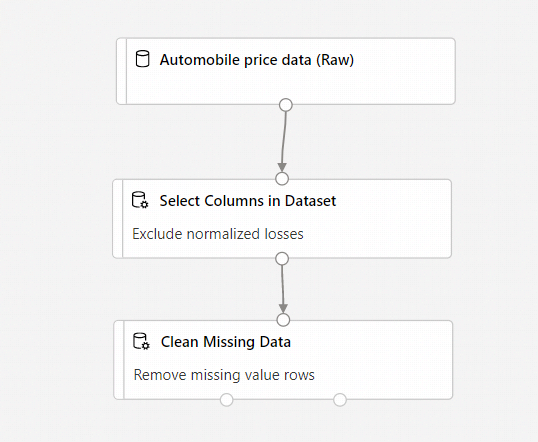
Votre pipeline doit maintenant se présenter comme ceci :
Entraîner un modèle Machine Learning
Une fois les composants en place pour traiter les données, vous pouvez configurer les composants d’entraînement.
Comme vous voulez prédire un prix, à savoir un nombre, vous pouvez utiliser un algorithme de régression. Pour cet exemple, vous utilisez un modèle de régression linéaire.
Fractionner les données
Le fractionnement des données est une tâche courante de Machine Learning. Vous allez diviser vos données en deux jeux de données distincts. Un jeu de données effectue l’apprentissage du modèle et l’autre teste ses performances.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Fractionner les données.
Faites glisser le composant Fractionner les données jusqu’au canevas du pipeline.
Connectez le port gauche du composant Nettoyage des données manquantes au composant Fractionner les données.
Important
Vérifiez que le port de sortie de gauche de Nettoyer les données manquantes se connecte à Fractionner les données. Le port de gauche contient les données nettoyées. Le port de droite contient les données abandonnées.
Sélectionnez le composant Split Data.
Cliquez sur l’icône de flèche sous Paramètres à droite du canevas pour ouvrir le volet des détails du composant. Vous pouvez également double-cliquer sur le composant Fractionner les données pour ouvrir le volet des détails.
Dans le volet des détails de Fractionner les données, affectez à l’option Fraction de lignes du premier jeu de données de sortie la valeur 0.7.
Cette option permet de diviser les données afin d’en utiliser 70 % pour entraîner le modèle et 30 % pour tester ce dernier. Le jeu de données comprenant 70 % des données est accessible par le biais du port de sortie de gauche. Les données restantes sont disponibles via le port de sortie de droite.
Dans le volet des détails Fractionner les données, développez Informations de nœud.
Sélectionnez la zone de texte Commentaire et entrez Diviser le jeu de données en un jeu d’entraînement (0,7) et un jeu de test (0,3).
Effectuer l’apprentissage du modèle
Entraînez le modèle en lui fournissant un jeu de données incluant le prix. L’algorithme construit un modèle qui explique la relation entre les caractéristiques et le prix dans les données d’entraînement.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Regression linéaire.
Faites glisser le composant Régression linéaire vers le canevas du pipeline.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Entraîner le modèle.
Faites glisser le composant Entraîner le modèle vers le canevas du pipeline.
Connectez la sortie du composant Régression linéaire à l’entrée gauche du composant Effectuer l’apprentissage du modèle.
Connectez la sortie des données d’entraînement (port gauche) du composant Fractionner les données à l’entrée droite du composant Effectuer l’apprentissage du modèle.
Important
Vérifiez que le port de sortie de gauche de Fractionner les données se connecte à Entraîner le modèle. Le port de gauche contient le jeu d’entraînement. Le port de droite contient le jeu de test.
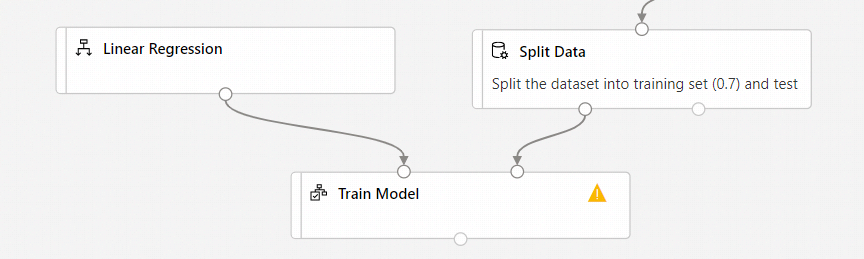
Sélectionnez le composant Effectuer l’apprentissage du modèle.
Cliquez sur l’icône de flèche sous Paramètres à droite du canevas pour ouvrir le volet des détails du composant. Vous pouvez également double-cliquer sur le composant Entraîner le modèle pour ouvrir le volet des détails.
Sélectionnez Modifier la colonne à droite du volet.
Dans la fenêtre Étiqueter une colonne qui apparaît, développez le menu déroulant et sélectionnez Noms de colonnes.
Dans la zone de texte, entrez price pour spécifier la valeur que votre modèle va prédire.
Important
Veillez à entrer le nom de colonne tel qu’indiqué. Ne mettez pas price en majuscules.
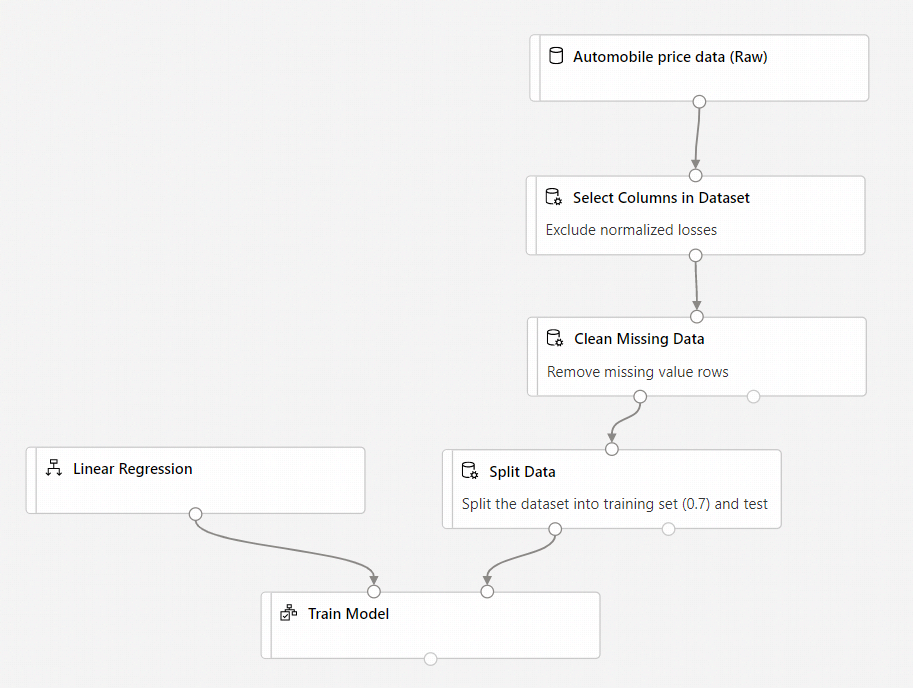
Votre pipeline doit se présenter comme suit :
Ajoutez le composant Noter le modèle.
Une fois que vous avez entraîné votre modèle à l’aide de 70 % des données, vous pouvez l’utiliser pour attribuer un score aux 30 % de données restants, et vérifier ainsi son bon fonctionnement.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Scorer le modèle.
Faites glisser le composant Scorer le modèle vers le canevas du pipeline.
Connectez la sortie du composant Effectuer l’apprentissage du modèle au port d’entrée gauche du composant Noter le modèle. Connectez la sortie des données de test (port droit) du composant Fractionner les données au port d’entrée droit du composant Noter le modèle.
Ajouter le composant Évaluer le modèle
Utilisez le composant Évaluer le modèle pour évaluer le score attribué par votre modèle au jeu de données de test.
Dans les jeux de données et la palette de composants à gauche du canevas, cliquez sur Composant et recherchez le composant Évaluer le modèle.
Faites glisser le composant Évaluer le modèle vers le canevas du pipeline.
Connectez la sortie du composant Noter le modèle à l’entrée gauche du composant Évaluer le modèle.
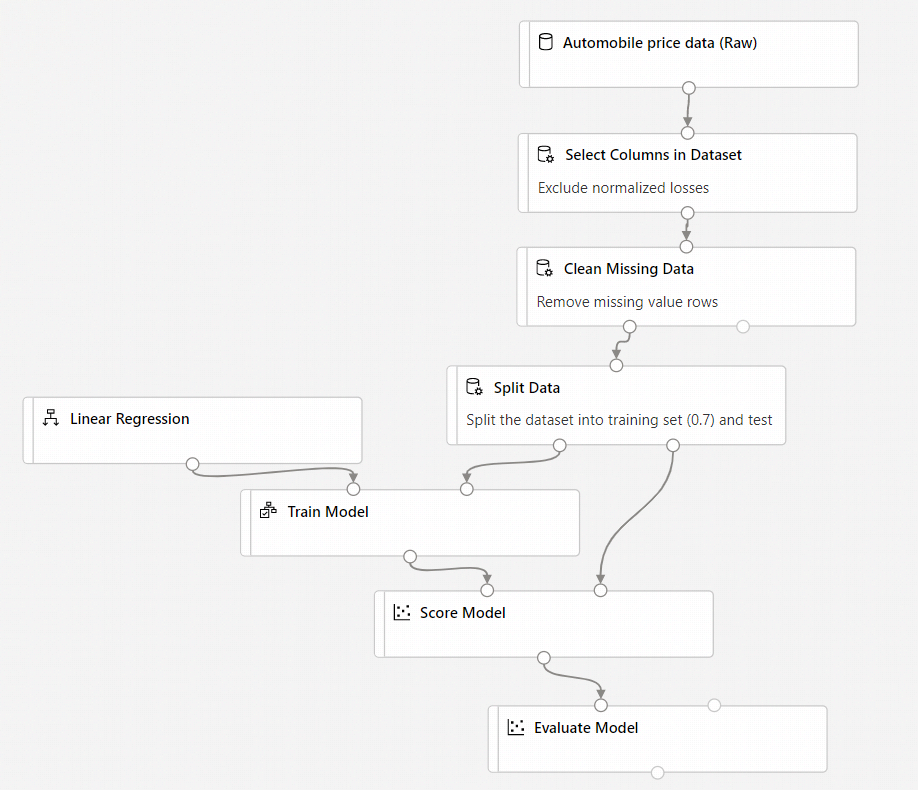
Le pipeline final doit maintenant se présenter comme ceci :
Envoyer le pipeline
Sélectionnez Configurer et Envoyer dans le coin supérieur droit pour soumettre le pipeline.

Ensuite, vous verrez un assistant étape par étape, suivez l'assistant pour soumettre le travail de pipeline.
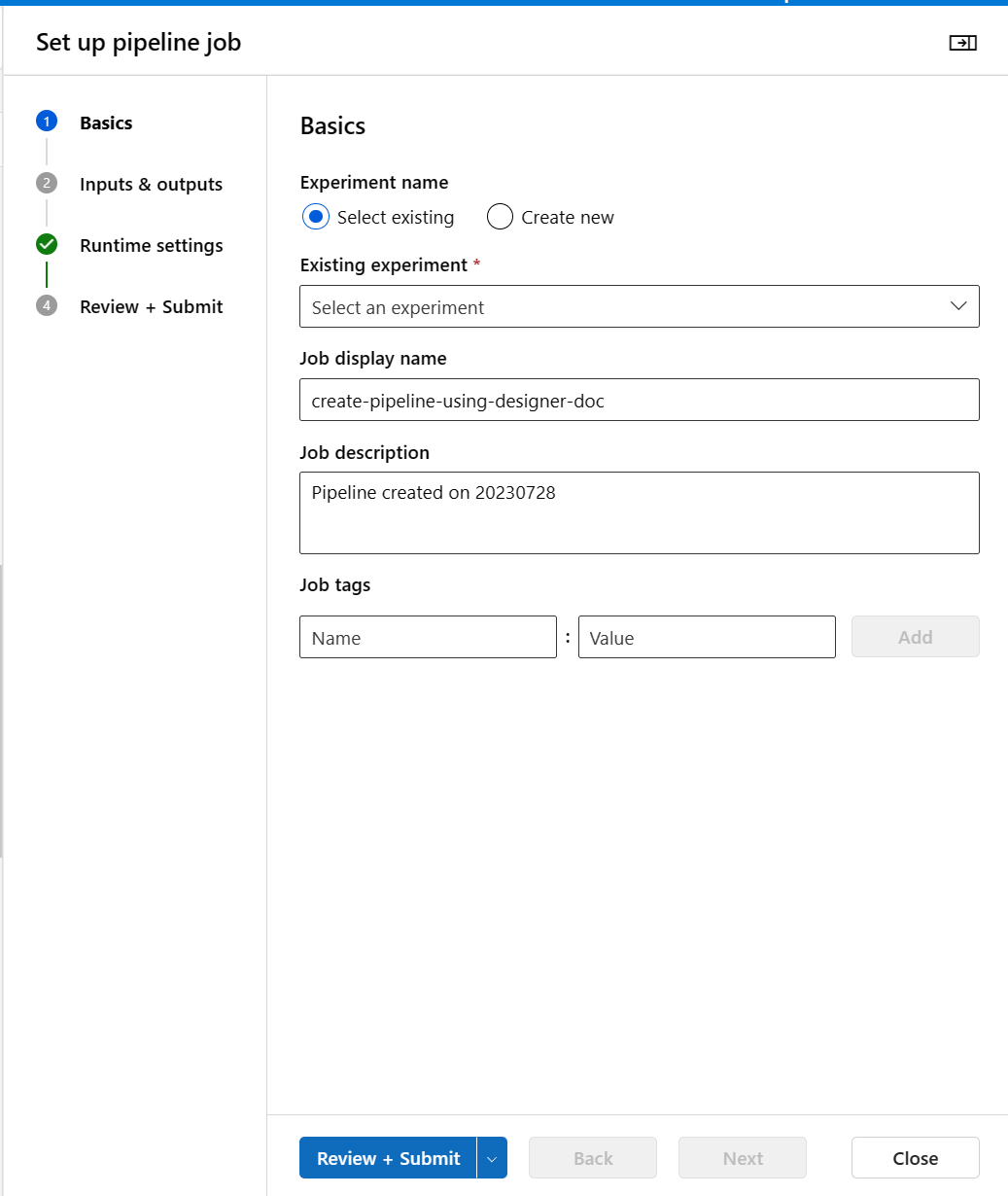

À l'étape Bases, vous pouvez configurer l'expérience, le nom d'affichage de la tâche, la description de la tâche, etc.
Dans l’étape Entrées et Sorties, vous pouvez affecter une valeur aux Entrées/Sorties qui sont promues au niveau du pipeline. Dans cet exemple, il sera vide, car nous n’avons pas promu d’entrée/sortie au niveau du pipeline.
Dans Paramètres d’exécution, vous pouvez configurer le magasin de données par défaut et le calcul par défaut du pipeline. Il s’agit du magasin de données/calcul par défaut pour tous les composants du pipeline. Toutefois, si vous définissez explicitement un calcul ou un magasin de données différent pour un composant, le système respecte le paramètre au niveau du composant. Sinon, il utilise la valeur par défaut.
L’étape Vérifier + Envoyer est la dernière étape pour examiner tous les paramètres avant de les soumettre. L’Assistant se souvient de votre dernière configuration si jamais vous soumettez le pipeline.
Après avoir soumis le travail de pipeline, un message apparaît en haut avec un lien vers les détails du travail. Vous pouvez sélectionner ce lien pour examiner les détails du travail.

Afficher les étiquettes de score
Dans la page Détails du travail, vous pouvez vérifier l’état du travail de pipeline, les résultats et les journaux.
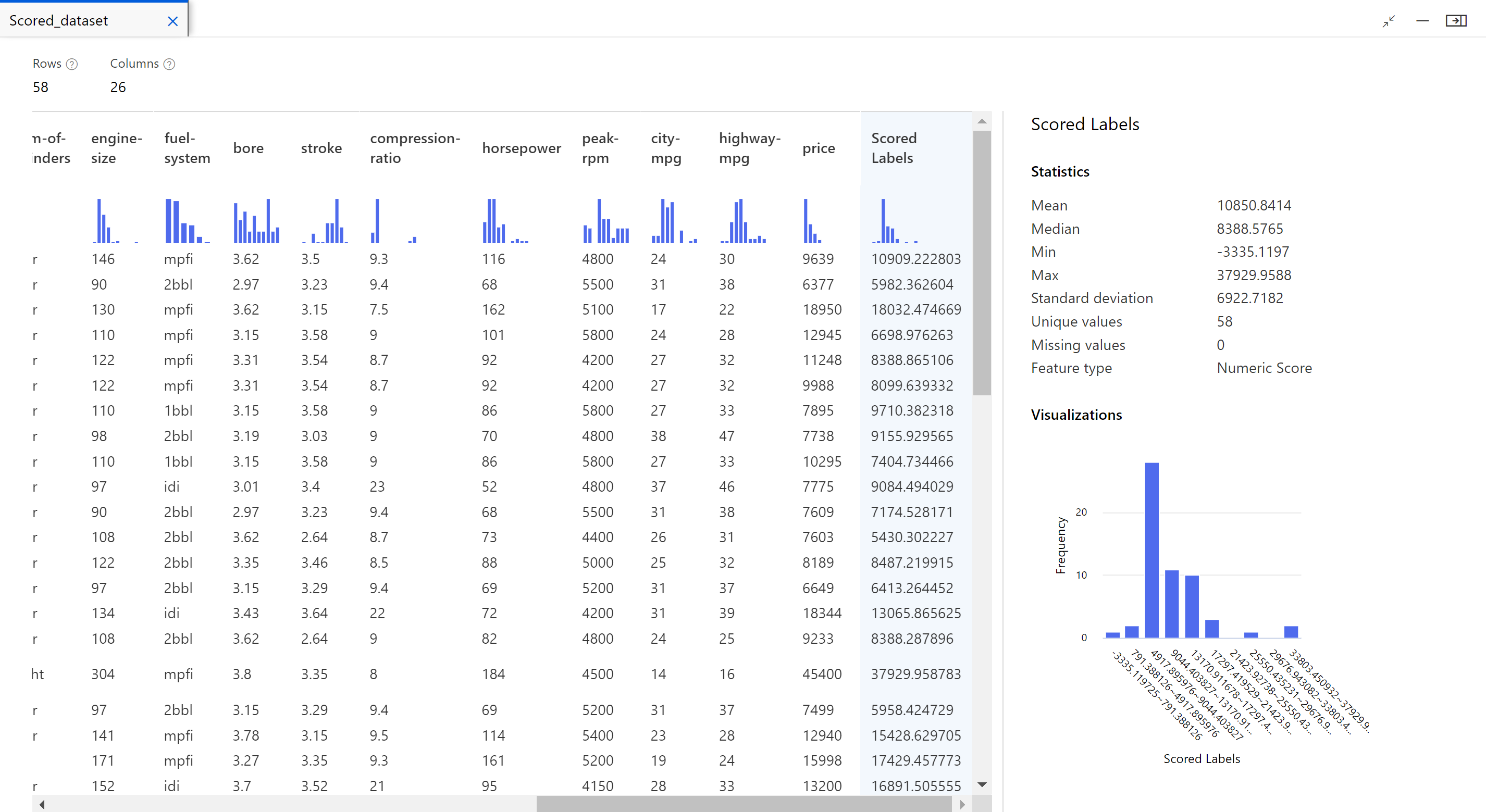
Une fois le travail terminé, vous pouvez voir les résultats du travail du pipeline. Tout d’abord, examinez les prédictions générées par le modèle de régression.
Cliquez avec le bouton droit sur le composant Noter le modèle et sélectionnez Aperçu des données>Jeu de données noté pour afficher sa sortie.
Vous pouvez voir ici les prix prédits et les prix réels des données à partir des données de test.
Évaluer les modèles
Utilisez Evaluate Model pour voir ce que donne le modèle entraîné sur le jeu de données de test.
- Cliquez avec le bouton droit sur le composant Évaluer le modèle et sélectionnez Aperçu des données>Résultats de l’évaluation pour afficher sa sortie.
Les statistiques suivantes s’affichent pour votre modèle :
- Erreur absolue moyenne : Moyenne des erreurs absolues. Une erreur est la différence entre la valeur prédite et la valeur réelle.
- Racine carrée de l’erreur quadratique moyenne : la racine carrée de la moyenne des erreurs carrées des prévisions effectuées sur le jeu de données de test.
- Erreur absolue relative: la moyenne des erreurs absolues relative à la différence absolue entre les valeurs réelles et la moyenne de toutes les valeurs réelles.
- Erreur carrée relative : la moyenne des erreurs carrées relative à la différence carrée entre les valeurs réelles et la moyenne de toutes les valeurs réelles.
- Coefficient de détermination : Également connue sous le nom de valeur R au carré, cette métrique statistique indique dans quelle mesure un modèle correspond aux données.
Pour chacune des statistiques liées aux erreurs, les valeurs les plus petites sont privilégiées. En effet, une valeur plus petite indique que les prédictions sont plus près des valeurs réelles. Plus la valeur du coefficient de détermination est proche de un (1,0), plus les prévisions sont correctes.
Nettoyer les ressources
Ignorez cette section si vous souhaitez passer à la deuxième partie du tutoriel sur le déploiement de modèles.
Important
Vous pouvez utiliser les ressources que vous avez créées comme prérequis pour d’autres didacticiels et articles de guides pratiques Azure Machine Learning.
Tout supprimer
Si vous n’avez pas l’intention d’utiliser les éléments que vous avez créés, supprimez l’intégralité du groupe de ressources pour éviter des frais.
Dans le portail Azure, sélectionnez Groupes de ressources sur le côté gauche de la fenêtre.
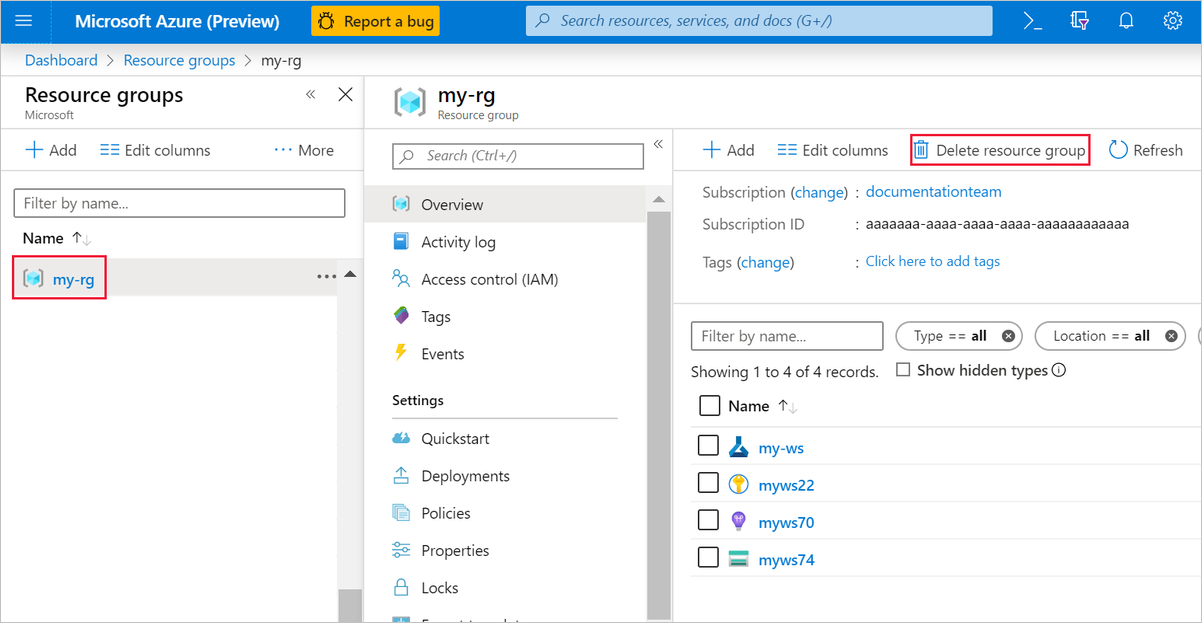
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
La suppression du groupe de ressources supprime également toutes les ressources créées dans le concepteur.
Supprimer des ressources individuelles
Dans le concepteur où vous avez créé votre expérience, supprimez des ressources individuelles en les sélectionnant, puis en sélectionnant le bouton Supprimer.
La cible de calcul que vous avez créée ici est automatiquement mise à l’échelle sur zéro nœud quand elle n’est pas utilisée. Cette action est effectuée pour réduire les frais. Si vous souhaitez supprimer la cible de calcul, procédez comme suit :
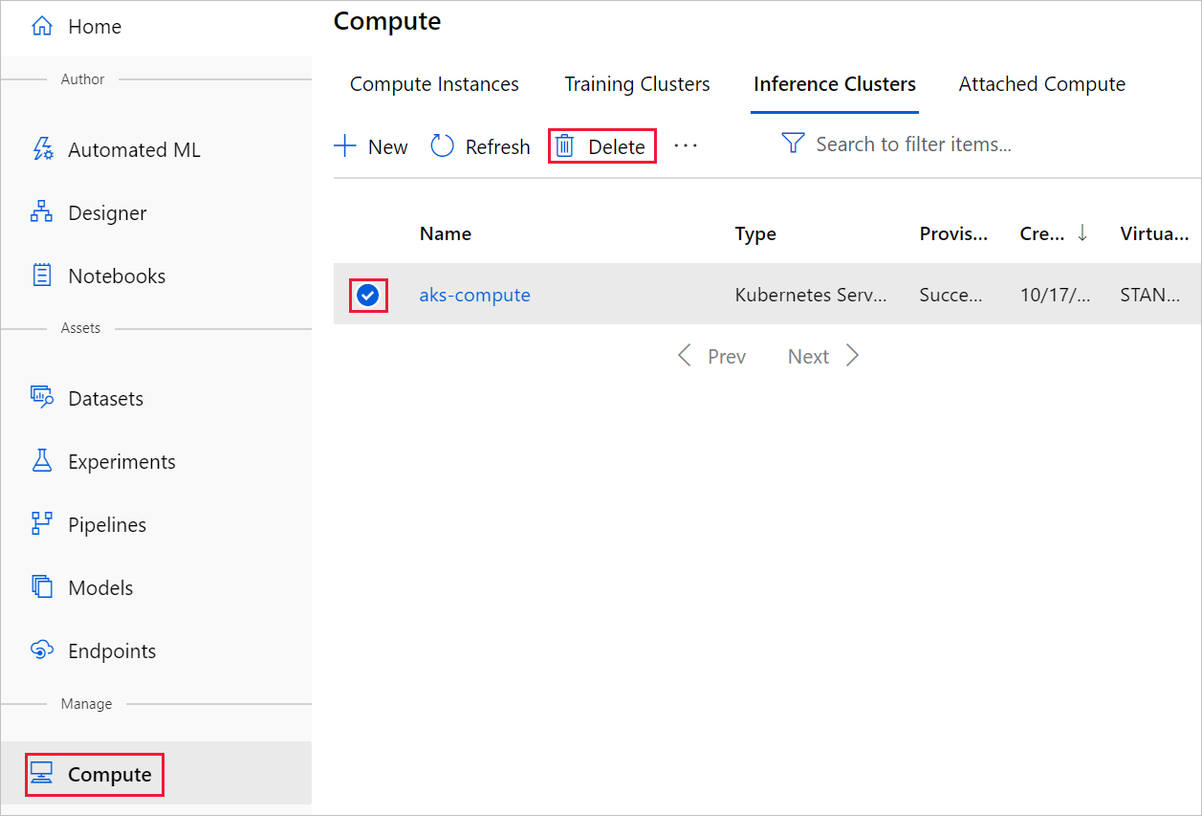
Vous pouvez désinscrire des jeux de données de votre espace de travail en sélectionnant chaque jeu de données, puis Annuler l’enregistrement.
Pour supprimer un jeu de données, accédez au compte de stockage à l’aide du portail Azure ou de l’Explorateur Stockage Azure et supprimez manuellement ces ressources.
Étapes suivantes
Dans la deuxième partie, vous allez découvrir comment déployer votre modèle en tant que point de terminaison en temps réel.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour