Déployer des modèles Machine Learning sur Azure
S’APPLIQUE À : Extension Azure CLI ml v1SDK Python azureml v1
Extension Azure CLI ml v1SDK Python azureml v1
Découvrez comment déployer votre modèle Machine Learning ou Deep Learning en tant que service web dans le cloud Azure.
Notes
Les points de terminaison Azure Machine Learning (v2) offrent une expérience de déploiement plus simple et améliorée. Les points de terminaison prennent en charge les scénarios d’inférence en temps réel et par lot. Les points de terminaison fournissent une interface unifiée pour appeler et gérer des déploiements de modèle pour différents types de calcul. Voir Quels sont les points de terminaison Azure Machine Learning ?.
Flux de travail pour le déploiement d’un modèle
Le workflow est le même, quel que soit l’endroit où vous déployez votre modèle :
- Inscrire le modèle.
- Préparer un script d’entrée.
- Préparer une configuration d’inférence.
- Déployer le modèle localement pour vous assurer que tout fonctionne.
- Choisir une cible de calcul.
- Déployer le modèle dans le cloud.
- Tester le service web qui en résulte.
Pour plus d’informations sur les concepts impliqués dans le workflow du déploiement Machine Learning, consultez Déployer, gérer et superviser des modèles avec Azure Machine Learning.
Prérequis
S’APPLIQUE À :Extension Azure CLI ml v1
Important
Les commandes Azure CLI de cet article requièrent l’extension azure-cli-ml, ou v1, pour Azure Machine Learning. La prise en charge de l’extension v1 se termine le 30 septembre 2025. Vous pourrez installer et utiliser l’extension v1 jusqu’à cette date.
Nous vous recommandons de passer à l’extension ml, ou v2, avant le 30 septembre 2025. Pour plus d’informations sur l’extension v2, consultez Extension Azure ML CLI et le SDK Python v2.
- Un espace de travail Azure Machine Learning. Pour plus d’informations, consultez Créer des ressources d’espace de travail.
- Un modèle Les exemples de cet article utilisent un modèle préformé.
- Une machine qui peut exécuter Docker, comme une instance de calcul.
Se connecter à un espace de travail
S’APPLIQUE À :Extension Azure CLI ml v1
Pour afficher les espaces de travail auxquels vous avez accès, utilisez les commandes suivantes :
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Inscrire le modèle
Une situation courante pour un service Machine Learning déployé est que vous avez besoin des composants suivants :
- Des ressources représentant le modèle spécifique que vous souhaitez déployer (par exemple : un fichier de modèle PyTorch).
- Le code que vous allez exécuter dans le service, qui exécute le modèle sur une entrée donnée.
Azure Machine Learning vous permet de séparer le déploiement en deux composants distincts, afin que vous puissiez conserver le même code et simplement mettre à jour le modèle. Nous définissons le mécanisme par lequel vous chargez un modèle séparément de votre code comme « inscription du modèle ».
Lorsque vous inscrivez un modèle, nous chargeons le modèle dans le cloud (dans le compte de stockage par défaut de votre espace de travail), puis nous le montons dans le même calcul que celui où est exécuté votre service web.
Les exemples suivants montrent comment inscrire un modèle.
Important
Utilisez uniquement les modèles que vous créez ou que vous obtenez auprès d’une source approuvée. Vous devez traiter les modèles sérialisés en tant que code, car des failles de sécurité ont été détectées dans plusieurs formats courants. En outre, des modèles peuvent être entraînés intentionnellement avec des intentions malveillantes pour fournir des sorties biaisées ou inexactes.
S’APPLIQUE À :Extension Azure CLI ml v1
Les commandes suivantes permettent de télécharger un modèle, puis de l’inscrire dans votre espace de travail Azure Machine Learning :
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Définissez -p sur le chemin d’accès d’un dossier ou d’un fichier que vous souhaitez inscrire.
Pour plus d’informations sur az ml model register, consultez la documentation de référence.
Inscrire un modèle à partir d’une tâche de formation Azure Machine Learning
Si vous devez inscrire un modèle qui a été créé précédemment par le biais d’un travail de formation Azure Machine Learning, vous pouvez spécifier l’expérience, l’exécution et le chemin d’accès au modèle :
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Le paramètre --asset-path fait référence à l’emplacement cloud du modèle. Dans cet exemple, le chemin d’un fichier unique est utilisé. Pour inclure plusieurs fichiers dans l’inscription du modèle, définissez --asset-path avec le chemin d’un dossier contenant les fichiers.
Pour plus d’informations sur az ml model register, consultez la documentation de référence.
Notes
Vous pouvez également inscrire un modèle à partir d’un fichier local via le portail de l’interface utilisateur de l’espace de travail.
Actuellement, il existe deux options pour charger un fichier de modèle local dans l’interface utilisateur :
- À partir de fichiers locaux, qui inscrivent un modèle v2.
- À partir de fichiers locaux (basés sur l’infrastructure) qui inscrivent un modèle v1.
Notez que seuls les modèles inscrits via l’entrée De fichiers locaux (basés sur l’infrastructure) (appelés modèles v1) peuvent être déployés en tant que services web à l’aide de SDKv1/CLIv1.
Définir un script d’entrée factice
Le script d’entrée reçoit les données envoyées à un service web déployé, puis les passe au modèle. Il renvoie ensuite la réponse du modèle au client. Le script est propre à votre modèle. Le script d'entrée doit comprendre les données que le modèle attend et renvoie.
Les deux choses que vous devez accomplir dans votre script d’entrée sont les suivantes :
- Charger votre modèle (à l’aide d’une fonction appelée
init()) - Exécuter votre modèle sur des données d’entrée (à l’aide d’une fonction appelée
run())
Pour votre déploiement initial, utilisez un script d'entrée factice qui imprime les données qu'il reçoit.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Enregistrez ce fichier sous le nom echo_score.py dans un répertoire appelé source_dir. Ce script factice renvoie les données que vous lui envoyez, il n’utilise donc pas le modèle. Mais il est utile pour tester que le script de scoring fonctionne.
Définir une configuration d’inférence
Une configuration d’inférence décrit le conteneur et les fichiers Docker à utiliser lors de l’initialisation de votre service web. Tous les fichiers de votre répertoire source, y compris les sous-répertoires, seront compressés et chargés dans le cloud lorsque vous déploierez votre service web.
La configuration d’inférence ci-dessous spécifie que le déploiement de Machine Learning utilisera le fichier echo_score.py dans le répertoire ./source_dir pour traiter les demandes entrantes, et utilisera l’image Docker avec les packages Python spécifiés dans l’environnement project_environment.
Vous pouvez utiliser n’importe quel environnement d’inférence Azure Machine Learning organisé comme image Docker de base lors de la création de votre environnement de projet. Nous allons aussi installer les dépendances requises et stocker l’image Docker qui en résulte dans le référentiel associé à votre espace de travail.
Notes
Le chargement du répertoire source de l’inférence de l’apprentissage automatique Azure ne respecte pas .gitignore ni .amlignore.
S’APPLIQUE À :Extension Azure CLI ml v1
Voici une configuration d’inférence minimale possible :
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Enregistrez le fichier sous le nom dummyinferenceconfig.json.
Pour une discussion plus approfondie sur les configurations d’inférence, consultez cet article.
Définir une configuration de déploiement
Une configuration de déploiement spécifie la quantité de mémoire et de cœurs dont votre service web a besoin pour s’exécuter. Elle fournit également des détails sur la configuration du service web sous-jacent. Par exemple, une configuration de déploiement vous permet de spécifier que votre service nécessite 2 gigaoctets de mémoire, 2 cœurs d’UC, 1 cœur GPU et que vous souhaitez activer la mise à l’échelle automatique.
Les options disponibles pour une configuration de déploiement varient en fonction de la cible de calcul que vous choisissez. Dans un déploiement local, tout ce que vous pouvez spécifier est le port sur lequel votre service web sera traité.
S’APPLIQUE À :Extension Azure CLI ml v1
Les entrées dans le document deploymentconfig.json correspondent aux paramètres pour LocalWebservice.deploy_configuration. Le tableau suivant décrit le mappage entre les entités dans le document JSON et les paramètres de la méthode :
| Entité JSON | Paramètre de méthode | Description |
|---|---|---|
computeType |
N/D | La cible de calcul. Pour les cibles locales, la valeur doit être local. |
port |
port |
Port local sur lequel exposer le point de terminaison HTTP du service. |
Ce code JSON suivant est un exemple de configuration de déploiement à utiliser avec l’interface CLI :
{
"computeType": "local",
"port": 32267
}
Enregistrez ce code JSON dans un fichier nommé deploymentconfig.json.
Pour plus d’informations, consultez le schéma de déploiement.
Déployer votre modèle Machine Learning
Vous êtes maintenant prêt à déployer votre modèle.
S’APPLIQUE À :Extension Azure CLI ml v1
Remplacez bidaf_onnx:1 par le nom et le numéro de version de votre modèle.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Appeler votre modèle
Vérifions que votre modèle d’écho a été correctement déployé. Vous deviez être en mesure d’effectuer une requête d’activité simple, ainsi qu’une requête de scoring :
S’APPLIQUE À :Extension Azure CLI ml v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Définir un script d’entrée
Il est maintenant temps de charger votre modèle. Tout d’abord, modifiez votre script d’entrée :
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Enregistrez ce fichier en tant que score.py à l’intérieur de source_dir.
Notez l’utilisation de la variable d’environnement AZUREML_MODEL_DIR pour rechercher votre modèle inscrit. Vous avez maintenant ajouté des packages pip.
S’APPLIQUE À :Extension Azure CLI ml v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Enregistrez ce fichier sous inferenceconfig.json.
Déployer à nouveau et appeler votre service
Déployez votre service :
S’APPLIQUE À :Extension Azure CLI ml v1
Remplacez bidaf_onnx:1 par le nom et le numéro de version de votre modèle.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Ensuite, assurez-vous que vous pouvez envoyer une demande de publication au service :
S’APPLIQUE À :Extension Azure CLI ml v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Choisir une cible de calcul
La cible de calcul que vous utilisez pour héberger votre modèle aura une incidence sur le coût et la disponibilité de votre point de terminaison déployé. Utilisez ce tableau pour choisir une cible de calcul appropriée.
| Cible de calcul | Utilisé pour | Prise en charge GPU | Description |
|---|---|---|---|
| Service web local | Test/débogage | Pour les tests et la résolution des problèmes limités. L’accélération matérielle dépend de l’utilisation de bibliothèques dans le système local. | |
| Points de terminaison Azure Machine Learning (SDK/CLI v2 uniquement) | Inférence en temps réel Inférence par lots |
Oui | Calculs complètement managés pour le scoring en temps réel (points de terminaison en ligne managés) et par lots (points de terminaison de lot) sur le calcul serverless. |
| Azure Machine Learning Kubernetes | Inférence en temps réel Inférence par lots |
Oui | Exécuter des charges de travail d’inférence sur des clusters Kubernetes locaux, cloud et de périphérie. |
| Azure Container Instances (SDK/CLI v1 uniquement) | Inférence en temps réel Recommandé à des fins de développement et de test uniquement. |
Pour les charges de travail à faible échelle basées sur le processeur qui nécessitent moins de 48 Go de RAM. Ne vous oblige pas à gérer un cluster. Pris en charge dans le concepteur. |
Notes
Lors du choix d’une référence (SKU) de cluster, effectuez un scale-up, puis un scale-out. Commencez avec une machine disposant de 150 % de la RAM dont votre modèle a besoin, profilez le résultat et recherchez une machine présentant le niveau de performance dont vous avez besoin. Une fois celle-ci trouvée, augmentez le nombre de machine en fonction de vos besoins en matière d’inférence simultanée.
Notes
Les instances de conteneur nécessitent le Kit de développement logiciel (SDK) ou CLI v1, et sont adaptées uniquement aux petits modèles d’une taille inférieure à 1 Go.
Déployer dans le cloud
Une fois que vous avez confirmé que votre service fonctionne localement et choisi une cible de calcul à distance, vous êtes prêt à effectuer le déploiement dans le cloud.
Modifiez votre configuration de déploiement pour qu’elle corresponde à la cible de calcul que vous avez choisie, dans ce cas Azure Container Instances :
S’APPLIQUE À :Extension Azure CLI ml v1
Les options disponibles pour une configuration de déploiement varient en fonction de la cible de calcul que vous choisissez.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Enregistrez ce fichier en tant que re-deploymentconfig.json.
Pour plus d’informations, consultez cette référence.
Déployez votre service :
S’APPLIQUE À :Extension Azure CLI ml v1
Remplacez bidaf_onnx:1 par le nom et le numéro de version de votre modèle.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Pour afficher les journaux de service, utilisez la commande suivante :
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Appeler votre service d’accès à distance
Lorsque vous déployez à distance, l’authentification de clé peut être activée. L’exemple ci-dessous montre comment obtenir votre clé de service avec Python afin d’effectuer une demande d’inférence.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Consultez l’article sur les applications clientes pour utiliser des services web pour d’autres exemples de clients dans d’autres langues.
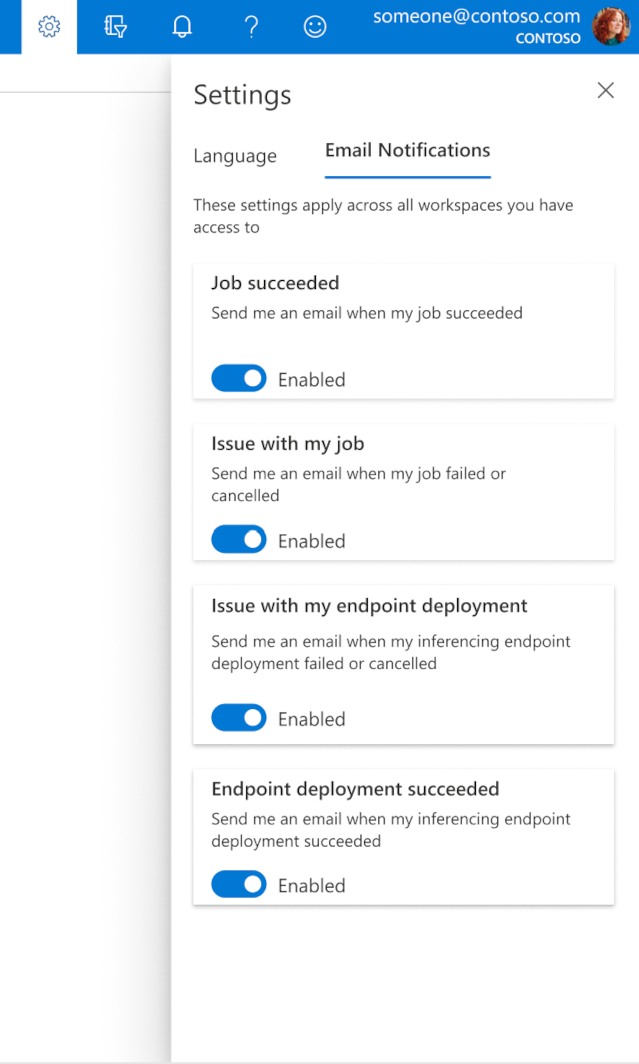
Comment configurer des e-mails dans studio
Pour commencer à recevoir des e-mails lorsque votre travail, point de terminaison en ligne ou point de terminaison de lot est terminé ou s’il existe un problème (échec, annulation), suivez les instructions suivantes :
- Dans Azure ML Studio, accédez aux paramètres en sélectionnant l’icône d’engrenage.
- Sélectionnez l’onglet Notifications par e-mail.
- Activez ou désactivez les notifications par e-mail pour un événement spécifique.
Fonctionnement de l’état du service
Pendant le déploiement du modèle, vous pouvez voir le changement de l’état du service lors de son déploiement complet.
Le tableau ci-après décrit les différents états de service :
| État du service web | Description | État final ? |
|---|---|---|
| Transition | Le service est en cours de déploiement. | Non |
| Unhealthy | Le service a été déployé, mais est actuellement inaccessible. | Non |
| Non planifiable | Le service ne peut pas être déployé pour l’instant en raison d’un manque de ressources. | Non |
| Échec | Le déploiement du service a échoué en raison d’une erreur ou d’un plantage. | Oui |
| Healthy | Le service est sain et le point de terminaison est disponible. | Oui |
Conseil
Lors du déploiement, les images Docker pour les cibles de calcul sont créées et chargées à partir d’Azure Container Registry (ACR). Par défaut, Azure Machine Learning crée un registre ACR du niveau de service De base. Un passage au niveau Standard ou Premium du registre ACR de l’espace de travail est susceptible de réduire le temps nécessaire à la génération et au déploiement des images dans les cibles de calcul. Pour plus d’informations, consultez Niveaux de service pour Azure Container Registry.
Notes
Si vous déployez un modèle sur Azure Kubernetes Service (AKS), nous vous conseillons d’activer Azure Monitor pour ce cluster. Vous pourrez ainsi mieux appréhender dans leur globalité l’intégrité du cluster et l’utilisation des ressources. Voici également quelques ressources pouvant vous être utiles :
- Rechercher les événements Resource Health qui ont un impact sur votre cluster AKS
- Diagnostics d’Azure Kubernetes Service
Si vous essayez de déployer un modèle sur un cluster défectueux ou surchargé, des problèmes sont à prévoir. Si vous avez besoin d’aide pour résoudre des problèmes de cluster AKS, contactez le support technique AKS.
Supprimer des ressources
S’APPLIQUE À :Extension Azure CLI ml v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Pour supprimer un service web déployé, utilisez az ml service delete <name of webservice>.
Pour supprimer de votre espace de travail un modèle inscrit, utilisez az ml model delete <model id>
Apprenez-en davantage sur la suppression d’un service web et la suppression d’un modèle.
Étapes suivantes
- Résoudre des problèmes d’échec de déploiement
- Mettre à jour un service web
- Déploiement en un clic pour les exécutions de ML automatisé dans Azure Machine Learning studio
- Utiliser TLS pour sécuriser un service web par le biais d’Azure Machine Learning
- Superviser vos modèles Azure Machine Learning avec Application Insights
- Créer des alertes d’événement et des déclencheurs pour les déploiements de modèle