Tutoriel : Entraîner et déployer un modèle de classification d’images avec un exemple Jupyter Notebook
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Dans ce tutoriel, vous allez entraîner un modèle Machine Learning sur des ressources de calcul distantes. Vous allez utiliser le workflow d’entraînement et de déploiement pour Azure Machine Learning dans un notebook Jupyter Notebook en Python. Vous pourrez ensuite utiliser le bloc-notes en tant que modèle pour entraîner votre propre modèle Machine Learning avec vos propres données.
Ce tutoriel montre comment effectuer l’entraînement d’une régression logistique simple à l’aide du jeu de données MNIST et de scikit-learn avec Azure Machine Learning. MNIST est un jeu de données populaire composé de 70 000 images en nuances de gris. Chaque image est un chiffre manuscrit de 28 x 28 pixels, représentant un nombre de zéro à neuf. L’objectif est de créer un classifieur multiclasse pour identifier le chiffre représenté par une image donnée.
Découvrez comment effectuer les actions suivantes :
- Télécharger un jeu de données et examiner les données.
- Entraîner un modèle de classification d’images et journaliser les métriques avec MLflow.
- Déployer le modèle pour effectuer une inférence en temps réel.
Prérequis
- Suivez le guide Démarrage rapide : Bien démarrer avec Azure Machine Learning pour :
- Créez un espace de travail.
- Créer une instance de calcul basée sur le cloud à utiliser pour votre environnement de développement.
Exécuter un notebook à partir de votre espace de travail
Azure Machine Learning inclut un serveur de notebook cloud dans votre espace de travail, qui vous offre une expérience préconfigurée qui ne nécessite aucune installation. Utilisez votre propre environnement si vous préférez contrôler votre environnement, vos packages et vos dépendances.
Cloner un dossier de notebooks
Vous effectuez la configuration d’expérience suivante et vous exécutez les étapes indiquées dans le studio Azure Machine Learning. Cette interface centralisée comprend des outils Machine Learning permettant de mettre en œuvre des scénarios de science des données pour les utilisateurs de science des données de tous niveaux de compétences.
Connectez-vous au studio Azure Machine Learning.
Sélectionnez votre abonnement et l’espace de travail que vous avez créé.
Sur la gauche, sélectionnez Notebooks.
En haut, sélectionnez l’onglet Exemples.
Ouvrez le dossier SDK v1.
Sélectionnez le bouton ... à droite du dossier tutoriels, puis sélectionnez Cloner.
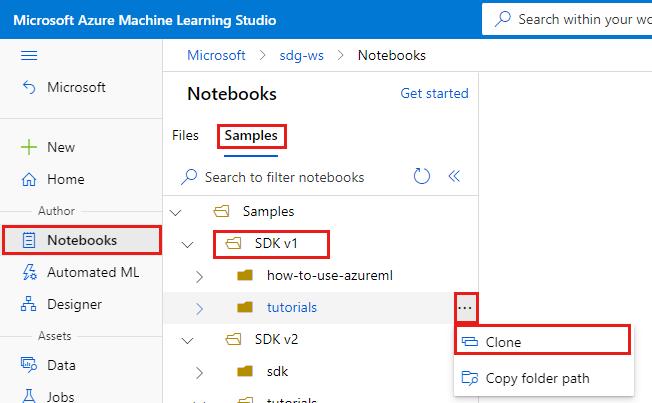
Une liste de dossiers montre tous les utilisateurs qui accèdent à l’espace de travail. Sélectionnez le dossier où cloner le dossier tutorials.
Ouvrir le notebook cloné
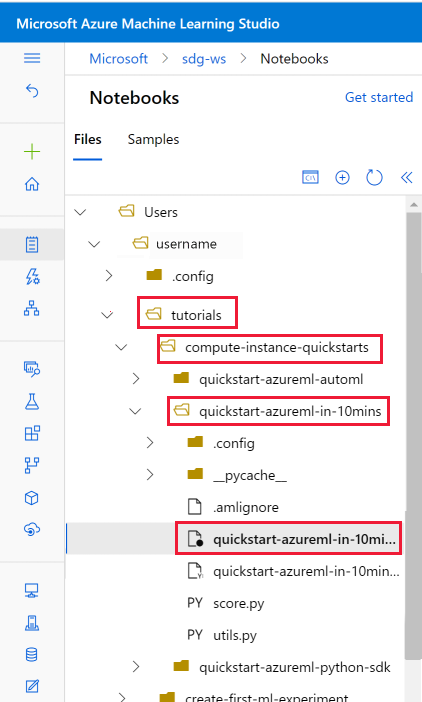
Ouvrez le dossier tutorials qui a été cloné dans la section Fichiers utilisateur.
Sélectionnez le fichier quickstart-azureml-in-10mins.ipynb dans votre dossier tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins.
Installer des packages
Une fois que l’instance de calcul est en cours d’exécution et que le noyau s’affiche, ajoutez une nouvelle cellule de code pour installer les packages nécessaires à ce tutoriel.
En haut du notebook, ajoutez une cellule de code.
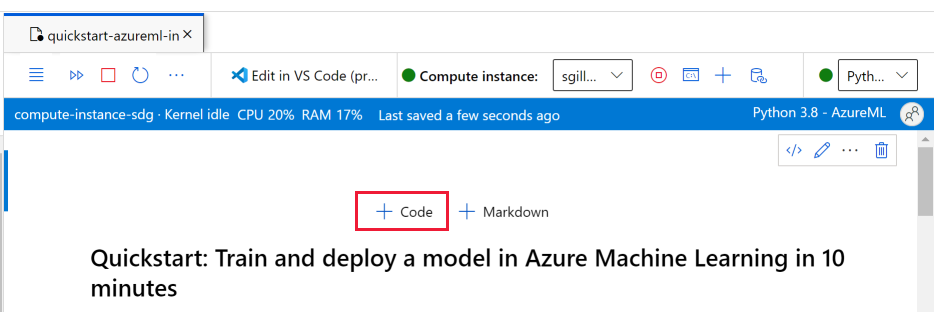
Ajoutez ce qui suit dans la cellule, puis exécutez la cellule, soit à l’aide de l’outil Exécuter, soit à l’aide de Maj+Entrée.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Vous pouvez voir quelques avertissements d’installation. Vous pouvez les ignorer sans problème.
Exécuter le bloc-notes
Vous trouverez également ce tutoriel et le fichier utils.py l’accompagnant sur GitHub si vous souhaitez les utiliser dans votre propre environnement local. Si vous n’utilisez pas l’instance de calcul, ajoutez %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib à l’installation ci-dessus.
Important
Le reste de cet article contient le même contenu que ce que vous voyez dans le notebook.
Basculez maintenant vers le notebook Jupyter si vous voulez exécuter le code à mesure que vous lisez. Pour exécuter une seule cellule de code dans un notebook, cliquez sur celle-ci et appuyez sur Maj + Entrée. Sinon, exécutez l’intégralité du notebook en choisissant Run all (Tout exécuter) dans la barre d’outils supérieure.
Importer des données
Avant d’entraîner un modèle, vous devez comprendre les données que vous utilisez pour l’entraîner. Dans cette section, découvrez comment :
- Télécharger le jeu de données MNIST
- Afficher des exemples d’images
Vous allez utiliser Azure Open Datasets pour récupérer les fichiers de données MNIST bruts. Les jeux de données Azure Open Datasets sont des jeux de données publics organisés que vous pouvez utiliser pour ajouter des caractéristiques spécifiques à des scénarios dans des solutions de Machine Learning afin d'obtenir de meilleurs modèles. Chaque jeu de données a une classe correspondante, MNIST dans ce cas, pour récupérer les données de différentes façons.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Examiner les données
Chargez les fichiers compressés dans des tableaux numpy. Utilisez ensuite matplotlib pour tracer 30 images aléatoires du jeu de données avec leurs étiquettes au-dessus.
Cette étape nécessite une fonction load_data qui est incluse dans un fichier utils.py. Ce fichier se trouve dans le même dossier que ce notebook. La fonction load_data analyse les fichiers compressés dans des tableaux Numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Le code ci-dessus affiche un ensemble aléatoire d’images avec leurs étiquettes, qui ressemble à ceci :

Entraîner les modèles et journaliser les métriques avec MLflow
Vous allez entraîner le modèle à l’aide du code ci-dessous. Notez que vous utilisez la journalisation automatique MLflow pour suivre les métriques et journaliser les artefacts de modèle.
Vous allez utiliser le classifieur LogisticRegression du framework SciKit Learn pour classifier les données.
Notes
L’entraînement du modèle prend environ 2 minutes.**
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Afficher une expérience
Dans le menu de gauche du studio Azure Machine Learning, sélectionnez Tâches, puis sélectionnez votre tâche (azure-ml-in10-mins-tutorial). Une tâche est un regroupement d’un grand nombre d’exécutions d’un script ou d’un morceau de code spécifié. Plusieurs tâches peuvent être regroupées en tant qu’expérience.
Les informations concernant l’exécution sont stockées sous cette tâche. Si le nom n’existe pas lorsque vous soumettez une tâche, si vous sélectionnez votre exécution, vous verrez différents onglets contenant des métriques, des journaux, des explications, etc.
Gestion de versions de vos modèles avec le registre de modèles
Vous pouvez utiliser l’inscription de modèles pour stocker et versionner vos modèles dans votre espace de travail. Les modèles inscrits sont identifiés par leur nom et par leur version. Chaque fois que vous inscrivez un modèle portant le même nom qu’un modèle existant, le registre incrémente la version. Le code ci-dessous inscrit et versionne le modèle que vous avez entraîné ci-dessus. Une fois que vous avez exécuté la cellule de code ci-dessous, vous pouvez voir le modèle dans le registre en sélectionnant Modèles dans le menu de gauche du studio Azure Machine Learning.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Déployer le modèle pour effectuer une inférence en temps réel
Dans cette section, vous allez apprendre à déployer un modèle afin qu’une application puisse consommer (inférence) le modèle sur REST.
Créer une configuration de déploiement
La cellule de code obtient un environnement organisé, qui spécifie toutes les dépendances requises pour héberger le modèle (par exemple, les packages comme scikit-learn). De plus, vous créez une configuration de déploiement, qui spécifie la quantité de calcul nécessaire pour héberger le modèle. Dans le cas présent, le calcul a 1 CPU et 1 Go de mémoire.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-0.24.1-ubuntu18.04-py37-cpu-inference",
version=1
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Déployer un modèle
Cette prochaine cellule de code déploie le modèle dans Azure Container Instance.
Notes
Le déploiement prend environ 3 minutes.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Le fichier de script de scoring référencé dans le code ci-dessus se trouve dans le même dossier que ce notebook et a deux fonctions :
- Une fonction
initqui s’exécute une fois au démarrage du service - dans cette fonction, vous récupérez normalement le modèle à partir du registre et définissez des variables globales. - Une fonction
run(data)qui s’exécute chaque fois qu’un appel est adressé au service. Dans cette fonction, vous devez mettre en forme les données d’entrée, exécuter une prédiction et générer le résultat prédit.
Afficher le point de terminaison
Une fois que le modèle a été déployé avec succès, vous pouvez afficher le point de terminaison en accédant à Points de terminaison dans le menu de gauche du studio Azure Machine Learning. Vous pourrez voir l’état du point de terminaison (sain/non sain), les journaux et la consommation (comment les applications peuvent consommer le modèle).
Tester le service du modèle
Vous pouvez tester le modèle en envoyant une requête HTTP brute pour tester le service web.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Nettoyer les ressources
Si vous n’envisagez pas de continuer à utiliser ce modèle, supprimez le service du modèle avec :
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Si vous souhaitez davantage maîtriser les coûts, arrêtez l’instance de calcul en sélectionnant le bouton « Arrêter le calcul » à côté de la liste déroulante Calcul. Ensuite, redémarrez l’instance de calcul la prochaine fois que vous en avez besoin.
Tout supprimer
Utilisez ces étapes pour supprimer votre espace de travail Azure Machine Learning et toutes les ressources de calcul.
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans le portail Azure, sélectionnez Groupes de ressources tout à gauche.
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
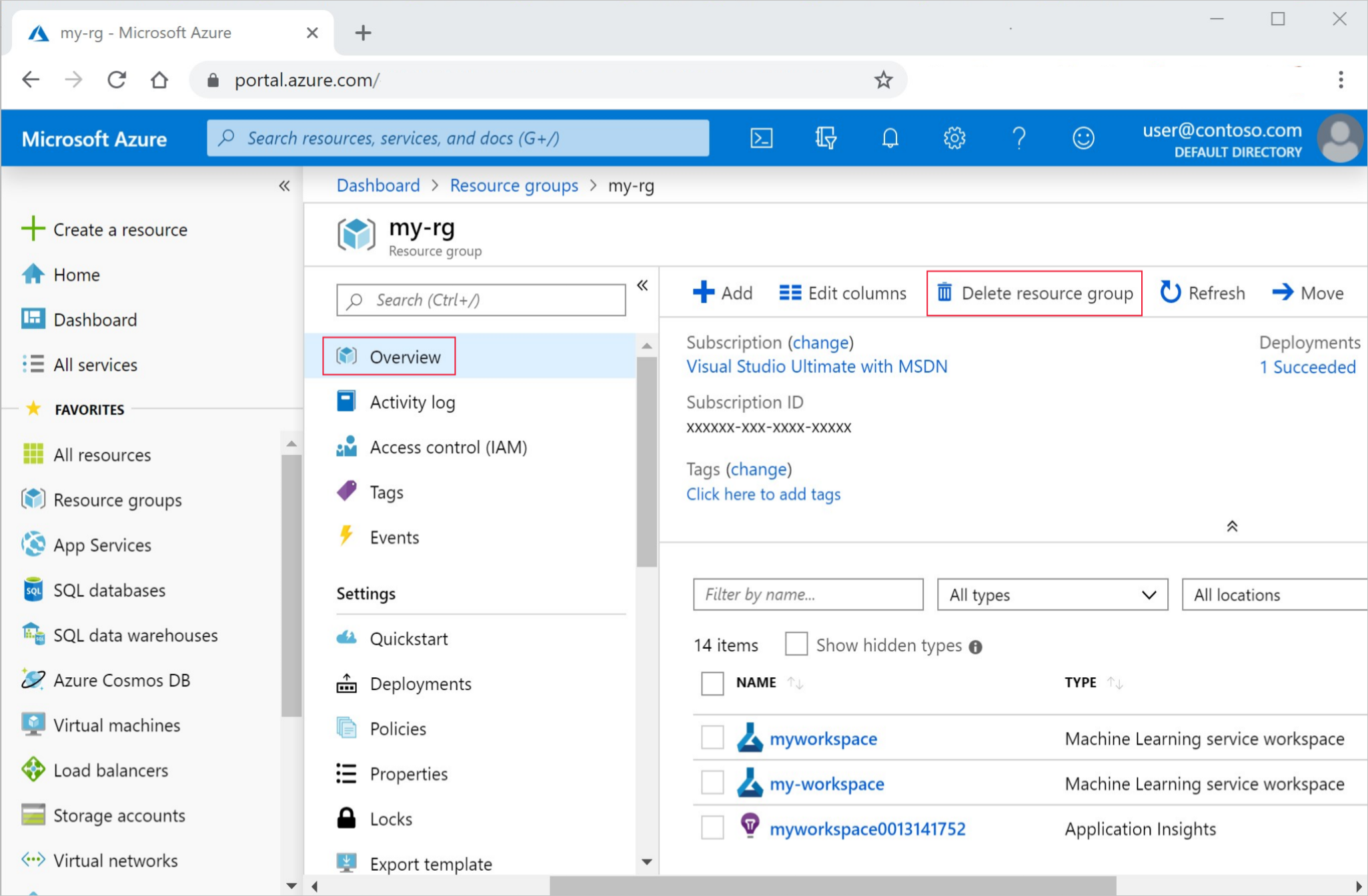
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
- Découvrez toutes les options de déploiement d’Azure Machine Learning.
- Découvrez comment s’authentifier auprès du modèle déployé.
- Effectuez des prédictions sur de grandes quantités de données de façon asynchrone.
- Supervisez vos modèles Azure Machine Learning avec Application Insights.