Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans la mesure du possible, nous vous recommandons d’utiliser la réplication native Apache Cassandra pour migrer des données de votre cluster actuel vers Azure Managed Instance pour Apache Cassandra en configurant un cluster hybride. Cette approche utilise le protocole de bavardage d’Apache Cassandra pour répliquer des données de votre centre de données source vers votre nouveau centre de données d’instance gérée. Toutefois, il peut y avoir des scénarios dans lesquels la version de la base de données source n’est pas compatible, ou une configuration de cluster hybride n’est pas possible.
Ce tutoriel explique comment migrer des données vers Azure Managed Instance pour Apache Cassandra en mode hors connexion avec le connecteur Spark Cassandra et Azure Databricks pour Apache Spark.
Prérequis
Approvisionnez un cluster Azure Managed Instance pour Apache Cassandra à l’aide du portail Azure ou d’Azure CLI, et assurez-vous que vous pouvez vous connecter à votre cluster avec CQLSH.
Approvisionnez un compte Azure Databricks à l’intérieur de votre réseau virtuel Cassandra géré. Veillez à ce qu’il dispose également d’un accès réseau à votre cluster Cassandra source.
Assurez-vous que vous avez déjà migré l’espace de clés/le schéma de table de votre base de données Cassandra source vers votre base de données Cassandra Managed Instance cible.
Provisionner un cluster Azure Databricks
Nous vous recommandons de sélectionner le runtime Databricks version 7.5, qui prend en charge Spark 3.0.
Ajout de dépendances
Ajoutez la bibliothèque du connecteur Apache Spark Cassandra à votre cluster pour vous connecter aux points de terminaison Cassandra natifs et Azure Cosmos DB. Dans votre cluster, sélectionnez Bibliothèques>Installer nouveau>Maven, puis ajoutez com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 dans les coordonnées Maven.
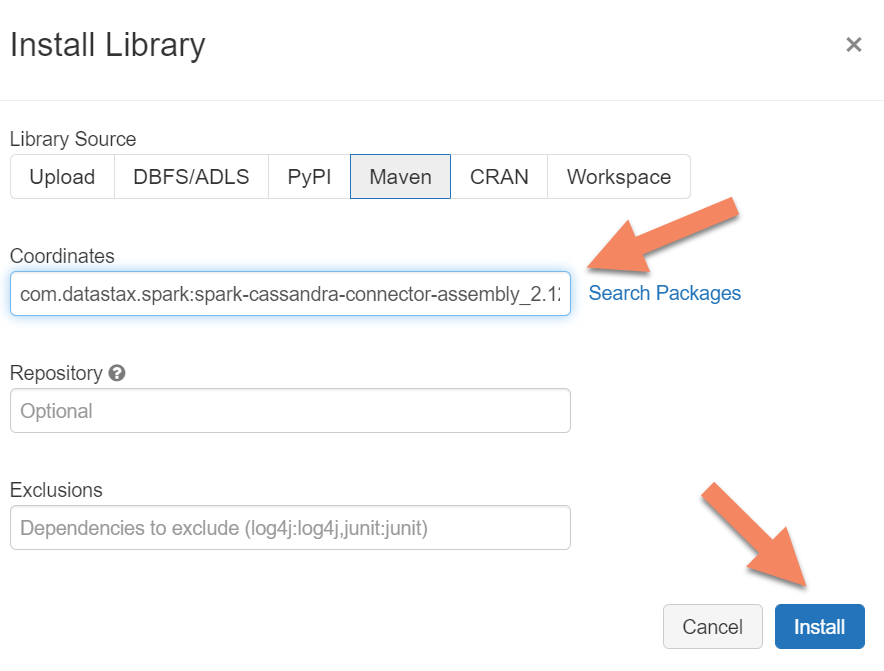
Sélectionnez Installer, puis redémarrez le cluster une fois l’installation terminée.
Notes
Veillez à redémarrer le cluster Databricks après l’installation de la bibliothèque du connecteur Cassandra.
Créer un notebook Scala pour la migration
Créez un notebook Scala dans Databricks. Remplacez vos configurations Cassandra source et cible par les informations d’identification correspondantes, ainsi que les espaces de clés et les tables sources et cibles. Exécutez ensuite le code suivant :
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Notes
Si vous avez besoin de préserver le writetime d’origine de chaque ligne, consultez l’exemple cassandra migrator.