Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce guide de démarrage rapide, vous allez apprendre à utiliser une ressource Microsoft Planetary Computer Pro GeoCatalog dans Azure Batch pour traiter des données géospatiales à grande échelle.
Azure Batch est un service de planification de travaux basé sur le cloud qui vous permet d’exécuter des charges de travail de calcul haute performance et parallèles à grande échelle. En combinant Azure Batch avec Microsoft Planetary Computer Pro, vous pouvez :
- Traiter de grands volumes de données géospatiales en parallèle sur plusieurs nœuds de calcul
- S’authentifier en toute sécurité auprès des API GeoCatalog à l’aide d’identités managées
- Mettre à l’échelle la puissance de traitement vers le haut ou vers le bas en fonction des demandes de charge de travail
- Automatiser les pipelines de données géospatiales sans gérer l’infrastructure
Ce guide de démarrage rapide montre comment configurer un pool Batch avec une identité managée affectée par l’utilisateur, configurer des autorisations pour accéder à votre GeoCatalog et exécuter des travaux qui interrogent l’API STAC.
Conseil / Astuce
Pour obtenir une vue d’ensemble des options de développement d’applications avec Microsoft Planetary Computer Pro, consultez Se connecter et créer des applications avec vos données.
Conditions préalables
Avant de commencer, vérifiez que vous répondez aux exigences suivantes pour suivre ce guide de démarrage rapide :
- Un compte Azure avec un abonnement actif. Utilisez le lien Créer un compte gratuitement.
- Ressource Microsoft Planetary Computer Pro GeoCatalog.
Une machine Linux avec les outils suivants installés :
- Azure CLI
-
package
perl.
Création d’un compte Batch
Créez un groupe de ressources :
az group create \
--name spatiobatchdemo \
--location uksouth
Créez un compte de stockage :
az storage account create \
--resource-group spatiobatchdemo \
--name spatiobatchstorage \
--location uksouth \
--sku Standard_LRS
Affectez Storage Blob Data Contributor à l’utilisateur actuel au compte de stockage :
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $(az account show --query user.name -o tsv) \
--scope $(az storage account show --name spatiobatchstorage --resource-group spatiobatchdemo --query id -o tsv)
Créez un compte Batch :
az batch account create \
--name spatiobatch \
--storage-account spatiobatchstorage \
--resource-group spatiobatchdemo \
--location uksouth
Important
Vérifiez que vous disposez d’un quota suffisant pour créer un pool de nœuds d’ordinateur. Si vous n’avez pas suffisamment de quota, vous pouvez demander une augmentation en suivant les instructions de la documentation sur les quotas et limites Azure Batch .
Connectez-vous au nouveau compte Batch en exécutant la commande suivante :
az batch account login \
--name spatiobatch \
--resource-group spatiobatchdemo \
--shared-key-auth
Une fois que vous authentifiez votre compte avec Batch, les commandes suivantes az batch de cette session utilisent le compte Batch que vous avez créé.
Créer une identité managée assignée par l'utilisateur :
az identity create \
--name spatiobatchidentity \
--resource-group spatiobatchdemo
Créez un pool de nœuds de calcul à l’aide du portail Azure :
- Dans le portail Azure, accédez à votre compte Batch et sélectionnez Pools :

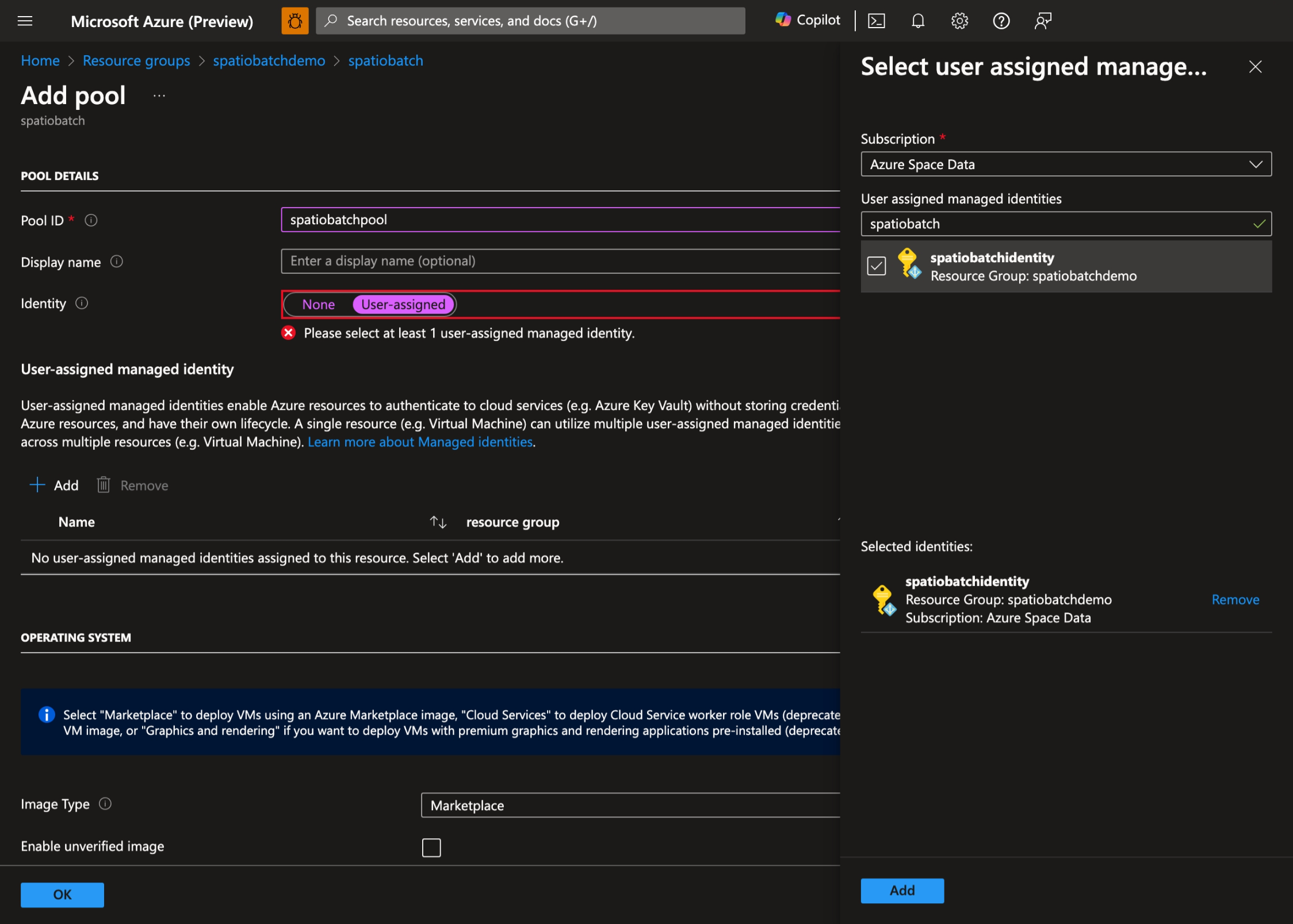
- Sélectionnez + Ajouter pour créer un pool et sélectionnez Utilisateur affecté comme identité du pool :

- Sélectionnez l’identité managée affectée par l’utilisateur que vous avez créée précédemment :
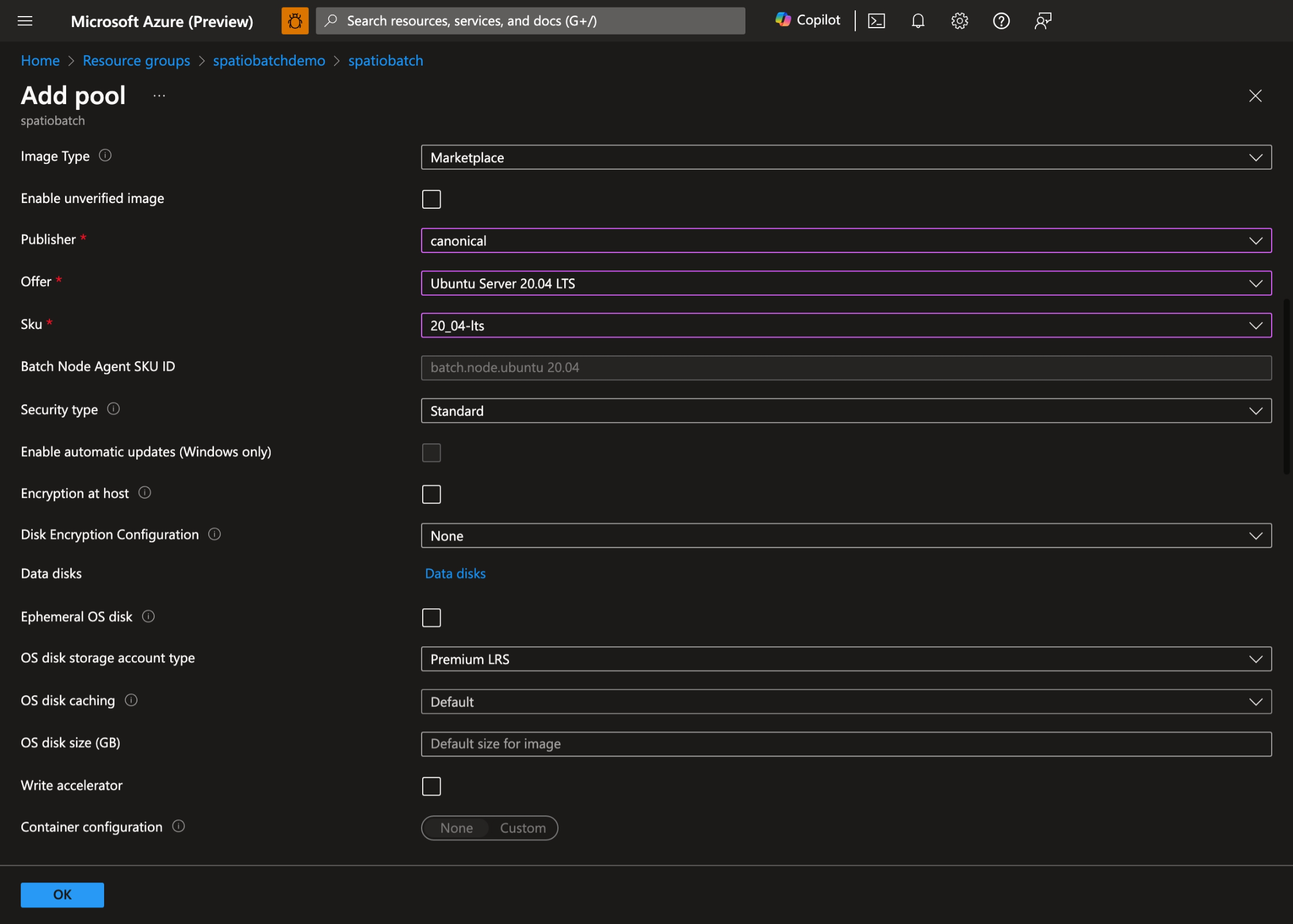
- Sélectionnez votre système d’exploitation et votre taille de machine virtuelle préférés. Dans cette démonstration, nous utilisons Ubuntu Server 20.04 LTS :
- Activez la tâche de démarrage, définissez la ligne de commande suivante :
bash -c "apt-get update && apt-get install jq python3-pip -y && curl -sL https://aka.ms/InstallAzureCLIDeb | bash"et définissez le niveau d’élévation sur l’utilisateur automatique du pool, Admin :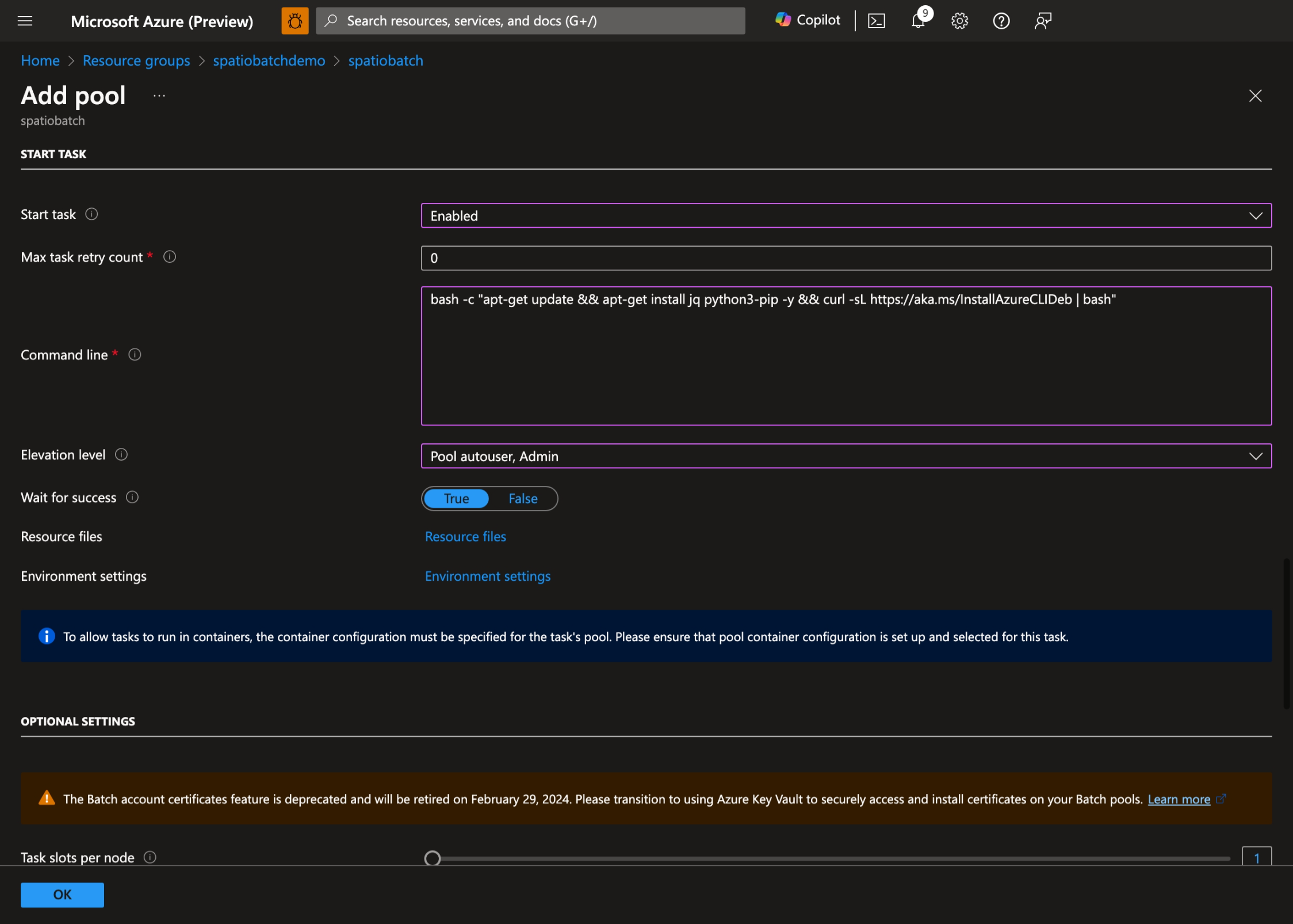
- Sélectionnez OK pour créer le pool.





Attribuer des autorisations à l’identité managée
Vous devez fournir l’accès d’identité managée à GeoCatalog. Accédez à votre GeoCatalog, sélectionnez sur Contrôle d’accès (IAM) et sélectionnez Ajouter une attribution de rôle :

Sélectionnez le rôle approprié en fonction de vos besoins GeoCatalog Administrator , ou GeoCatalog Readersélectionnez Suivant :

Sélectionnez l’identité managée que vous avez créée, puis sélectionnez Vérifier + affecter.

Préparer le travail Batch
Créez un conteneur dans le compte de stockage :
az storage container create \
--name scripts \
--account-name spatiobatchstorage
Chargez le script dans le conteneur :
az storage blob upload \
--container-name scripts \
--file src/task.py \
--name task.py \
--account-name spatiobatchstorage
Exécuter les travaux Batch
Il existe deux exemples dans ce guide de démarrage rapide : un script Python et un script Bash. Vous pouvez utiliser l’un d’eux pour créer un travail.
Travail de script Python
Pour exécuter le travail de script Python, exécutez les commandes suivantes :
geocatalog_url="<geocatalog url>"
token_expiration=$(date -u -d "30 minutes" "+%Y-%m-%dT%H:%M:%SZ")
python_task_url=$(az storage blob generate-sas --account-name spatiobatchstorage --container-name scripts --name task.py --permissions r --expiry $token_expiration --auth-mode login --as-user --full-uri -o tsv)
cat src/pythonjob.json | perl -pe "s,##PYTHON_TASK_URL##,$python_task_url,g" | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Le travail Python exécute le script Python suivant :
import json
from os import environ
import requests
from azure.identity import DefaultAzureCredential
MPCPRO_APP_ID = "https://geocatalog.spatio.azure.com"
credential = DefaultAzureCredential()
access_token = credential.get_token(f"{MPCPRO_APP_ID}/.default")
geocatalog_url = environ["GEOCATALOG_URL"]
response = requests.get(
f"{geocatalog_url}/stac/collections",
headers={"Authorization": "Bearer " + access_token.token},
params={"api-version": "2026-04-15"},
)
print(json.dumps(response.json(), indent=2))
Qui utilise DefaultAzureCredential pour s’authentifier auprès de l’identité managée et récupère les collections à partir de GeoCatalog. Pour obtenir les résultats du travail, exécutez la commande suivante :
az batch task file download \
--job-id pythonjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Travail Bash
Pour exécuter le travail de script Bash, exécutez les commandes suivantes :
geocatalog_url="<geocatalog url>"
cat src/bashjob.json | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
La tâche Bash exécute le script Bash suivant :
az login --identity --allow-no-subscriptions > /dev/null
token=$(az account get-access-token --resource https://geocatalog.spatio.azure.com --query accessToken --output tsv)
curl --header \"Authorization: Bearer $token\" $GEOCATALOG_URL/stac/collections | jq
Qui utilise az login --identity pour s’authentifier auprès de l’identité managée et récupère les collections à partir de GeoCatalog. Pour obtenir les résultats du travail, exécutez la commande suivante :
az batch task file download \
--job-id bashjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Contenu connexe
- Connecter et créer des applications avec vos données
- Configurer l’authentification d’application pour Microsoft Planetary Computer Pro
- Créer une application web avec Microsoft Planetary Computer Pro
- Utiliser l’Explorateur Microsoft Planetary Computer Pro
- Gérer l’accès à Microsoft Planetary Computer Pro
- Configurer des identités managées dans des pools Batch
- Copier des applications et des données vers des nœuds de pool
- Déployer des applications sur des nœuds de calcul avec des packages d’applications Batch
- Création et utilisation de fichiers de ressources