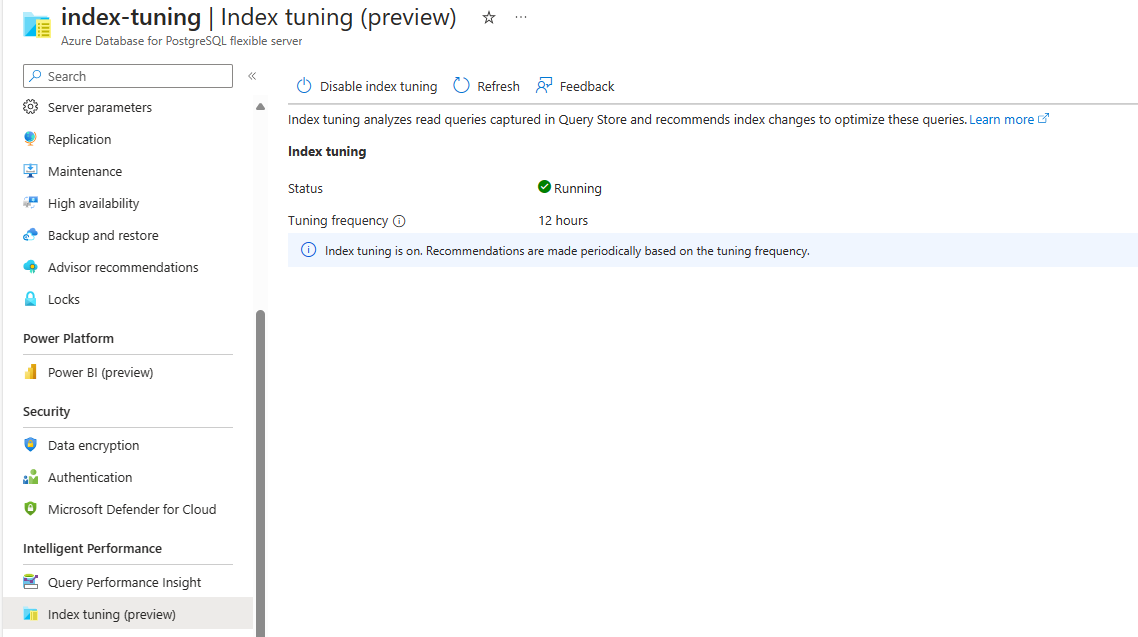
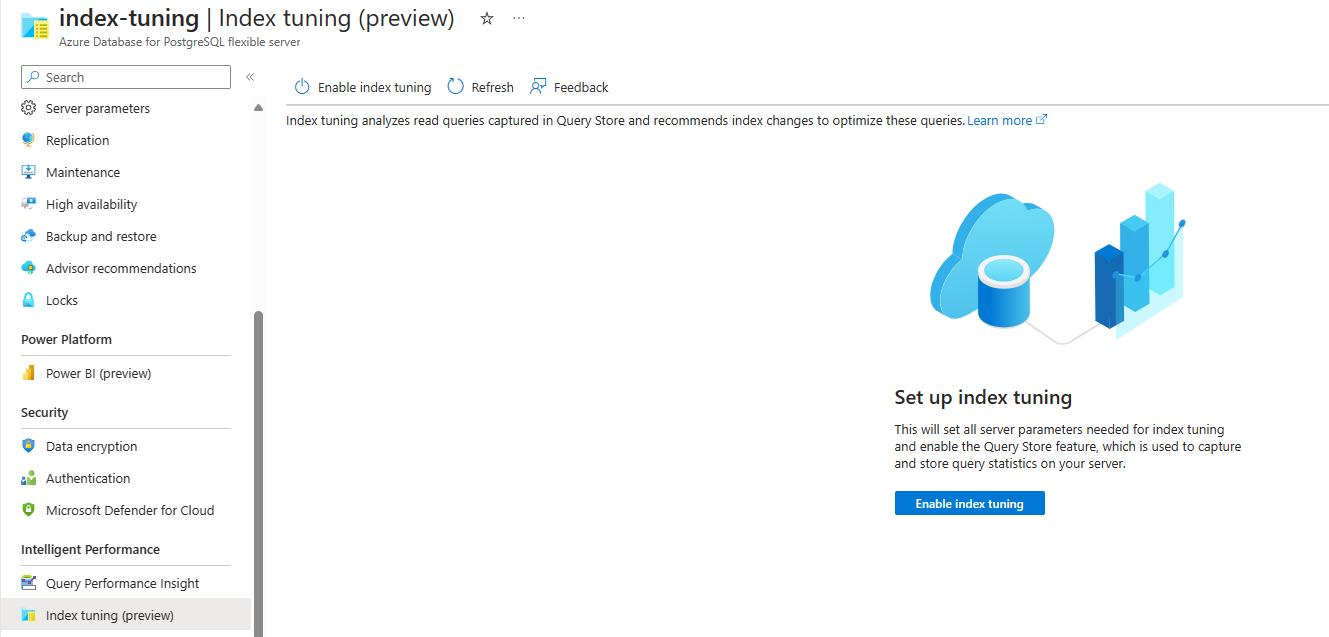
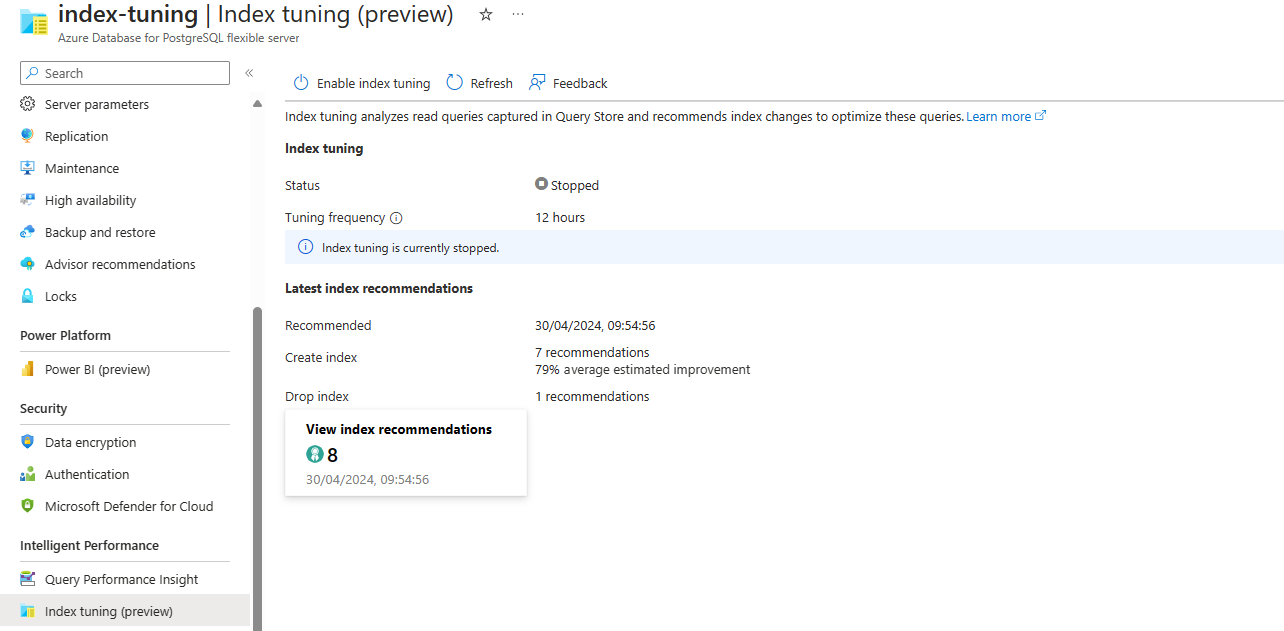
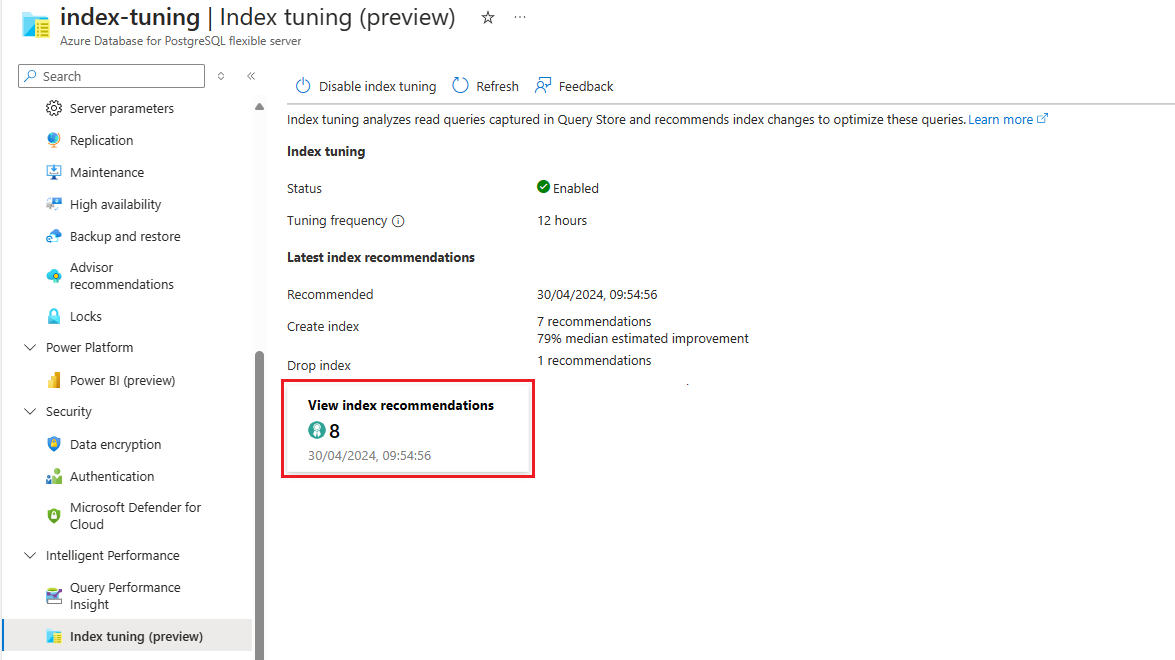
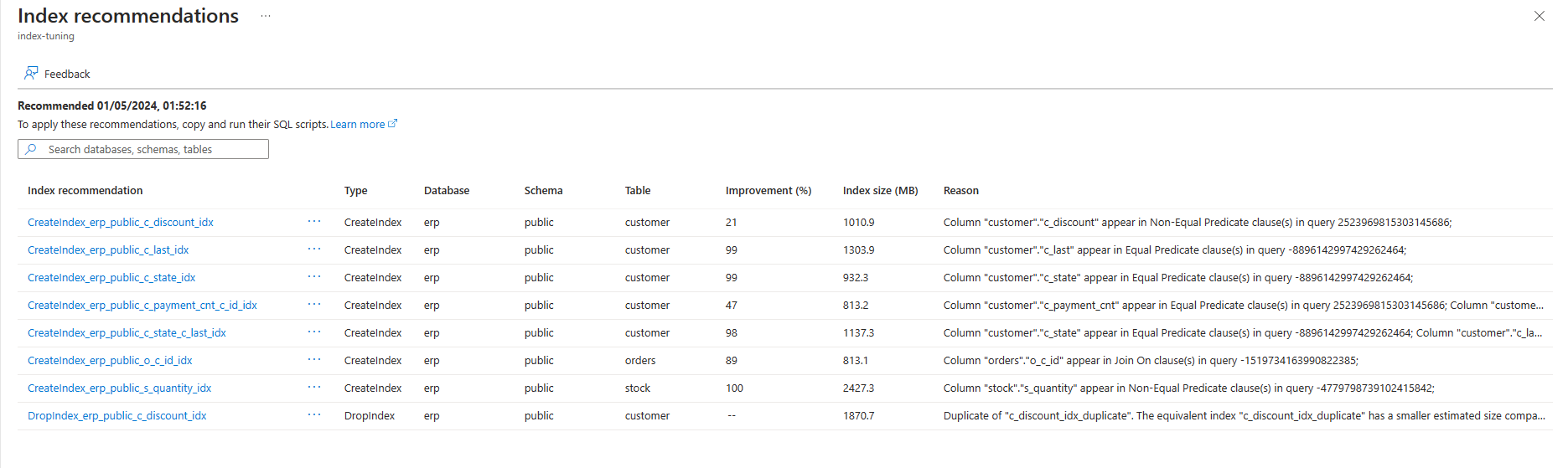
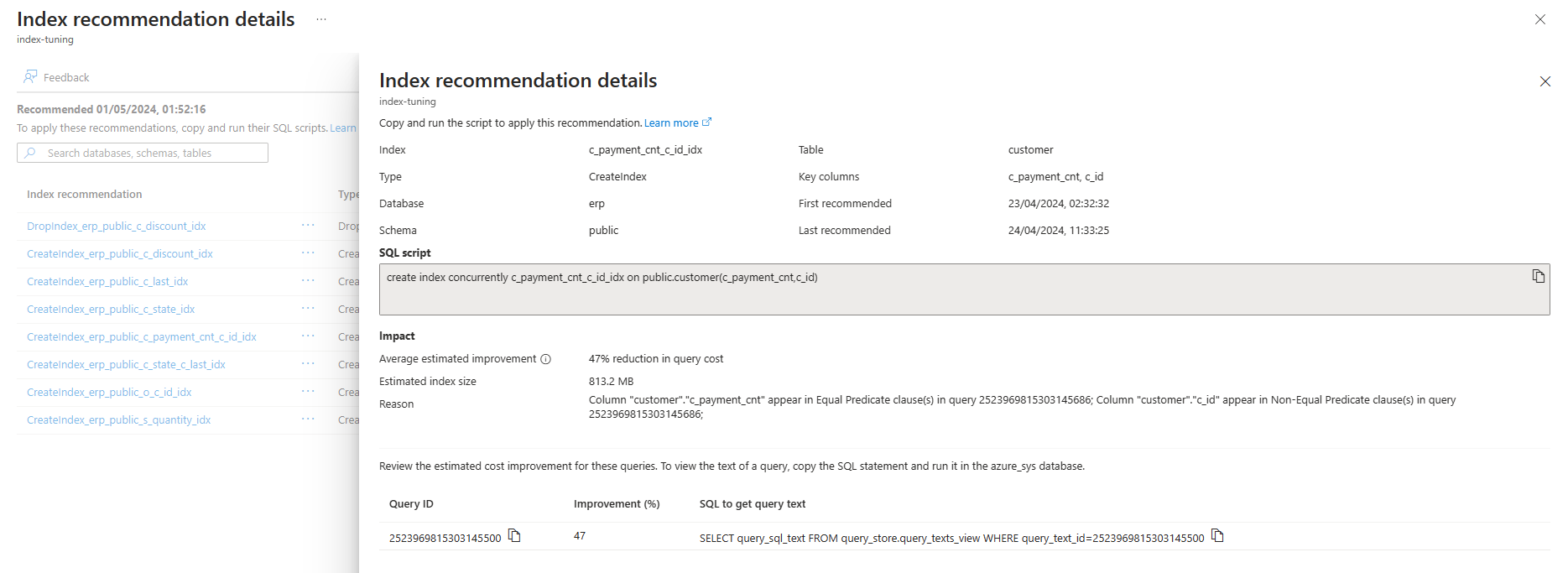
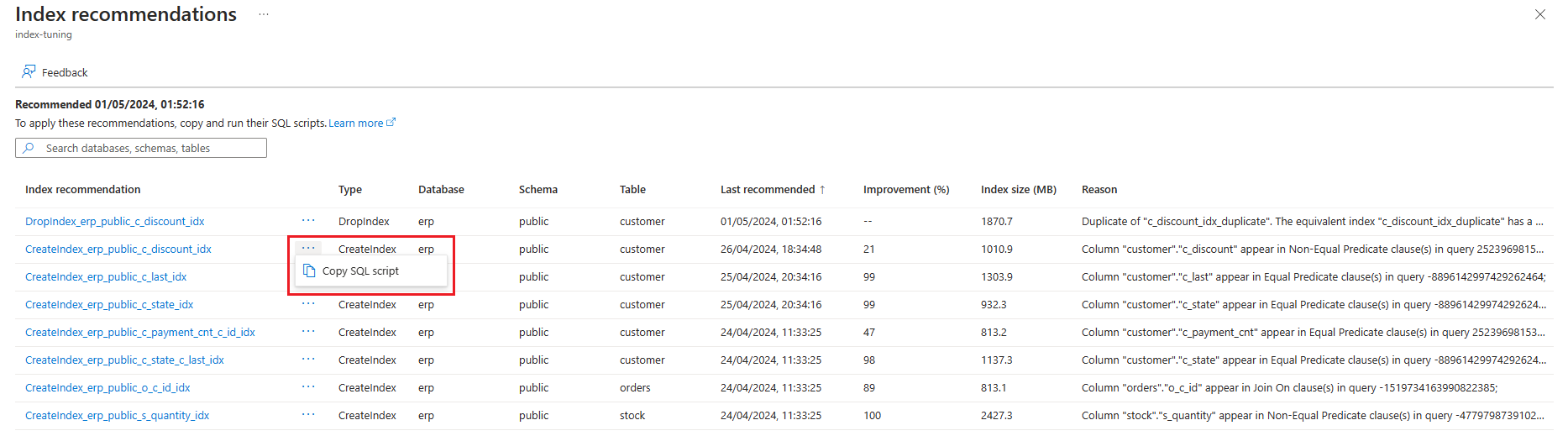
Vous pouvez répertorier les recommandations de paramétrage d’index générées par le réglage d’index dans un serveur existant via la commande az postgres flexible-server index-tuning list-recommendations .
Pour répertorier toutes les recommandations CREATE INDEX, utilisez cette commande :
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type createindex
La commande retourne toutes les informations sur les recommandations CREATE INDEX produites par le réglage d’index, montrant quelque chose de similaire à la sortie suivante :
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T14:40:18.788628+00:00",
"queryCount": 18,
"startTime": "2025-02-26T13:40:18.788628+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "\"<table>\".\"<column>\"",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 0.3984375,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
},
{
"absoluteValue": 62.86969111969111,
"dimensionName": "QueryCostImprovement",
"queryId": -555955670159268890,
"unit": "Percentage"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "create index concurrently <index> on <schema>.<table>(<column>)"
},
"improvedQueryIds": [
-555955670159268890
],
"initialRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"name": "CreateIndex_<database>_<schema>_<column>_idx",
"recommendationReason": "Column \"<table>\".\"<column>\" appear in Equal Predicate clause(s) in query -555955670159268890;",
"recommendationType": "CreateIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Pour répertorier toutes les recommandations DROP INDEX, utilisez cette commande :
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type dropindex
La commande retourne toutes les informations sur les recommandations de suppression d'index générées par le réglage de l'index, présentant un résultat similaire à celui-ci :
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2025-01-22T19:02:47.522193+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "<column>",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 35.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 31.28125,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "drop index concurrently \"<schema>\".\"<index>\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"name": "DropIndex_<database>_<sechema>_<index>",
"recommendationReason": "Duplicate of \"<index>\". The equivalent index \"<index>\" has a shorter length compared to \"<index>\".",
"recommendationType": "DropIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
}
]
Utilisation de n’importe quel outil client PostgreSQL de votre préférence :
Connectez-vous à la base de données azure_sys disponible dans votre serveur avec n’importe quel rôle autorisé à se connecter à l’instance. Les membres du rôle public peuvent lire ces vues.
Exécutez des requêtes sur la vue sessions pour récupérer les détails relatifs aux sessions de recommandation.
Exécutez des requêtes sur la vue recommendations afin de récupérer les recommandations produites par l’optimisation des index pour CREATE INDEX et DROP INDEX.
Vues
Les vues de la base de données azure_sys offrent un moyen pratique d’accéder aux recommandations d’index générées par l’optimisation d’index et de les récupérer. En particulier, les vues createindexrecommendations et dropindexrecommendations contiennent des informations détaillées sur les recommandations CREATE INDEX et DROP INDEX, respectivement. Ces vues affichent des données telles que l’ID de session, le nom de la base de données, le type de conseiller, les heures de début et de fin de la session d’optimisation, l’ID de recommandation, le type de recommandation, le motif de la recommandation et d’autres détails pertinents. Les utilisateurs peuvent interroger ces vues pour accéder facilement aux recommandations d’index produites par le réglage des index et les analyser facilement.
La vue sessions expose tous les détails de toutes les sessions d’optimisation des index.
| nom de colonne |
type de données |
Descriptif |
| identifiant_de_session |
Identifiant unique universel (UUID) |
Identificateur global unique affecté à chaque nouvelle session d’optimisation lancée. |
| nom_de_la_base_de_données |
varchar(64) |
Nom de la base de données dans le contexte de laquelle la session d’optimisation des index a été exécutée. |
| session_type |
intelligentperformance.recommendation_type |
Indique les types de recommandations que cette session d’optimisation des index peut produire. Les valeurs possibles sont les suivantes : CreateIndex, DropIndex. Les sessions de type CreateIndex peuvent produire des recommandations de type CreateIndex. Les sessions de type DropIndex peuvent produire des recommandations de type DropIndex ou ReIndex. |
| type d'exécution |
intelligentperformance.recommendation_run_type |
Indique la façon dont cette session a été lancée. Les valeurs possibles sont les suivantes : Scheduled. Les sessions exécutées automatiquement en fonction de la valeur index_tuning.analysis_interval se voient affecter le type d’exécution Scheduled. |
| état |
intelligentperformance.recommendation_state |
Indique l’état actuel de la session. Les valeurs possibles sont les suivantes : Error, Success, InProgress. Les sessions dont l’exécution a échoué sont définies en tant que Error. Les sessions dont l’exécution s’est correctement effectuée, qu’elles aient généré ou non des recommandations, sont définies en tant que Success. Les sessions qui sont toujours en cours d’exécution sont définies en tant que InProgress. |
| heure de début |
timestamp sans timezone |
Horodatage auquel la session d’optimisation qui a produit cette recommandation a été démarrée. |
| temps d'arrêt |
timestamp sans timezone |
Horodatage auquel la session d’optimisation qui a produit cette recommandation a été démarrée. NULL si la session est en cours ou a été abandonnée en raison d’un échec. |
| nombre_de_recommandations |
entier |
Nombre total de recommandations produites au cours de cette session. |
La vue recommendations expose tous les détails de toutes les recommandations générées dans une session d’optimisation dont les données sont toujours disponibles dans les tables sous-jacentes.
| nom de colonne |
type de données |
Descriptif |
| recommendation_id |
entier |
Numéro qui identifie de manière unique une recommandation dans l’ensemble du serveur. |
| last_known_session_id |
Identifiant unique universel (UUID) |
Chaque session d’optimisation des index se voit affecter un identificateur global unique. La valeur de cette colonne représente celle de la session qui a produit récemment cette recommandation. |
| nom_de_la_base_de_données |
varchar(64) |
Nom de la base de données dans laquelle le contexte a produit la recommandation. |
| type_de_recommandation |
intelligentperformance.recommendation_type |
Indique le type de recommandation produite. Les valeurs possibles sont les suivantes : CreateIndex, DropIndex, ReIndex. |
| temps initial recommandé |
timestamp sans timezone |
Horodatage auquel la session d’optimisation qui a produit cette recommandation a été démarrée. |
| dernier_temps_recommandé |
timestamp sans timezone |
Horodatage auquel la session d’optimisation qui a produit cette recommandation a été démarrée. |
| times_recommended |
entier |
Horodatage auquel la session d’optimisation qui a produit cette recommandation a été démarrée. |
| raison |
texte |
Motif expliquant pourquoi cette recommandation a été produite. |
| contexte_de_recommandation |
json |
Contient la liste des identificateurs de requête pour les requêtes affectées par la recommandation, le type d’index recommandé, le nom du schéma et le nom de la table sur laquelle l’index est recommandé, les colonnes d’index, le nom de l’index et la taille estimée en octets de l’index recommandé. |
Raisons liées aux recommandations de création d’index
Quand l’optimisation des index recommande la création d’un index, elle ajoute au moins l’une des raisons suivantes :
| Motif |
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Raisons liées aux recommandations de suppression d’index
Quand l’optimisation des index identifie des index marqués comme étant non valides, elle propose de les supprimer pour la raison suivante :
The index is invalid and the recommended recovery method is to reindex.
Pour en savoir plus sur la raison et le moment où les index sont marqués comme étant non valides, consultez REINDEX dans la documentation officielle de PostgreSQL.
Raisons liées aux recommandations de suppression d’index
Quand l’optimisation des index détecte un index inutilisé depuis au moins le nombre de jours défini dans index_tuning.unused_min_period, elle propose de le supprimer pour la raison suivante :
The index is unused in the past <days_unused> days.
Quand l’optimisation des index détecte des index dupliqués, elle conserve l’un des doublons, et propose de supprimer l’autre. La raison fournie commence toujours par le texte suivant :
Duplicate of <surviving_duplicate>.
Suivi d’un autre texte qui explique la raison pour laquelle chacun des doublons a été choisi pour la suppression :
| Motif |
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Si l’index est non seulement éligible à la suppression en raison d’une duplication, mais qu’il est également inutilisé depuis au moins le nombre de jours défini dans index_tuning.unused_min_period, le texte suivant est ajouté à la raison :
Also, the index is unused in the past <days_unused> days.