Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous guide dans la migration d’une instance PostgreSQL à partir de vos machines virtuelles locales ou Azure vers Azure Database pour PostgreSQL en mode en ligne.
Le service de migration dans Azure Database pour PostgreSQL est un service complètement managé intégré au Portail Azure et à Azure CLI. Il est conçu pour simplifier votre parcours de migration vers le serveur flexible Azure Database pour PostgreSQL.
- Prérequis
- Effectuer la migration
- Surveiller la migration
- Lancer le basculement
- Vérifier la migration une fois terminée
Prérequis
Pour commencer la migration, vous avez besoin des prérequis suivants :
Avant de commencer la migration avec le service de migration Azure Database pour PostgreSQL, il est important de vérifier que les prérequis suivants, spécialement conçus pour les scénarios de migration en ligne, sont satisfaits.
- Vérifier la version source
- Définir la configuration cible
- Activer la capture des changements de données en tant que source
- Définir la configuration réseau
- Activer les extensions
- Vérifier les paramètres de serveur
- Vérifier les utilisateurs et les rôles
Vérifier la version source
La version du serveur PostgreSQL source doit être 9.5 ou une version ultérieure.
Si la version du serveur PostgreSQL source est inférieure à 9.5, mettez-la à niveau vers la version 9.5 ou ultérieure avant de commencer la migration.
Remarque
Le service de migration dans Azure Database pour PostgreSQL prend en charge les connexions à l’aide de l’adresse IP pour la source Google Cloud SQL pour PostgreSQL. Le format myproject:myregion:myinstance n’est pas pris en charge.
Remarque
- PgOutput est le plug-in de décodage logique par défaut utilisé pour la migration en ligne. Si la version <10 de PostgreSQL source est utilisée, test_decoding plug-in est utilisé.
- test_decoding reçoit WAL par le biais du mécanisme de décodage logique et le décode en représentations textuelles des opérations effectuées.
- Dans Google Cloud SQL pour PostgreSQL, le plug-in test_decoding est préinstallé et prêt pour la réplication logique. Cela vous permet de configurer facilement des emplacements de réplication logique et de diffuser en continu des modifications WAL, ce qui facilite les cas d’usage tels que la capture des changements de données (CDC) ou la réplication vers des systèmes externes.
- Pour plus d’informations sur le plug-in de réplication logique, consultez la documentation PostgreSQL
Définir la configuration cible
- Avant la migration, un serveur flexible Azure Database pour PostgreSQL doit être créé.
- La référence SKU approvisionnée pour le serveur flexible Azure Database pour PostgreSQL doit correspondre à la source.
- Pour créer une base de données Azure pour PostgreSQL, consultez Créer un serveur flexible Azure Database pour PostgreSQL
Activer la capture des changements de données en tant que source
- Le plug-in de décodage logique capture les enregistrements modifiés de la source.
- Pour vous assurer que l’utilisateur de migration dispose des privilèges de réplication nécessaires, exécutez la commande SQL suivante :
ALTER USER <user> WITH REPLICATION;
Accédez à l’instance Google Cloud SQL PostgreSQL dans la console Google Cloud, sélectionnez le nom de l’instance pour ouvrir sa page de détails, sélectionnez le bouton Modifier et, dans la section Indicateurs, modifiez les indicateurs suivants :
- Définissez l’indicateur
cloudsql.logical_decoding = on - Définissez l’indicateur
max_replication_slotssur une valeur supérieure à un. La valeur doit être supérieure au nombre de bases de données sélectionnées pour la migration. - Définissez l’indicateur
max_wal_senderssur une valeur supérieure à un. Elle doit être au moins identique àmax_replication_slots, plus le nombre d’expéditeurs déjà utilisés sur votre instance. - L’indicateur
wal_sender_timeoutmet fin aux connexions de réplication inactives plus longtemps que le nombre spécifié de millisecondes. Définissez la valeur sur 0 (zéro) pour désactiver le mécanisme d’expiration, ce qui constitue un paramètre valide pour la migration.
- Définissez l’indicateur
Dans le serveur flexible cible, afin d’éviter que la migration en ligne ne manque d’espace de stockage pour les journaux, assurez-vous que vous disposez d’un espace de table suffisant en tirant parti d’un disque managé approvisionné. Pour ce faire, désactivez le paramètre
azure.enable_temp_tablespaces_on_local_ssddu serveur pendant la durée de la migration et rétablissez-le dans son état d’origine après la migration.
Définir la configuration réseau
La configuration du réseau est cruciale pour que le service de migration fonctionne. Vérifiez que le serveur PostgreSQL source peut communiquer avec le serveur Azure Database pour PostgreSQL cible. Les configurations réseau suivantes sont essentielles pour une migration réussie.
Pour plus d’informations sur la configuration réseau, consultez le Guide réseau pour le service de migration.
Activer les extensions
Pour garantir la réussite de la migration à l’aide du service de migration dans Azure Database pour PostgreSQL, il peut être nécessaire de vérifier les extensions de votre instance PostgreSQL source. Les extensions fournissent des fonctionnalités qui peuvent être requises pour votre application. Veillez à vérifier les extensions sur l’instance PostgreSQL source avant de lancer le processus de migration.
Dans l’instance cible du serveur flexible Azure Database pour PostgreSQL, activez les extensions prises en charge identifiées dans l’instance PostgreSQL source.
Pour plus d’informations, consultez Extensions et modules.
Vérifier les paramètres de serveur
Ces paramètres ne sont pas automatiquement migrés vers l’environnement cible et doivent être configurés manuellement.
Faites correspondre les valeurs des paramètres du serveur de la base de données PostgreSQL source à Azure Database pour PostgreSQL en accédant à la section « Paramètres du serveur » dans le Portail Azure et en mettant à jour manuellement les valeurs en conséquence.
Enregistrez les modifications apportées aux paramètres et, si nécessaire, redémarrez Azure Database pour PostgreSQL pour appliquer la nouvelle configuration.
Vérifier les utilisateurs et les rôles
Lors de la migration vers Azure Database pour PostgreSQL, il est essentiel de traiter séparément la migration des utilisateurs et des rôles, car une intervention manuelle est nécessaire :
Migration manuelle des utilisateurs et des rôles : les utilisateurs et leurs rôles associés doivent être migrés manuellement vers Azure Database pour PostgreSQL. Pour faciliter ce processus, vous pouvez utiliser l’utilitaire
pg_dumpallavec l’indicateur--globals-onlypour exporter des objets globaux tels que des rôles et des comptes d’utilisateur. Exécutez la commande suivante, en remplaçant<<username>>par le nom d’utilisateur réel et<<filename>>par le nom de fichier de sortie souhaité :pg_dumpall --globals-only -U <<username>> -f <<filename>>.sqlRestriction sur les rôles de superutilisateur : Azure Database pour PostgreSQL ne prend pas en charge les rôles de superutilisateur. Par conséquent, les privilèges de superutilisateur accordés aux utilisateurs doivent être supprimés avant la migration. Veillez à ajuster les autorisations et les rôles en conséquence.
En procédant ainsi, vous pouvez vous assurer que les comptes d’utilisateur et les rôles sont correctement migrés vers Azure Database pour PostgreSQL sans rencontrer de problèmes liés aux restrictions associés aux rôles de superutilisateur.
Désactiver la haute disponibilité (fiabilité) et les réplicas de lecture dans la cible
Il est essentiel de désactiver les réplicas de haute disponibilité (fiabilité) et de lecture dans l’environnement cible. Ces fonctionnalités doivent uniquement être activées une fois la migration terminée.
En procédant ainsi, vous pouvez garantir un processus de migration fluide sans les variables ajoutées introduites par les réplicas de haute disponibilité et de lecture. Une fois la migration terminée et la base de données stable, vous pouvez activer ces fonctionnalités pour améliorer la disponibilité et la scalabilité de votre environnement de base de données dans Azure.
Effectuer la migration
Vous pouvez migrer à l’aide du portail Azure ou d’Azure CLI.
Cet article vous guide à l’aide du portail Azure pour migrer votre base de données PostgreSQL à partir d’un serveur Google Cloud SQL pour PostgreSQL vers une base de données Azure pour PostgreSQL. Le portail Azure vous permet d’effectuer différentes tâches, notamment la migration de base de données. En suivant les étapes décrites dans ce tutoriel, vous pouvez transférer en toute transparence votre base de données vers Azure et tirer parti de ses puissantes fonctionnalités et scalabilité.
Configurer la tâche de migration
Le service de migration inclut une expérience simple basée sur un Assistant sur le Portail Azure.
Utilisation du portail Azure :
Sélectionnez votre serveur flexible Azure Database pour PostgreSQL.
Dans le menu des ressources, sélectionnez Migration.

Sélectionnez Créer pour suivre une série d'onglets guidée par un assistant afin d'effectuer une migration vers un serveur flexible depuis une machine virtuelle sur site ou Azure.
Remarque
La première fois que vous utilisez le service de migration, une grille vide s’affiche avec une invite pour commencer votre première migration.
Si des migrations vers votre cible de serveur flexible ont déjà été créées, la grille contient désormais des informations sur les tentatives de migration.
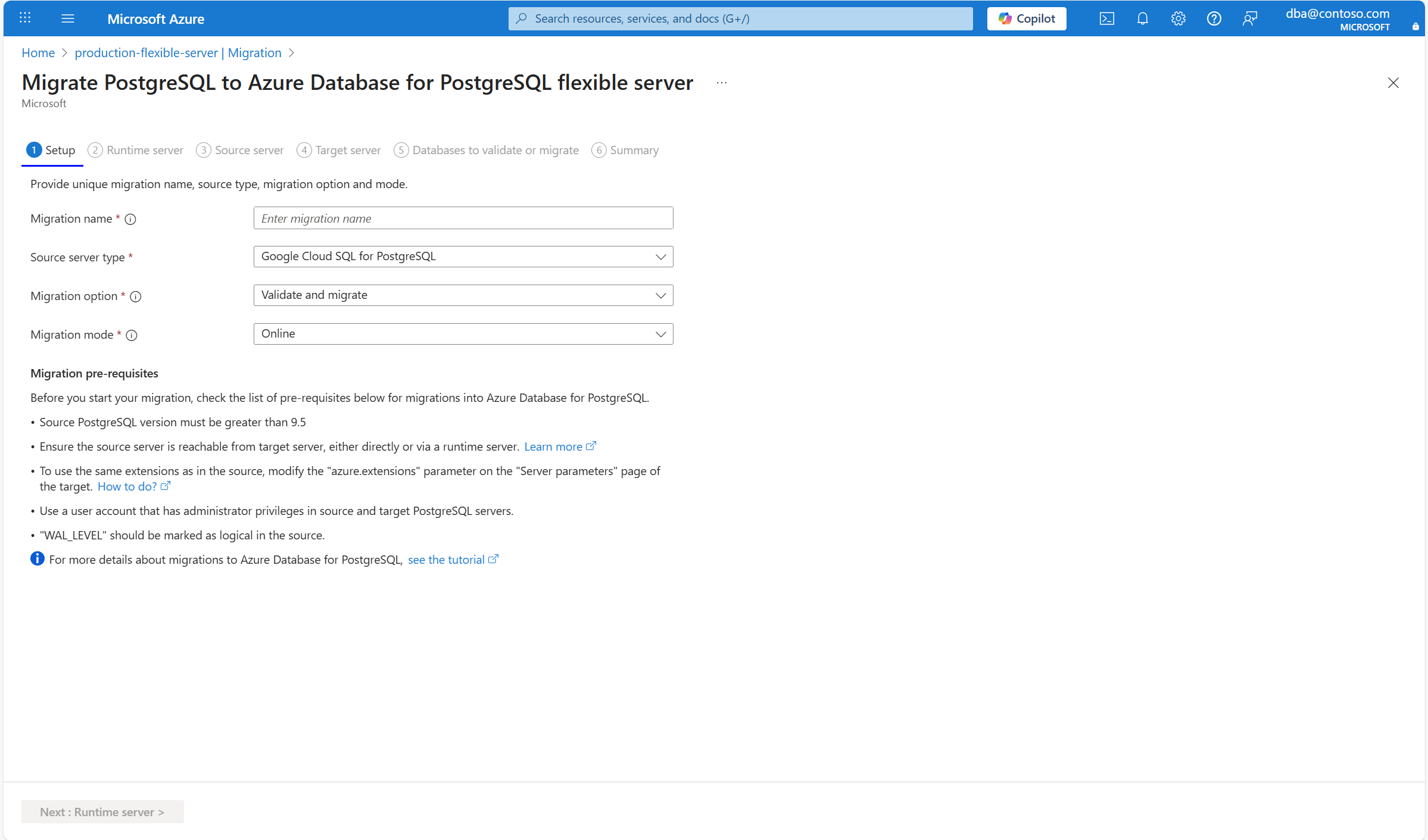


Programme d’installation
Vous devez fournir plusieurs détails liés à la migration, comme le nom de la migration, le type de serveur source, l’option et le mode.
Le nom de la migration est l’identificateur unique de chaque migration vers cette cible de serveur flexible. Ce champ accepte uniquement les caractères alphanumériques et n’accepte aucun caractère spécial à l’exception du trait d’union (-). Le nom ne peut pas commencer par un trait d’union et doit être unique pour un serveur cible. Aucune migration vers la même cible de serveur flexible ne peut avoir le même nom.
Type de serveur source : selon votre source PostgreSQL, vous pouvez sélectionner une machine virtuelle Azure ou un serveur local.
Option de migration : vous permet d’effectuer des validations avant de déclencher une migration. Vous pouvez choisir l’une des options suivantes :
- Valider : vérifie la préparation de votre serveur et de votre base de données pour la migration vers la cible.
- Valider et migrer : effectue la validation avant de déclencher une migration. En l’absence d’échecs de validation, la migration est lancée.
Le choix de l’option Valider ou Valider et migrer est toujours une bonne pratique pour effectuer des validations de prémigration avant d’exécuter la migration.
Pour en savoir plus sur la validation avant migration, consultez la page de prémigration.
- Mode de migration vous permet de choisir le mode de la migration. Hors connexion est l’option par défaut. Dans ce cas, nous allons le remplacer par Online.
Sélectionnez Suivant : Serveur d’exécution.

Serveur d’exécution
Le serveur runtime de migration est une fonctionnalité spécialisée dans le service de migration dans Azure Database pour PostgreSQL, conçue pour agir en tant que serveur intermédiaire pendant la migration. Il s’agit d’une instance de serveur flexible Azure Database pour PostgreSQL distincte qui n’est pas le serveur cible, mais utilisée pour faciliter la migration des bases de données à partir d’un environnement source accessible uniquement via un réseau privé.

Pour plus d’informations sur le serveur d’exécution, visitez le serveur runtime de migration.
Serveur source
L’onglet Serveur source vous invite à fournir des détails relatifs à la source sélectionnée dans l’onglet Installation , qui est la source des bases de données.
- Nom du serveur : indiquez le nom de l’hôte ou l’adresse IP du serveur PostgreSQL source.
- Port : numéro de port du serveur source.
- Connexion administrateur : nom de l’utilisateur administrateur du serveur PostgreSQL source.
- Mot de passe : mot de passe de la connexion administrateur fournie pour se connecter au serveur PostgreSQL source.
-
Mode SSL - Les valeurs prises en charge sont
preferredetrequired. Lorsque le protocole SSL sur le serveur PostgreSQL source estOFF, utilisezprefer. Si le protocole SSL sur le serveur source estON, utilisez lerequire. Les valeurs SSL peuvent être déterminées dans le fichier postgresql.conf du serveur source. - Tester la connexion : effectue le test de connectivité entre la cible et la source. Une fois la connexion établie, vous pouvez passer à l’onglet suivant. Ces tests visent à identifier les problèmes de connectivité qui peuvent exister entre les serveurs cibles et sources, notamment la vérification de l’authentification à l’aide des informations d’identification fournies. L’établissement d’une connexion de test prend quelques secondes.
Une fois la connexion testée réussie, sélectionnez Suivant : Serveur cible.

Serveur cible
L’onglet Serveur cible affiche les métadonnées de la cible de serveur flexible, comme le nom de l’abonnement, le groupe de ressources, le nom du serveur, l’emplacement et la version postgreSQL.
- Connexion administrateur : nom de l’utilisateur administrateur du serveur PostgreSQL cible.
- Mot de passe : mot de passe de la connexion administrateur fournie pour se connecter au serveur PostgreSQL cible.
- Nom de domaine complet personnalisé ou adresse IP : le champ DQDN personnalisé ou adresse IP est facultatif et peut être utilisé lorsque la cible se trouve derrière un serveur DNS personnalisé ou possède des espaces de noms DNS personnalisés, ce qui le rend accessible uniquement via des noms de domaine complets ou des adresses IP spécifiques. Par exemple, cela peut inclure des entrées telles que
production-flexible-server.example.com,198.1.0.2ou un nom de domaine complet PostgreSQL tel queproduction-flexible-server.postgres.database.azure.com, si le serveur DNS personnalisé contient la zonepostgres.database.azure.comDNS ou transfère les requêtes pour cette zone vers168.63.129.16, où le nom de domaine complet est résolu dans la zone DNS publique ou privée Azure. - Tester la connexion : effectue le test de connectivité entre la source et la cible. Une fois la connexion établie, vous pouvez passer à l’onglet suivant. Ce test vise à identifier les problèmes de connectivité qui peuvent exister entre les serveurs source et cible, notamment la vérification de l’authentification à l’aide des informations d’identification fournies. L’établissement d’une connexion de test prend quelques secondes.
Une fois la connexion de test réussie, sélectionnez Suivant : Bases de données à valider ou à migrer

Bases de données à valider ou migrer
Sous l’onglet Bases de données à valider ou migrer , vous pouvez choisir une liste de bases de données utilisateur à migrer à partir de votre serveur PostgreSQL source.
Après avoir sélectionné les bases de données, sélectionnez Suivant : Résumé.

Résumé
L’onglet Résumé récapitule tous les détails source et cible pour la création de la validation ou de la migration. Passez en revue les détails et sélectionnez Démarrer la validation et la migration.

Annuler la validation ou la migration
Vous pouvez annuler toutes les validations ou migrations en cours. Le flux de travail doit être dans l’état En cours pour être annulé. Vous ne pouvez pas annuler une validation ou une migration dans l’état Réussite ou Échec .
L’annulation d’une validation arrête toute activité de validation supplémentaire et la validation passe à un état Annulé .
L’annulation d’une migration arrête l’activité de migration supplémentaire sur votre serveur cible et passe à un état Annulé . Elle ne supprime ni ne restaure aucune modification sur votre serveur cible. Veillez à supprimer les bases de données sur votre serveur cible impliqué dans une migration annulée.
Surveiller la migration
Une fois que vous avez sélectionné le bouton Démarrer la validation et la migration , une notification s’affiche, en quelques secondes, pour indiquer que la création de la validation ou de la migration réussit. Vous êtes automatiquement redirigé vers la page Migration du serveur flexible. L’entrée affiche l’état comme en cours. Le flux de travail prend 2 à 3 minutes pour configurer l’infrastructure de migration et vérifier les connexions réseau.

La grille qui affiche les migrations comporte les colonnes suivantes : Nom, État, Mode Migration, Type de migration, Serveur source, Type de serveur source, Bases de données, Durée et Heure de début. Les entrées sont triées par heure de début dans l’ordre décroissant, avec l’entrée la plus récente en haut. Vous pouvez utiliser le bouton Actualiser dans la barre d’outils pour actualiser l’état de la validation ou de l’exécution de la migration.
Détails de la migration
Sélectionnez le nom de la migration dans la grille pour afficher les informations associées.
N’oubliez pas que lors de la création de cette migration, vous avez configuré l’option de migration en tant que Validation et migration. Dans ce scénario, les validations sont effectuées en premier avant le démarrage de la migration. Une fois le sous-état Effectuer les étapes préalables terminé, le flux de travail passe à l'état de validation en cours.
Si la validation présente des erreurs, la migration passe à l’état Échec.
Si la validation est terminée sans erreur, la migration démarre et le flux de travail passe dans la sous-état de migration des données.
Les détails de validation sont disponibles au niveau de l’instance et de la base de données.
-
Détails de validation pour l’instance
- Contient la validation liée à la vérification de la connectivité, à la version source, autrement dit, à la version >PostgreSQL = 9.5 et à la vérification des paramètres de serveur, si les extensions sont activées dans les paramètres de serveur du serveur flexible Azure Database pour PostgreSQL.
-
Détails de validation et de migration pour les bases de données
- Il contient la validation des bases de données individuelles relatives à la prise en charge des extensions et des classements dans un serveur flexible Azure Database pour PostgreSQL.
Vous pouvez voir l’état de validation et l’état de migration dans la page détails de la migration.

Certains états de migration possibles :
état de la migration
| Statut | Descriptif |
|---|---|
| En cours | L’infrastructure de migration est en cours de configuration, ou la migration des données est en cours. |
| Canceled | La migration est annulée ou supprimée. |
| Échec | La migration a échoué. |
| Échec de la validation | La validation a échoué. |
| Réussi | La migration a réussi et est terminée. |
| En attente d'une action de l’utilisateur | Attente d’une action de l’utilisateur pour effectuer le basculement. |
Détails de la migration
| Sous-état | Descriptif |
|---|---|
| Exécution des étapes requises | L’infrastructure est en cours de configuration pour la migration des données. |
| Validation en cours | La validation est en cours. |
| Dépôt de la base de données sur la cible | Suppression d’une base de données déjà existante sur le serveur cible. |
| Migration de données | La migration des données est en cours. |
| Fin de la migration | La migration est en phase finale. |
| Terminé | La migration est terminée. |
| Échec | La migration a échoué. |
Sous-états de validation
| Sous-état | Descriptif |
|---|---|
| Échec | La validation a échoué. |
| Réussi | La validation a réussi. |
| Avertissement | La validation présente un avertissement. |
Lancer le basculement
Vous pouvez lancer le basculement à l’aide du portail Azure ou d’Azure CLI.
Pour l’option Valider et migrer , l’exécution de la migration en ligne nécessite que l’utilisateur effectue une étape supplémentaire, qui consiste à déclencher l’action de basculement. Une fois la copie ou le clonage des données de base terminées, la migration passe à l’état Waiting for user action et au Waiting for cutover trigger sous-état. Dans cet état, l’utilisateur peut déclencher le basculement à partir du portail en sélectionnant la migration.
Avant de lancer le basculement, il est important de s’assurer que :
- Les écritures dans la source sont arrêtées :
latencyla valeur est 0 ou proche de 0. Les informationslatencypeuvent être obtenues à partir de l’écran des détails de la migration, comme indiqué ci-dessous : -
La valeur de
latencydiminue à 0 ou proche de 0 - La
latencyvaleur indique quand la cible a été synchronisée pour la dernière fois avec la source. Les écritures vers la source peuvent alors être arrêtées et le basculement peut être lancé. Si le trafic est important au niveau de la source, nous vous recommandons d’arrêter d’abord les écritures afin quelatencypuisse atteindre une valeur proche de 0, puis de lancer le basculement.
L’opération de basculement applique toutes les modifications en attente du serveur source au serveur cible et termine la migration. Si vous déclenchez un basculement, même avec une valeur latency non nulle, la réplication s’arrête jusqu’à ce moment précis. Toutes les données de la source jusqu'au point de basculement sont ensuite appliquées à la cible. Si vous rencontrez une latence de 15 minutes au point de basculement, toutes les modifications apportées aux données au cours des 15 dernières minutes sont appliquées à la cible.
Le temps nécessaire dépend du backlog des changements survenus au cours des 15 dernières minutes. Par conséquent, il est recommandé que la latence passe à zéro ou près de zéro avant de déclencher le basculement.
- La migration passe à l’état
Succeededlorsque le sous-étatMigrating dataou le basculement (dans le cas d’une migration en ligne) se termine avec succès. S’il existe un problème au niveau duMigrating datasous-état, la migration passe à unFailedétat.
Vérifier la migration une fois terminée
Une fois les bases de données terminées, vous devez valider manuellement les données entre la source et la cible et vérifier que tous les objets de la base de données cible sont correctement créés.
Après la migration, vous pouvez effectuer les tâches suivantes :
Vérifiez les données sur votre serveur flexible et vérifiez qu’il s’agit d’une copie exacte de l’instance source.
Après vérification, et si cela est nécessaire, activez l’option haute disponibilité sur votre serveur flexible.
Changez la référence SKU du serveur flexible en fonction des besoins d’applications. Cette modification nécessite un redémarrage du serveur de base de données.
Si vous modifiez les valeurs par défaut de certains paramètres de serveur sur l’instance source, copiez les valeurs de ces paramètres de serveur dans le serveur flexible.
Copiez d’autres paramètres de serveur, tels que les étiquettes, les alertes et les règles de pare-feu (le cas échéant), de l’instance source vers le serveur flexible.
Apportez des modifications à votre application pour lui faire pointer les chaînes de connexion vers un serveur flexible.
Surveillez de près le niveau de performance des bases de données pour déterminer s’il est nécessaire de l’ajuster.