Analyses et ingestion dans Microsoft Purview
Cet article fournit une vue d’ensemble des fonctionnalités d’analyse et d’ingestion dans Microsoft Purview. Ces fonctionnalités connectent votre compte Microsoft Purview à vos sources pour remplir la carte de données et le catalogue de données afin que vous puissiez commencer à explorer et à gérer vos données via Microsoft Purview.
- L’analyse capture les métadonnées des sources de données et les apporte à Microsoft Purview.
-
L’ingestion traite les métadonnées et les stocke dans le catalogue de données à partir des deux :
- Analyses de source de données : les métadonnées analysées sont ajoutées à la Mappage de données Microsoft Purview.
- Connexions de traçabilité : les ressources de transformation ajoutent des métadonnées sur leurs sources, sorties et activités au Mappage de données Microsoft Purview.
Analyse
Une fois que les sources de données sont inscrites dans votre compte Microsoft Purview, l’étape suivante consiste à analyser les sources de données. Le processus d’analyse établit une connexion à la source de données et capture les métadonnées techniques telles que les noms, la taille de fichier, les colonnes, etc. Il extrait également le schéma des sources de données structurées, applique des classifications aux schémas et applique des étiquettes de confidentialité si votre Mappage de données Microsoft Purview est connecté à un portail de conformité Microsoft Purview. Le processus d’analyse peut être déclenché pour s’exécuter immédiatement ou peut être planifié pour s’exécuter régulièrement pour maintenir votre compte Microsoft Purview à jour.
Pour chaque analyse, vous pouvez appliquer des personnalisations afin que vous n’analysez que les informations dont vous avez besoin, plutôt que la source entière.
Choisir une méthode d’authentification pour vos analyses
Microsoft Purview est sécurisé par défaut. Aucun mot de passe ou secret n’étant stocké directement dans Microsoft Purview, vous devez choisir une méthode d’authentification pour vos sources. Il existe plusieurs façons d’authentifier votre compte Microsoft Purview, mais toutes les méthodes ne sont pas prises en charge pour chaque source de données.
- Identité managée
- Service Principal
- Authentification SQL
- Authentification Windows
- ARN de rôle
- Authentification déléguée
- Clé du consommateur
- Clé de compte ou authentification de base
Dans la mesure du possible, une identité managée est la méthode d’authentification préférée, car elle élimine la nécessité de stocker et de gérer les informations d’identification pour des sources de données individuelles. Cela peut considérablement réduire le temps que vous et votre équipe consacrez à la configuration et à la résolution des problèmes d’authentification pour les analyses. Lorsque vous activez une identité managée pour votre compte Microsoft Purview, une identité est créée dans Azure Active Directory et est liée au cycle de vie de votre compte.
Définir l’étendue de votre analyse
Lors de l’analyse d’une source, vous avez le choix d’analyser l’intégralité de la source de données ou de choisir uniquement des entités spécifiques (dossiers/tables) à analyser. Les options disponibles dépendent de la source que vous analysez et peuvent être définies pour les analyses ponctuelles et planifiées.
Par exemple, lors de la création et de l’exécution d’une analyse pour une base de données Azure SQL, vous pouvez choisir les tables à analyser ou sélectionner la base de données entière.
Pour chaque entité (dossier/table), il y aura trois états de sélection : entièrement sélectionné, partiellement sélectionné et non sélectionné. Dans l’exemple ci-dessous, si vous sélectionnez « Département 1 » dans la hiérarchie de dossiers, « Département 1 » est considéré comme entièrement sélectionné. Les entités parentes pour « Département 1 », telles que « Société » et « exemple » sont considérées comme partiellement sélectionnées, car d’autres entités sous le même parent n’ont pas été sélectionnées, par exemple « Département 2 ». Différentes icônes seront utilisées dans l’interface utilisateur pour les entités avec des états de sélection différents.
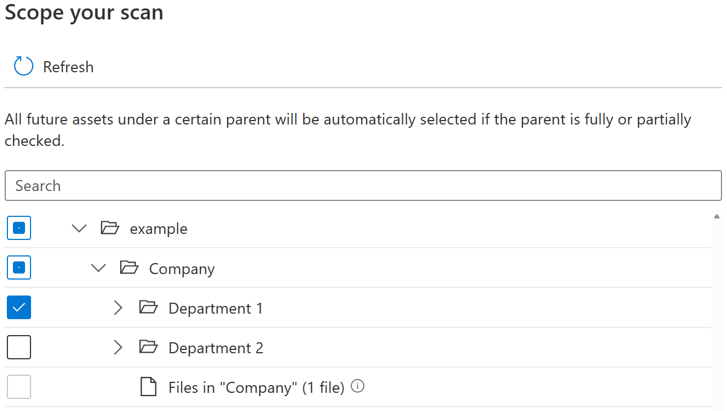
Après avoir exécuté l’analyse, il est probable que de nouvelles ressources soient ajoutées dans le système source. Par défaut, les ressources futures sous un certain parent sont automatiquement sélectionnées si le parent est entièrement ou partiellement sélectionné lorsque vous réexécutez l’analyse. Dans l’exemple ci-dessus, une fois que vous avez sélectionné « Service 1 » et exécuté l’analyse, toutes les nouvelles ressources sous le dossier « Service 1 » ou sous « Société » et « exemple » sont incluses lorsque vous réexécutez l’analyse.
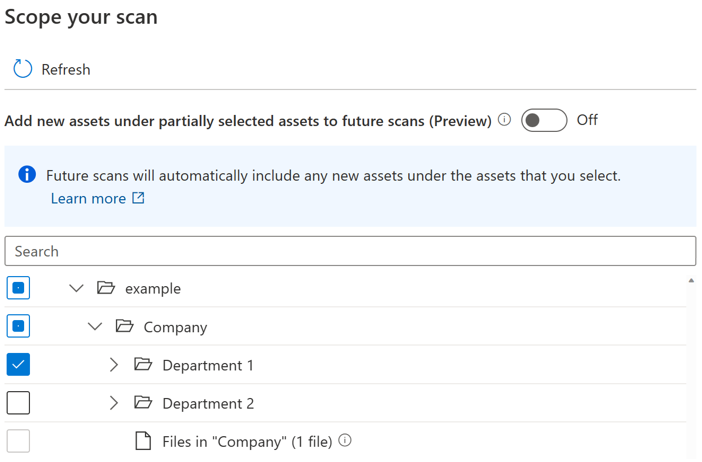
Un bouton bascule est introduit pour permettre aux utilisateurs de contrôler l’inclusion automatique des nouvelles ressources sous un parent partiellement sélectionné. Par défaut, le bouton bascule est désactivé et le comportement d’inclusion automatique pour le parent partiellement sélectionné est désactivé. Dans le même exemple, avec le bouton bascule désactivé, toutes les nouvelles ressources sous des parents partiellement sélectionnés, telles que « Société » et « exemple » ne seront pas incluses lorsque vous réexécutez l’analyse, seules les nouvelles ressources sous « Département 1 » seront incluses dans l’analyse ultérieure.
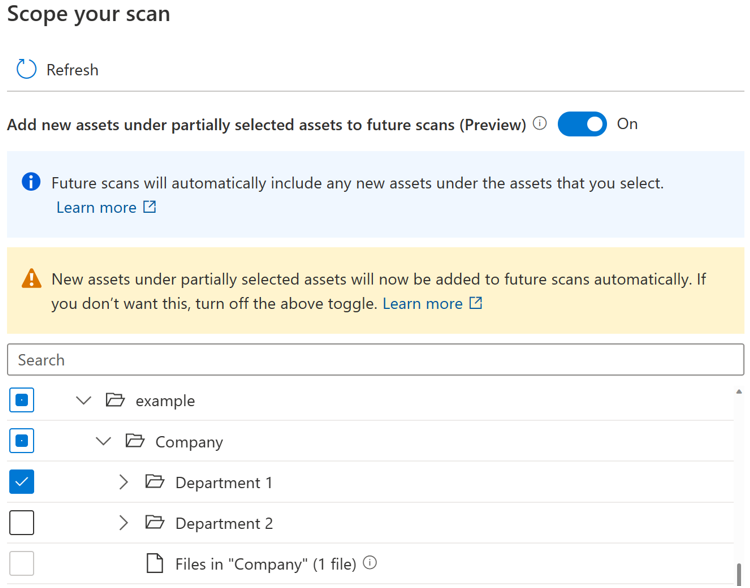
Si le bouton bascule est activé, les nouvelles ressources sous un certain parent sont automatiquement sélectionnées si le parent est entièrement ou partiellement sélectionné lorsque vous réexécutez l’analyse. Le comportement d’inclusion sera le même qu’avant l’introduction du bouton bascule.
Remarque
- La disponibilité du bouton bascule dépend du type de source de données. Il est actuellement disponible en préversion publique pour les sources, notamment Stockage Blob Azure, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, Azure Files et le pool SQL Dédié Azure (anciennement SQL DW).
- Pour toutes les analyses créées ou planifiées avant l’introduction du bouton bascule, l’état du bouton bascule est défini sur activé et ne peut pas être modifié. Pour les analyses créées ou planifiées après l’introduction du bouton bascule, l’état du bouton bascule ne peut pas être modifié une fois l’analyse enregistrée. Vous devez créer une analyse pour modifier l’état du bouton bascule.
- Lorsque le bouton bascule est désactivé, pour les sources de type de stockage comme Azure Data Lake Storage Gen 2, l’expérience parcourir par type de source peut prendre jusqu’à 4 heures une fois votre travail d’analyse terminée.
Limitations connues
Lorsque le bouton bascule est désactivé :
- Les entités de fichier sous un parent partiellement sélectionné ne seront pas analysées.
- Si toutes les entités existantes sous un parent sont explicitement sélectionnées, le parent est considéré comme entièrement sélectionné et toutes les nouvelles ressources sous le parent sont incluses lorsque vous réexécutez l’analyse.
Ensemble de règles d’analyse
Un ensemble de règles d’analyse détermine les types d’informations qu’une analyse recherche lorsqu’elle s’exécute sur l’une de vos sources. Les règles disponibles dépendent du type de source que vous analysez, mais incluent des éléments tels que les types de fichiers que vous devez analyser et les types de classifications dont vous avez besoin.
Il existe déjà des ensembles de règles d’analyse système disponibles pour de nombreux types de sources de données, mais vous pouvez également créer vos propres ensembles de règles d’analyse pour adapter vos analyses à vos organization.
Planifier votre analyse
Microsoft Purview vous offre le choix entre l’analyse hebdomadaire ou mensuelle à l’heure de votre choix. Les analyses hebdomadaires peuvent convenir aux sources de données dont les structures sont activement en cours de développement ou qui changent fréquemment. L’analyse mensuelle est plus appropriée pour les sources de données qui changent rarement. La meilleure pratique consiste à travailler avec l’administrateur de la source que vous souhaitez analyser pour identifier un moment où les demandes de calcul sur la source sont faibles.
Comment les analyses détectent les ressources supprimées
Un catalogue Microsoft Purview n’est conscient de l’état d’un magasin de données que lorsqu’il exécute une analyse. Pour que le catalogue sache si un fichier, une table ou un conteneur a été supprimé, il compare la dernière sortie d’analyse à la sortie d’analyse actuelle. Par exemple, supposons que la dernière fois que vous avez analysé un compte Azure Data Lake Storage Gen2, il incluait un dossier nommé folder1. Lorsque le même compte est à nouveau analysé, le dossier1 est manquant. Par conséquent, le catalogue suppose que le dossier a été supprimé.
Détection des fichiers supprimés
La logique de détection des fichiers manquants fonctionne pour plusieurs analyses effectuées par le même utilisateur et par différents utilisateurs. Par exemple, supposons qu’un utilisateur exécute une analyse unique sur un magasin de données Data Lake Storage Gen2 sur les dossiers A, B et C. Par la suite, un autre utilisateur du même compte exécute une analyse unique différente sur les dossiers C, D et E du même magasin de données. Étant donné que le dossier C a été analysé deux fois, le catalogue le vérifie pour les suppressions possibles. Toutefois, les dossiers A, B, D et E n’ont été analysés qu’une seule fois, et le catalogue ne les case activée pas pour les ressources supprimées.
Pour conserver les fichiers supprimés hors de votre catalogue, il est important d’exécuter des analyses régulières. L’intervalle d’analyse est important, car le catalogue ne peut pas détecter les ressources supprimées tant qu’une autre analyse n’est pas exécutée. Par conséquent, si vous exécutez des analyses une fois par mois sur un magasin particulier, le catalogue ne peut pas détecter les ressources de données supprimées dans ce magasin tant que vous n’exécutez pas l’analyse suivante un mois plus tard.
Lorsque vous énumérez des magasins de données volumineux comme Data Lake Storage Gen2, il existe plusieurs façons (y compris les erreurs d’énumération et les événements supprimés) de manquer des informations. Une analyse particulière peut manquer qu’un fichier a été créé ou supprimé. Par conséquent, à moins que le catalogue soit certain qu’un fichier a été supprimé, il ne le supprimera pas du catalogue. Cette stratégie signifie qu’il peut y avoir des erreurs lorsqu’un fichier qui n’existe pas dans le magasin de données analysé existe toujours dans le catalogue. Dans certains cas, un magasin de données peut avoir besoin d’être analysé deux ou trois fois avant d’intercepter certaines ressources supprimées.
Remarque
- Les ressources marquées pour suppression sont supprimées après une analyse réussie. Les ressources supprimées peuvent continuer à être visibles dans votre catalogue pendant un certain temps avant d’être traitées et supprimées.
- Actuellement, la détection de suppression de source n’est pas prise en charge pour les sources suivantes : Azure Databricks, Amazon Redshift, Cassandra, DB2, Erwin, Google BigQuery, Hive Metastore, Looker, MongoDB, MySQL, Oracle, PostgreSQL, Salesforce, SAP BW, SAP ECC, SAP HANA, SAP S/4HANA, Snowflake et Teradata. Lorsque l’objet est supprimé de la source de données, l’analyse suivante ne supprime pas automatiquement la ressource correspondante dans Microsoft Purview.
Ingestion
L’ingestion est le processus responsable du remplissage de la carte de données avec les métadonnées collectées par le biais de ses différents processus.
Ingestion à partir d’analyses
Les métadonnées techniques ou classifications identifiées par le processus d’analyse sont ensuite envoyées à l’ingestion. L’ingestion analyse l’entrée de l’analyse, applique des modèles de jeu de ressources, remplit les informations de traçabilité disponibles, puis charge automatiquement le mappage de données. Les ressources/schémas peuvent être découverts ou organisés uniquement une fois l’ingestion terminée. Par conséquent, si votre analyse est terminée, mais que vous n’avez pas vu vos ressources dans la carte de données ou le catalogue, vous devez attendre la fin du processus d’ingestion.
Ingestion à partir de connexions de traçabilité
Des ressources telles que Azure Data Factory et Azure Synapse peuvent être connectées à Microsoft Purview pour intégrer des informations de source de données et de traçabilité dans votre Mappage de données Microsoft Purview. Par exemple, lorsqu’un pipeline de copie s’exécute dans un Azure Data Factory qui a été connecté à Microsoft Purview, les métadonnées relatives aux sources d’entrée, à l’activité et aux sources de sortie sont ingérées dans Microsoft Purview et les informations sont ajoutées au mappage de données.
Si une source de données a déjà été ajoutée à la carte de données par le biais d’une analyse, des informations de traçabilité sur l’activité sont ajoutées à la source existante. Si la source de données n’a pas encore été ajoutée au mappage de données, le processus d’ingestion de traçabilité l’ajoute à la collection racine avec ses informations de traçabilité.
Pour plus d’informations sur les connexions de traçabilité disponibles, consultez le guide de l’utilisateur de traçabilité.
Prochaines étapes
Pour plus d’informations ou pour obtenir des instructions spécifiques sur l’analyse des sources, suivez les liens ci-dessous.
- Pour comprendre les jeux de ressources, consultez notre article jeux de ressources.
- Guide pratique pour régir une base de données Azure SQL
- Traçabilité dans Microsoft Purview