Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit la prise en charge de la fiabilité dans Azure HDInsight, et passe en revue les zones de disponibilité et la récupération entre régions, ainsi que la continuité des activités. Pour obtenir une vue d’ensemble plus détaillée de la fiabilité dans Azure, consultez Fiabilité Azure.
Prise en charge des zones de disponibilité
Les zones de disponibilité sont des groupes physiquement distincts de centres de données au sein d’une région Azure. Lorsqu'une zone tombe en panne, les services peuvent basculer vers l'une des zones restantes.
Azure HDInsight prend en charge une configuration de déploiement zonale. Les nœuds de cluster Azure HDInsight sont placés dans une seule zone que vous sélectionnez dans la région choisie. Un cluster HDInsight zonal est isolé des pannes qui se produisent dans d'autres zones. Toutefois, si une panne a un impact sur la zone spécifique choisie pour le cluster HDInsight, le cluster n'est pas disponible. Ce modèle de déploiement fournit une connectivité réseau peu coûteuse et à faible latence au sein du cluster. La réplication de ce modèle de déploiement dans plusieurs zones de disponibilité peut fournir un niveau de disponibilité plus élevé pour la protection contre les défaillances matérielles.
Important
Pour les déploiements dans lesquels les utilisateurs ne spécifient pas de zone spécifique, les types de nœuds ne sont pas résilients aux zones et peuvent subir des temps d'arrêt lors d'une panne dans n'importe quelle zone de cette région.
Prerequisites
Les zones de disponibilité ne sont prises en charge que pour les clusters créés après le 15 juin 2023. Les paramètres de la zone de disponibilité ne peuvent pas être mis à jour une fois le cluster créé. Vous ne pouvez pas non plus mettre à jour un cluster de zones de non-disponibilité existant pour utiliser des zones de disponibilité.
Les clusters doivent être créés sous un réseau virtuel personnalisé.
Vous devez apporter votre propre base de données SQL pour la base de données Ambari et le metastore externe (par exemple le metastore Hive), afin de pouvoir configurer ces bases de données dans la même zone de disponibilité.
Vos clusters HDInsight doivent être créés avec l'option de zone de disponibilité dans l'une des régions suivantes :
- Australia East
- Brazil South
- Canada Central
- Central US
- East US
- Est des États-Unis 2
- France Centrale
- Allemagne Centre-Ouest
- Japon Est
- Korea Central
- Europe Nord
- Qatar Central
- Asie du Sud-Est
- États-Unis - partie centrale méridionale
- UK South
- Gouvernement américain - Virginie
- Europe Ouest
- Ouest des États-Unis 2
Créer un cluster HDInsight à l’aide d’une zone de disponibilité
Vous pouvez utiliser le modèle Azure Resource Manager (ARM) pour lancer un cluster HDInsight dans une zone de disponibilité spécifiée.
Dans la section des ressources, vous devez ajouter une section de « zones » et spécifier la zone de disponibilité dans laquelle vous souhaitez déployer ce cluster.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Vérifier les nœuds dans une zone de disponibilité entre les zones
Lorsque le cluster HDInsight est prêt, vous pouvez vérifier l’emplacement pour afficher la zone de disponibilité dans laquelle il est déployé.
Obtenir une réponse d’API :
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Effectuer un scale-up du cluster
Vous pouvez effectuer un scale-up d’un cluster HDInsight avec plus de nœuds Worker. Les nœuds Worker récemment ajoutés sont placés dans la même zone de disponibilité de ce cluster.
Migration de zones de disponibilité
Actuellement, les clusters Azure HDInsight ne prennent pas en charge la migration sur place d'instances de cluster existantes vers la prise en charge de la zone de disponibilité. Toutefois, vous pouvez choisir de recréer votre cluster,et de choisir une autre zone de disponibilité ou région pendant sa création. Un cluster de secours secondaire dans une autre région et une autre zone de disponibilité peut être utilisé dans les scénarios de récupération d'urgence.
Expérience en cas de panne de zone
Lorsqu'une zone de disponibilité est en panne :
- Vous ne pouvez pas utiliser SSH pour accéder à ce cluster.
- Vous ne pouvez pas supprimer, ni effectuer de scale-up ou scale-down de ce cluster.
- Vous ne pouvez pas envoyer de travaux ni consulter l'historique des travaux.
- Vous pouvez toujours envoyer une nouvelle requête de création de cluster dans une autre région.
Récupération d’urgence et continuité d’activité inter-région
La reprise après sinistre (DR) fait référence aux pratiques utilisées par les organisations pour se remettre d’événements à fort impact, tels que des catastrophes naturelles ou des déploiements échoués qui entraînent des temps d’arrêt et des pertes de données. Quelle qu’en soit la cause, la meilleure solution en cas de sinistre est d’avoir un plan de DR bien défini et testé, et une conception d’application qui prend activement en charge la DR. Avant de commencer à créer votre plan de reprise après sinistre, consultez Recommandations pour la conception d'une stratégie de reprise après sinistre.
Pour la récupération d’urgence, Microsoft utilise le modèle de responsabilité partagée. Dans ce modèle, Microsoft garantit que l’infrastructure de base et les services de plateforme sont disponibles. Cependant, de nombreux services Azure ne répliquent pas automatiquement les données ou ne reviennent pas d’une région défaillante pour effectuer une réplication croisée vers une autre région activée. Pour ces services, vous êtes responsable de la configuration d’un plan de récupération d’urgence qui fonctionne pour votre charge de travail. La plupart des services qui s’exécutent sur des offres PaaS (Platform as a Service) Azure fournissent des fonctionnalités et des instructions pour la prise en charge de la récupération d’urgence. Vous pouvez utiliser des fonctionnalités spécifiques au service pour prendre en charge une récupération rapide afin de vous aider à développer votre plan de reprise après sinistre.
Les clusters Azure HDInsight dépendent de nombreux services Azure tels que le stockage, les bases de données, Active Directory, Active Directory Domain Services, la mise en réseau et Key Vault. Une application d’analytique bien conçue, hautement disponible et tolérante aux pannes doit être conçue avec suffisamment de redondance pour résister à des interruptions régionales ou locales dans un ou plusieurs de ces services. Cette section donne un aperçu des meilleures pratiques, de la disponibilité dans une et plusieurs régions et des options d'optimisation pour la planification de la continuité des activités.
Récupération d’urgence dans la zone géographique multi-région
L’amélioration de la continuité de l’activité à l’aide de la récupération d’urgence à haute disponibilité entre les régions nécessite des conceptions architecturales plus complexes et plus coûteuses. Les tableaux suivants décrivent certains domaines techniques qui peuvent augmenter le coût total de possession.
Optimisation des coûts
| Area | Cause de la hausse des coûts | Stratégies d’optimisation |
|---|---|---|
| Stockage des données | Duplication des données/tables primaires dans une région secondaire | Répliquer uniquement les données organisées |
| Sortie de données | Les transferts de données interrégions sortants ont un prix. Voir les directives relatives à la tarification de la bande passante | Répliquer uniquement les données organisées pour réduire l’empreinte de sortie de la région |
| Calcul de cluster | Clusters HDInsight supplémentaires dans la région secondaire | Utiliser des scripts automatisés pour déployer le calcul secondaire après l’échec du calcul primaire. Utiliser la mise à l’échelle automatique pour réduire au minimum la taille des clusters secondaires. Utiliser des SKU de machine virtuelle moins chers. Créer des clusters secondaires dans les régions où les SKU de machine virtuelle peuvent faire l’objet d’une remise |
| Authentication | Les scénarios multiutilisateurs dans la région secondaire entraînent des configurations supplémentaires de Microsoft Entra Domain Services | Éviter les installations multi-utilisateurs dans la région secondaire. |
Optimisations de la complexité
| Area | Cause de la hausse de la complexité | Stratégies d’optimisation |
|---|---|---|
| Modèles Lecture/Écriture | Obligation de permettre la lecture et l’écriture dans les régions primaires et secondaires | Concevoir la région secondaire pour qu’elle soit en lecture seule |
| RPO et RTO zéro | Obligation de zéro perte de données (RPO = 0) et zéro temps d’arrêt (RTO = 0) | Concevoir RPO et RTO de manière à réduire le nombre de composants qui doivent basculer. Pour plus d’informations sur les RTO et RPO, consultez Qu’est-ce que la continuité des activités, la haute disponibilité et la récupération d’urgence ?. |
| Fonctionnalités d’entreprise | Obligation d’avoir toutes les fonctionnalités métier de la région primaire dans la région secondaire | Évaluer s’il est possible de fonctionner avec un sous-ensemble critique minimal des fonctionnalités métier dans la région secondaire |
| Connectivity | Obligation pour tous les systèmes en amont et en aval de la région primaire de se connecter également à la région secondaire | Limiter la connectivité de la région secondaire à un sous-ensemble critique minimal. |
Lorsque vous créez votre plan de récupération d’urgence pour plusieurs régions, tenez compte des recommandations suivantes :
Déterminez les fonctionnalités métier minimales dont vous avez besoin en cas de sinistre, et pourquoi. Par exemple, évaluez si vous avez besoin de capacités de basculement pour la couche de transformation des données (en jaune) et la couche de service des données (en bleu), ou si vous avez uniquement besoin d’un basculement pour la couche de service de données.
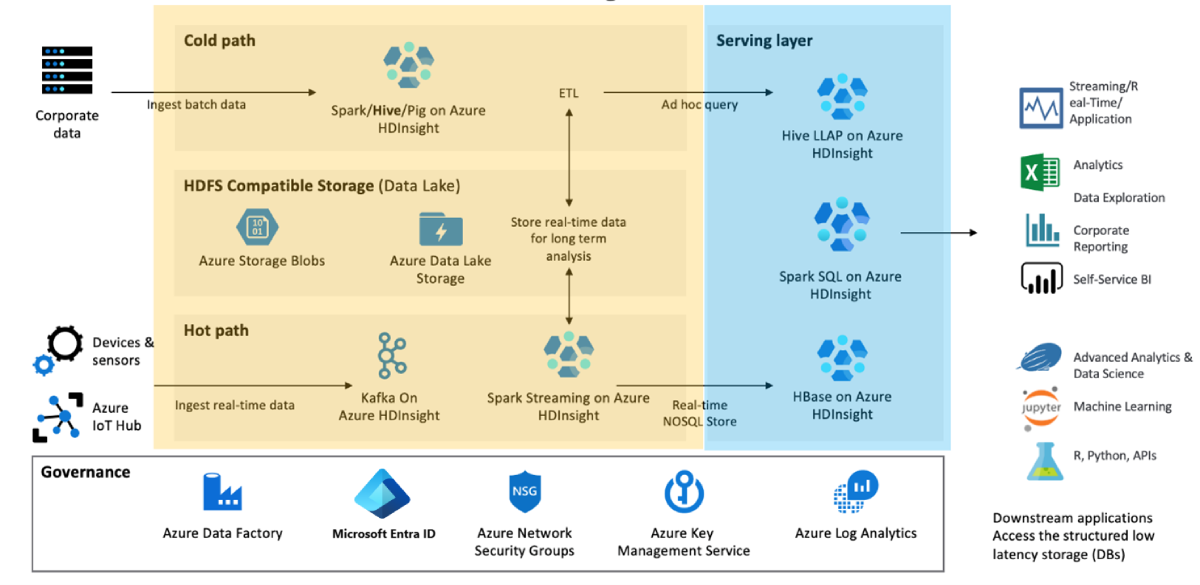
Segmentez vos clusters en fonction de la charge de travail, du cycle de vie de développement et des départements. Le fait de disposer d’un plus grand nombre de clusters réduit les risques qu’une seule grande défaillance nuise à plusieurs processus métier différents.
Rendez vos régions secondaires accessibles en lecture seule. Les régions de basculement disposant à la fois de capacités de lecture et d’écriture peuvent conduire à des architectures complexes.
Les clusters temporaires sont plus faciles à gérer en cas d’urgence. Concevez vos charges de travail de façon à ce que les clusters puissent être cycliques et qu’aucun état ne soit conservé dans les clusters.
Souvent, les charges de travail ne sont pas terminées en cas d’urgence et doivent être redémarrées dans la nouvelle région. Concevez vos charges de travail de manière à ce qu’elles soient de nature idempotente.
Utilisez l’automatisation lors des déploiements de cluster et assurez-vous que les paramètres de configuration de cluster sont scriptés autant que possible pour garantir un déploiement rapide et entièrement automatisé en cas d’urgence.
Détection, notification et gestion des pannes
Utilisez les outils d’analyse Azure sur HDInsight pour détecter un comportement anormal dans le cluster et définir les notifications d’alerte correspondantes. Vous pouvez déployer les solutions de gestion de cluster HDInsight préconfigurées qui collectent des métriques de performances importantes du type de cluster spécifique. Pour plus d’informations, consultez Azure Monitor pour HDInsight.
Abonnez-vous aux alertes d’intégrité Azure pour être informé des problèmes de service, de la maintenance planifiée et des conseils en matière d’intégrité et de sécurité pour un abonnement, un service ou une région. Les notifications d’intégrité qui incluent la cause du problème et une estimation de l’heure de résolution vous aident à mieux exécuter le basculement et les restaurations. Pour plus d’informations, consultez la documentation Azure Service Health.
Récupération d’urgence dans une zone géographique à région unique
Chaque composant d'un système HDInsight de base possède ses propres mécanismes de tolérance de panne de région unique. Rappelez-vous qu'il n'y a pas toujours besoin d'un événement catastrophique pour nuire aux fonctionnalités métier. Les incidents de service dans un ou plusieurs des services suivants dans une même région peuvent également entraîner une perte des fonctionnalités métier attendues.
Calcul (machines virtuelles) : cluster Azure HDInsight. HDInsight propose un contrat SLA de disponibilité de 99,9 %. Pour assurer la haute disponibilité dans un seul déploiement, HDInsight est accompagné de nombreux services qui sont en mode haute disponibilité par défaut. Les mécanismes de tolérance de panne dans HDInsight sont fournis par les services de haute disponibilité de Microsoft et de l’écosystème OSS Apache.
Les composants d'infrastructure suivants sont conçus pour être hautement disponibles :
- Nœuds principaux actif et en attente
- Plusieurs nœuds de passerelle
- Trois nœuds de quorum Zookeeper
- Nœuds Worker distribués par des domaines d’erreur et de mise à jour
Les services suivants sont également conçus pour être hautement disponibles :
- Serveur Apache Ambari
- Serveurs de chronologie d’application pour YARN
- Serveur d’historique des travaux pour Hadoop MapReduce
- Apache Livy
- HDFS (système de fichiers distribué Hadoop)
- Gestionnaire de ressources YARN
- HBase Master
Pour en savoir plus, consultez les services à haute disponibilité pris en charge par Azure HDInsight.
Metastore(s) : Azure SQL Database. HDInsight utilise Azure SQL Database comme metastore, qui propose un contrat SLA de 99,99 %. Trois réplicas de données persistent dans un centre de données à l’aide de la réplication synchrone. En cas de perte d’un réplica, un autre réplica prend le relais en toute transparence. La géoréplication active est prise en charge dès le départ avec un maximum de quatre centres de données. En cas de basculement manuel ou lancé par le centre de données, le premier réplica de la hiérarchie devient automatiquement accessible en lecture et en écriture. Pour plus d’informations, consultez Continuité de l’activité Azure SQL Database.
Stockage : Azure Data Lake Gen2 ou stockage Blob. HDInsight recommande Azure Data Lake Storage Gen2 comme couche de stockage sous-jacente. Stockage Azure, notamment Azure Data Lake Storage Gen2, propose un contrat SLA de 99,9 %. HDInsight utilise le service LRS dans lequel trois réplicas de données sont conservés dans un centre de données et où la réplication est synchrone. En cas de perte d’un réplica, un autre réplica prend le relais en toute transparence.
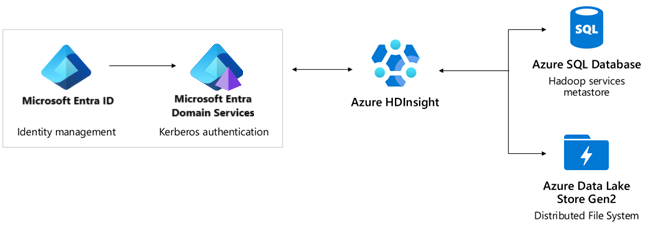
Authentification : Microsoft Entra ID, Microsoft Entra Domain Services,Pack Sécurité Entreprise.
- Microsoft Entra ID fournit un contrat SLA de 99,9 %. Active Directory est un service mondial avec plusieurs niveaux de redondance interne et de récupération automatique. Pour plus d'informations, découvrez comment Microsoft améliore en permanence la fiabilité de Microsoft Entra ID.
- Microsoft Entra Domain Services fournit un contrat SLA de 99,9 %. Microsoft Entra Domain Services est un service hautement disponible hébergé dans des centres de données distribués à l'échelle mondiale. Les jeux de réplicas sont une fonctionnalité d'évaluation dans Microsoft Entra Domain Services qui permet la récupération d'urgence géographique si une région Azure est mise hors connexion. Pour en savoir plus, consultez les Concepts et fonctionnalités des jeux de réplicas pour Microsoft Entra Domain Services.
- Azure DNS propose un contrat SLA de 100 %. HDInsight utilise Azure DNS à différents emplacements pour la résolution de noms de domaine.
Services facultatifs, comme Azure Key Vault et Azure Data Factory.