Configuration de la haute disponibilité dans SUSE à l’aide de l’appareil d’isolation
Dans cet article, nous allons suivre les étapes de configuration de la haute disponibilité (HA) dans de grandes instances HANA sur le système d’exploitation SUSE à l’aide de l’appareil d’isolation.
Notes
Ce guide provient de tests réussis de la configuration dans l’environnement des grandes instances Microsoft HANA. L’équipe de management des services Microsoft pour les grandes instances HANA ne prend pas en charge le système d’exploitation. Pour résoudre les problèmes ou clarifier la couche du système d’exploitation, contactez SUSE.
L’équipe de management des services Microsoft configure et prend entièrement en charge l’appareil d’isolation. Elle peut vous aider à résoudre les problèmes liés aux appareils d’isolation.
Prérequis
Pour configurer la haute disponibilité à l’aide du clustering SUSE, vous devez :
- Provisionner les grandes instances HANA.
- Installer et enregistrer le système d’exploitation avec les derniers correctifs.
- Connecter les serveurs de grande instance HANA au serveur SMT pour recevoir des correctifs et des packages.
- Configurer le protocole NTP (Network Time Protocol).
- Lire et comprendre la dernière version de la documentation SUSE sur la configuration de la haute disponibilité.
Détails de la configuration
Ce guide utilise la configuration suivante :
- Système d’exploitation : SLES 12 SP1 pour SAP
- HANA - Grandes instances : 2xS192 (quatre sockets, 2 To)
- Version HANA : HANA 2.0 SP1
- Noms de serveurs : sapprdhdb95 (node1) et sapprdhdb96 (node2)
- Appareil d’isolation : basé sur iSCSI
- Protocole NTP configuré sur l’un des nœuds de grande instance HANA
Quand vous configurez de grandes instances HANA avec la réplication système HANA, vous pouvez demander à l’équipe de management des services Microsoft de configurer l’appareil d’isolation. Faites cela au moment du provisionnement.
Si vous êtes déjà client avec de grandes instances HANA provisionnées, vous pouvez toujours faire configurer l’appareil d’isolation. Fournissez les informations suivantes à l’équipe de gestion des services Microsoft dans le formulaire de demande de service (SRF). Vous pouvez obtenir le formulaire SRF en passant par le responsable technique de compte ou votre contact Microsoft pour l’intégration d’une grande instance HANA.
- Nom du serveur et adresse IP du serveur (par exemple, myhanaserver1 et 10.35.0.1)
- Emplacement (par exemple, USA Est)
- Nom du client (par exemple, Microsoft)
- Identificateur du système HANA (SID) (par exemple, H11)
Une fois l’appareil d’isolation configuré, l’équipe de management des services Microsoft vous fournit le nom SBD et l’adresse IP du stockage iSCSI. Vous pouvez utiliser ces informations pour configurer l’isolation.
Suivez les étapes décrites dans les sections suivantes pour configurer la haute disponibilité (HA) à l’aide de l’appareil d’isolation.
Identifier l’appareil SBD
Notes
Cette section s’applique uniquement à des clients existants. Si vous êtes un nouveau client, vous pouvez ignorer cette section, car l’équipe de gestion des services Microsoft vous fournira le nom de l’appareil SBD.
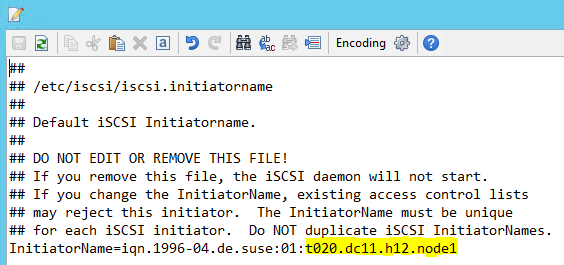
Modifiez /etc/iscsi/initiatorname.isci en :
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>L’équipe de gestion des services Microsoft fournit cette chaîne. Modifier le fichier sur les deux nœuds. Toutefois, le numéro de nœud est différent sur chaque nœud.
Modifiez /etc/iscsi/iscsid.conf en définissant
node.session.timeo.replacement_timeout=5etnode.startup = automatic. Modifier le fichier sur les deux nœuds.Exécutez la commande de détection suivante sur les deux nœuds.
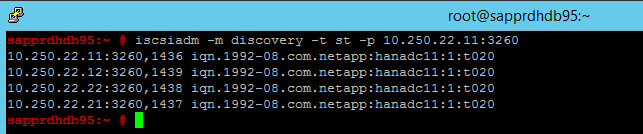
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Les résultats affichent quatre sessions.
Exécutez la commande suivante sur les deux nœuds pour vous connecter à l’appareil iSCSI.
iscsiadm -m node -lLes résultats affichent quatre sessions.

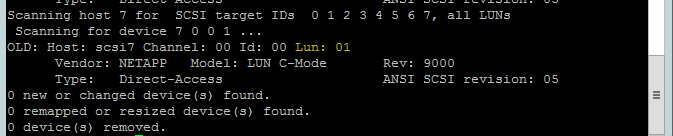
Utilisez la commande suivante pour exécutez le script de nouvelle analyse rescan-scsi-bus.sh. Ce script affiche les nouveaux disques créés pour vous. Exécutez-la sur les deux nœuds.
rescan-scsi-bus.shLes résultats doivent afficher un numéro d’unité logique supérieur à zéro (par exemple : 1, 2 et ainsi de suite).
Pour obtenir le nom de l’appareil, exécutez la commande suivante sur les deux nœuds.
fdisk –lDans les résultats, choisissez l’appareil avec la taille 178 Mio.

Initialiser l’appareil SBD
Utilisez la commande suivante pour initialiser l’appareil SBD sur les deux nœuds.
sbd -d <SBD Device Name> create
Utilisez la commande suivante sur les deux nœuds pour vérifier ce qui a été écrit sur l’appareil.
sbd -d <SBD Device Name> dump
Configurer le cluster à haute disponibilité SUSE
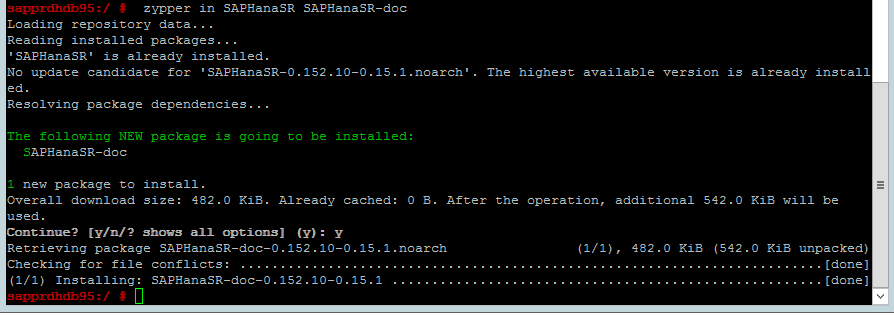
Utilisez la commande suivante pour vérifier si les patterns ha_sles et SAPHanaSR-doc sont installés sur les deux nœuds. S’ils ne sont pas installés, installez-les.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Configurez le cluster à l’aide de la commande
ha-cluster-initou de l’Assistant yast2. Dans cet exemple, nous utilisons l’Assistant yast2. Effectuez cette étape uniquement sur le nœud principal.Accédez à yast2>Haute disponibilité>Cluster.
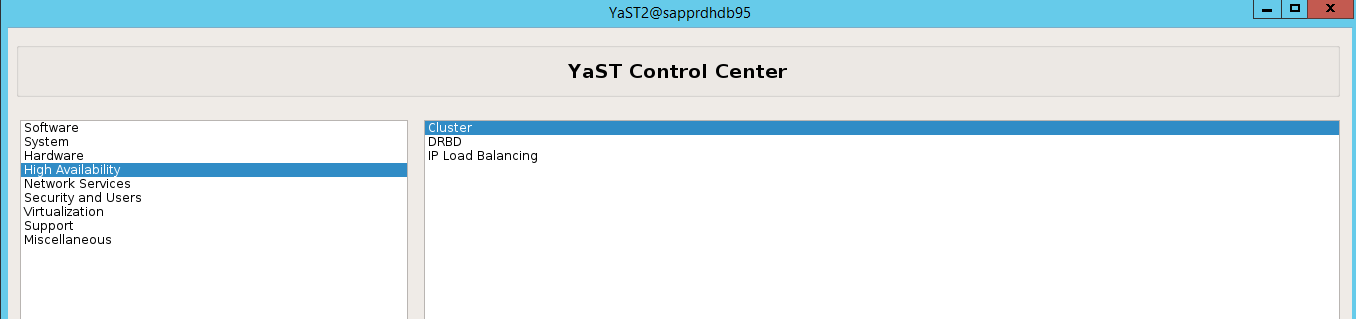
Dans la boîte de dialogue qui s’affiche à propos de l’installation du package hawk, sélectionnez Annuler, car le package halk2 est déjà installé.
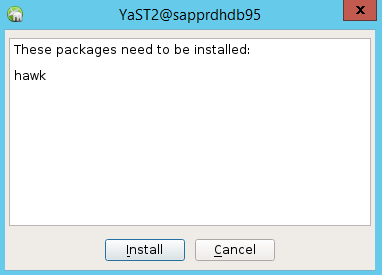
Dans la boîte de dialogue qui s’affiche pour continuer, sélectionnez Continuer.
La valeur attendue est le nombre de nœuds déployés (dans ce cas : 2). Sélectionnez Suivant.
Ajoutez des noms de nœuds, puis sélectionnez Ajouter les fichiers suggérés.
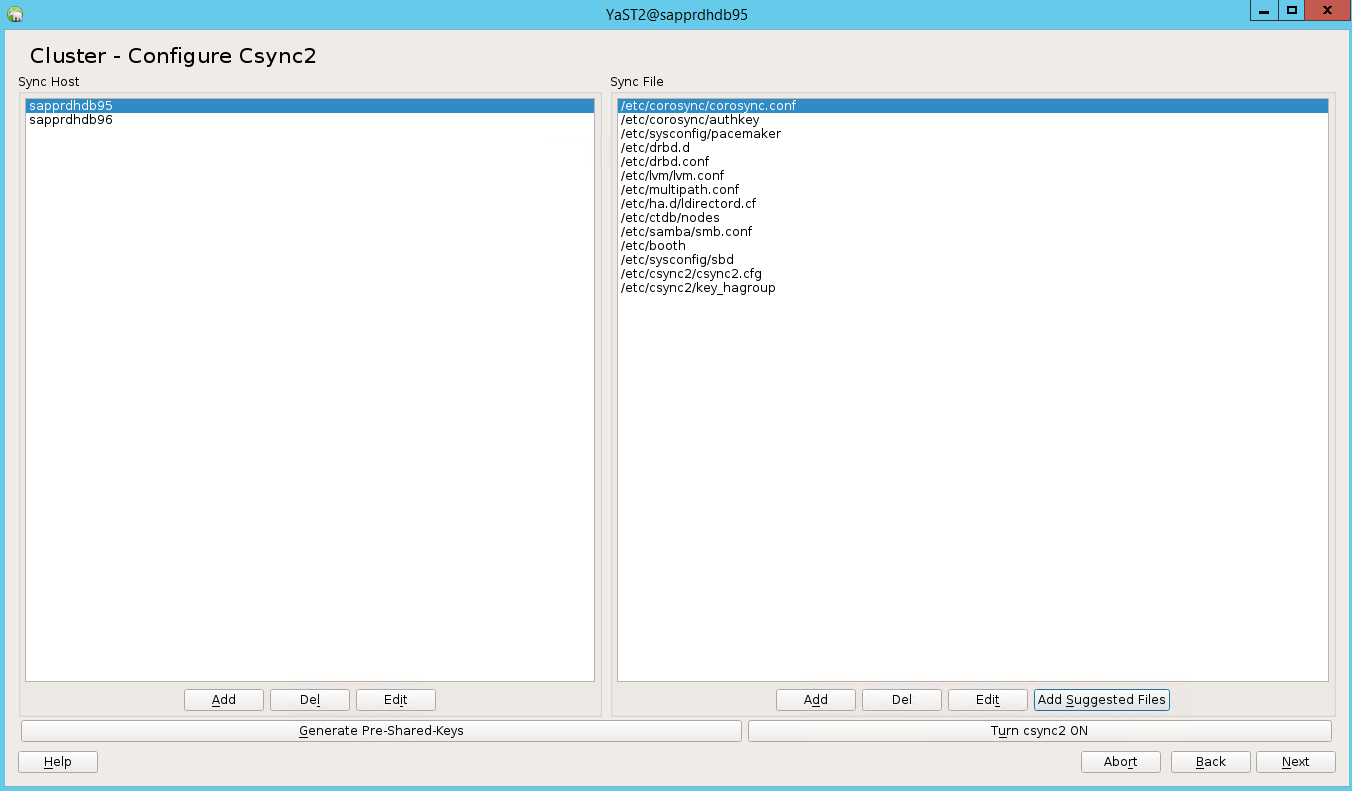
Sélectionnez Activer csync2.
Sélectionnez Générer des clés prépartagées.
Dans le message contextuel qui s’affiche, sélectionnez OK.
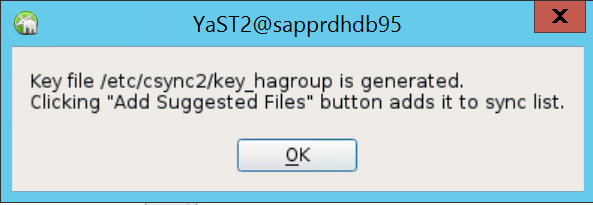
L’authentification est effectuée à l’aide des adresses IP et des clés prépartagées dans Csync2. Le fichier de clé est généré avec
csync2 -k /etc/csync2/key_hagroup.Copiez manuellement le fichier key_hagroup sur tous les membres du cluster après sa création. Veillez à copier le fichier à partir de node1 vers node2. Sélectionnez ensuite Suivant.
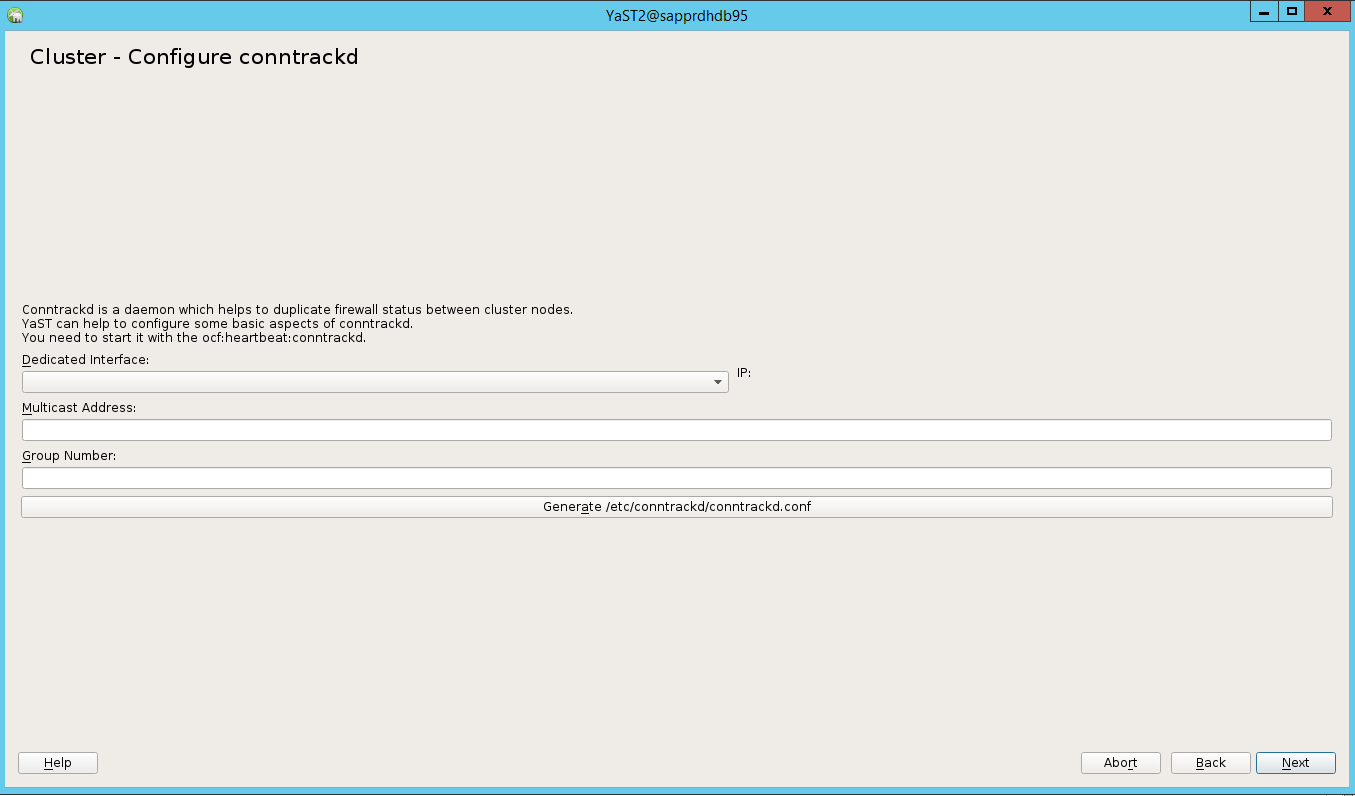
Dans l’option par défaut, le démarrage était désactivé. Activez-le pour que le service pacemaker se lance au démarrage. Vous pouvez effectuer votre choix en fonction de vos exigences d’installation.
Sélectionnez Suivant pour terminer la configuration du cluster.
Configurer l’agent de surveillance softdog
Ajoutez la ligne suivante à /etc/init.d/boot.local sur les deux nœuds.
modprobe softdog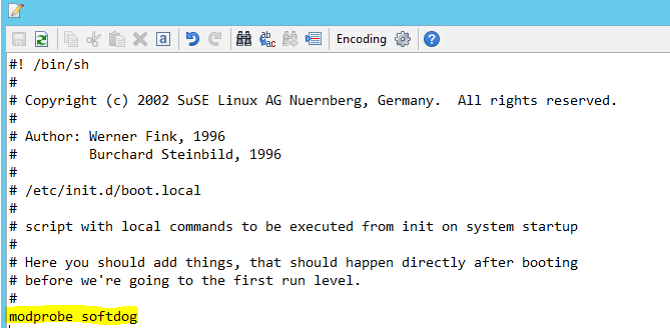
Utilisez la commande suivante pour mettre à jour le fichier /etc/sysconfig/sbd sur les deux nœuds.
SBD_DEVICE="<SBD Device Name>"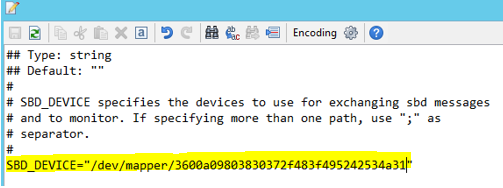
Chargez le module du noyau sur les deux nœuds en exécutant la commande suivante.
modprobe softdog
Utilisez la commande suivante pour vous assurer que softdog est exécuté sur les deux nœuds.
lsmod | grep dog
Utilisez la commande suivante pour démarrer l’appareil SBD sur les deux nœuds.
/usr/share/sbd/sbd.sh start
Utilisez la commande suivante pour tester le démon SBD sur les deux nœuds.
sbd -d <SBD Device Name> listLes résultats affichent deux entrées après la configuration sur les deux nœuds.

Envoyez le message de test suivant à l’un de vos nœuds.
sbd -d <SBD Device Name> message <node2> <message>Sur le second nœud (node2), utilisez la commande suivante pour vérifier l’état du message.
sbd -d <SBD Device Name> list
Pour adopter la configuration SBD, mettez à jour le fichier /etc/sysconfig/sbd comme suit sur les deux nœuds.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Utilisez la commande suivante pour démarrer le service pacemaker sur le nœud principal (node1).
systemctl start pacemaker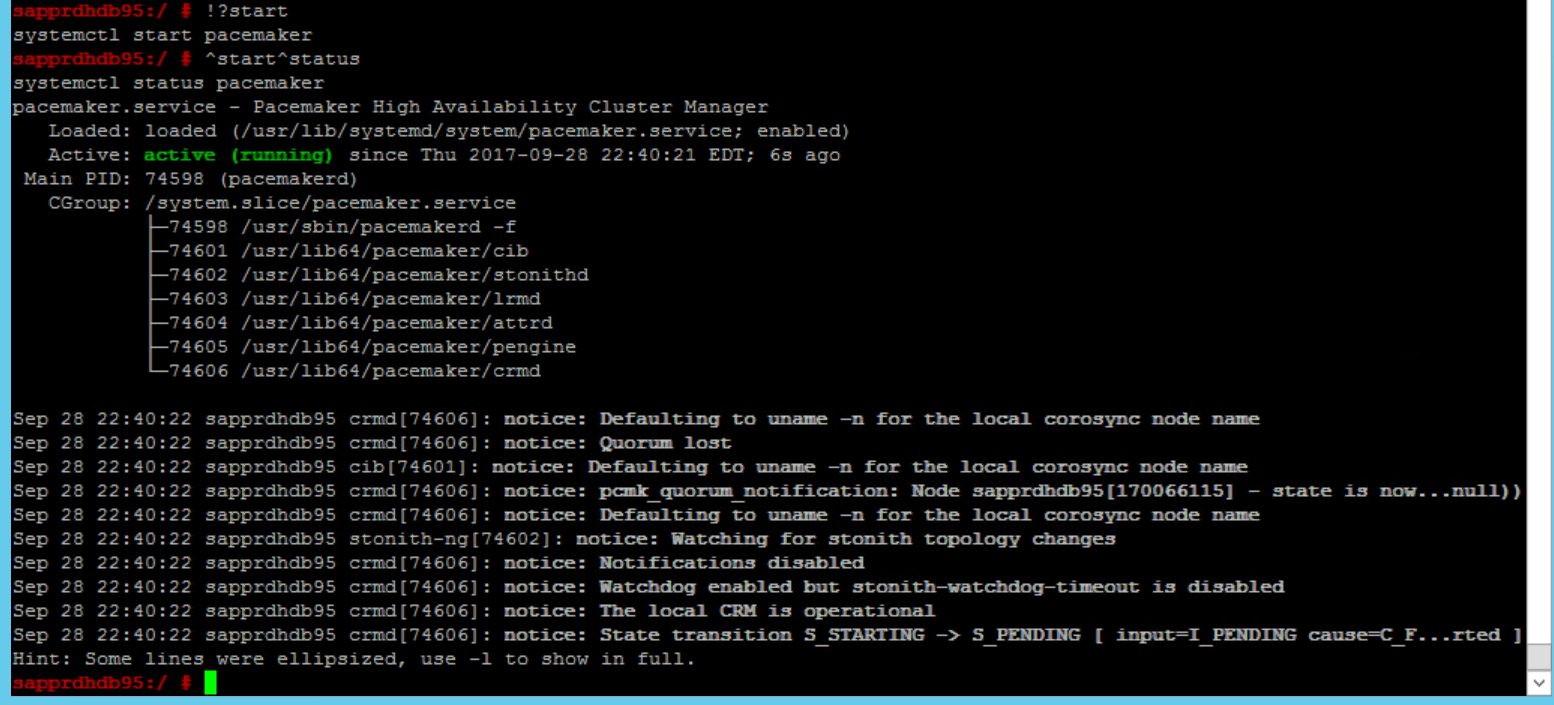
Si le service pacemaker échoue, consultez la section Scénario 5 : échec du service Pacemaker plus loin dans cet article.
Joindre le nœud au cluster
Exécutez la commande suivante sur node2 pour lui permettre de rejoindre le cluster.
ha-cluster-join
Si vous recevez une erreur lors de la jonction au cluster, consultez la section Scénario 6 : Node2 ne peut pas rejoindre le cluster plus loin dans cet article.
Valider le cluster
Utilisez la commande suivante pour vérifier et éventuellement démarrer le cluster pour la première fois sur les deux nœuds.
systemctl status pacemaker systemctl start pacemaker
Exécutez la commande suivante pour vérifier que les deux nœuds sont en ligne. Vous pouvez l’exécuter sur l’un ou l’autre des nœuds du cluster.
crm_mon
Vous pouvez également vous connecter à hawk pour vérifier l’état du cluster :
https://\<node IP>:7630. L’utilisateur par défaut est hacluster et le mot de passe est linux. Si nécessaire, vous pouvez changer le mot de passe avec la commandepasswd.
Configurer les propriétés et ressources du cluster
Cette section décrit les étapes permettant de configurer les ressources du cluster. Dans cet exemple, vous configurez les ressources suivantes. Vous pouvez configurer le reste (si nécessaire) en faisant référence au guide de la haute disponibilité SUSE.
- Bootstrap du cluster
- Appareil d’isolation
- Adresse IP virtuelle
Effectuez la configuration sur le nœud principal uniquement.
Créez le fichier de démarrage du cluster et configurez-le en ajoutant le texte suivant.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Utilisez la commande suivante pour ajouter la configuration au cluster.
crm configure load update crm-bs.txt
Configurez l’appareil d’isolation en ajoutant la ressource, en créant le fichier et en ajoutant du texte de la façon suivante.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Utilisez la commande suivante pour ajouter la configuration au cluster.
crm configure load update crm-sbd.txtAjoutez l’adresse IP virtuelle de la ressource en créant le fichier et en ajoutant le texte suivant.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Utilisez la commande suivante pour ajouter la configuration au cluster.
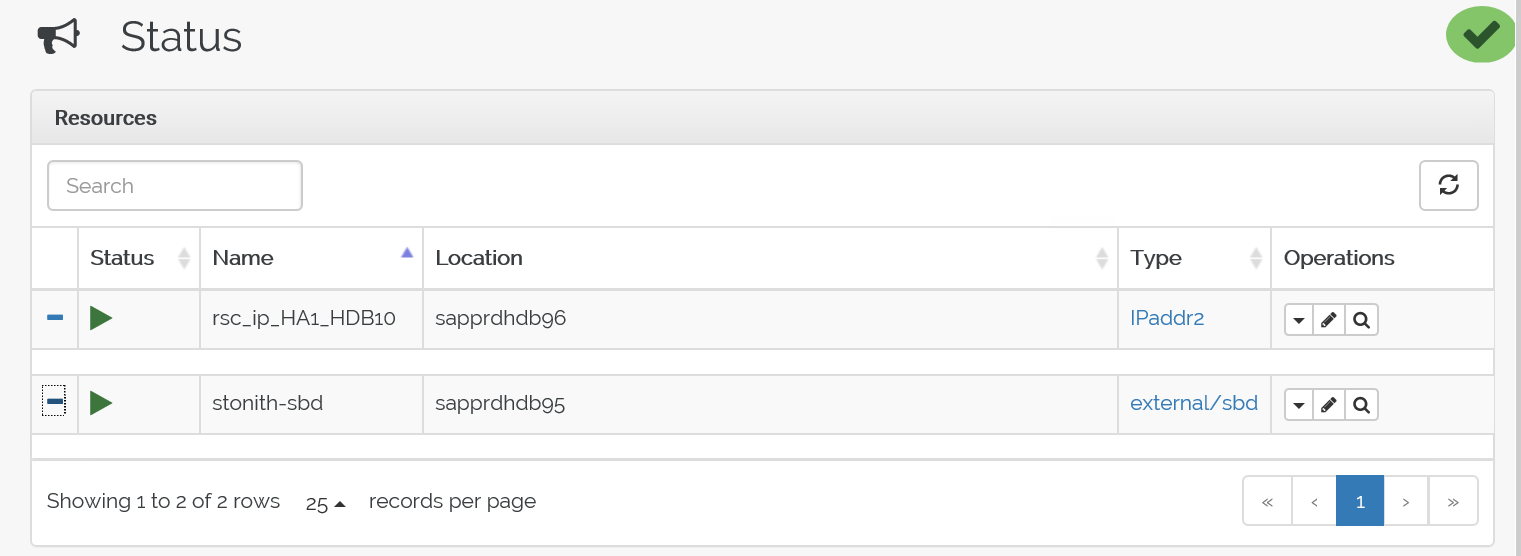
crm configure load update crm-vip.txtUtilisez la commande
crm_monpour valider les ressources.Les résultats montrent les deux ressources.

Vous pouvez également vérifier l’état à l’adresse https://<adresse IP du nœud>:7630/cib/live/state.
Tester le processus de basculement
Pour tester le processus de basculement, utilisez la commande suivante pour arrêter le service pacemaker sur node1.
Service pacemaker stopLes ressources basculent vers node2.
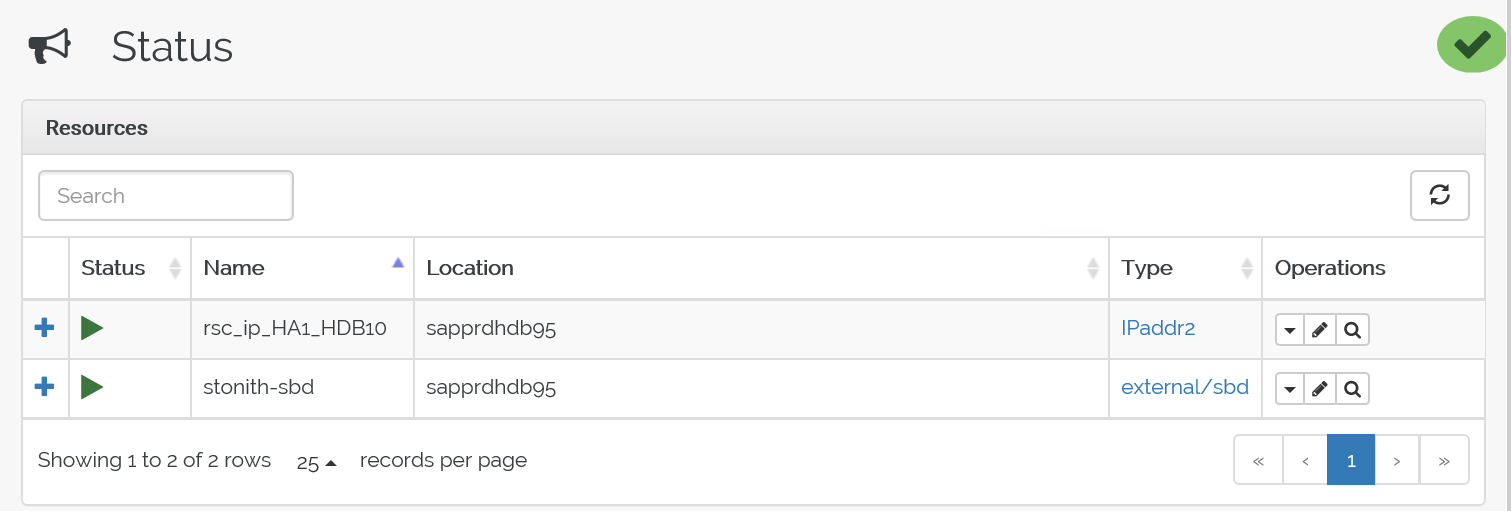
Arrêtez le service pacemaker sur node2 et les ressources basculent sur node1.
Voici l’état avant le basculement :
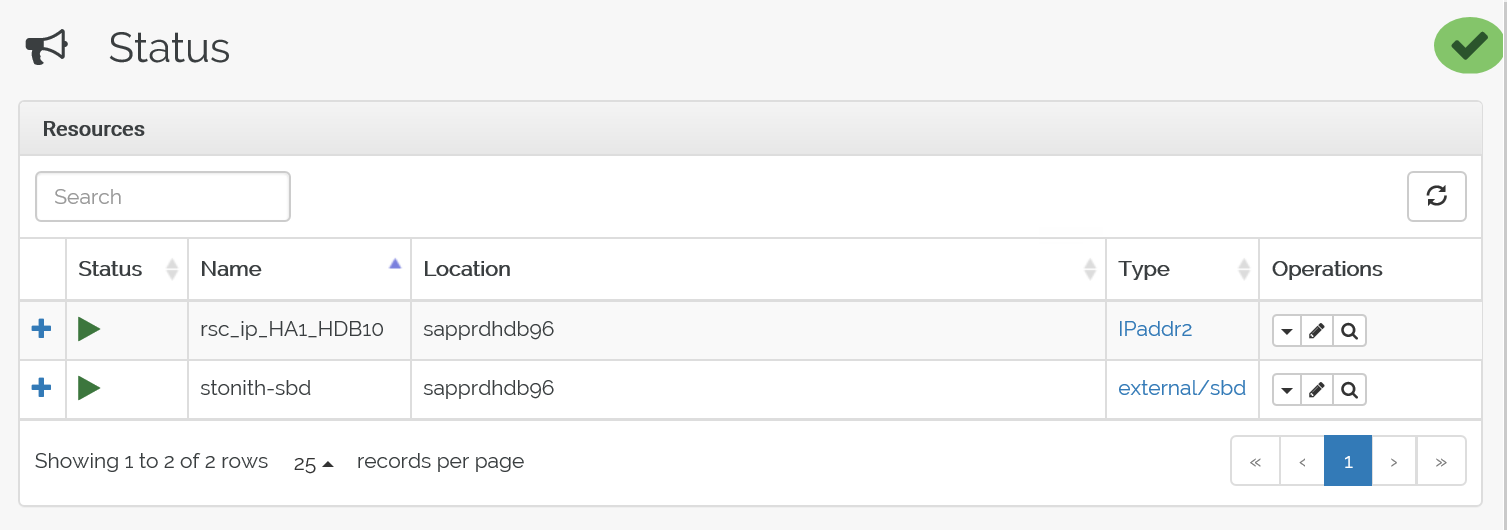
Voici l’état après le basculement :

Résolution des problèmes
Cette section décrit les scénarios d’échec que vous pouvez rencontrer pendant la configuration.
Scénario 1 : le nœud de cluster n’est pas en ligne
Si l’un des nœuds n’apparaît pas en ligne dans le Gestionnaire de cluster, vous pouvez essayer cette procédure pour le mettre en ligne.
Utilisez la commande suivante pour démarrer le service iSCSI.
service iscsid startUtilisez la commande suivante pour vous connecter à ce nœud iSCSI.
iscsiadm -m node -lLe résultat attendu ressemble à ce qui suit :
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scénario 2 : Yast2 ne montre pas la vue graphique
L’écran graphique de yast2 est utilisé pour configurer le cluster à haute disponibilité dans cet article. Si yast2 ne s’ouvre pas avec la fenêtre graphique indiquée et lance une erreur Qt, effectuez les étapes suivantes pour installer les packages requis. Si yast2 s’ouvre avec la fenêtre graphique, vous pouvez ignorer ces étapes.
Voici un exemple de l’erreur Qt :

Voici un exemple de la sortie attendue :
Assurez-vous d’être connecté en tant qu’utilisateur « racine » et d’avoir configuré SMT pour télécharger et installer les packages.
Accédez à yast>Logiciels>Gestion des logiciels>Dépendances, puis sélectionnez Installer les packages recommandés.
Notes
Effectuez les étapes sur les deux nœuds, afin de pouvoir accéder à la vue graphique yast2 à partir des deux nœuds.
La capture d’écran suivante représente l’écran attendu.
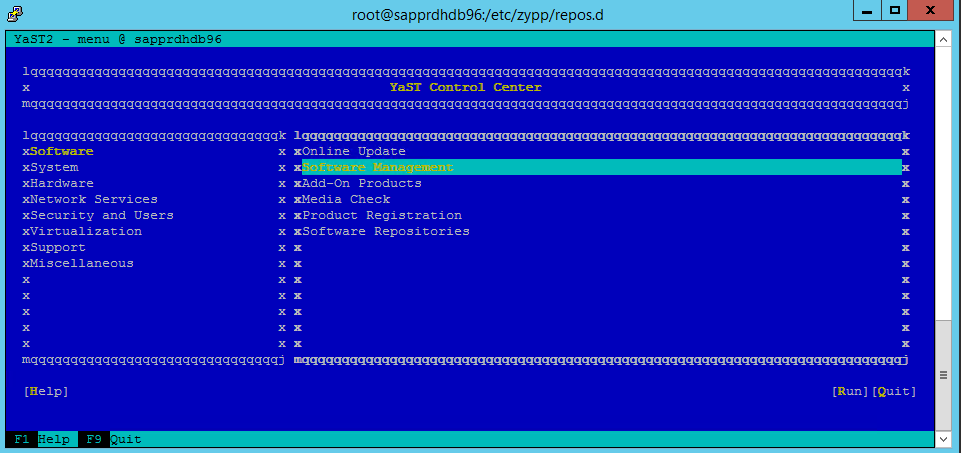
Sous Dépendances, sélectionnez Installer les packages recommandés.
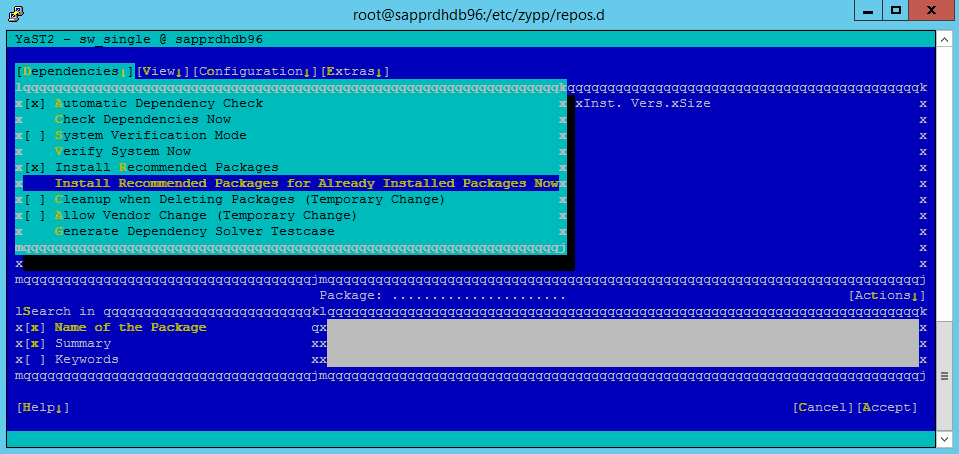
Passez en revue les modifications et sélectionnez OK.
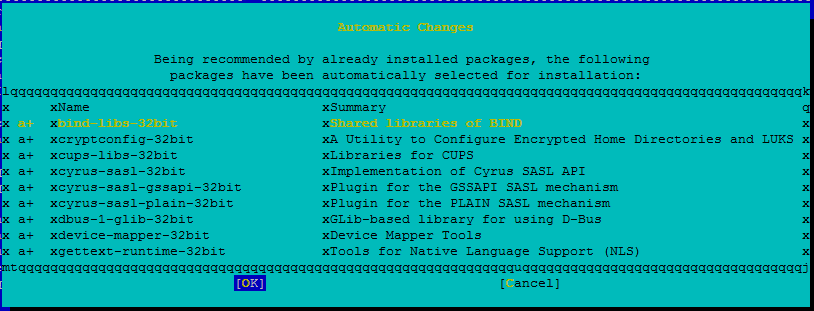
L’installation du package se poursuit.
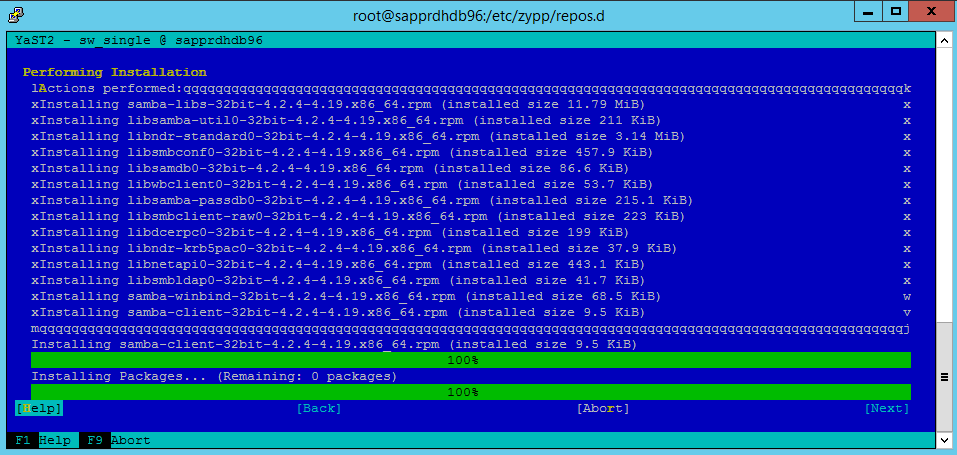
Sélectionnez Suivant.
Quand l’écran Installation réussie apparaît, sélectionnez Terminer.
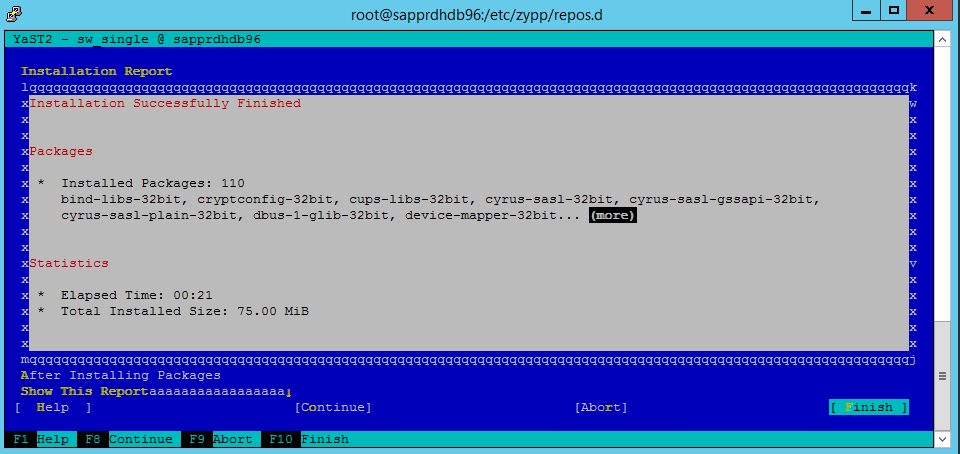
Utilisez les commandes suivantes pour installer les packages libqt4 et libyui-qt.
zypper -n install libqt4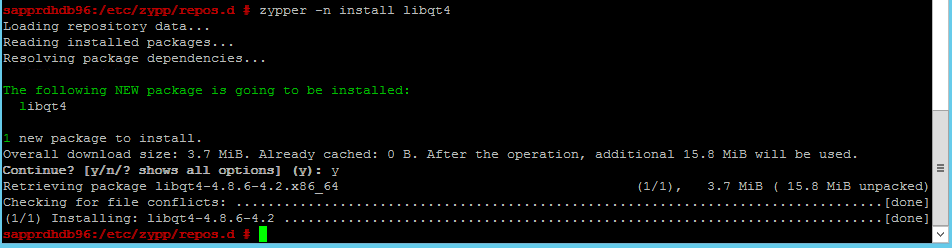
zypper -n install libyui-qt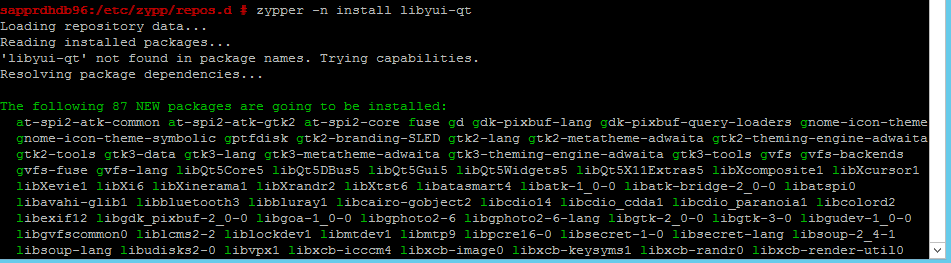

Yast2 peut maintenant ouvrir la vue graphique.
Scénario 3 : Yast2 ne montre pas l’option de haute disponibilité
Pour que l’option de haute disponibilité soit visible dans le Centre de contrôle yast2, vous devez installer les autres packages.
Accédez à Yast2>Logiciels>Gestion des logiciels. Puis sélectionnez Logiciels>Mise à jour en ligne.
Sélectionnez des patterns pour les éléments suivants. Puis sélectionnez Accepter.
- Base de serveur SAP HANA
- Compilateur et outils C/C++
- Haute disponibilité
- Base de serveur d’applications SAP
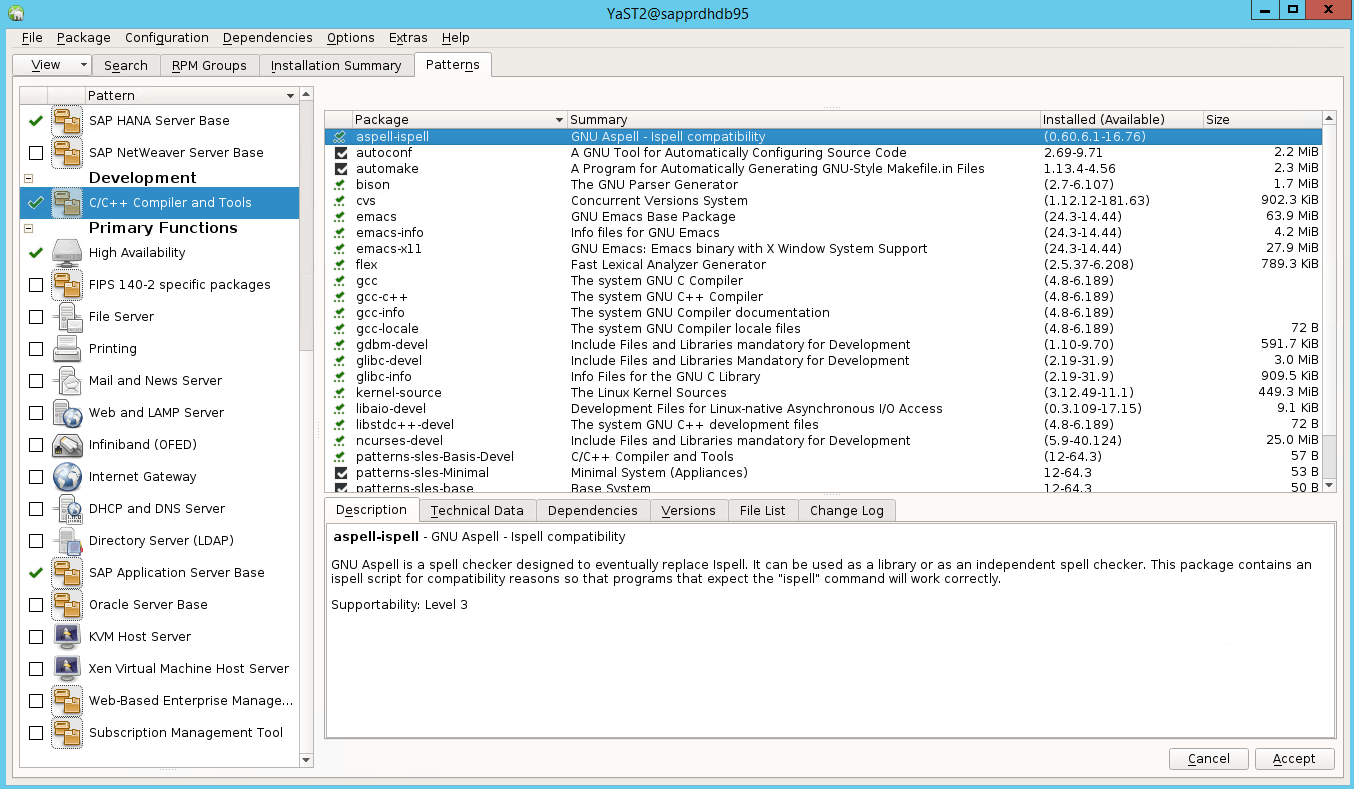
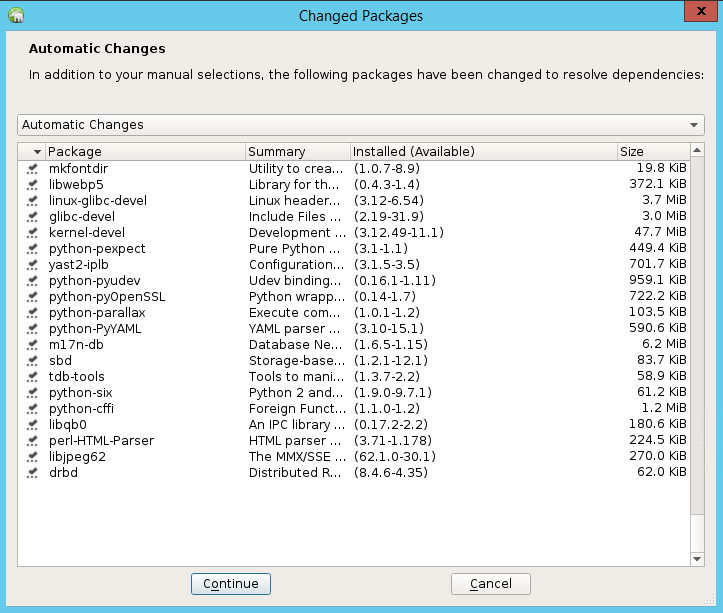
Dans la liste des packages qui ont été modifiés pour résoudre les dépendances, sélectionnez Continuer.
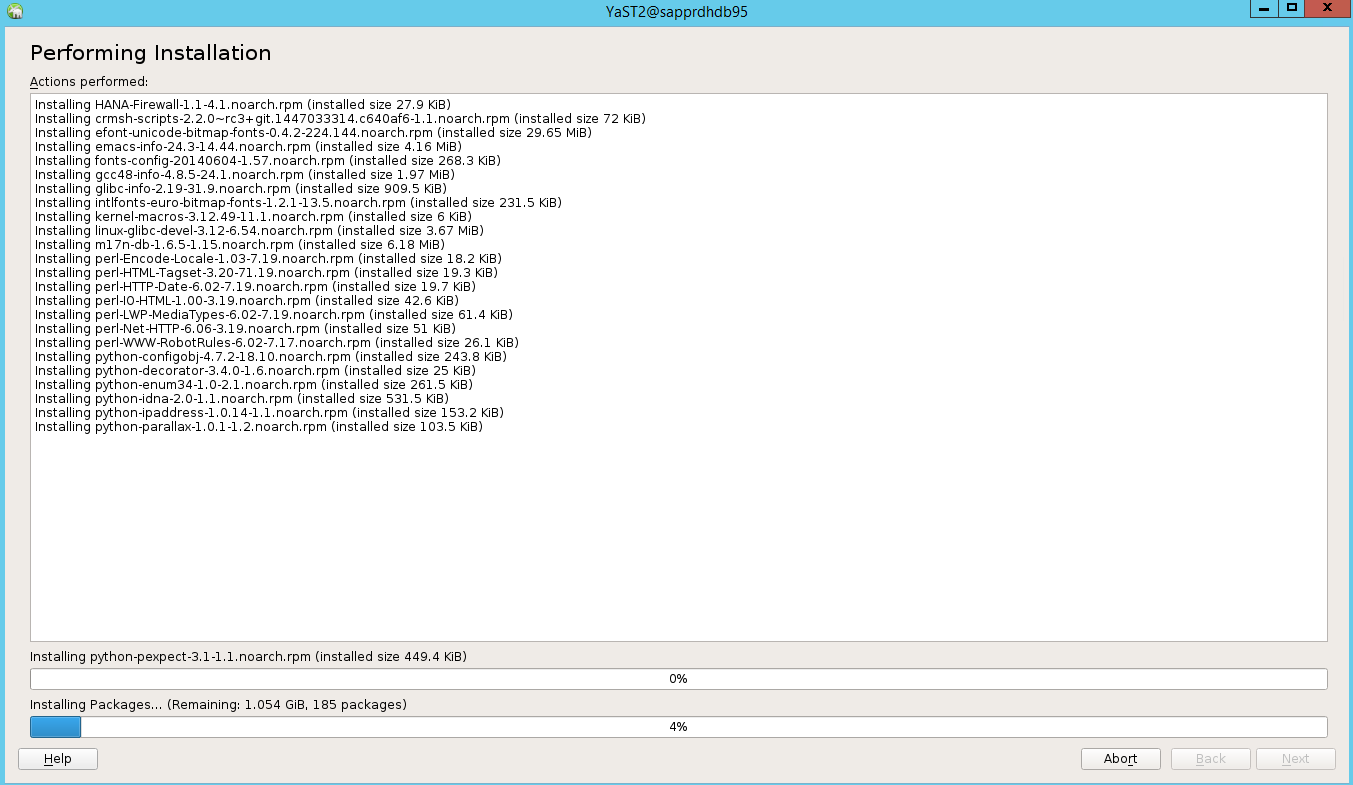
Dans la page d’état Exécution de l’installation, sélectionnez Suivant.
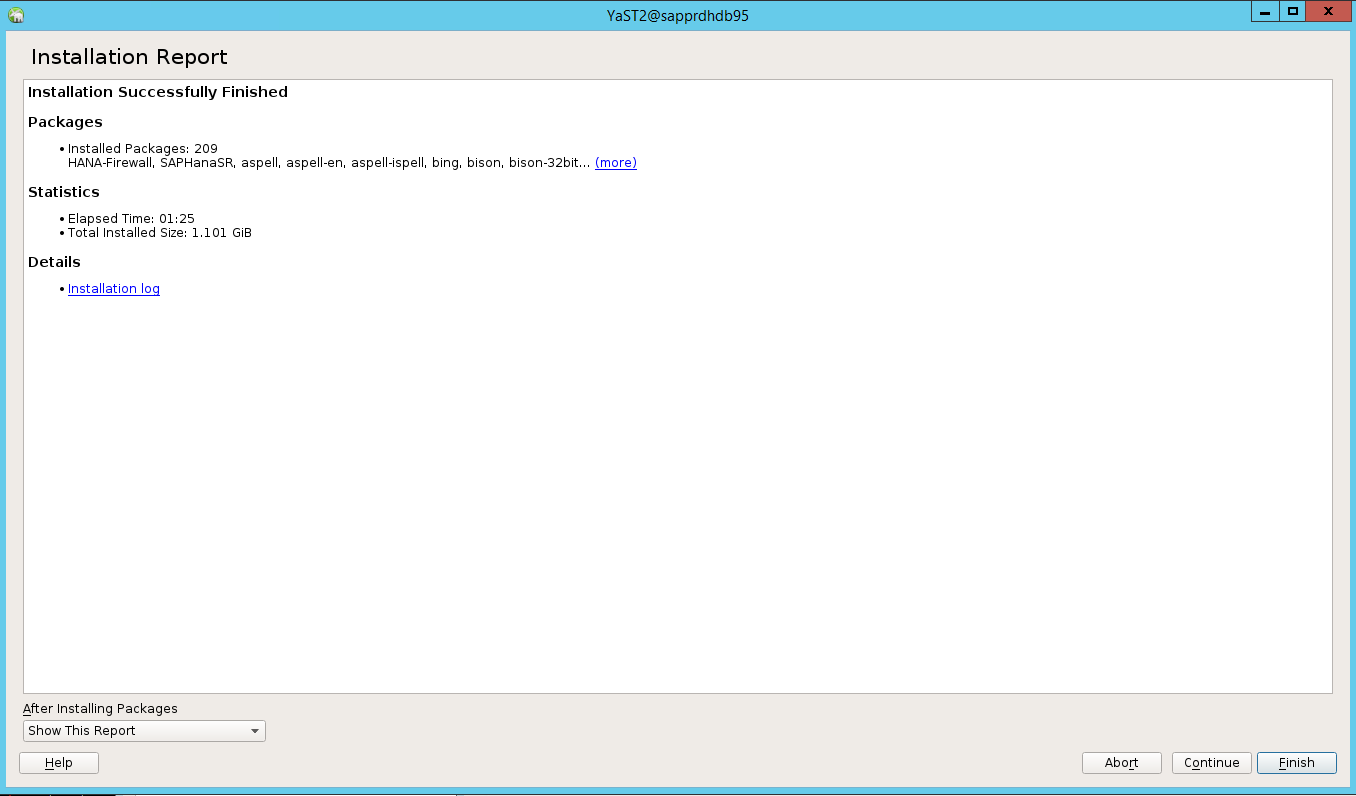
Une fois l’installation terminée, un rapport d’installation s’affiche. Sélectionnez Terminer.
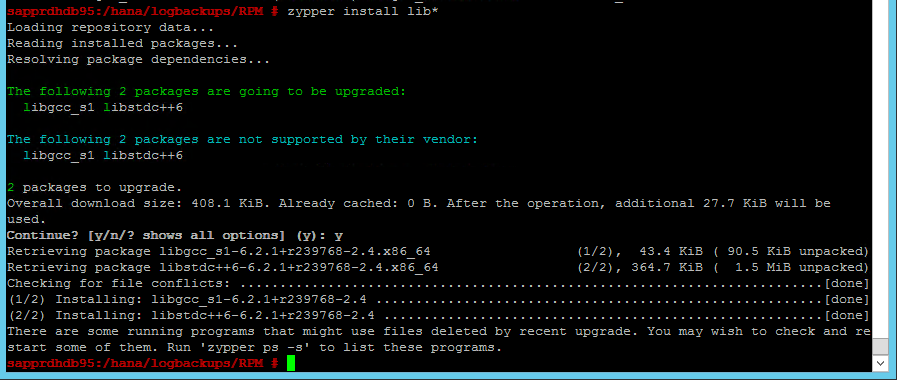
Scénario 4 : échec de l’installation de HANA avec une erreur des assemblys gcc
En cas d’échec de l’installation de HANA, vous pouvez recevoir l’erreur suivante.
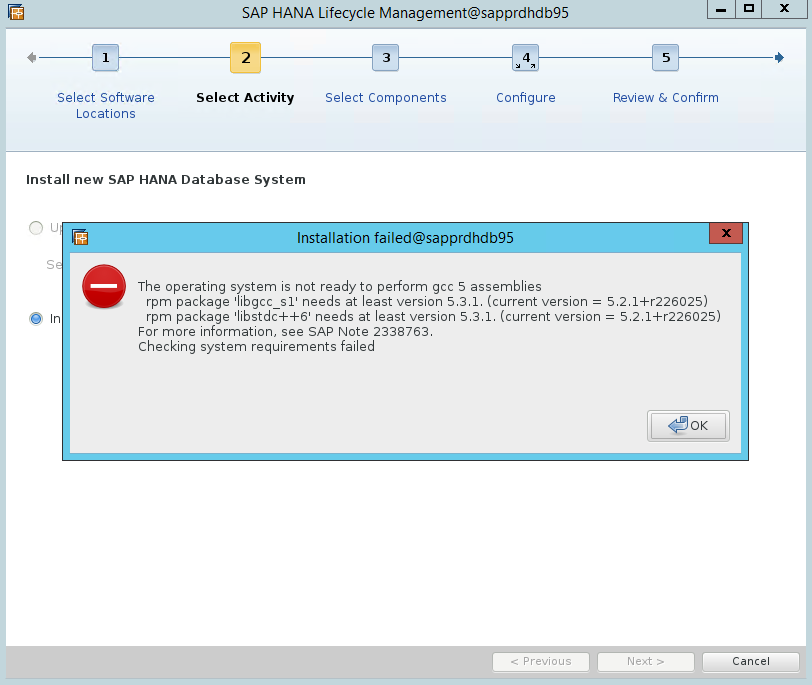
Pour résoudre le problème, installez les bibliothèques libgcc_sl et libstdc++6 comme indiqué dans la capture d’écran suivante.
Scénario 5 : échec du service Pacemaker
Les informations suivantes s’affichent si le service pacemaker ne peut pas démarrer.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
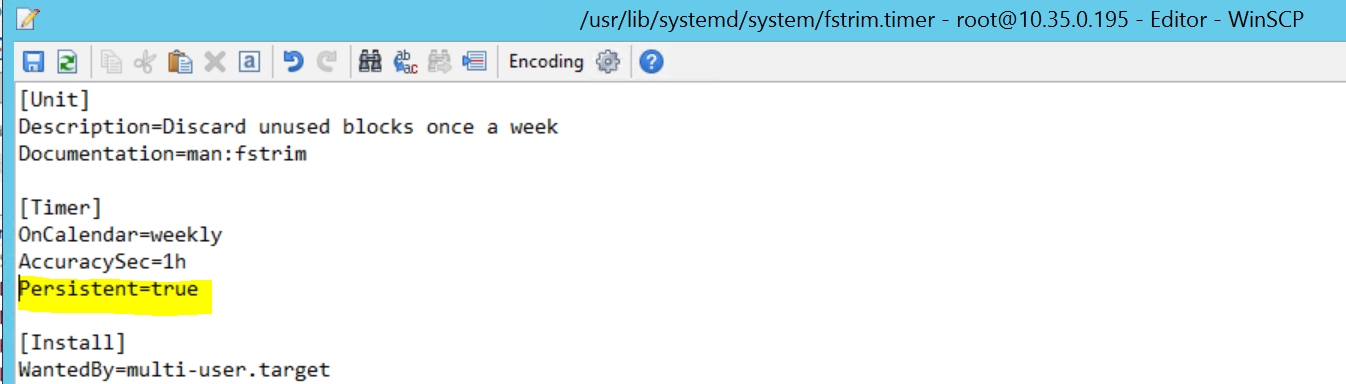
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Pour le corriger, supprimez la ligne suivante du fichier /usr/lib/systemd/system/fstrim.timer :
Persistent=true
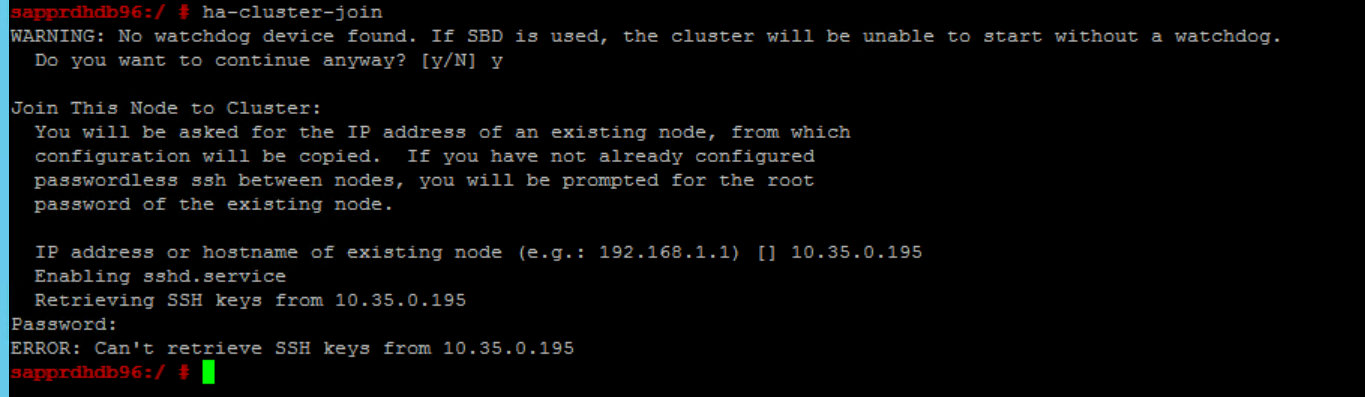
Scénario 6 : Node2 ne peut pas rejoindre le cluster
L’erreur suivante s’affiche s’il y a un problème avec la jonction de node2 au cluster existant par le biais de la commande ha-cluster-join.
ERROR: Can’t retrieve SSH keys from <Primary Node>
Pour corriger :
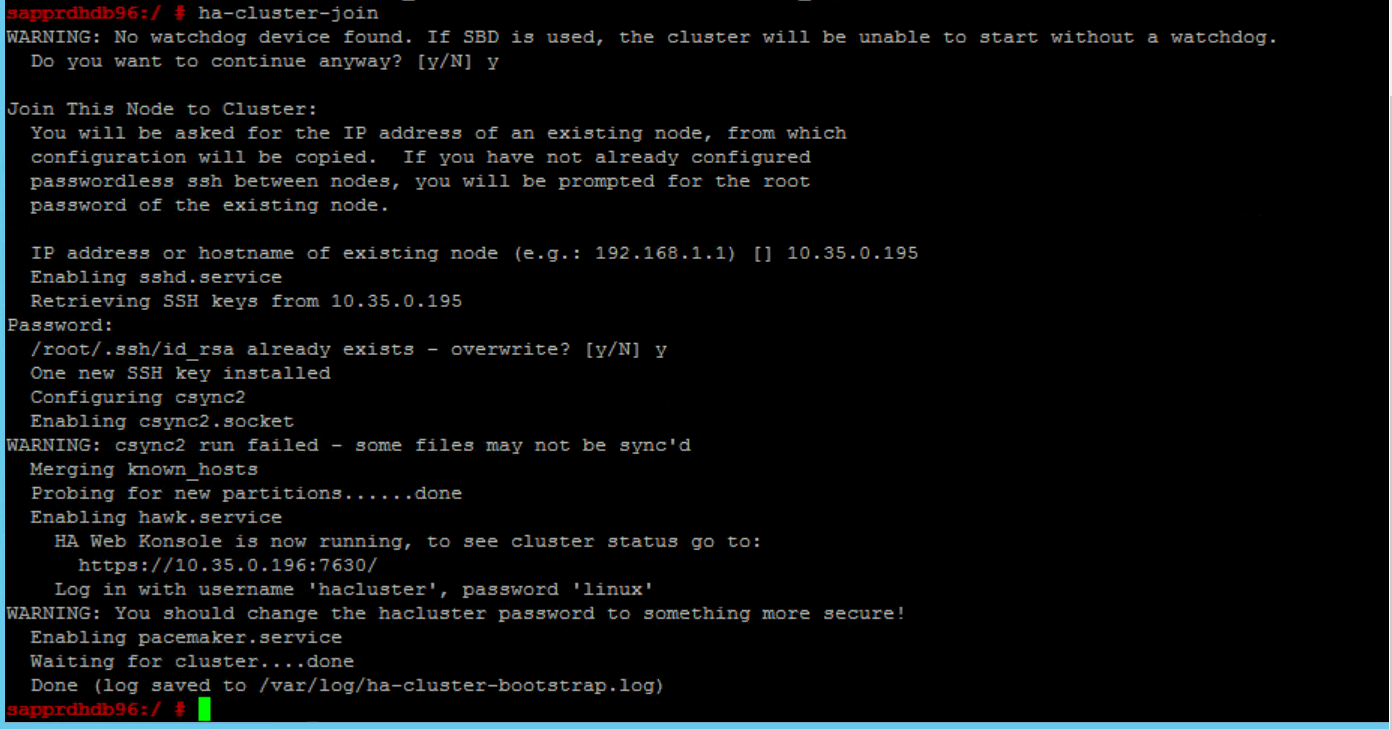
Exécutez les commandes suivantes sur les deux nœuds.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Vérifiez que node2 est ajouté au cluster.
Étapes suivantes
Vous trouverez plus d’informations sur la configuration de la haute disponibilité SUSE dans les articles suivants :
- SAP HANA SR Performance Optimized Scenario (site web SUSE)
- Isolation et appareils d’isolation (site web SUSE)
- Be Prepared for Using Pacemaker Cluster for SAP HANA – Part 1: Basics (blog SAP)
- Be Prepared for Using Pacemaker Cluster for SAP HANA – Part 2: Failure of Both Nodes (blog SAP)
- Sauvegarde et restauration du système d’exploitation