Haute disponibilité de la mise à l’échelle de SAP HANA avec Azure NetApp Files sur RHEL
Cet article explique comment configurer la réplication du système SAP HANA dans le cadre d’un déploiement de mise à l’échelle lorsque les systèmes de fichiers HANA sont montés via NFS à l’aide d’Azure NetApp Files. Les exemples de configuration et les commandes d’installation utilisent le numéro d’instance 03 et l’ID système HANA HN1. La réplication du système SAP HANA se compose d’un nœud principal et d’au moins un nœud secondaire.
Lorsque les étapes de ce document sont marquées des préfixes suivants, la signification est la suivante :
- [A] : l’étape s’applique à tous les nœuds.
- [1] : l’étape ne s’applique qu’à node1.
- [2] : l’étape ne s’applique qu’à node2.
Prérequis
Commencez par lire les notes et publications SAP suivantes :
- Note SAP 1928533, qui contient :
- Liste des tailles de machines virtuelles (VM) Azure prises en charge pour le déploiement du logiciel SAP.
- Des informations importantes sur la capacité en fonction de la taille des machines virtuelles Azure.
- Les combinaisons prises en charge de logiciels SAP, de systèmes d’exploitation et de bases de données.
- La version du noyau SAP requise pour Windows et Linux sur Microsoft Azure.
- La note SAP 2015553 répertorie les conditions préalables au déploiement de logiciels SAP pris en charge par SAP sur Azure.
- La note SAP 405827 répertorie les systèmes de fichiers recommandés pour les environnements HANA.
- La note SAP 2002167 recommande des paramètres de système d’exploitation pour Red Hat Enterprise Linux.
- La note SAP 2009879 conseille sur SAP HANA pour Red Hat Enterprise Linux.
- La note SAP 3108302 contient des recommandations SAP HANA pour Red Hat Enterprise Linux 9.x.
- La note SAP 2178632 contient des informations détaillées sur toutes les métriques de surveillance rapportées pour SAP sur Azure.
- La note SAP 2191498 contient la version requise de l’agent hôte SAP pour Linux sur Azure.
- La note SAP 2243692 contient des informations sur les licences SAP sur Linux dans Azure.
- La note SAP 1999351 contient des informations supplémentaires sur le dépannage de l’extension Azure Enhanced Monitoring pour SAP.
- Le wiki de la communauté SAP contient toutes les notes SAP nécessaires pour Linux.
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux
- Déploiement de machines virtuelles Azure pour SAP sur Linux
- Déploiement SGBD de machines virtuelles Azure pour SAP sur Linux
- Réplication du système SAP HANA dans un cluster Pacemaker
- Documentation générale RHEL :
- Vue d’ensemble des modules complémentaires de haute disponibilité
- Administration des modules complémentaires de haute disponibilité
- Référence des modules complémentaires de haute disponibilité
- Configurer la réplication du système SAP HANA dans le cadre d’une mise à l'échelle dans un cluster Pacemaker lorsque les systèmes de fichiers HANA se trouvent sur des partages NFS
- Documentation RHEL spécifique à Azure :
- Stratégies de prise en charge des clusters à haute disponibilité RHEL - Machines virtuelles Microsoft Azure en tant que membres du cluster
- Installation et configuration d’un cluster à haute disponibilité Red Hat Enterprise Linux 7.4 (et versions ultérieures) sur Microsoft Azure
- Configurer la réplication du système SAP HANA de mise à l'échelle dans un cluster Pacemaker lorsque les systèmes de fichiers HANA se trouvent sur des partages NFS
- Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA
Vue d’ensemble
Traditionnellement, dans un environnement de mise à l’échelle, tous les systèmes de fichiers pour SAP HANA sont montés à partir du stockage local. La configuration de la haute disponibilité pour la réplication du système SAP HANA sur Red Hat Enterprise Linux est publiée dans Configurer la réplication du système SAP HANA sur RHEL.
Pour atteindre la haute disponibilité SAP HANA d’un système de mise à l'échelle sur les partages NFS d’Azure NetApp Files, nous avons besoin d’une configuration supplémentaire des ressources dans le cluster afin que les ressources HANA soient récupérées lorsqu’un nœud perd l’accès aux partages NFS sur Azure NetApp Files. Le cluster gère les montages NFS, ce qui lui permet de surveiller l’intégrité des ressources. Les dépendances entre les montages de système de fichiers et les ressources SAP HANA sont appliquées.
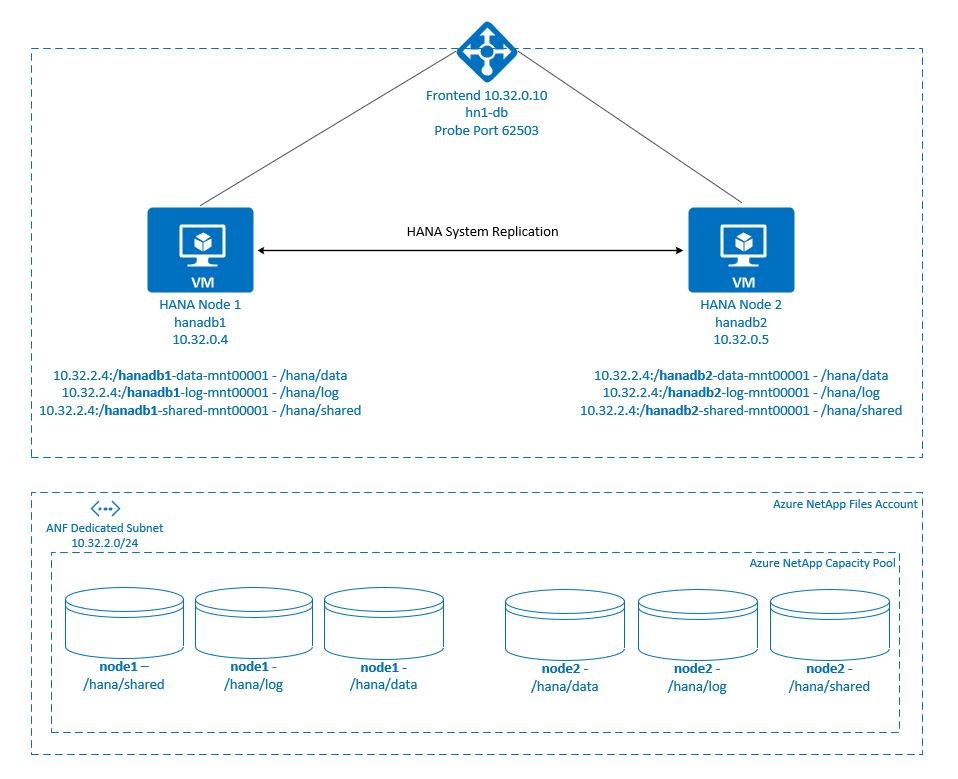 .
.
Les systèmes de fichiers SAP HANA sont montés sur des partages NFS à l’aide d’Azure NetApp Files sur chaque nœud. Les systèmes de fichiers /hana/data, /hana/loget /hana/shared sont uniques et propres à chaque nœud.
Monté sur node1 (hanadb1) :
- 10.32.2.4:/hanadb1-data-mnt00001 sur /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 sur /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 sur /hana/shared
Monté sur node2 (hanadb2) :
- 10.32.2.4:/hanadb2-data-mnt00001 sur /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 sur /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 sur /hana/shared
Remarque
Les systèmes de fichiers /hana/shared, /hana/dataet /hana/log ne sont pas partagés entre les deux nœuds. Chaque nœud de cluster a ses propres systèmes de fichiers distincts.
La configuration de la réplication du système SAP HANA utilise un nom d’hôte virtuel dédié et des adresses IP virtuelles. Sur Azure, un équilibreur de charge est nécessaire pour utiliser une adresse IP virtuelle. La configuration présentée montre un équilibreur de charge avec :
- Adresse IP frontale : 10.32.0.10 pour hn1-db
- Port de la sonde d’intégrité : 62503
Configurer l’infrastructure Azure NetApp Files
Avant de poursuivre la configuration de l’infrastructure Azure NetApp Files, familiarisez-vous avec la documentation Azure NetApp Files.
Azure NetApp Files est disponible dans plusieurs régions Azure. Vérifiez si la région Azure que vous avez sélectionnée est compatible avec Azure NetApp Files.
Pour des informations sur la disponibilité d’Azure NetApp Files par région Azure, consultez Disponibilité d’Azure NetApp Files par région Azure.
Considérations importantes
Lorsque vous créez vos volumes Azure NetApp Files pour les systèmes de mise à l'échelle SAP HANA, tenez compte des considérations importantes documentées dans les volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA.
Dimensionnement de la base de données HANA sur Azure NetApp Files
Le débit d’un volume NetApp Azure Files est une fonction de la taille de volume et du niveau de service, comme décrit dans Niveau de service pour Azure NetApp Files.
Lors de la conception de l’infrastructure pour SAP HANA sur Azure avec Azure NetApp Files, tenez compte des recommandations contenues dans les volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA.
La configuration de cet article est présentée avec des volumes Azure NetApp Files simples.
Important
Pour les systèmes de production, pour lesquels les performances sont essentielles, nous vous recommandons d’évaluer et d’envisager d’utiliser le groupe de volumes d’application Azure NetApp Files pour SAP HANA.
Déployer des ressources Azure NetApp Files
Les instructions suivantes supposent que vous avez déjà déployé votre réseau virtuel Azure. Les ressources Azure NetApp Files et les machines virtuelles, où les ressources Azure NetApp Files seront montées, doivent être déployées dans le même réseau virtuel Azure ou dans des réseaux virtuels Azure appairés.
Créez un compte NetApp dans la région Azure sélectionnée en suivant les instructions de la page Création d’un compte NetApp.
Configurez un pool de capacité Azure NetApp Files en suivant les instructions de la page Configuration d’un pool de capacité Azure NetApp Files.
L’architecture HANA présentée dans cet article utilise un seul pool de capacité Azure NetApp Files au niveau de service Ultra. Pour les charges de travail HANA sur Azure, nous vous recommandons d’utiliser un niveau de serviceUltra ou Premium d’Azure NetApp Files.
Déléguez un sous-réseau à Azure NetApp Files, comme décrit dans les instructions de la page Déléguer un sous-réseau à Azure NetApp Files.
Déployez des volumes Azure NetApp Files en suivant les instructions de la page Créer un volume NFS pour Azure NetApp Files.
Lors du déploiement des volumes, veillez à sélectionner la version NFSv4.1, . Déployez les volumes dans le sous-réseau Azure NetApp Files désigné. Les adresses IP des volumes Azure NetApp sont attribuées automatiquement.
Gardez à l’esprit que les ressources Azure NetApp Files et les machines virtuelles Azure doivent être dans le même réseau virtuel Azure ou dans des réseaux virtuels Azure appairés. Par exemple,
hanadb1-data-mnt00001ethanadb1-log-mnt00001sont les noms de volumes etnfs://10.32.2.4/hanadb1-data-mnt00001etnfs://10.32.2.4/hanadb1-log-mnt00001sont les chemins d’accès aux fichiers pour les volumes Azure NetApp Files.Sur hanadb1 :
- Volume hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
Sur hanadb2 :
- Volume hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Remarque
Toutes les commandes permettant de monter /hana/shared dans cet article sont présentées pour les volumes /hana/shared NFSv4.1.
Si vous avez déployé les volumes /hana/shared en tant que volumes NFSv3, n’oubliez pas d’ajuster les commandes de montage pour /hana/shared en conséquence.
Préparer l’infrastructure
La Place de marché Azure contient des images qualifiées pour SAP HANA avec le module complémentaire de haute disponibilité, que vous pouvez utiliser pour déployer de nouvelles machines virtuelles en utilisant différentes versions de Red Hat.
Déployer des machines virtuelles Linux manuellement via le portail Azure
Ce document part du principe que vous avez déjà déployé un groupe de ressources, un réseau virtuel Azure et un sous-réseau.
Déployez des machines virtuelles pour SAP HANA. Choisissez une image RHEL appropriée et prise en charge pour le système HANA. Vous pouvez déployer une machine virtuelle dans l’une des options de disponibilité : groupe de machines virtuelles identiques, zone de disponibilité ou groupe à haute disponibilité.
Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous envisagez d’utiliser dans votre déploiement. Vous pouvez rechercher les types de machines virtuelles certifiées SAP HANA et leurs versions de système d’exploitation sur la page Plateformes IaaS certifiées SAP HANA. Veillez à consulter les détails du type de machine virtuelle pour obtenir la liste complète des versions de système d’exploitation prises en charge par SAP HANA pour le type de machine virtuelle spécifique.
Configurer l’équilibrage de charge Azure
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner un équilibreur de charge existant dans la section réseau. Suivez les étapes ci-dessous pour configurer l’équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données HANA.
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Pour plus d’informations sur les ports requis pour SAP HANA, consultez le chapitre Connections to Tenant Databases (Connexions aux bases de données locataires) dans le guide SAP HANA Tenant Databases (Bases de données locataires SAP HANA) ou la Note SAP 2388694.
Remarque
Lorsque des machines virtuelles sans adresse IP publique sont placées dans le pool back-end d’une instance interne d’Azure Standard Load Balancer (sans adresse IP publique), il n’y a pas de connectivité Internet sortante à moins qu’une configuration supplémentaire soit effectuée pour permettre le routage vers des points de terminaison publics. Pour plus d’informations sur la façon d’obtenir une connectivité sortante, consultez Connectivité de point de terminaison public pour les machines virtuelles avec Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
N’activez pas les horodateurs TCP sur les machines virtuelles Azure placées derrière l’Équilibreur de charge Azure. L’activation de timestamps TCP peut entraîner l’échec des sondes d’intégrité. Définissez le paramètre net.ipv4.tcp_timestamps sur 0. Pour plus d’informations, consultez Sondes d’intégrité Load Balancer et la note SAP 2382421.
Monter le volume Azure NetApp Files
[A] Créez des points de montage pour les volumes de base de données HANA.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Vérifiez le paramètre de domaine NFS. Assurez-vous que le domaine est configuré en tant que domaine Azure NetApp Files par défaut, c’est-à-dire defaultv4iddomain.com, et que le mappage est défini sur nobody.
sudo cat /etc/idmapd.confExemple de sortie :
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportant
Veillez à définir le domaine NFS dans
/etc/idmapd.confsur la machine virtuelle pour qu’il corresponde à la configuration de domaine par défaut sur Azure NetApp Files : defaultv4iddomain.com. En cas d’incompatibilité entre la configuration de domaine sur le client NFS (c’est-à-dire, la machine virtuelle) et le serveur NFS (par exemple la configuration Azure NetApp Files), les autorisations pour les fichiers sur les volumes Azure NetApp montés sur les machines virtuelles s’affichent en tant quenobody.[1] Montez les volumes spécifiques aux nœuds sur node1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Montez les volumes spécifiques aux nœuds sur node2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Vérifiez que tous les volumes HANA sont montés avec la version NFSv4 du protocole NFS.
sudo nfsstat -mVérifiez que l’indicateur
versest défini sur 4.1. Exemple depuis hanadb1 :/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Vérifiez nfs4_disable_idmapping. Cette option doit avoir la valeur Y. Pour créer la structure de répertoire où se trouve nfs4_disable_idmapping, exécutez la commande de montage. Vous ne serez pas en mesure de créer manuellement le répertoire sous
/sys/modules, car l’accès est réservé pour le noyau et les pilotes.Recherchez le chemin
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingSi vous devez définir
nfs4_disable_idmappingsur :sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingRendre la configuration permanente.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPour plus d’informations sur la modification du paramètre
nfs_disable_idmapping, consultez la base de connaissances Red Hat.
Installation de SAP HANA
[A] Configurez la résolution de nom d’hôte pour tous les hôtes.
Vous pouvez utiliser un serveur DNS ou modifier le fichier
/etc/hostssur tous les nœuds. Cet exemple vous explique comment utiliser le fichier/etc/hosts. Remplacez l’adresse IP et le nom d’hôte dans les commandes suivantes :sudo vi /etc/hostsInsérez les lignes suivantes dans le fichier
/etc/hosts. Changez l’adresse IP et le nom d’hôte en fonction de votre environnement.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Préparez l’OS pour l’exécution de SAP HANA sur Azure NetApp avec NFS, comme indiqué dans la note SAP 3024346 - Paramètres du noyau Linux pour NFS NetApp. Créez un fichier de configuration
/etc/sysctl.d/91-NetApp-HANA.confpour les paramètres de configuration de NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confAjoutez les entrées suivantes au fichier de configuration.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Créer le fichier de configuration
/etc/sysctl.d/ms-az.confavec d’autres paramètres d’optimisation.sudo vi /etc/sysctl.d/ms-az.confAjoutez les entrées suivantes au fichier de configuration.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Conseil
Évitez de définir
net.ipv4.ip_local_port_rangeetnet.ipv4.ip_local_reserved_portsde manière explicite dans les fichiers de configurationsysctl, pour permettre à l’agent hôte SAP de gérer les plages de ports. Pour plus d’informations, consultez la note SAP 2382421.[A] Ajustez les paramètres
sunrpc, comme recommandé dans la note SAP 3024346 - Paramètres noyau Linux pour NFS NetApp.sudo vi /etc/modprobe.d/sunrpc.confInsérez la ligne suivante :
options sunrpc tcp_max_slot_table_entries=128[A] Procédez à la configuration du système d’exploitation RHEL pour HANA.
Configurez le système d’exploitation comme décrit dans les notes SAP suivantes en fonction de votre version de RHEL :
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (SAP HANA DB : Paramètres de système d’exploitation recommandés pour RHEL 7)
- 2777782 – Base de données SAP HANA : paramètres de système d’exploitation recommandés pour RHEL 8
- 2455582 – Linux : Exécution d’applications SAP compilées avec GCC 6.x
- 2593824 – Linux : Exécution d’applications SAP compilées avec GCC 7.x
- 2886607 – Linux : Exécution d’applications SAP compilées avec GCC 9.x
[A] Installez SAP HANA.
À partir de HANA 2.0 SPS 01, MDC est l’option par défaut. Quand vous installez le système HANA, SYSTEMDB et un locataire avec le même SID sont créés simultanément. Dans certains cas, vous ne souhaitez pas utiliser le locataire par défaut. Si vous ne souhaitez pas créer de locataire initial pendant l’installation, vous pouvez suivre la note SAP 2629711.
Exécutez le programme hdblcm depuis le DVD HANA. Entrez les valeurs suivantes à l’invite :
- Choisir une installation : entrez 1 (pour l’installation).
- Sélectionner des composants supplémentaires pour l’installation : entrez 1.
- Entrer le chemin d’accès pour l’installation [/hana/shared] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer le nom d’hôte local [..] : appuyez sur Entrée pour accepter la valeur par défaut. Do you want to add additional hosts to the system? (o/n) [n] : n.
- Entrer l’ID de système SAP HANA : entrez HN1.
- Entrer le numéro d’instance [00] : entrez 03.
- Sélectionner Mode base de données / Entrer Index [1] : appuyez sur Entrée pour accepter la valeur par défaut.
- Sélectionner Utilisation du système / Entrer Index [4] : entrez 4 (pour personnalisation).
- Entrer l’emplacement des volumes de données [/hana/data] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer l’emplacement des volumes de fichier journal [/hana/log] : appuyez sur Entrée pour accepter la valeur par défaut.
- Restrict maximum memory allocation? [n] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer le nom d’hôte du certificat pour l’hôte « ... » [...] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer le mot de passe de l’agent utilisateur hôte SAP (sapadm) : entrez le mot de passe de l’agent utilisateur hôte.
- Confirmer le mot de passe de l’agent utilisateur hôte SAP (sapadm) : entrez de nouveau le mot de passe de l’agent utilisateur hôte pour confirmer.
- Entrer le mot de passe d'administrateur système (hn1adm) : entrez le mot de passe d’administrateur système.
- Confirmer le mot de passe d'administrateur système (hn1adm) : entrez de nouveau le mot de passe d’administrateur système.
- Entrer le répertoire d’accueil de l’administrateur système [/usr/sap/HN1/home] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer l’interpréteur de commandes de connexion de l’administrateur système [/bin/sh] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer l’ID utilisateur de l’administrateur système [1001] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer l’ID du groupe d'utilisateurs (sapsys) [79] : appuyez sur Entrée pour accepter la valeur par défaut.
- Entrer le mot de passe utilisateur (SYSTÈME) de la base de données : entrez le mot de passe utilisateur de la base de données.
- Confirmer le mot de passe utilisateur (SYSTÈME) de la base de données : entrez de nouveau le mot de passe utilisateur de la base de données.
- Restart system after machine reboot? [n] : appuyez sur Entrée pour accepter la valeur par défaut.
- Voulez-vous continuer ? (o/n): validez le résumé. Tapez Y pour continuer.
[A] Mettre à niveau l’agent hôte SAP.
Téléchargez la dernière archive de l’agent hôte SAP à partir du SAP Software Center et exécutez la commande suivante pour mettre à niveau l’agent. Remplacez le chemin d’accès à l’archive pour pointer vers le fichier que vous avez téléchargé :
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Configurer un pare-feu.
Créez la règle de pare-feu pour le port de la sonde d’intégrité Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
Configurer la réplication de système SAP HANA
Suivez les étapes décrites dans Configurer la réplication du système SAP HANA pour configurer la réplication du système SAP HANA.
Configuration de clusters
Cette section décrit les étapes nécessaires au bon fonctionnement du cluster lorsque SAP HANA est installé sur des partages NFS à l’aide d’Azure NetApp Files.
Créez un cluster Pacemaker
Suivez les étapes décrites dans Configurer Pacemaker sur Red Hat Enterprise Linux dans Azure pour créer un cluster Pacemaker de base pour ce serveur HANA.
Important
Avec SAP Startup Framework basé sur systemd, les instances SAP HANA peuvent désormais être gérées par systemd. La version minimale requise de Red Hat Enterprise Linux (RHEL) est RHEL 8 pour SAP. Comme indiqué dans la note SAP 3189534, pour les nouvelles installations de SAP HANA SPS07 révision 70 ou ultérieure, ou les mises à jour des systèmes HANA vers HANA 2.0 SPS07 révision 70 ou ultérieure, SAP Startup Framework est automatiquement inscrit auprès de systemd.
Lorsque des solutions HA sont utilisées pour gérer la réplication du système SAP HANA en combinaison avec des instances SAP HANA compatibles avec systemd (consultez la note SAP 3189534), des étapes supplémentaires sont nécessaires pour que le cluster HA puisse gérer l’instance SAP sans interférence avec systemd. Par conséquent, pour le système SAP HANA intégré à systemd, il convient de suivre les étapes supplémentaires décrites dans l’article KBA Red Hat 7029705 sur tous les nœuds de cluster.
Implémenter le hook de réplication de système Python SAPHanaSR
Il s’agit d’une étape importante pour optimiser l’intégration au cluster et améliorer la détection lorsqu’un basculement de cluster est nécessaire. Nous vous recommandons vivement de configurer le hook Python SAPHanaSR. Suivez les étapes mentionnées dans Implémenter le hook de réplication de système Python SAPHanaSR.
Configurer les ressources de système de fichiers
Dans cet exemple, chaque nœud de cluster possède ses propres systèmes de fichiers NFS HANA : /hana/shared, /hana/data et /hana/log.
[1] Mettez le cluster en mode maintenance.
sudo pcs property set maintenance-mode=true[1] Créez les ressources du système de fichiers pour les montages hanadb1.
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Créez les ressources du système de fichiers pour les montages hanadb2.
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsL’attribut
OCF_CHECK_LEVEL=20est ajouté à l’opération d’analyse afin que chaque analyse effectue un test en lecture/écriture sur le système de fichiers. Sans cet attribut, l’opération d’analyse vérifie uniquement que le système de fichiers est monté. Cela peut être un problème car, en cas de perte de connectivité, le système de fichiers peut rester monté, bien qu’il soit inaccessible.L’attribut
on-fail=fenceest également ajouté à l’opération d’analyse. Avec cette option, si l’opération d’analyse échoue sur un nœud, ce dernier est immédiatement isolé. Sans cette option, le comportement par défaut consiste à arrêter toutes les ressources qui dépendent de la ressource défaillante, puis à redémarrer la ressource qui a échoué, puis à démarrer toutes les ressources qui dépendent de la ressource qui a échoué.Non seulement ce comportement peut prendre beaucoup de temps lorsqu’une ressource SAP HANA dépend de la ressource qui a échoué, mais il peut aussi échouer complètement. La ressource SAP HANA ne peut pas s’arrêter correctement si le serveur NFS contenant les exécutables HANA est inaccessible.
Les valeurs de délai d’expiration suggérées permettent aux ressources de cluster de résister à une pause propre au protocole, liée aux renouvellements de bail NFSv4.1. Pour plus d’informations, consultez les bonnes pratiques relatives à NFS dans NetApp. Les délais d’expiration de la configuration précédente peuvent nécessiter une adaptation à la configuration SAP spécifique.
Pour les charges de travail qui nécessitent un débit plus élevé, envisagez d’utiliser l’option de montage
nconnect, comme indiqué dans l’article Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA. Vérifiez sinconnectest pris en charge par Azure NetApp Files sur votre version Linux.[1] Configurer des contraintes d’emplacement.
Configurez des contraintes d’emplacement pour vous assurer que les ressources qui gèrent les montages uniques hanadb1 ne peuvent jamais s’exécuter sur hanadb2, et vice-versa.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1L’option
resource-discovery=neverest définie, car les montages uniques de chaque nœud partagent le même point de montage. Par exemple,hana_data1utilise le point de montage/hana/data, ethana_data2utilise également le point de montage/hana/data. Le partage d’un même point de montage peut provoquer un faux positif pour une opération de sondage, lorsque l’état de la ressource est vérifié au démarrage du cluster, et cela peut à son tour entraîner un comportement de récupération inutile. Pour éviter ce scénario, définissezresource-discovery=never.[1] Configuration des ressources d’attribut.
Configurez des ressources d’attribut. Ces attributs sont définis sur true si tous les montages NFS d’un nœud (
/hana/data,/hana/loget/hana/data) sont montés. Sinon, ils ont la valeur false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Configurer des contraintes d’emplacement.
Configurez des contraintes d’emplacement pour vous assurer que la ressource d’attribut de hanadb1 ne s’exécute jamais sur hanadb2, et vice-versa.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Création de contraintes de classement.
Configurez des contraintes de classement afin que les ressources d’attribut d’un nœud démarrent uniquement une fois que tous les montages NFS du nœud ont été montés.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeConseil
Si votre configuration inclut des systèmes de fichiers, en dehors du groupe
hanadb1_nfsouhanadb2_nfs, incluez l’optionsequential=falseafin qu’il n’y ait aucune dépendance de classement entre les systèmes de fichiers. Tous les systèmes de fichiers doivent démarrer avanthana_nfs1_active, mais ils n’ont pas besoin de démarrer dans un ordre particulier les uns par rapport aux autres. Pour plus d’informations, consultez Comment configurer la réplication du système SAP HANA dans le cadre de mise à l’échelle dans un cluster Pacemaker lorsque les systèmes de fichiers HANA se trouvent sur des partages NFS
Configurer les ressources de cluster SAP HANA
Suivez les étapes décrites dans Créer les ressources de cluster SAP HANA pour créer les ressources SAP HANA dans le cluster. Une fois que les ressources SAP HANA sont créées, vous devez créer une contrainte de règle d’emplacement entre les ressources SAP HANA et les systèmes de fichiers (montages NFS).
[1] Configuration des contraintes entre les ressources SAP HANA et les montages NFS.
Les contraintes de règle d’emplacement sont définies de sorte que les ressources SAP HANA peuvent s’exécuter sur un nœud uniquement si tous les montages NFS du nœud sont montés.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueSur RHEL 7.x :
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueSur RHEL 8;x/9.x :
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne truePlacez le cluster en mode maintenance.
sudo pcs property set maintenance-mode=falseVérifiez l’état du cluster et celui de toutes les ressources.
Remarque
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
sudo pcs statusExemple de sortie :
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Configurer la réplication du système active/accessible en lecture HANA dans le cluster Pacemaker
À compter de SAP HANA 2.0 SPS 01, SAP autorise les configurations actives/accessibles en lecture pour la réplication du système SAP HANA, où les systèmes secondaires de réplication du système SAP HANA peuvent être utilisés activement pour les charges de travail à forte intensité de lecture. Pour prendre en charge une telle configuration dans un cluster, une deuxième adresse IP virtuelle est nécessaire, ce qui permet aux clients d’accéder à la base de données SAP HANA secondaire accessible en lecture.
Pour vous assurer que le site de réplication secondaire est toujours accessible après une prise de contrôle, le cluster doit déplacer l’adresse IP virtuelle avec le secondaire de la ressource SAPHana.
La configuration supplémentaire, nécessaire pour gérer la réplication du système active/accessible en lecture HANA dans un cluster haute disponibilité Red Hat avec une seconde adresse IP virtuelle est décrite dans Configurer la réplication du système active/accessible en lecture HANA dans le cluster Pacemaker.
Avant de poursuivre, assurez-vous que le cluster haute disponibilité Red Hat est entièrement configuré en gérant la base de données SAP HANA comme décrit dans les segments ci-dessus de la documentation.
Tester la configuration du cluster
Cette section explique comment vous pouvez tester votre configuration.
Avant de lancer un test, vérifiez que Pacemaker ne présente pas d’action en échec (via le statut pcs), qu’il n’existe pas de contraintes d’emplacement inattendues (par exemple, les restes d’un test de migration) et que la réplication du système HANA est en état de synchronisation, par exemple avec
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Vérifiez la configuration du cluster pour un scénario de défaillance lorsqu’un nœud perd l’accès au partage NFS (
/hana/shared).Les agents de ressource SAP HANA dépendent des binaires stockés sur
/hana/sharedpour effectuer des opérations pendant le basculement. Le système de fichiers/hana/sharedest monté sur NFS dans le scénario présenté.Il est difficile de simuler une défaillance pendant laquelle l’un des serveurs perd l’accès au partage NFS. Vous pouvez remonter le système de fichiers en lecture seule en guise de test. Cette approche valide la capacité du cluster à basculer en cas de perte de l’accès à
/hana/sharedsur le nœud actif.Résultat attendu : Lors de l’exécution de
/hana/shareden tant que système de fichiers en lecture seule, l’attributOCF_CHECK_LEVELde la ressourcehana_shared1, qui effectue des opérations de lecture/écriture sur les systèmes de fichiers, échoue. Il n’est pas en mesure d’écrire quoi que ce soit sur le système de fichiers et d’effectuer un basculement de ressource HANA. Le même résultat est attendu lorsque votre nœud HANA perd l’accès aux partages NFS.État des ressources avant le début du test :
sudo pcs statusExemple de sortie :
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1Vous pouvez placer
/hana/shareden mode lecture seule sur le nœud de cluster actif à l’aide de la commande suivante :sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbredémarrera ou s’éteindra en fonction de l’action définie surstonith(pcs property show stonith-action). Une fois que le serveur (hanadb1) est arrêté, la ressource HANA passe àhanadb2. Vous pouvez vérifier l’état du cluster à partir dehanadb2.sudo pcs statusExemple de sortie :
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2Nous vous recommandons de tester minutieusement la configuration du cluster SAP HANA, en effectuant également les tests décrits dans Configurer la réplication du système SAP HANA sur RHEL.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour