Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans les solutions de recherche, les chaînes qui ont des modèles complexes ou des caractères spéciaux peuvent être difficiles à utiliser, car l’analyseur par défaut supprime ou interprète mal les parties significatives d’un modèle. Cela entraîne une expérience de recherche médiocre où les utilisateurs ne peuvent pas trouver les informations attendues. Les numéros de téléphone sont un exemple classique de chaînes difficiles à analyser. Ils sont fournis dans différents formats et incluent des caractères spéciaux que l’analyseur par défaut ignore.
Avec les numéros de téléphone comme sujet, ce tutoriel utilise les API REST du service de recherche pour résoudre les problèmes de données modèles à l’aide d’un analyseur personnalisé. Cette approche peut être utilisée comme c’est le cas pour les numéros de téléphone ou adaptées aux champs présentant les mêmes caractéristiques (avec des caractères spéciaux), telles que les URL, les e-mails, les codes postaux et les dates.
Dans ce tutoriel, vous allez :
- Comprendre le problème
- Développer un analyseur personnalisé initial pour gérer les numéros de téléphone
- Tester l’analyseur personnalisé
- Itérer sur la conception de l’analyseur personnalisé pour améliorer encore les résultats
Prérequis
Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Télécharger les fichiers
Le code source de ce tutoriel se trouve dans le fichier custom-analyzer.rest dans le référentiel GitHub Azure-Samples/azure-search-rest-samples .
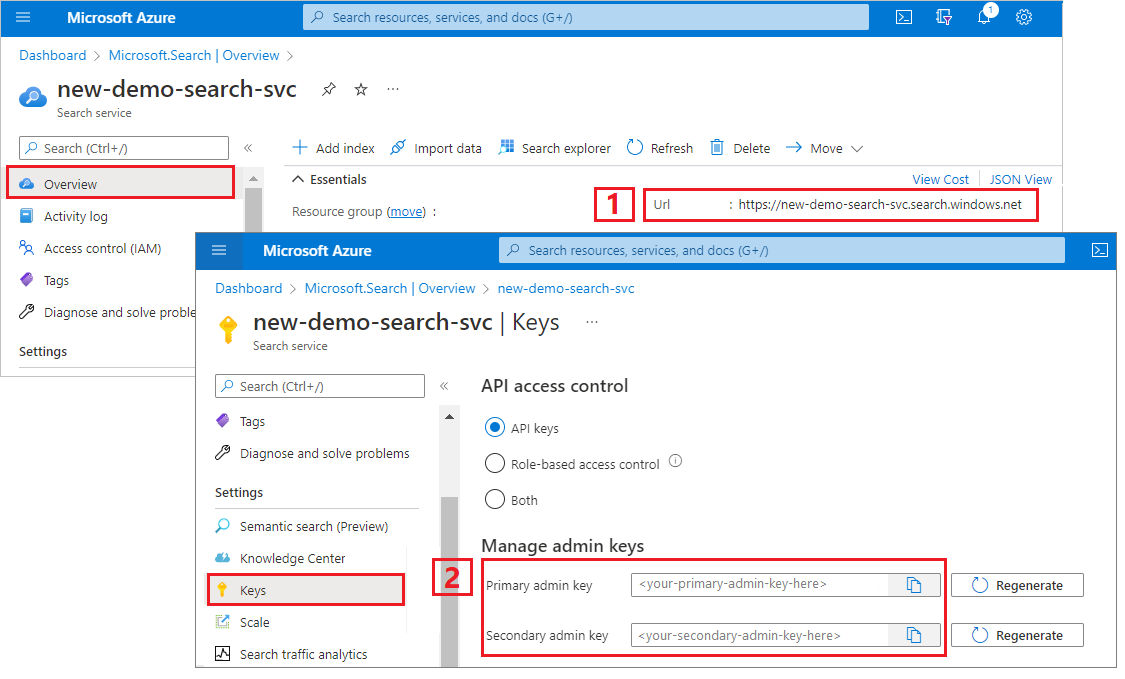
Copier une clé d’administration et une URL
Les appels REST de ce tutoriel nécessitent un point de terminaison de service de recherche et une clé API d’administration. Vous pouvez obtenir ces valeurs à partir du Portail Azure.
Accédez à votre service Search dans le Portail Microsoft Azure.
Dans le volet gauche, sélectionnez Vue d’ensemble et copiez le point de terminaison. Il doit être au format suivant :
https://my-service.search.windows.netDans le volet gauche, sélectionnez Clés de paramètres> et copiez une clé d’administration pour obtenir des droits complets sur le service. Il existe deux clés d’administration interchangeables, fournies pour assurer la continuité de l’activité au cas où vous deviez en remplacer une. Vous pouvez utiliser une clé sur les requêtes pour ajouter, modifier ou supprimer des objets.
Créer un index initial
Ouvrez un nouveau fichier texte dans Visual Studio Code.
Définissez les variables sur le point de terminaison de recherche et la clé API que vous avez collectées dans la section précédente.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREEnregistrez le fichier avec une extension de fichier
.rest.Collez l’exemple suivant pour créer un petit index appelé
phone-numbers-indexavec deux champs :idetphone_number.### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Vous n’avez pas encore défini d’analyseur. Par conséquent, l’analyseur
standard.luceneest utilisé par défaut.Sélectionnez Envoyer une demande. Vous devez avoir une
HTTP/1.1 201 Createdréponse et le corps de la réponse doit inclure la représentation JSON du schéma d’index.Chargez des données dans l’index à l’aide de documents qui contiennent différents formats de numéros de téléphone. Il s’agit de vos données de test.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Essayez des requêtes similaires à ce qu’un utilisateur peut taper. Par exemple, un utilisateur peut rechercher
(425) 555-0100dans n’importe quel nombre de formats et s’attendre à ce que les résultats soient retournés. Commencez par rechercher(425) 555-0100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }La requête retourne trois résultats attendus sur quatre, mais retourne également deux résultats inattendus.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Réessayez sans mise en forme :
4255550100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }Cette requête fait encore pire, ne renvoyant qu'une seule correspondance correcte sur quatre.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Si vous trouvez que ces résultats prêtent à confusion, vous n’êtes pas le seul. La section suivante explique pourquoi vous obtenez ces résultats.
Examiner le fonctionnement des analyseurs
Pour comprendre ces résultats de recherche, vous devez comprendre ce que fait l’analyseur. À partir de là, vous pouvez tester l’analyseur par défaut à l’aide de l’API d’analyse, en fournissant une base pour concevoir un analyseur qui répond mieux à vos besoins.
Un analyseur est un composant du moteur de recherche en texte intégral responsable du traitement du texte dans les chaînes de requête et les documents indexés. La façon dont les différents analyseurs manipulent le texte varie en fonction du scénario. Pour ce scénario, nous devons créer un analyseur adapté aux numéros de téléphone.
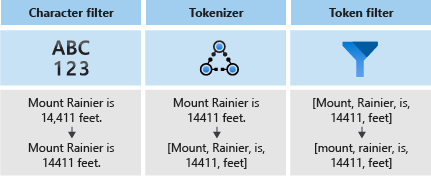
Un analyseur comprend trois composants :
- Des filtres de caractères qui suppriment ou remplacent des caractères individuels du texte d’entrée.
- Un tokenizer qui divise le texte source en jetons afin qu'ils deviennent des clés dans l'index de recherche.
- Des filtres de jetons qui manipulent les jetons produits par le générateur de jetons.
Le diagramme suivant montre comment ces trois composants fonctionnent ensemble pour tokeniser une phrase.
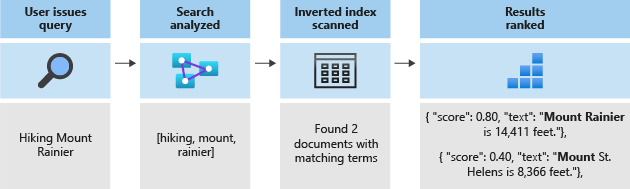
Ces jetons sont ensuite stockés dans un index inversé qui autorise des recherches rapides en texte intégral. Pour cela, un index inversé mappe tous les termes uniques extraits durant l’analyse lexicale aux documents dans lesquels ils apparaissent. Vous pouvez voir un exemple dans le diagramme suivant :

Toute la recherche se résume à rechercher les termes stockés dans l’index inversé. Quand un utilisateur émet une requête :
- La requête est analysée et les termes de la requête sont analysés.
- L’index inversé est analysé pour les documents avec des termes correspondants.
- L’algorithme de scoring classe les documents récupérés.
Si les termes de la requête ne correspondent pas aux termes de votre index inversé, aucun résultat n’est renvoyé. Pour en savoir plus sur le fonctionnement des requêtes, consultez recherche en texte intégral dans Recherche IA Azure.
Remarque
Les requêtes sur des termes partiels constituent une exception importante à cette règle. Contrairement aux requêtes de terme standard, ces requêtes (requête de préfixe, requête générique et requête regex) contournent le processus d’analyse lexicale. Les termes partiels sont uniquement mis en minuscules avant d’être mis en correspondance avec les termes de l’index. Si un analyseur n’est pas configuré pour prendre en charge ces types de requêtes, vous recevez souvent des résultats inattendus, car les termes correspondants n’existent pas dans l’index.
Tester les analyseurs avec l’API Analyser
La Recherche Azure AI fournit une API Analyser qui vous permet de tester les analyseurs pour comprendre comment ils traitent le texte.
Appelez l’API Analyze à l’aide de la requête suivante :
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
L’API renvoie les jetons extraits du texte avec l’analyseur que vous avez spécifié. L’analyseur Lucene standard divise le numéro de téléphone en trois éléments distincts.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
À l’inverse, le numéro de téléphone 4255550100 mis en forme sans ponctuation produit un seul jeton.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Réponse :
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Gardez à l’esprit que les termes de la requête et les documents indexés sont analysés. En repensant aux résultats de la recherche de l'étape précédente, vous pouvez commencer à comprendre pourquoi ces résultats sont affichés.
Dans la première requête, des numéros de téléphone inattendus sont retournés en raison de l’un de leurs jetons, 555correspondant à l’un des termes que vous avez recherchés. Dans la deuxième requête, seul le seul nombre est retourné, car il s’agit du seul enregistrement ayant un jeton correspondant 4255550100.
Créer un analyseur personnalisé
Maintenant que vous comprenez les résultats que vous voyez, créez un analyseur sur mesure pour améliorer la logique de tokenisation.
L’objectif est de pouvoir rechercher de manière intuitive des numéros de téléphone, quel que soit le format de la requête ou de la chaîne indexée. Pour obtenir ce résultat, spécifiez un filtre de caractères, un tokenizer et un filtre de jeton.
Filtres de caractères
Les filtres de caractères traitent le texte avant qu’il ne soit transmis au générateur de jetons. Les utilisations courantes des filtres de caractères filtrent les éléments HTML et remplacent les caractères spéciaux.
Pour les numéros de téléphone, vous souhaitez supprimer des espaces blancs et des caractères spéciaux, car tous les formats de numéros de téléphone ne contiennent pas les mêmes caractères spéciaux et espaces.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Le filtre supprime -()+. et les espaces de l’entrée.
| Entrée | Output |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Générateurs de jetons
Les générateurs de jetons divisent le texte en jetons et rejettent certains caractères, comme les signes de ponctuation, au cours du processus. Dans de nombreux cas, l’objectif de la génération de jetons est de diviser une phrase en mots individuels.
Pour ce scénario, utilisez un tokenizer de mot clé, keyword_v2pour capturer le numéro de téléphone sous la forme d’un seul terme. Ce n’est pas la seule façon de résoudre ce problème, comme expliqué dans la section Autres approches .
Les tokeniseurs de mots-clés génèrent toujours le même texte qui leur est donné sous forme de terme unique.
| Entrée | Output |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtres de jeton
Les filtres de jeton modifient ou filtrent les jetons générés par le tokenizer. Un filtre de jetons est couramment utilisé pour mettre en minuscules pour tous les caractères à l’aide d’un filtre de jeton. Une autre utilisation courante consiste à filtrer les stopwords, tels que the, and, ou is.
Bien que vous n’ayez pas besoin d’utiliser l’un de ces filtres pour ce scénario, utilisez un filtre de jeton nGram pour permettre des recherches partielles de numéros de téléphone.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Le filtre de jetons nGram_v2 divise les jetons en n-grammes d’une taille donnée en fonction des paramètres minGram et maxGram.
Pour l'analyseur téléphonique, minGram est défini sur 3 car c'est la plus courte sous-chaîne que les utilisateurs sont censés rechercher.
maxGram est configuré sur 20 pour garantir que tous les numéros de téléphone, même avec des extensions, tiennent dans un seul n-gramme.
L’effet secondaire malheureux des n-grammes est que certains faux positifs sont renvoyés. Vous allez corriger ce problème dans une étape ultérieure en créant un analyseur distinct pour les recherches qui n’incluent pas le filtre de jeton n-grammes.
| Entrée | Output |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analyseur
Avec les filtres de caractères, le tokenizer, et les filtres de tokens étant déjà en place, vous êtes prêt à définir l'analyseur.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
À partir de l’API Analyze, étant donné les entrées suivantes, les sorties de l’analyseur personnalisé sont les suivantes :
| Entrée | Output |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Tous les jetons de la colonne de sortie existent dans l’index. Si votre requête inclut l’un de ces termes, le numéro de téléphone est retourné.
Recréer avec le nouvel analyseur
Supprimez l’index actuel.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2026-04-01 HTTP/1.1 api-key: {{apiKey}}Recréez l’index avec le nouvel analyseur. Ce schéma d’index ajoute une définition d’analyseur personnalisé et une affectation d’analyseur personnalisée sur le champ numéro de téléphone.
### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Tester l’analyseur personnalisé
Après avoir recréé l’index, testez l’analyseur à l’aide de la requête suivante :
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Vous devriez maintenant voir la collection de jetons résultant du numéro de téléphone.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Réviser l’analyseur personnalisé pour gérer les faux positifs
Après avoir utilisé l'analyseur personnalisé pour effectuer des exemples de requêtes sur l'index, vous devriez voir que le rappel s'est amélioré et que tous les numéros de téléphone correspondants sont maintenant affichés. Cependant, le filtre de jeton n-gramme provoque également le retour de certains faux positifs. Il s’agit d’un effet secondaire courant avec les fitres de jetons n-gramme.
Pour empêcher les faux positifs, créez un analyseur distinct pour l’interrogation. Cet analyseur est identique à celui précédent, sauf qu’il omet le custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
Dans la définition d’index, spécifiez à la fois un indexAnalyzer et un searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Une fois ce changement effectué, tout est prêt. Voici vos prochaines étapes :
Supprimez l’index.
Recréez l’index après avoir ajouté le nouvel analyseur personnalisé (
phone_analyzer-search) et affectez cet analyseur à laphone-numberpropriété dusearchAnalyzerchamp.Rechargez le modèle.
Testez à nouveau les requêtes pour vérifier que la recherche fonctionne comme prévu. Si vous utilisez l’exemple de fichier, cette étape crée le troisième index nommé
phone-number-index-3.
Autres approches
L’analyseur décrit dans la section précédente est conçu pour optimiser la flexibilité de la recherche. Toutefois, il en résulte le stockage de nombreux termes potentiellement sans importance dans l’index.
L’exemple suivant montre un autre analyseur plus efficace dans la tokenisation, mais il présente des inconvénients.
Prenons l’entrée 14255550100, l’analyseur ne peut pas segmenter logiquement le numéro de téléphone. Par exemple, il ne peut pas séparer le code de pays, 1, de l’indicatif régional, 425. Cette différence entraîne le renvoi du numéro de téléphone si un utilisateur n’inclut pas de code de pays dans sa recherche.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Dans l’exemple suivant, le numéro de téléphone est divisé en blocs que vous attendez normalement qu’un utilisateur recherche.
| Entrée | Output |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Selon vos besoins, cette approche peut être plus efficace pour résoudre le problème.
Éléments importants à retenir
Ce tutoriel a montré le processus de création et de test d’un analyseur personnalisé. Vous avez créé un index, indexé les données, puis interrogé l’index pour voir les résultats de la recherche retournés. Ensuite, vous avez utilisé l’API Analyser pour voir le processus d’analyse lexicale en action.
Bien que l’analyseur défini dans ce tutoriel offre une solution simple de recherche de numéros de téléphone, vous pouvez suivre ce même processus afin de créer un analyseur personnalisé pour n’importe quel scénario partageant les mêmes caractéristiques.
Nettoyer les ressources
Quand vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez trouver et gérer des ressources dans le Portail Azure, à l’aide du lien Toutes les ressources ou Groupes de ressources dans le volet de navigation de gauche.
Étapes suivantes
Maintenant que vous savez comment créer un analyseur personnalisé, examinez tous les différents filtres, tokenizers et analyseurs disponibles pour créer une expérience de recherche riche :