Déployer un cluster Azure Service Fabric sur des zones de disponibilité
Les zones de disponibilité dans Azure constituent une offre à haute disponibilité qui protège vos applications et données contre les pannes des centres de données. Une zone de disponibilité est un emplacement physique unique équipé d’une alimentation, d’un refroidissement et d’une mise en réseau indépendants dans une région Azure.
Pour prendre en charge les clusters qui s’étendent dans plusieurs zones de disponibilité, Azure Service Fabric fournit les deux méthodes de configuration décrites dans l’article ci-dessous. Les zones de disponibilité sont disponibles uniquement dans les régions sélectionnées. Pour plus d’informations, consultez Vue d’ensemble des zones de disponibilité.
Des exemples de modèles sont disponibles dans les modèles de zones de disponibilité croisée Service Fabric.
Consultez la topologie pour étendre un type de nœud principal dans des zones de disponibilité
Notes
L’avantage de répartir le type de nœud principal entre les zones de disponibilité n’est vraiment visible que pour trois zones et pas seulement deux.
- Le niveau de fiabilité du cluster défini sur
Platinum - Une ressource d’adresse IP publique unique utilisant une référence SKU standard
- Une ressource de Load Balancer unique utilisant une référence SKU standard
- Un groupe de sécurité réseau (NSG) référencé par le sous-réseau dans lequel vous déployez vos groupes de machines virtuelles identiques
Notes
La propriété de groupe de placement unique du groupe de machines virtuelles identiques doit être définie sur true.
L’exemple de liste de nœuds suivant illustre les formats FD/UD dans les zones étendues d’un groupe de machines virtuelles identiques :
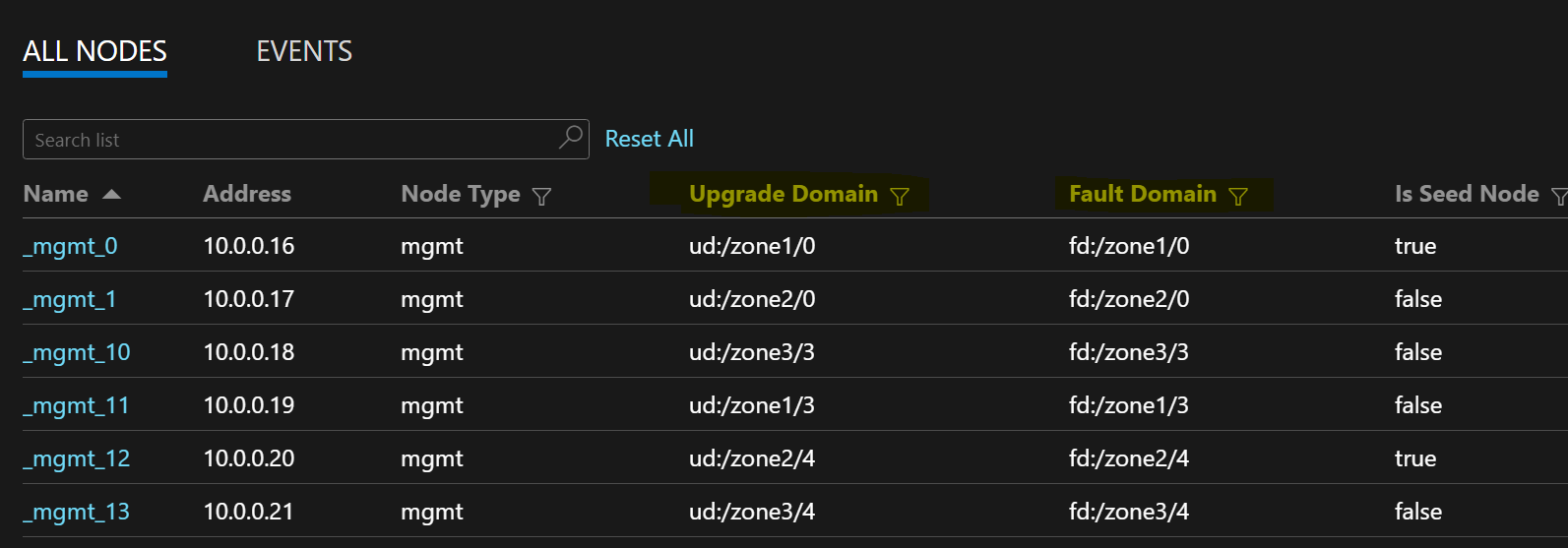
Distribution des réplicas de service entre les zones
Lorsqu’un service est déployé sur les types de nœuds qui couvrent plusieurs zones de disponibilité, les réplicas sont placés pour s’assurer qu’ils se trouvent dans des zones distinctes. Les domaines d’erreur sur les nœuds de chacun de ces types de nœuds sont configurés avec les informations de zone (FD = fd:/zone1/1, etc.). Par exemple : pour cinq réplicas ou instances de service, la distribution sera 2-2-1 et le runtime essaiera de garantir une distribution égale entre les zones.
Configuration du réplica du service utilisateur
Les services utilisateur avec état déployés sur les types de nœuds sur plusieurs zones de disponibilité doivent être configurés comme suit : nombre de réplicas avec cible = 9, min = 5. Cette configuration permet au service de fonctionner même lorsqu’une zone tombe en panne, car six réplicas sont toujours dans les deux autres zones. Une mise à niveau de l’application dans ce scénario réussit également.
ReliabilityLevel du cluster
Cette valeur définit le nombre de nœuds de départ dans le cluster et la taille de réplica des services système. Une configuration de zone de disponibilité croisée possède un nombre de nœuds plus élevé, qui sont répartis entre les zones pour permettre la résilience de zone.
Une valeur plus élevée de ReliabilityLevel garantit que davantage de nœuds de départ et de réplicas de service système sont présents et uniformément répartis entre les zones, de sorte que si une zone échoue, le cluster et les services système ne sont pas affectés. ReliabilityLevel = Platinum (recommandé) permet de s’assurer qu’il y a neuf nœuds de départ répartis entre les zones du cluster, avec trois seeds dans chaque zone.
Scénario de zonage
Quand une zone tombe en panne, tous les nœuds et réplicas de service pour cette zone apparaissent comme étant inactifs. Étant donné qu’il y a des réplicas dans les autres zones, le service continue de répondre. Les réplicas principaux basculent vers les zones fonctionnelles. Les services semblent être dans des états d’avertissement, car le nombre de réplicas cible n’est pas encore atteint et le nombre de machines virtuelles est toujours supérieur à la taille minimale du réplica cible.
L’équilibreur de charge Service Fabric affiche les réplicas dans les zones de travail afin de correspondre au nombre de réplicas cible. À ce stade, les services apparaissent intègres. Lorsque la zone qui était introuvable est reprise, l’équilibrage de charge répartit tous les réplicas de service uniformément dans les zones.
Optimisations à venir
- Pour fournir des mises à jour de l’infrastructure fiables, Service Fabric nécessite que la durabilité du groupe de machines virtuelles identiques soit définie au moins au niveau Silver. Cela permet au groupe de machines virtuelles identiques sous-jacent et au runtime Service Fabric de fournir des mises à jour fiables. Chaque zone doit également disposer d’au moins cinq machines virtuelles. Nous travaillons actuellement afin de réduire cette exigence respectivement à trois et deux machines virtuelles par zone pour les types de nœuds principaux et non principaux.
- Toutes les configurations mentionnées ci-dessous et le travail à venir permettent une migration sur place vers les clients dans lesquels le même cluster peut être mis à niveau pour utiliser la nouvelle configuration en ajoutant de nouveaux nodeTypes et en supprimant les anciens.
Configuration requise du réseau
Ressource d’adresse IP publique et Load Balancer
Pour activer la propriété zones sur une ressource de groupe de machines virtuelles identiques, les ressources d’équilibreur de charge et d’adresse IP référencées par ce groupe de machines virtuelles identiques doivent toutes deux utiliser une référence SKU Standard. La création d’une ressource d’équilibreur de charge ou d’adresse IP sans la propriété de référence SKU créera une référence SKU de base, qui ne prend pas en charge les zones de disponibilité. Un équilibreur de charge de référence SKU standard bloque tout le trafic en provenance de l’extérieur par défaut. Pour autoriser le trafic externe, déployez un groupe de sécurité réseau sur le sous-réseau.
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/publicIPAddresses",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "Standard"
}
}
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/loadBalancers",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"dependsOn": [
"[concat('Microsoft.Network/networkSecurityGroups/', concat('nsg', parameters('subnet0Name')))]"
],
"properties": {
"addressSpace": {
"addressPrefixes": [
"[parameters('addressPrefix')]"
]
},
"subnets": [
{
"name": "[parameters('subnet0Name')]",
"properties": {
"addressPrefix": "[parameters('subnet0Prefix')]",
"networkSecurityGroup": {
"id": "[resourceId('Microsoft.Network/networkSecurityGroups', concat('nsg', parameters('subnet0Name')))]"
}
}
}
]
},
"sku": {
"name": "Standard"
}
}
Notes
Il n’est pas possible d’effectuer une modification sur place de référence SKU sur les ressources d’adresse IP publique et d’équilibreur de charge. Si vous effectuez une migration à partir de ressources existantes ayant une référence SKU de base, consultez la section relative à la migration de cet article.
Règles NAT pour les groupes de machines virtuelles identiques
Les règles de traduction d’adresses réseau (NAT) entrantes pour l’équilibreur de charge doivent correspondre aux pools NAT du groupe de machines virtuelles identiques. Chaque groupe de machines virtuelles identiques doit avoir un pool NAT entrant unique.
{
"inboundNatPools": [
{
"name": "LoadBalancerBEAddressNatPool0",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "50999",
"frontendPortRangeStart": "50000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool1",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "51999",
"frontendPortRangeStart": "51000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool2",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "52999",
"frontendPortRangeStart": "52000",
"protocol": "tcp"
}
}
]
}
Règles de trafic sortant dans Load Balancer de la référence SKU standard
Les références SKU Standard pour les adresses IP publiques et l’équilibreur de charge introduisent de nouvelles fonctionnalités et des comportements différents pour la connectivité sortante. Si vous souhaitez une connectivité sortante lorsque vous travaillez avec des références SKU Standard, vous devez explicitement la définir avec des adresses IP publiques Standard ou l’équilibreur de charge public du SKU Standard. Pour plus d’informations, consultez Connexions sortantes et Présentation d’Azure Load Balancer.
Notes
Le modèle standard fait référence à un groupe de sécurité réseau (NSG) qui autorise tout le trafic sortant par défaut. Le trafic entrant est limité aux ports qui sont requis pour les opérations de gestion de Service Fabric. Les règles NSG peuvent être modifiées pour répondre à vos besoins.
Important
Chaque type de nœud d’un cluster Service Fabric qui utilise un équilibreur de charge de référence SKU standard requiert une règle autorisant le trafic sortant sur le port 443. Cela est nécessaire pour terminer l’installation du cluster. Tout déploiement sans cette règle échoue.
1. Activer plusieurs zones de disponibilité dans un seul groupe de machines virtuelles identiques
Cette solution permet aux utilisateurs de couvrir trois zones de disponibilité dans le même type de nœud. Il s’agit de la topologie de déploiement recommandée, car elle vous permet un déploiement sur plusieurs zones de disponibilité tout en conservant un seul groupe de machines virtuelles identiques.
Un exemple de modèle complet est disponible sur GitHub.
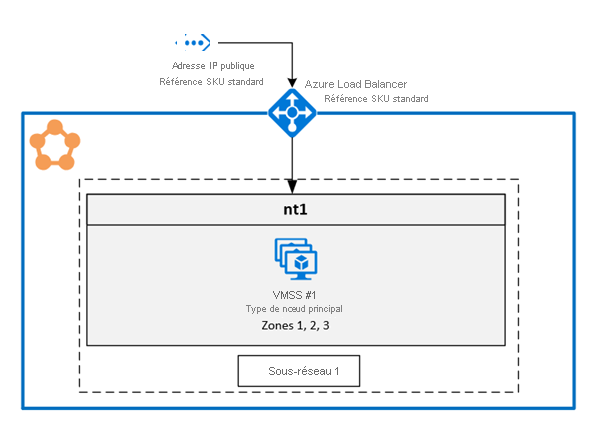
Configuration de zones sur un groupe de machines virtuelles identiques
Pour activer des zones sur un groupe de machines virtuelles identiques, incluez les trois valeurs suivantes dans la ressource de groupe de machines virtuelles identiques :
La première valeur est la propriété
zonesqui spécifie les zones de disponibilité dans le groupe de machines virtuelles identiques.La deuxième valeur est la propriété
singlePlacementGroup, qui doit être définie surtrue. Le groupe identique qui s’étend sur trois zones de disponibilité peut monter en puissance jusqu’à 300 machines virtuelles même avecsinglePlacementGroup = true.La troisième valeur est
zoneBalance, qui garantit un strict équilibrage des zones. Cette valeur doit êtretrue. Cela garantit que les distributions de machines virtuelles entre les zones ne sont pas déséquilibrées, ce qui signifie que lorsqu’une zone tombe en panne, les deux autres zones ont suffisamment de machines virtuelles pour maintenir l’exécution du cluster.Un cluster avec une distribution de machines virtuelles déséquilibrée peut ne pas survivre à un scénario de zone défaillante, car cette zone peut avoir la majorité des machines virtuelles. La distribution déséquilibrée des machines virtuelles entre les zones entraînera également des problèmes liés au placement de services et au blocage des mises à jour de l’infrastructure. Découvrez zoneBalancing.
Vous n’avez pas besoin de configurer les remplacements FaultDomain et UpgradeDomain.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [ "1", "2", "3" ],
"properties": {
"singlePlacementGroup": true,
"zoneBalance": true
}
}
Notes
- Les clusters Service Fabric doivent avoir au moins un nodeType principal. Le niveau de durabilité des types de nœuds principaux doit être Silver ou supérieur.
- Une zone de disponibilité qui s’étend sur un groupe de machines virtuelles identiques doit être configurée avec au moins trois zones de disponibilité, quel que soit le niveau de durabilité.
- Une zone de disponibilité couvrant un ensemble d'échelles de machines virtuelles avec une durabilité Silver ou supérieure doit avoir au moins 15 machines virtuelles (5 par région).
- Une zone de disponibilité qui s’étend sur un groupe de machines virtuelles identiques avec une durabilité Bronze doit comprendre au moins six machines virtuelles.
Activation de la prise en charge de plusieurs zones dans le nodeType Service Fabric
Le nodeType Service Fabric doit être activé pour prendre en charge plusieurs zones de disponibilité.
La première valeur est
multipleAvailabilityZones, qui doit être définie surtruepour le type de nœud.La deuxième valeur,
sfZonalUpgradeMode, est facultative. Il n’est pas possible de modifier cette propriété si un type de nœud avec plusieurs AZ est déjà présent dans le cluster. La propriété contrôle le regroupement logique des machines virtuelles dans les domaines de mise à niveau (UD).- Si cette valeur est définie sur
Parallel: les machines virtuelles sous le type de nœud sont regroupées en UD et ignorent les informations de zone dans cinq UD. Ce paramètre entraîne la mise à niveau simultanée des UD dans toutes les zones. Ce mode de déploiement est plus rapide pour les mises à niveau, mais il n’est pas recommandé, car il s’applique aux instructions SDP, qui stipulent que les mises à jour doivent être appliquées à une seule zone à la fois. - Si la valeur est omise ou définie sur
Hierarchical: les machines virtuelles sont regroupées pour refléter la distribution zonale jusqu’à 15 UD. Chacune des trois zones a cinq UD. Cela permet de s’assurer que les zones sont mises à jour l’une après l’autre, en passant à la zone suivante uniquement après avoir terminé cinq UD au sein de la première zone. Ce processus de mise à jour est plus sûr pour le cluster et l’application utilisateur.
Cette propriété définit uniquement le comportement de mise à niveau pour l’application Service Fabric et les mises à niveau de code. Les mises à niveau du groupe de machines virtuelles identiques sous-jacentes seront toujours parallèles dans toutes les zones de disponibilité. Cette propriété n’affecte pas la distribution d’UD pour les types de nœuds pour lesquels plusieurs zones ne sont pas activées.
- Si cette valeur est définie sur
La troisième valeur est
vmssZonalUpgradeMode. Elle est facultative et peut être mise à jour à tout moment. Cette propriété définit le schéma de mise à niveau pour que le jeu de mise à l’échelle de machine virtuelle se produise en parallèle ou de manière séquentielle entre zones de disponibilité.- Si cette valeur est définie sur
Parallel: toutes les mises à jour de groupe identique se produisent en parallèle dans toutes les zones. Ce mode de déploiement est plus rapide pour les mises à niveau, mais il n’est pas recommandé, car il s’applique aux instructions SDP, qui stipulent que les mises à jour doivent être appliquées à une seule zone à la fois. - Si la valeur est omise ou définie sur
Hierarchical: Cela permet de s’assurer que les zones sont mises à jour l’une après l’autre, en passant à la zone suivante uniquement après avoir terminé cinq UD au sein de la première zone. Ce processus de mise à jour est plus sûr pour le cluster et l’application utilisateur.
- Si cette valeur est définie sur
Important
La version d’API de la ressource de cluster Service Fabric doit être « 2020-12-01-preview » ou une version ultérieure.
La version de code du cluster doit être au moins « 8.1.321 » ou une version ultérieure.
{
"apiVersion": "2020-12-01-preview",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
"reliabilityLevel": "Platinum",
"sfZonalUpgradeMode": "Hierarchical",
"vmssZonalUpgradeMode": "Parallel",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"multipleAvailabilityZones": true
}
]
}
}
Notes
- Les ressources d’adresse IP publique et d’équilibreur de charge doivent utiliser la référence (SKU) Standard, comme décrit précédemment dans l’article.
- La propriété
multipleAvailabilityZonessur le type de nœud ne peut être définie que lorsque le type de nœud est créé et ne peut pas être modifié ultérieurement. Des types de nœuds existants ne peuvent pas être configurés avec cette propriété. - Quand
sfZonalUpgradeModeest omis ou défini surHierarchical, les déploiements de cluster et d’application sont plus lents, car il y a plus de domaines de mise à niveau dans le cluster. Il est important d’ajuster correctement les délais d’expiration de stratégie de mise à niveau pour prendre en compte la durée de mise à niveau requise pour 15 domaines de mise à niveau. La stratégie de mise à niveau pour l’application et le cluster doit être mise à jour pour s’assurer que le déploiement ne dépasse pas les délais d’attente de déploiement du service Azure Resource de 12 heures. Cela signifie que le déploiement ne doit pas durer plus de 12 heures pour 15 UD (autrement dit, il ne doit pas prendre plus de 40 minutes pour chaque UD). - Définissez le niveau de fiabilité du cluster sur
Platinumpour garantir que le cluster résiste au scénario à une seule zone. - La mise à niveau de DurabilityLevel pour un type de nœud avec plusieursAvailabilityZones n’est pas prise en charge. Créez un type de nœud avec la durabilité supérieure à la place.
- SF prend en charge seulement 3 AvailabilityZones. Tout nombre plus élevé n’est pas pris en charge pour l’instant.
Conseil
Nous vous recommandons de définir la valeur sfZonalUpgradeMode sur Hierarchical ou de l’omettre. Le déploiement suivra la distribution zonale des machines virtuelles ayant un impact sur un plus petit nombre de réplicas et/ou d’instances, rendant celles-ci plus sûres.
Utilisez sfZonalUpgradeMode défini sur Parallel si la vitesse de déploiement est une priorité ou si seule une charge de travail sans état s’exécute sur le type de nœud avec plusieurs zones de disponibilité. Cela provoque l’exécution en parallèle des UD dans toutes les zones de disponibilité.
Migration vers le type de nœud avec plusieurs zones de disponibilité
Pour tous les scénarios de migration, vous devez ajouter un nouveau type de nœud qui prend en charge plusieurs zones de disponibilité. Un type de nœud existant ne peut pas être migré pour prendre en charge plusieurs zones. L’article Monter en puissance un type de nœud principal de cluster Service Fabric comprend des étapes détaillées pour ajouter un nouveau type de nœud et les autres ressources requises pour le nouveau type de nœud, telles que les ressources d’équilibrage de charge et d’adresse IP. Le même article décrit également comment retirer le type de nœud existant après l’ajout du type de nœud avec plusieurs zones de disponibilité au cluster.
Migration à partir d’un type de nœud qui utilise l’équilibrage de charge et les ressources IP de base : ce processus est déjà décrit dans la sous-section ci-dessous pour la solution avec un type de nœud par zone de disponibilité.
Pour le nouveau type de nœud, la seule différence est qu’il n’y a qu’un seul groupe de machines virtuelles identiques et un seul type de nœud pour toutes les zones de disponibilité au lieu d’un par zone de disponibilité.
Migration à partir d’un type de nœud qui utilise l’équilibrage de charge et les ressources IP de référence SKU standard avec un groupe de sécurité réseau : suivez la même procédure que celle décrite précédemment. Toutefois, il n’est pas nécessaire d’ajouter de nouvelles ressources d’équilibrage de charge, d’adresse IP et de groupe de sécurité réseau. Les mêmes ressources peuvent être réutilisées dans le nouveau type de nœud.
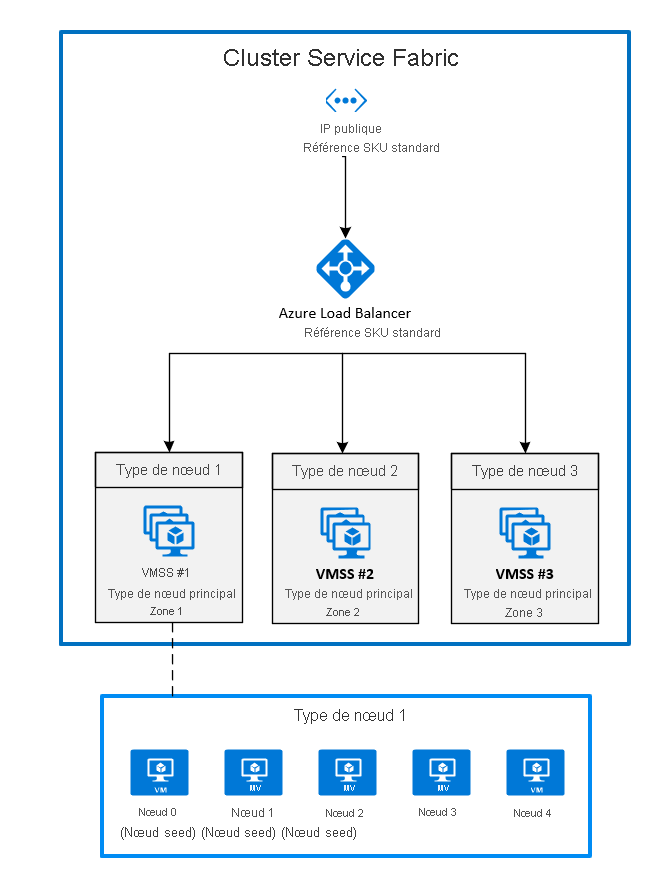
2. Déployer des zones en épinglant un groupe de machines virtuelles identiques à chaque zone
Il s’agit de la configuration généralement disponible actuellement. Pour étendre un cluster Service Fabric sur des zones de disponibilité, vous devez créer un type de nœud principal dans chaque zone de disponibilité prise en charge par la région. Les nœuds initiaux sont ainsi distribués uniformément sur chacun des types de nœuds principaux.
La topologie recommandée du type de nœud principal nécessite les éléments suivants :
- Trois types de nœuds marqués comme principaux
- Chaque type de nœud doit être mappé à son propre groupe de machines virtuelles identiques situé dans une zone différente.
- Chaque groupe de machines virtuelles identiques doit avoir au moins cinq nœuds (durabilité Silver).
Le diagramme illustre l’architecture des zones de disponibilité Azure Service Fabric :
Activation de zones sur un groupe de machines virtuelles identiques
Pour activer une zone sur un groupe de machines virtuelles identiques, incluez les trois valeurs suivantes dans la ressource de groupe de machines virtuelles identiques :
- La première valeur est la propriété
zones, qui spécifie la zone de disponibilité sur laquelle le groupe de machines virtuelles identiques sera déployé. - La deuxième valeur est la propriété
singlePlacementGroup, qui doit être définie surtrue. - La troisième valeur est la propriété
faultDomainOverridedans l’extension de groupe de machines virtuelles identiques Service Fabric. Cette propriété doit uniquement inclure la zone dans laquelle ce groupe de machines virtuelles identiques sera placé. Exemple :"faultDomainOverride": "az1". Toutes les ressources de groupe de machines virtuelles identiques doivent être placées dans la même région car les clusters Azure Service Fabric ne prennent pas en charge entre régions.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [
"1"
],
"properties": {
"singlePlacementGroup": true
},
"virtualMachineProfile": {
"extensionProfile": {
"extensions": [
{
"name": "[concat(parameters('vmNodeType1Name'),'_ServiceFabricNode')]",
"properties": {
"type": "ServiceFabricNode",
"autoUpgradeMinorVersion": false,
"publisher": "Microsoft.Azure.ServiceFabric",
"settings": {
"clusterEndpoint": "[reference(parameters('clusterName')).clusterEndpoint]",
"nodeTypeRef": "[parameters('vmNodeType1Name')]",
"dataPath": "D:\\\\SvcFab",
"durabilityLevel": "Silver",
"certificate": {
"thumbprint": "[parameters('certificateThumbprint')]",
"x509StoreName": "[parameters('certificateStoreValue')]"
},
"systemLogUploadSettings": {
"Enabled": true
},
"faultDomainOverride": "az1"
},
"typeHandlerVersion": "1.0"
}
}
]
}
}
}
Activation de plusieurs types de nœuds principaux dans la ressource de cluster Service Fabric
Pour définir un ou plusieurs types de nœuds comme principal dans une ressource de cluster, définissez la propriété isPrimary sur true. Lorsque vous déployez un cluster Service Fabric entre des zones de disponibilité, vous devez avoir trois types de nœuds dans des zones distinctes.
{
"reliabilityLevel": "Platinum",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"applicationPorts": {
"endPort": "[parameters('nt0applicationEndPort')]",
"startPort": "[parameters('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt0ephemeralEndPort')]",
"startPort": "[parameters('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt0InstanceCount')]"
},
{
"name": "[parameters('vmNodeType1Name')]",
"applicationPorts": {
"endPort": "[parameters('nt1applicationEndPort')]",
"startPort": "[parameters('nt1applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt1fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt1ephemeralEndPort')]",
"startPort": "[parameters('nt1ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt1fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt1InstanceCount')]"
},
{
"name": "[parameters('vmNodeType2Name')]",
"applicationPorts": {
"endPort": "[parameters('nt2applicationEndPort')]",
"startPort": "[parameters('nt2applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt2fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt2ephemeralEndPort')]",
"startPort": "[parameters('nt2ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt2fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt2InstanceCount')]"
}
]
}
Migrer à l’aide de zones de disponibilité à partir d’un cluster à l’aide d’un Load Balancer de référence SKU de base et d’une adresse IP de référence SKU de base
Pour migrer un cluster qui utilisait un Load Balancer et une adresse IP avec une référence SKU de base, vous devez tout d’abord créer une toute nouvelle ressource de Load Balancer et d’adresse à l’aide de la référence SKU standard. Il n’est pas possible de mettre à jour ces ressources.
Référencez le nouvel équilibreur de charge et l’adresse IP dans les nouveaux types de nœuds de zone de disponibilité croisée que vous souhaitez utiliser. Dans l’exemple précédent, trois nouvelles ressources de groupe de machines virtuelles identiques ont été ajoutées dans les zones 1, 2 et 3. Ces groupes de machines virtuelles identiques font référence aux nouveaux équilibreur de charge et adresse IP et sont marqués comme des types de nœuds principaux dans la ressource de cluster Service Fabric.
Pour commencer, ajoutez les nouvelles ressources à votre modèle Azure Resource Manager existant. Ces ressources incluent :
- Une ressource d’adresse IP publique utilisant une référence SKU standard
- Une ressource de Load Balancer utilisant une référence SKU standard
- Un groupe de sécurité réseau (NSG) référencé par le sous-réseau dans lequel vous déployez vos groupes de machines virtuelles identiques
- Trois types de nœuds marqués comme principaux
- Chaque type de nœud doit être mappé à son propre groupe de machines virtuelles identiques situé dans une zone différente.
- Chaque groupe de machines virtuelles identiques doit avoir au moins cinq nœuds (durabilité Silver).
Vous trouverez un exemple de ces ressources dans l’exemple de modèle.
New-AzureRmResourceGroupDeployment ` -ResourceGroupName $ResourceGroupName ` -TemplateFile $Template ` -TemplateParameterFile $ParametersUne fois le déploiement des ressources terminé, vous pouvez désactiver les nœuds dans le type de nœud principal du cluster d’origine. Comme les nœuds sont désactivés, les services système migrent vers le nouveau type de nœud principal que vous avez déployé précédemment.
Connect-ServiceFabricCluster -ConnectionEndpoint $ClusterName ` -KeepAliveIntervalInSec 10 ` -X509Credential ` -ServerCertThumbprint $thumb ` -FindType FindByThumbprint ` -FindValue $thumb ` -StoreLocation CurrentUser ` -StoreName My Write-Host "Connected to cluster" $nodeNames = @("_nt0_0", "_nt0_1", "_nt0_2", "_nt0_3", "_nt0_4") Write-Host "Disabling nodes..." foreach($name in $nodeNames) { Disable-ServiceFabricNode -NodeName $name -Intent RemoveNode -Force }Lorsque tous les nœuds sont désactivés, les services système s’exécutent sur le type de nœud principal, qui s’étend entre des zones. Vous pouvez ensuite supprimer les nœuds désactivés du cluster. Lorsque les nœuds sont supprimés, vous pouvez supprimer les ressources d’adresse IP, de Load Balancer et de groupe de machines virtuelles identiques d’origine.
foreach($name in $nodeNames){ # Remove the node from the cluster Remove-ServiceFabricNodeState -NodeName $name -TimeoutSec 300 -Force Write-Host "Removed node state for node $name" } $scaleSetName="nt0" Remove-AzureRmVmss -ResourceGroupName $groupname -VMScaleSetName $scaleSetName -Force $lbname="LB-cluster-nt0" $oldPublicIpName="LBIP-cluster-0" $newPublicIpName="LBIP-cluster-1" Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -ForceEnsuite, supprimez les références à ces ressources du modèle Resource Manager que vous avez déployé.
Enfin, mettez à jour le nom DNS et l’adresse IP publique.
$oldprimaryPublicIP = Get-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname
$primaryDNSName = $oldprimaryPublicIP.DnsSettings.DomainNameLabel
$primaryDNSFqdn = $oldprimaryPublicIP.DnsSettings.Fqdn
Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force
Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -Force
$PublicIP = Get-AzureRmPublicIpAddress -Name $newPublicIpName -ResourceGroupName $groupname
$PublicIP.DnsSettings.DomainNameLabel = $primaryDNSName
$PublicIP.DnsSettings.Fqdn = $primaryDNSFqdn
Set-AzureRmPublicIpAddress -PublicIpAddress $PublicIP
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour