Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit certains modèles adaptés aux solutions de service de Table. Par ailleurs, il explique comment traiter certains problèmes et compromis abordés dans les autres articles de conception de stockage de table. Le diagramme suivant récapitule les relations entre les différents modèles :
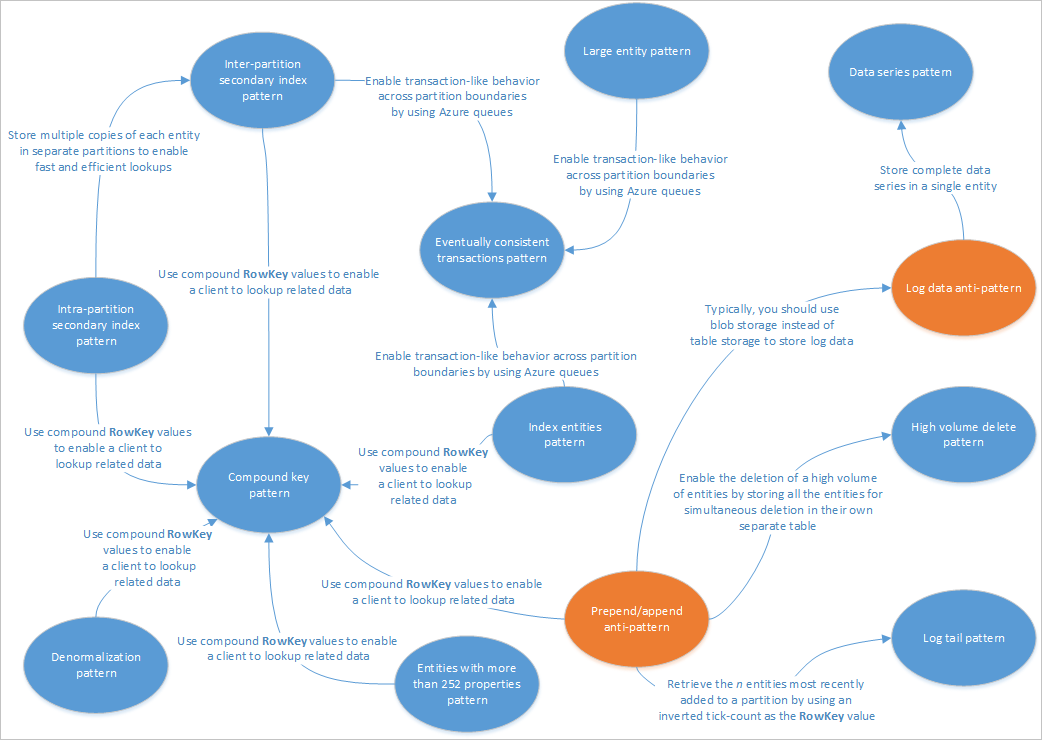
Le plan des modèles ci-dessus met en évidence les relations entre les modèles (bleus) et les anti-modèles (orange) qui sont décrits dans ce guide. Il existe bien d’autres modèles qui méritent votre attention. Par exemple, l’un des principaux scénarios pour un service de Table consiste à utiliser des modèles d’affichages matérialisés à partir du modèle Répartition de la responsabilité de requête de commande (CQRS).
Modèle d’index secondaire intra-partition
Stockez plusieurs copies de chaque entité en utilisant différentes valeurs de RowKey (dans la même partition) pour pouvoir mener des recherches rapides et efficaces et alterner des commandes de tri à l’aide de différentes valeurs de RowKey. La cohérence des mises à jour entre les copies peut être assurée par des transactions de groupe d’entités (EGT).
Contexte et problème
Le service de Table indexe automatiquement les entités en utilisant les valeurs de PartitionKey et de RowKey. Ainsi, une application cliente peut récupérer une entité efficacement à l'aide de ces valeurs. Par exemple, à l’aide de la structure de table ci-dessous, une application cliente peut utiliser une requête de pointage pour récupérer une entité d’employé individuelle en utilisant le nom de service et l’ID d’employé (PartitionKey et RowKey). Un client peut aussi récupérer des entités triées par ID d’employé au sein de chaque service.

Si vous voulez également pouvoir trouver une entité d'employé en fonction de la valeur d'une autre propriété, comme l'adresse de messagerie, vous devez utiliser une analyse de partition moins efficace pour rechercher une correspondance. En effet, le service de Table ne fournit pas d'index secondaires. De plus, vous ne pouvez pas demander une liste des employés triés dans un ordre différent de celui de RowKey .
Solution
Pour contourner l’absence d’index secondaires, vous pouvez stocker plusieurs copies de chaque entité avec chaque copie en utilisant une autre valeur de RowKey . Si vous stockez une entité avec les structures indiquées ci-dessous, vous pouvez récupérer efficacement des entités d’employé selon leur adresse e-mail ou leur ID d’employé. Les valeurs de préfixe pour RowKey, « empid » et « email » permettent d’interroger un seul employé ou une plage d’employés à l’aide d’une plage d’adresses de messagerie ou d’ID d’employé.

Les deux critères de filtre suivants (l’un recherchant selon l’ID d’employé et l’autre selon l’adresse e-mail) spécifient des requêtes de pointage :
- $filter=(PartitionKey eq ’Sales’) and (RowKey eq ’empid_000223’)
- $filter=(PartitionKey eq 'Sales') and (RowKey eq email_jonesj@contoso.com
Si vous interrogez un ensemble d’entités d’employé, vous pouvez spécifier une plage triée par ID d’employé ou une plage triée par adresse e-mail en recherchant les entités avec le préfixe approprié dans RowKey.
Pour rechercher tous les employés du service des ventes avec un ID d’employé compris entre 000100 et 000199, utilisez : $filter=(PartitionKey eq ’Sales’) and (RowKey ge ’empid_000100’) and (RowKey le ’empid_000199’)
Pour rechercher tous les employés du service des ventes dont l’adresse de messagerie commence par la lettre « a », utilisez : $filter=(PartitionKey eq ’Sales’) and (RowKey ge ’email_a’) and (RowKey lt ’email_b’)
La syntaxe de filtre utilisée dans les exemples ci-dessus provient de l’API REST Service de Table. Pour en savoir plus, consultez Interrogation d’entités.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
L'utilisation du stockage de tables est relativement bon marché. Le coût réel du stockage des données en double ne doit donc pas être une préoccupation majeure. Toutefois, vous devez toujours évaluer le coût de la conception en fonction de vos besoins en stockage anticipés et ajouter uniquement des entités en double pour prendre en charge les requêtes que votre application cliente exécutera.
Comme les entités d'index secondaires sont stockées dans la même partition que les entités d'origine, vous devez vous assurer que vous ne dépassez pas les objectifs d'évolutivité pour une partition individuelle.
Vous pouvez maintenir la cohérence de vos entités en double en utilisant des EGT pour mettre à jour de façon atomique les deux copies d'une même entité. Cela implique un stockage de toutes les copies d'une entité dans la même partition. Pour en savoir plus, consultez la section Utilisation des transactions de groupe d’entités.
La valeur de la RowKey doit être unique pour chaque entité. Nous vous conseillons d'utiliser des valeurs de clé composée.
Le remplissage des valeurs numériques dans RowKey (par exemple, l’ID d’employé 000223) permet de corriger le tri et le filtrage en fonction des limites inférieure et supérieure.
Vous n'avez pas toujours besoin de dupliquer toutes les propriétés de votre entité. Par exemple, si les requêtes de recherche des entités à l’aide de l’adresse de messagerie dans la RowKey n’ont jamais besoin de l’âge de l’employé, ces entités peuvent présenter la structure suivante :
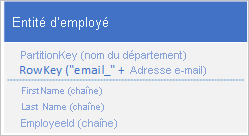
Il est généralement préférable de stocker les données en double et de vous assurer que vous pouvez récupérer toutes les données dont vous avez besoin avec une seule requête, plutôt que d'utiliser une requête pour rechercher une entité et une autre pour rechercher les données requises.
Quand utiliser ce modèle
Utilisez ce modèle lorsque votre application cliente a besoin de récupérer des entités en utilisant des clés différentes, lorsque votre client a besoin de récupérer des entités dans différents ordres de tri et où vous pouvez identifier chaque entité à l'aide d'une variété de valeurs uniques. Toutefois, vous devez être sûr de ne pas dépasser les limites d’extensibilité de partition lorsque vous effectuez des recherches d’entité à l’aide des différentes valeurs de RowKey .
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Modèle d’index secondaire entre les partitions
- Modèle de clé composée
- Transactions de groupe d’entités
- Utilisation des types d’entités hétérogènes
Modèle d’index secondaire entre les partitions
Stockez plusieurs copies de chaque entité à l’aide de différentes valeurs de RowKey dans des partitions ou des tables distinctes pour mener des recherches rapides et efficaces et alterner des commandes de tri à l’aide de différentes valeurs de RowKey.
Contexte et problème
Le service de Table indexe automatiquement les entités en utilisant les valeurs de PartitionKey et de RowKey. Ainsi, une application cliente peut récupérer une entité efficacement à l'aide de ces valeurs. Par exemple, à l’aide de la structure de table ci-dessous, une application cliente peut utiliser une requête de pointage pour récupérer une entité d’employé individuelle en utilisant le nom de service et l’ID d’employé (PartitionKey et RowKey). Un client peut aussi récupérer des entités triées par ID d’employé au sein de chaque service.

Si vous voulez également pouvoir trouver une entité d'employé en fonction de la valeur d'une autre propriété, comme l'adresse de messagerie, vous devez utiliser une analyse de partition moins efficace pour rechercher une correspondance. En effet, le service de Table ne fournit pas d'index secondaires. De plus, vous ne pouvez pas demander une liste des employés triés dans un ordre différent de celui de RowKey .
Vous prévoyez un volume élevé de transactions sur ces entités et vous souhaitez réduire le risque de limitation de votre client par le service de Table.
Solution
Pour contourner l’absence d’index secondaires, vous pouvez stocker plusieurs copies de chaque entité avec chaque copie à l’aide de différentes valeurs de PartitionKey et de RowKey. Si vous stockez une entité avec les structures indiquées ci-dessous, vous pouvez récupérer efficacement des entités d’employé selon leur adresse e-mail ou leur ID d’employé. Les valeurs de préfixe pour PartitionKey, « empid » et « email » permettent d’identifier l’index à utiliser pour une requête.

Les deux critères de filtre suivants (l’un recherchant selon l’ID d’employé et l’autre selon l’adresse e-mail) spécifient des requêtes de pointage :
- $filter=(PartitionKey eq ’empid_Sales’) and (RowKey eq ’000223’)
- $filter=(PartitionKey eq ’email_Sales’) and (RowKey eq jonesj@contoso.com
Si vous interrogez un ensemble d’entités d’employé, vous pouvez spécifier une plage triée par ID d’employé ou une plage triée par adresse e-mail en recherchant les entités avec le préfixe approprié dans RowKey.
- Pour rechercher tous les employés du service des ventes avec un ID d’employé compris entre 000100 et 000199, utilisez : $filter=(PartitionKey eq ’empid_Sales’) and (RowKey ge ’000100’) and (RowKey le ’000199’)
- Pour rechercher tous les employés du service des ventes ayant une adresse de messagerie qui commence par « a » triés dans l’ordre des adresses de messagerie, utilisez : $filter=(PartitionKey eq ’email_Sales’) and (RowKey ge ’a’) and (RowKey lt ’b’)
La syntaxe de filtre utilisée dans les exemples ci-dessus provient de l’API REST Service de Table. Pour en savoir plus, consultez Interrogation d’entités.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
Vous pouvez conserver la cohérence de vos entités en double en utilisant le modèle de transactions cohérentes pour gérer les entités d’index primaire et secondaire.
L'utilisation du stockage de tables est relativement bon marché. Le coût réel du stockage des données en double ne doit donc pas être une préoccupation majeure. Toutefois, vous devez toujours évaluer le coût de la conception en fonction de vos besoins en stockage anticipés et ajouter uniquement des entités en double pour prendre en charge les requêtes que votre application cliente exécutera.
La valeur de la RowKey doit être unique pour chaque entité. Nous vous conseillons d'utiliser des valeurs de clé composée.
Le remplissage des valeurs numériques dans RowKey (par exemple, l’ID d’employé 000223) permet de corriger le tri et le filtrage en fonction des limites inférieure et supérieure.
Vous n'avez pas toujours besoin de dupliquer toutes les propriétés de votre entité. Par exemple, si les requêtes de recherche des entités à l’aide de l’adresse de messagerie dans la RowKey n’ont jamais besoin de l’âge de l’employé, ces entités peuvent présenter la structure suivante :
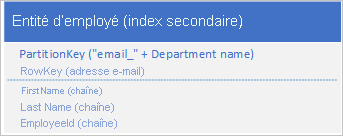
Il est généralement préférable de stocker les données en double et de vous assurer que vous pouvez récupérer toutes les données dont vous avez besoin en utilisant une seule requête, plutôt que d’utiliser une requête pour rechercher une entité à l’aide de l’index secondaire et une autre pour rechercher les données requises dans l’index primaire.
Quand utiliser ce modèle
Utilisez ce modèle lorsque votre application cliente a besoin de récupérer des entités en utilisant des clés différentes, lorsque votre client a besoin de récupérer des entités dans différents ordres de tri et où vous pouvez identifier chaque entité à l'aide d'une variété de valeurs uniques. Utilisez ce modèle si vous voulez éviter le dépassement des limites d’extensibilité de partition quand vous effectuez des recherches d’entité à l’aide des différentes valeurs de RowKey .
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Modèle de transactions cohérentes
- Modèle d’index secondaire intra-partition
- Modèle de clé composée
- Transactions de groupe d’entités
- Utilisation des types d’entités hétérogènes
Modèle de transactions cohérentes
Permet de conserver un comportement cohérent entre les limites de partition ou les limites du système de stockage à l'aide des files d'attente Azure.
Contexte et problème
Les EGT activent les transactions atomiques de plusieurs entités qui partagent la même clé de partition. Pour des raisons d'évolutivité et de performances, vous pouvez décider de stocker des entités ayant des exigences de cohérence dans des partitions distinctes ou dans un système de stockage distinct : dans ce scénario, vous ne pouvez pas utiliser les EGT pour maintenir la cohérence. Par exemple, vous pouvez avoir besoin de maintenir la cohérence entre :
- des entités stockées dans deux partitions différentes de la même table, dans des tables différentes ou dans différents comptes de stockage ;
- une entité stockée dans le service de Table et un objet blob stocké dans le service d'objets blob ;
- une entité stockée dans le service de Table et un fichier dans un système de fichiers ;
- une entité stockée dans le service de Table, mais indexée avec le service Recherche cognitive Azure.
Solution
À l'aide des files d'attente Azure, vous pouvez implémenter une solution cohérente entre plusieurs partitions ou systèmes de stockage. Pour illustrer cette approche, supposons que vous ayez besoin d'archiver d'anciennes entités d'employés. Les anciennes entités d'employés sont rarement interrogées et doivent être exclues de toutes les activités impliquant des employés actuels. Pour implémenter cette exigence, vous stockez des employés actifs dans la table Current et les anciens employés dans la table Archive. L’archivage d’un employé nécessite la suppression de son entité de la table Current et son ajout à la table Archive, mais vous ne pouvez pas utiliser une EGT pour effectuer ces deux opérations. Pour éviter le risque qu'une défaillance provoque l'apparition d'une entité dans les deux tables ou dans aucune d'elles, l'opération d'archivage doit être cohérente. Le diagramme de séquence suivant décrit les étapes de cette opération. Le texte suivant fournit plus de détails au sujet des chemins d'accès de l'exception.
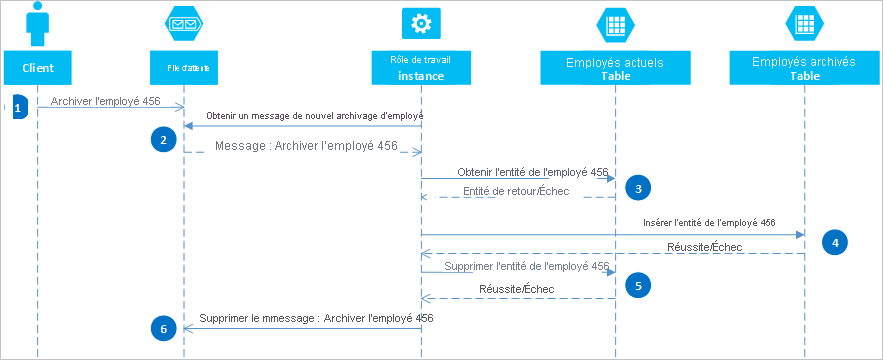
Un client lance l'opération d'archivage en plaçant un message dans une file d'attente Azure, dans cet exemple pour archiver l'employé #456. Un rôle de travail interroge la file d'attente à la recherche de nouveaux messages ; lorsqu'il en trouve un, il le lit et laisse une copie masquée dans la file d'attente. Le rôle de travail extrait ensuite une copie de l’entité à partir de la table Current, insère une copie dans la table Archive et supprime l’original de la table Current. Enfin, si aucune erreur n'est survenue lors des étapes précédentes, le rôle de travail supprime le message masqué de la file d'attente.
Dans cet exemple, l’étape 4 permet d’insérer l’employé dans la table Archive . L'employé peut être ajouté à un objet blob dans le service d'objets blob ou à un fichier dans un système de fichiers.
Récupération après échec
Il est important que les opérations des étapes 4 et 5 soient idempotentes au cas où le rôle de travail nécessite un redémarrage de l’opération d’archivage. Si vous utilisez le service de Table, à l’étape 4, vous devez utiliser une opération « insérer ou remplacer » (insert or replace) ; à l’étape 5, vous devez faire appel à une opération « supprimer si existe » (delete if exists) dans la bibliothèque cliente que vous utilisez. Si vous utilisez un autre système de stockage, vous devez utiliser une opération idempotent appropriée.
Si le rôle de travail ne termine jamais l’étape 6, après un délai d’attente, le message réapparaît dans la file d’attente, prêt pour le rôle de travail qui tentera de le retraiter. Le rôle de travail peut vérifier le nombre de fois où un message de file d'attente a été lu et, si nécessaire, l'indiquer comme message « incohérent » en vue d'une investigation en l'envoyant vers une file d'attente distincte. Pour plus d’informations sur la lecture des messages de la file d’attente et la vérification du nombre de retraits, consultez Obtention des messages.
Certaines erreurs provenant des services de Table et de File d'attente sont des erreurs temporaires et votre application cliente doit inclure une logique de nouvelle tentative appropriée pour les gérer.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Cette solution ne fournit pas d'isolation des transactions. Par exemple, un client peut lire les tables Current et Archive quand le rôle de travail est entre les étapes 4 et 5, et voir des données incohérentes affichées. Les données seront cohérentes par la suite.
- Vous pouvez être amené à vérifier que les étapes 4 et 5 sont idempotent afin d'assurer la cohérence.
- Vous pouvez mettre à l'échelle la solution en utilisant plusieurs files d'attente et instances de rôle de travail.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous souhaitez maintenir une cohérence entre des entités qui existent dans différentes partitions ou tables. Vous pouvez étendre ce modèle pour garantir la cohérence des opérations entre le service de Table, le service BLOB et d'autres sources de données différentes d'Azure Storage, comme une base de données ou un système de fichiers.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Transactions de groupe d’entités
- Fusion ou remplacement
Notes
Si l'isolation des transactions est importante pour votre solution, vous devez envisager de redéfinir vos tables pour pouvoir utiliser des EGT.
Modèle d’entités d’index
Permet de mettre à jour des entités d'index pour mener des recherches efficaces renvoyant des listes d'entités.
Contexte et problème
Le service de Table indexe automatiquement les entités en utilisant les valeurs de PartitionKey et de RowKey. Ainsi, une application cliente peut récupérer une entité efficacement à l'aide d'une requête de pointage. Par exemple, à l’aide de la structure de table ci-dessous, une application cliente peut récupérer efficacement une entité d’employé individuelle en utilisant le nom du service et l’ID d’employé (PartitionKey et RowKey).

Si vous voulez également récupérer la liste des entités d'employés en fonction de la valeur d'une autre propriété qui n'est pas unique (par exemple, son nom), vous devez utiliser une analyse de partition moins efficace pour rechercher des correspondances, plutôt que d'utiliser un index pour rechercher directement. En effet, le service de Table ne fournit pas d'index secondaires.
Solution
Pour permettre la recherche par nom de famille en utilisant la structure d’entité indiquée ci-dessus, vous devez gérer des listes d’ID d’employés. Si vous voulez récupérer les entités d’employés ayant un nom donné (comme Jones), vous devez d’abord localiser la liste d’ID d’employés dont le nom est Jones, puis récupérer ces entités d’employés. Il existe trois méthodes principales pour stocker les listes d’ID d’employés :
- Le stockage d'objets blob.
- La création d'entités d'index dans la même partition que les entités des employés.
- La création d'entités d'index dans une table ou une partition séparée.
Option 1 : Utiliser le Stockage Blob
Pour la première option, vous créez un objet blob pour chaque nom unique et dans chaque magasin d’objets blob vous stockez une liste des valeurs de PartitionKey (service) et RowKey (ID d’employé) pour les employés de ce nom. Lorsque vous ajoutez ou supprimez un employé, vous devez vous assurer que le contenu de l’objet blob adéquat est cohérent avec les entités de l’employé.
Option 2 : Créer des entités d’index dans la même partition
Pour la seconde méthode, utilisez les entités d'index stockant les données suivantes :

La propriété EmployeeIDs contient une liste d’ID d’employés pour les employés portant le nom stocké dans la RowKey.
Les étapes suivantes décrivent le processus à suivre lorsque vous ajoutez un nouvel employé si vous utilisez la deuxième option. Dans cet exemple, nous ajoutons au service des ventes un employé ayant l’ID 000152 et dont le nom de famille est Jones :
- Récupérez l’entité de l’index par la valeur de PartitionKey « Sales » et la valeur de RowKey « Jones ». Enregistrez l’ETag de cette entité pour l’utiliser lors de l’étape 2.
- Créez une transaction de groupe d’entités (c’est-à-dire une opération par lots) qui insère la nouvelle entité d’employé (valeur de PartitionKey « Sales » et valeur de RowKey « 000152 ») et met à jour l’entité d’index (valeur de PartitionKey « Sales » et valeur de RowKey « Jones ») en ajoutant l’ID d’employé à la liste du champ EmployeeIDs. Pour plus d’informations sur les transactions de groupe d’entités, consultez Transactions de groupe d’entités.
- Si la transaction de groupe d’entités échoue en raison d’une erreur d’accès concurrentiel optimiste (quelqu’un d’autre vient de modifier l’entité d’index), vous devez recommencer à l’étape 1.
Vous pouvez utiliser une approche similaire pour supprimer un employé si vous utilisez la deuxième option. La modification du nom d’un employé est légèrement plus complexe, car vous devrez exécuter une transaction de groupe d’entités qui met à jour trois entités : l’entité d’employé, l’entité d’index pour l’ancien nom et l’entité d’index pour le nouveau nom. Vous devez récupérer chaque entité avant d'apporter des modifications afin de récupérer les valeurs ETag que vous pouvez ensuite utiliser pour effectuer les mises à jour à l'aide de l'accès concurrentiel optimiste.
Les étapes suivantes décrivent le processus à suivre lorsque vous devez rechercher tous les employés ayant un nom donné dans un service, si vous utilisez la deuxième méthode. Dans cet exemple, nous recherchons tous les employés dont le nom est Jones et qui travaillent dans le service des ventes :
- Récupérez l’entité de l’index par la valeur de PartitionKey « Sales » et la valeur de RowKey « Jones ».
- Analysez la liste des identificateurs dans le champ EmployeeIDs des employés.
- Si vous avez besoin de plus d’informations sur chacun de ces employés (par exemple leurs adresses de messagerie), récupérez chacune des entités d’employé à l’aide de la valeur de PartitionKey « Sales » et des valeurs de RowKey de la liste des employés obtenue à l’étape 2.
Option 3 : Créer des entités d’index dans une table ou une partition séparée
Pour cette troisième méthode, utilisez les entités d'index qui stockent les données suivantes :

La propriété EmployeeDetails contient une liste de paires ID d’employé/nom de département pour les employés dont le nom est stocké dans RowKey.
Dans la troisième méthode, vous ne pouvez pas utiliser des EGT pour maintenir la cohérence, car les entités d'index sont dans une partition distincte des entités d'employé. Vérifiez que les entités d’index sont cohérentes avec les entités d’employé.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Cette solution nécessite au moins deux requêtes pour récupérer des entités correspondantes : une pour interroger les entités d’index afin d’obtenir la liste des valeurs RowKey , puis des requêtes pour récupérer chaque entité dans la liste.
- Étant donné qu’une entité a une taille maximale de 1 Mo, l’utilisation des méthodes #2 et #3 dans la solution supposent que la liste d’ID d’employés pour n’importe quel nom donné n’est jamais supérieure à 1 Mo. Si la liste d’ID d’employés est susceptible d’être supérieure à 1 Mo, utilisez la méthode #1 et stockez les données d’index dans le stockage d’objets blob.
- Si vous utilisez l’option #2 (à l’aide des EGT pour gérer l’ajout et la suppression des employés et la modification du nom d’un employé), vous devez évaluer si le volume des transactions atteint les limites de l’évolutivité dans une partition donnée. Si c'est le cas, vous devez envisager une solution cohérente (méthode 1# ou #3) qui utilisera des files d'attente pour gérer les demandes de mise à jour et vous permettra de stocker vos entités d'index dans une partition distincte à partir des entités d'employés.
- La méthode #2 de cette solution part du principe que vous souhaitez effectuer une recherche par nom de famille dans un service : par exemple, si vous souhaitez récupérer une liste des employés avec un nom de famille Jones dans le service des ventes. Si vous souhaitez être en mesure de rechercher dans toute l'organisation tous les employés portant le nom de famille Jones, suivez la méthode # 1 ou # 3.
- Vous pouvez implémenter une solution basée sur la file d’attente qui assure la cohérence éventuelle (pour plus d’informations, voir le modèle de transactions cohérentes ).
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous souhaitez rechercher un jeu d’entités qui partagent toutes une valeur de propriété courante, comme l’ensemble des employés dont le nom de famille est Jones.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Modèle de clé composée
- Modèle de transactions cohérentes
- Transactions de groupe d’entités
- Utilisation des types d’entités hétérogènes
Modèle de dénormalisation
Combinez des données connexes dans une entité unique pour pouvoir récupérer toutes les données dont vous avez besoin avec une seule requête de pointage.
Contexte et problème
Dans une base de données relationnelle, vous normalisez généralement des données pour supprimer des doublons résultant des requêtes qui extraient des données provenant de plusieurs tables. Si vous normalisez des données dans les tables Azure, vous devez effectuer plusieurs allers-retours à partir du client vers le serveur pour récupérer des données associées. Par exemple, avec la structure de table indiquée ci-dessous, vous devez effectuer deux opérations complètes pour récupérer les détails d’un service : une pour extraire l’entité de service qui inclut l’ID du responsable, puis une autre pour extraire les détails du responsable dans une entité d’employé.

Solution
Au lieu de stocker les données dans les deux entités distinctes, dénormalisez les données et conservez une copie des détails du responsable dans l’entité du service. Par exemple :
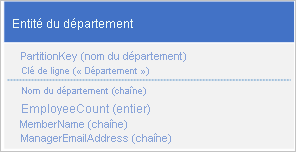
Une fois les entités de service stockées avec ces propriétés, vous pouvez récupérer toutes les informations nécessaires sur un service à l'aide d'une requête de pointage.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Des coûts réels sont associés au stockage des données à deux reprises. Les bénéfices de performance (résultant d'une diminution des demandes relatives au service Azure Storage) dépassent généralement l'augmentation mineure des coûts de stockage (et ce coût est partiellement compensé par une réduction du nombre de transactions dont vous avez besoin pour extraire les détails au service).
- Vous devez conserver la cohérence des deux entités qui stockent des informations sur les responsables. Vous pouvez gérer le problème de cohérence à l'aide des EGT pour mettre à jour plusieurs entités dans une transaction atomique unique : dans ce cas, l'entité du service et celle de l'employé pour le responsable du service sont stockées dans la même partition.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous devez fréquemment rechercher des informations connexes. Ce modèle réduit le nombre de requêtes que votre client doit effectuer pour récupérer les données requises.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Modèle de clé composée
- Transactions de groupe d’entités
- Utilisation des types d’entités hétérogènes
Modèle de clé composée
Utilisez les valeurs de RowKey composée pour permettre à un client de rechercher des données associées en utilisant une seule requête de pointage.
Contexte et problème
Dans une base de données relationnelle, il est naturel d’utiliser des jointures dans les requêtes pour renvoyer les ensembles de données au client dans une seule requête. Par exemple, vous pouvez utiliser l’ID d’employé pour rechercher une liste d’entités associées qui contiennent des données de performances et d’évaluation de cet employé.
Supposons que vous stockiez des entités relatives aux employés dans le service de Table à l'aide de la structure suivante :

Vous devez également stocker les données historiques relatives aux évaluations et aux performances de chaque année durant laquelle l'employé a travaillé pour votre organisation, et vous devez être en mesure d'accéder à ces informations par année. Une option consiste à créer une autre table qui stocke les entités avec la structure suivante :

Notez que, avec cette approche, vous pouvez décider de dupliquer certaines informations (telles que le prénom et le nom) dans la nouvelle entité afin de pouvoir récupérer vos données avec une requête unique. Cependant, vous ne pouvez pas conserver une cohérence forte, car vous ne pouvez pas utiliser une EGT pour mettre à jour les deux entités de manière atomique.
Solution
Stockez un nouveau type d'entité dans votre table d'origine à l'aide d'entités structurées comme suit :

Notez que RowKey est à présent une clé composée, basée sur l’ID d’employé et l’année des données d’évaluation, ce qui vous permet de récupérer les données de performances et d’évaluation de l’employé au moyen d’une seule demande pour une seule entité.
L'exemple suivant indique comment vous pouvez récupérer toutes les données d'évaluation d'un employé donné (par exemple, l'employé 000123 du service des ventes) :
$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000123') and (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Vous devez utiliser un caractère de séparation approprié pour faciliter l’analyse des valeurs de RowKey : par exemple, 000123_2012.
- Vous stockez également cette entité dans la même partition que les autres entités qui contiennent des données associées au même employé, ce qui signifie que vous pouvez utiliser des EGT pour maintenir une forte cohérence.
- Vous devez prendre en compte la fréquence à laquelle vous interrogez les données afin de déterminer si ce modèle est approprié. Par exemple, si vous accédez rarement aux données d'évaluation et souvent aux données principales de l'employé, vous devez les conserver en entités distinctes.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous devez stocker une ou plusieurs entités connexes que vous interrogez fréquemment.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Transactions de groupe d’entités
- Utilisation des types d’entités hétérogènes
- Modèle de transactions cohérentes
Modèle de fin de journal
Récupérez les n entités récemment ajoutées à une partition en utilisant une valeur de RowKey qui effectue un tri dans l’ordre inverse de la date et de l’heure.
Contexte et problème
Une exigence courante était de pouvoir récupérer les entités plus récemment créées, par exemple les 10 dernières notes de frais soumises par un employé. Les requêtes de table prennent en charge une opération de requête $top pour retourner les n premières entités en provenance d’un ensemble. Il n’existe aucune opération de requête équivalente pour retourner les n dernières entités d’un ensemble.
Solution
Stockez les entités en utilisant une RowKey qui trie naturellement l’ordre inverse de date et d’heure par utilisation, pour que l’entrée la plus récente soit toujours la première dans la table.
Par exemple, pour être en mesure de récupérer les 10 dernières notes de frais soumises par un employé, vous pouvez utiliser une valeur de graduation inverse dérivée de l’heure actuelle. L’exemple de code C# suivant montre une méthode de création d’une valeur de « graduation inverse » adéquate pour une RowKey qui procède à un tri du plus récent au plus ancien :
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Vous pouvez récupérer la valeur de date-heure en utilisant le code suivant :
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
La requête de table ressemble à ceci :
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Vous devez faire précéder la valeur de graduation inverse par des zéros non significatifs pour garantir que la valeur de chaîne trie comme prévu.
- Vous devez être conscient des objectifs d'évolutivité au niveau d'une partition. Veillez à ne pas créer des partitions de zone sensible.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous avez besoin d'accéder aux entités dans l'ordre inverse de date-heure ou lorsque vous devez accéder aux entités ajoutées récemment.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
Modèle de suppression de volume élevé
Activez la suppression d'un volume élevé d'entités en stockant toutes les entités pour les supprimer simultanément dans leur propre table distincte ; vous supprimez les entités en supprimant la table.
Contexte et problème
De nombreuses applications suppriment les anciennes données qui n’ont plus besoin d’être disponibles pour une application cliente ou archivées par l’application sur un autre support de stockage. Vous identifiez généralement ces données à une date : par exemple, vous devez supprimer les enregistrements de toutes les demandes de connexion datant de plus de 60 jours.
Une conception possible consiste à utiliser la date et l’heure de la demande de connexion dans la RowKey:
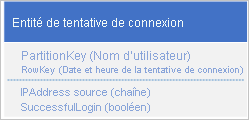
Cette approche évite les zones sensibles de partition, car l'application peut insérer et supprimer des entités de connexion pour chaque utilisateur dans une partition séparée. Toutefois, cette approche peut être coûteuse et fastidieuse si vous avez beaucoup d'entités, car vous devez d'abord analyser la table pour identifier toutes les entités à supprimer, avant de supprimer chaque ancienne entité. Vous pouvez réduire le nombre d’allers-retours vers le serveur requis pour supprimer les anciennes entités en traitant par lots plusieurs demandes de suppression dans les TGE.
Solution
Utilisez une table distincte pour chaque jour de tentative de connexion. Vous pouvez utiliser la conception de l'entité ci-dessus afin d'éviter les zones sensibles lorsque vous insérez des entités et la suppression des anciennes entités consiste désormais à simplement supprimer une table tous les jours (une seule opération de stockage) au lieu de rechercher et de supprimer des centaines de milliers d'entités de connexion individuelle chaque jour.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Votre conception prend-elle en charge les autres méthodes de traitement des données que votre application va utiliser, telles que la recherche des entités spécifiques, les liaisons avec d'autres données ou la génération des informations d'agrégation ?
- Votre conception évite-t-elle les zones sensibles lorsque vous insérez de nouvelles entités ?
- Vous devez attendre un délai si vous voulez réutiliser le même nom de table après l'avoir supprimée. Il est préférable de toujours utiliser des noms de table uniques.
- Prévoyez une limitation lorsque vous utiliserez tout d'abord une table pendant que le service de Table assimile les modèles d'accès et distribue les partitions entre les nœuds. Vous devez réfléchir à la fréquence à laquelle vous devez créer des tables.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous avez un volume élevé d'entités, que vous devez supprimer en même temps.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Transactions de groupe d’entités
- Modification des entités
Modèle de série de données
Stockez des séries de données complètes dans une entité unique pour réduire votre nombre de demandes.
Contexte et problème
Il arrive qu'une application stocke une série de données qu'elle doit fréquemment récupérer en une seule fois : Par exemple, votre application peut enregistrer combien de messages de messagerie instantanée chaque employé envoie toutes les heures, puis utiliser ces informations pour tracer le nombre de messages envoyés par chaque utilisateur dans les 24 heures précédentes. Une conception peut consister à stocker 24 entités pour chaque employé :
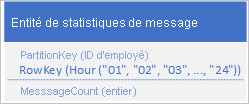
Grâce à cette conception, vous pouvez facilement rechercher et mettre à jour l'entité mise à jour pour chaque employé chaque fois que l'application doit mettre à jour la valeur de nombre de messages. Cependant, pour récupérer les informations pour tracer un graphique de l'activité des 24 heures précédentes, vous devez récupérer les 24 entités.
Solution
Utilisez la conception suivante avec une propriété distincte pour stocker le nombre de messages pour chaque heure :
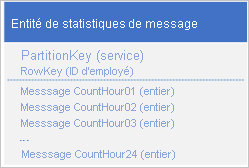
Grâce à cette conception, vous pouvez utiliser une opération de fusion pour mettre à jour le nombre de messages pour un employé pour une heure spécifique. À présent, vous pouvez récupérer toutes les informations dont vous avez besoin pour tracer le graphique à l'aide d'une requête pour une seule entité.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Si votre série de données complète ne tient pas dans une seule entité (une entité peut avoir jusqu'à 252 propriétés), utilisez un autre magasin de données, comme un objet blob.
- Si vous avez plusieurs clients qui mettent à jour une entité simultanément, vous devez utiliser le ETag pour implémenter l’accès concurrentiel optimiste. Si vous avez de nombreux clients, vous pouvez rencontrer une contention élevée.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous devez mettre à jour et récupérer une série de données associée à une entité individuelle.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Modèle d'entités volumineuses
- Fusion ou remplacement
- Modèle de transactions cohérentes (si vous stockez la série de données dans un objet blob)
Modèle d’entités larges
Utilisez plusieurs entités physiques pour stocker des entités logiques ayant plus de 252 propriétés.
Contexte et problème
Une entité individuelle ne peut pas avoir plus de 252 propriétés (à l'exception des propriétés système obligatoires) et ne peut pas stocker plus de 1 Mo de données au total. Dans une base de données relationnelle, vous allez généralement arrondir les limites de taille d'une ligne en ajoutant une nouvelle table et en appliquant une relation 1 à 1 entre elles.
Solution
À l'aide du service de Table, vous pouvez stocker plusieurs entités pour représenter un objet métier volumineux unique ayant plus de 252 propriétés. Par exemple, si vous souhaitez stocker le nombre de messages instantanés envoyés par chaque employé durant les 365 derniers jours, vous pouvez utiliser la conception suivante qui utilise deux entités avec des schémas différents :
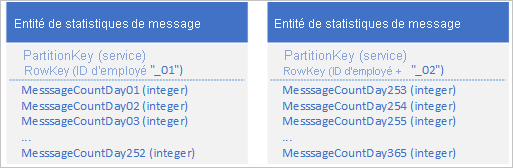
Si vous souhaitez apporter une modification qui nécessite la mise à jour des deux entités pour les garder mutuellement synchronisées, vous pouvez utiliser une EGT. Sinon, vous pouvez utiliser une opération de fusion pour mettre à jour le nombre de messages pour un jour spécifique. Pour récupérer toutes les données pour un employé individuel, vous devez récupérer les deux entités. Pour ce faire, utilisez deux demandes efficaces qui utilisent toutes deux une valeur de PartitionKey et de RowKey.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- La récupération d'une entité logique complète implique au moins deux transactions de stockage : une pour récupérer chaque entité physique.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous avez besoin de stocker des entités dont la taille ou le nombre de propriétés dépassent les limites d'une entité individuelle dans le service de Table.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
- Transactions de groupe d’entités
- Fusion ou remplacement
Modèle d’entités volumineuses
Utilisez le stockage d'objets blob pour stocker des valeurs de propriétés volumineuses.
Contexte et problème
Une entité individuelle ne peut pas stocker plus de 1 Mo de données au total. Si une ou plusieurs des propriétés stockent des valeurs qui provoquent un dépassement de la taille totale de votre entité, vous ne pouvez pas stocker l'intégralité de l'entité sur le service de Table.
Solution
Si votre entité dépasse 1 Mo, car une ou plusieurs propriétés contiennent une grande quantité de données, vous pouvez stocker des données dans le service BLOB et stocker ensuite l'adresse de l'objet blob dans une propriété de l'entité. Par exemple, vous pouvez stocker la photo d’un employé dans le stockage d’objets blob et stocker un lien vers la photo dans la propriété Photo de votre entité d’employé :

Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Pour maintenir la cohérence entre l’entité du service de Table et les données du service BLOB, utilisez le modèle de transactions cohérentes pour maintenir vos entités.
- La récupération d'une entité complète implique au moins deux transactions de stockage : une pour récupérer l'entité et l'autre pour récupérer les données blob.
Quand utiliser ce modèle
Utilisez ce modèle lorsque vous avez besoin de stocker des entités dont la taille dépasse les limites d'une entité individuelle dans le service de Table.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
Ajouter un anti-modèle ou un préfixe d'anti-modèle
Augmentez l'évolutivité lorsque vous avez un volume élevé d'insertions en répartissant les insertions sur plusieurs partitions.
Contexte et problème
L'ajout d'entité ou de suffixe d'entité à vos entités stockées pousse généralement l'application à ajouter de nouvelles entités à la première ou à la dernière partition d'une séquence. Dans ce cas, toutes les insertions à tout moment ont lieu dans la même partition, créant une zone sensible qui empêche le service de Table d'équilibrer la charge sur plusieurs nœuds et éventuellement de pousser votre application à atteindre les objectifs d'extensibilité pour la partition. Par exemple, si vous avez une application qui journalise l’accès au réseau et aux ressources des employés, une structure d’entité semblable à celle affichée ci-dessous peut transformer la partition de l’heure actuelle en zone sensible si le volume des transactions atteint l’objectif d’évolutivité pour une partition individuelle :

Solution
La structure d’entité alternative suivante permet d’éviter une zone sensible dans n’importe quelle partition particulière tandis que l’application journalise les événements :

Dans cet exemple, notez que PartitionKey et RowKey sont toutes deux des clés composées. PartitionKey utilise les ID de service et d’employé pour distribuer la journalisation sur plusieurs partitions.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- La structure clé alternative qui évite de créer efficacement des partitions sensibles sur des insertions prend-elle en charge efficacement les requêtes effectuées par votre application cliente ?
- Le volume prévu de transactions signifie-t-il que vous êtes susceptible d'atteindre les objectifs d'évolutivité pour une partition individuelle et d'être limité par le service de stockage ?
Quand utiliser ce modèle
Évitez l'ajout d'anti-modèle ou de suffixe d'anti-modèle lorsque votre volume de transactions est susceptible d'entraîner la limitation par le service de stockage lorsque vous accédez à une partition sensible.
Conseils et modèles connexes
Les modèles et les conseils suivants peuvent également être pertinents lors de l'implémentation de ce modèle :
Journalisation de l'anti-modèle de données
En règle générale, vous devez utiliser le service BLOB plutôt que le service de Table pour stocker les données du journal.
Contexte et problème
Un cas d'utilisation courante des données de journal consiste à récupérer une sélection d'entrées de journal pour une plage de date/heure spécifique : par exemple, vous souhaitez rechercher tous les messages d'erreur et critiques enregistrés par votre application entre 15h04 et 15h06 à une date spécifique. Vous ne souhaitez pas utiliser la date et l’heure du message de journalisation pour déterminer la partition sur laquelle vous enregistrez les entités de journalisation : cela entraîne une partition sensible, car à n’importe quel moment, toutes les entités de journalisation partageront la même valeur de PartitionKey (consultez la section Ajouter un anti-modèle ou un préfixe d’anti-modèle). Par exemple, le schéma d'entité suivant d'un message de journalisation génère une partition sensible, car l'application écrit tous les messages de journalisation sur la partition pour la date et l'heure actuelles :
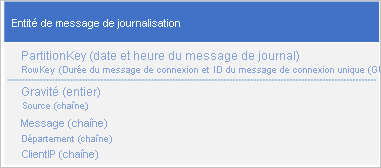
Dans cet exemple, RowKey inclut la date et l’heure du message de journalisation pour garantir que les messages de journalisation sont stockés et triés dans l’ordre de date/heure et incluent un ID de message au cas où plusieurs messages de journalisation partagent les mêmes date et heure.
Une autre approche consiste à utiliser une valeur de PartitionKey qui garantit que l’application écrit des messages dans une plage de partitions. Par exemple, si la source du message de journalisation fournit un moyen de distribuer les messages sur plusieurs partitions, vous pouvez utiliser le schéma de l'entité suivante :
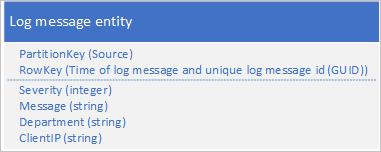
Toutefois, le problème avec ce schéma est que, pour récupérer tous les messages de journalisation pour un intervalle de temps spécifique, vous devez rechercher chaque partition dans la table.
Solution
La section précédente a présenté le problème posé par la tentative d'utilisation du service de Table pour stocker des entrées de journalisation et a suggéré deux conceptions, peu satisfaisantes. Une solution a conduit à une partition sensible, avec le risque de faibles performances d'écriture de messages de journalisation ; l'autre solution a entraîné des performances médiocres, en raison de la nécessité d'analyser chaque partition dans la table pour récupérer les messages du journal pour une période spécifique. Le stockage d'objets blob offre une meilleure solution pour ce type de scénario. Voici comment Azure Storage Analytics stocke les données de journalisation collectées.
Cette section décrit comment Storage Analytics stocke les données de journalisation dans le stockage d'objets blob, en guise d'illustration de cette approche pour le stockage des données que vous interrogez généralement par plage.
Storage Analytics stocke les messages de journalisation dans un format délimité dans plusieurs objets blob. Ce format facilite l'analyse des données du message de journalisation pour une application cliente.
Storage Analytics utilise une convention d'affectation des noms d'objets blob qui vous permet de localiser le ou les objets blob contenant les messages de journalisation que vous recherchez. Par exemple, un objet blob nommé « queue/2014/07/31/1800/000001.log » contient des messages de journalisation liés au service de File d'attente dont l'heure de début est à 18h00, le 31 juillet 2014. Le « 000001 » indique qu'il s'agit du premier fichier journal pour cette période. Storage Analytics enregistre également les horodatages du premier et du dernier messages stockés dans le fichier dans le cadre des métadonnées de l’objet blob. L'API pour le stockage d'objets blob vous permet de rechercher des objets blob dans un conteneur selon un préfixe de nom : pour rechercher tous les objets blob qui contiennent des données de journalisation des files d'attente correspondant à l'heure de début de 18h00, vous pouvez utiliser le préfixe « queue/2014/07/31/1800 ».
Storage Analytics met en mémoire tampon les messages de journalisation en interne, puis met à jour de façon périodique l'objet blob adéquat ou en crée un autre avec le dernier lot d'entrées de journalisation. Cela réduit le nombre d'écritures qu'il doit exécuter vers le service BLOB.
Si vous implémentez une solution similaire dans votre propre application, vous devez déterminer comment gérer le compromis entre la fiabilité (écrire chaque entrée de journalisation pour le stockage d'objets blob comme cela est le cas) et le coût, ainsi que l'évolutivité (mise en mémoire tampon des mises à jour dans votre application et écriture du stockage d'objet blob par lots).
Problèmes et considérations
Prenez en compte les points suivants lorsque vous décidez de la manière de stocker des données de journalisation :
- Si vous créez une conception de table qui évite les partitions sensibles potentielles, il est possible que l'accès aux données de journalisation ne soit pas très efficace.
- Pour traiter les données de journalisation, un client doit souvent charger de nombreux enregistrements.
- Bien que les données de journalisation soient souvent structurées, le stockage d'objets blob peut être une meilleure solution.
Considérations relatives à l’implémentation
Cette section décrit certaines des considérations à prendre en compte lorsque vous implémentez les modèles décrits dans les sections précédentes. La majeure partie de cette section utilise des exemples rédigés en C# qui se sert de la bibliothèque cliente Stockage Azure (version 4.3.0 au moment de la rédaction).
Récupération des entités
Comme indiqué dans la section Conception pour l’interrogation, la requête la plus efficace est une requête de pointage. Toutefois, dans certains scénarios, vous devrez peut-être récupérer plusieurs entités. Cette section décrit certaines des approches courantes permettant de récupérer des entités à l'aide de la bibliothèque cliente Stockage Azure.
Exécution d'une requête de pointage à l'aide de la bibliothèque cliente Stockage Azure
La méthode la plus simple pour exécuter une requête de pointage consiste à utiliser la méthode GetEntityAsync, comme indiqué dans l’extrait de code C# suivant, qui récupère une entité avec une PartitionKey dont la valeur est « Sales » et une RowKey dont la valeur est « 212 » :
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Notez que cet exemple part du principe que l’entité extraite doit être de type EmployeeEntity.
Récupération de plusieurs entités à l’aide de LINQ
Vous pouvez utiliser LINQ pour récupérer plusieurs entités à partir du service de Table lorsque vous travaillez avec la bibliothèque standard de tables Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Pour que les exemples ci-dessous fonctionnent, vous devez inclure des espaces de noms :
using System.Linq;
using Azure.Data.Tables
La récupération de plusieurs entités peut être réalisée en spécifiant une requête contenant une clause filter. Pour éviter une analyse de table, vous devez toujours inclure la valeur de PartitionKey dans la clause filter, et si possible la valeur de RowKey afin d’éviter les analyses de table et de partition. Le service de Table prend en charge un ensemble limité d’opérateurs de comparaison (greater than, greater than or equal, less than or equal, equal et not equal) (supérieur à, supérieure ou égal à, inférieur ou égal à, égal et différent de) utilisables dans la clause filter.
Dans l’exemple suivant, employeeTable est un objet de TableClient. Cet exemple recherche tous les employés dont le nom commence par « B » (en supposant que RowKey stocke le nom de famille) du service des ventes (en supposant que PartitionKey stocke le nom du service) :
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Notez comment la requête spécifie à la fois une RowKey et une PartitionKey pour garantir des performances optimales.
L’exemple de code suivant montre des fonctionnalités équivalentes sans utiliser la syntaxe LINQ :
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Notes
Les méthodes exemples Query incluent les trois conditions de filtre.
Récupération d'un grand nombre d'entités à partir d'une requête
Une requête optimale renvoie une entité individuelle basée sur une valeur de PartitionKey et une valeur de RowKey. Toutefois, dans certains scénarios, vous pouvez être obligé de renvoyer de nombreuses entités à partir de la même partition ou même de plusieurs partitions.
Vous devez toujours tester entièrement les performances de votre application dans de tels scénarios.
Une requête sur le service de Table peut renvoyer un maximum de 1 000 entités à la fois et peut s'exécuter pendant un maximum de 5 secondes. Si l'ensemble des résultats contient plus de 1 000 entités, si la requête ne s'est pas terminée dans les 5 secondes ou si la requête dépasse la limite de la partition, le service de Table renvoie un jeton de liaison pour permettre à l'application cliente de demander l'ensemble d'entités suivant. Pour plus d’informations sur la façon dont fonctionnent les jetons de continuation, consultez Délai de requête et pagination.
Si vous utilisez la bibliothèque cliente Tables Azure, celle-ci peut gérer automatiquement les jetons de continuation pour vous en renvoyant des entités à partir du service de Table. L’exemple de code C# suivant utilise la bibliothèque cliente pour gérer automatiquement les jetons de continuation si le service de Table les renvoie dans une réponse :
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Vous pouvez également spécifier le nombre maximal d’entités retournées par page. L’exemple suivant montre comment définir des requêtes d’entités avec maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
Dans les scénarios plus avancés, vous pouvez stocker le jeton de continuation retourné par le service afin que votre code contrôle exactement quand les pages suivantes sont récupérées. L’exemple suivant présente un scénario de base illustrant la façon dont le jeton peut être récupéré et appliqué aux résultats paginés :
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
En utilisant des jetons de continuation de manière explicite, vous pouvez contrôler le moment où votre application extrait le segment suivant des données. Par exemple, si votre application cliente permet aux utilisateurs de parcourir les entités stockées dans une table, un utilisateur peut décider de ne pas parcourir toutes les entités récupérées par la requête pour que votre application utilise uniquement un jeton de continuation pour extraire le segment suivant lorsque l'utilisateur a terminé la pagination via toutes les entités dans le segment actuel. Cette approche présente plusieurs avantages :
- Elle vous permet de limiter la quantité de données à récupérer à partir du service de Table et que vous placez sur le réseau.
- Elle vous permet d'effectuer des E/S asynchrones dans .NET.
- Elle vous permet de sérialiser le jeton de continuation dans un stockage permanent, pour que vous puissiez continuer même si l'application tombe en panne.
Notes
En général, un jeton de liaison retourne un segment contenant 1 000 entités, bien qu'il puisse y en avoir moins. C’est également le cas si vous limitez le nombre d’entrées qu’une requête renvoie à l’aide de l’instruction Take (prendre) pour renvoyer les n premières entités qui correspondent à vos critères de recherche : le service de table peut renvoyer un segment contenant moins de n entités avec un jeton de liaison pour vous permettre de récupérer les entités restantes.
Projection côté serveur
Une seule entité peut avoir jusqu'à 255 propriétés et une taille allant jusqu'à 1 Mo. Lorsque vous interrogez la table et récupérez des entités, il est possible que vous n'ayez pas besoin de toutes les propriétés et que vous puissiez éviter de transférer des données sans que cela soit nécessaire (ce qui permet de réduire la latence et les coûts). Vous pouvez utiliser la projection côté serveur pour transférer uniquement les propriétés que vous avez besoin. L’exemple suivant récupère uniquement la propriété Email (avec les valeurs de PartitionKey, de RowKey, de Timestamp et d’ETag) à partir des entités sélectionnées par la requête.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Notez comment la valeur de RowKey est disponible même si elle ne figurait pas dans la liste de propriétés à récupérer.
Modification des entités
La bibliothèque cliente Stockage Azure vous permet de modifier les entités stockées dans votre service de Table pour les insérer, les supprimer et les mettre à jour. Vous pouvez utiliser EGTs pour traiter par lot plusieurs opérations d’insertion, mise à jour et suppression afin de réduire le nombre d’allers-retours requis et améliorer les performances de votre solution.
Les exceptions levées lorsque la bibliothèque cliente Stockage Azure exécute une EGT incluent généralement l’index de l’entité qui a provoqué l’échec du lot. Cela est utile lorsque vous déboguez du code qui utilise des EGT.
Nous vous conseillons de réfléchir également à la façon dont votre conception affecte la méthode de votre application cliente pour gérer les opérations d'accès concurrentiel et de mises à jour.
Gérer l'accès concurrentiel
Par défaut, le service de Table implémente des contrôles d’accès concurrentiel optimiste au niveau des entités individuelles pour les opérations d’insertion (Insert), de fusion (Merge) et de suppression (Delete), bien qu’il soit possible pour un client de forcer le service de Table à ignorer ces contrôles. Pour plus d’informations sur la façon dont le service de Table gère l’accès concurrentiel, consultez Gestion de l’accès concurrentiel dans Stockage Microsoft Azure.
Fusion ou remplacement
La méthode de remplacement (Replace) de la classe TableOperation remplace toujours l’entité complète du service de Table. Si vous n'incluez pas une propriété dans la demande lorsque cette propriété existe dans l'entité stockée, la demande supprime cette propriété de l'entité stockée. Si vous ne souhaitez pas supprimer une propriété explicitement à partir d'une entité stockée, vous devez inclure chaque propriété dans la demande.
Vous pouvez utiliser la méthode de fusion (Merge) de la classe TableOperation pour réduire la quantité de données que vous envoyez au service de Table quand vous souhaitez mettre à jour une entité. La méthode de fusion remplace toutes les propriétés de l’entité stockée par les valeurs de propriété de l’entité incluse dans la demande, mais ne modifie pas les propriétés de l’entité stockée qui ne sont pas incluses dans la demande. Cela est utile si vous avez des entités volumineuses et que vous avez seulement besoin de mettre à jour un petit nombre de propriétés dans une demande.
Notes
Les méthodes de remplacement et de fusion échouent si l’entité n’existe pas. Comme alternative, vous pouvez utiliser les méthodes InsertOrReplace et InsertOrMerge qui créent une entité si elle n’existe pas.
Utilisation des types d’entités hétérogènes
Le service de Table est un magasin de tables sans schéma , ce qui signifie qu’une seule table peut stocker des entités de plusieurs types pour améliorer la flexibilité de votre conception. L'exemple suivant présente une table qui stocke les entités de service et d'employé :
| PartitionKey | RowKey | Timestamp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Chaque entité doit toujours avoir les valeurs PartitionKey, RowKey et Timestamp, mais elle peut aussi avoir n’importe quel ensemble de propriétés. De plus, il n'y a rien pour indiquer le type d'une entité, sauf si vous choisissez de stocker ces informations quelque part. Il existe deux options pour identifier le type d'une entité :
- Ajout d’un préfixe de type d’entité à la RowKey (ou éventuellement à la PartitionKey). Par exemple, EMPLOYEE_000123 ou DEPARTMENT_SALES en tant que valeurs de RowKey.
- Utilisez une propriété distincte pour enregistrer le type d'entité comme indiqué dans le tableau ci-dessous.
| PartitionKey | RowKey | Timestamp | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
La première option, qui consiste à ajouter un préfixe de type d’entité à la RowKey, est utile au cas où deux entités de types différents se retrouvent avec la même valeur de clé. Il regroupe également les entités du même type dans la partition.
Les techniques présentées dans cette section sont particulièrement adaptées à la discussion Relations d’héritage plus haut dans ce guide, dans l’article Modélisation des relations.
Notes
Pensez à inclure un numéro de version dans la valeur de type d'entité pour permettre aux applications clientes de faire évoluer des objets POCO et de travailler avec différentes versions.
Le reste de cette section décrit certaines des fonctionnalités de la bibliothèque cliente Stockage Azure qui facilitent l'utilisation de plusieurs types d'entités dans la même table.
Récupération de types d'entités hétérogènes
Si vous utilisez la bibliothèque cliente Table, vous avez trois options pour travailler avec plusieurs types d’entité.
Si vous connaissez le type de l’entité stockée avec des valeurs RowKey et PartitionKey spécifiques, vous pouvez spécifier le type d’entité quand vous récupérez l’entité, comme indiqué dans les deux exemples précédents qui récupèrent des entités de type EmployeeEntity : Exécution d’une requête de pointage à l’aide de la bibliothèque cliente Stockage Azure et Récupération de plusieurs entités à l’aide de LINQ.
La deuxième option consiste à utiliser le type TableEntity (un conteneur de propriétés) plutôt qu’un type d’entité POCO concret (cette option peut également améliorer les performances, car il n’est pas nécessaire de sérialiser et désérialiser l’entité en types .NET). Le code C# suivant récupère plusieurs entités de types différents à partir de la table, mais renvoie toutes les entités en tant qu’instances de TableEntity. Il utilise ensuite la propriété EventType pour déterminer le type de chaque entité :
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Pour récupérer d’autres propriétés, vous devez utiliser la méthode GetString sur la propriété entity de la classe TableEntity.
Modification des types d'entités hétérogènes
Vous n'avez pas besoin de connaître le type d'une entité pour la supprimer et vous connaissez toujours le type d'une entité lorsque vous l'insérez. Toutefois, vous pouvez utiliser le type TableEntity pour mettre à jour une entité sans connaître son type et sans utiliser de classe d’entité POCO. L’exemple de code suivant récupère une entité unique et vérifie qu’elle dispose bien d’une propriété EmployeeCount avant de la mettre à jour.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Contrôle d’accès avec des signatures d’accès partagé
Vous pouvez utiliser des jetons de signature d’accès partagé (SAP) pour permettre aux applications clientes de modifier (et d’interroger) des entités de table sans inclure votre clé de compte de stockage dans votre code. En règle générale, il existe trois principaux avantages à l'utilisation de SAP dans votre application :
- Vous n'avez plus besoin de distribuer votre clé de compte de stockage vers une plateforme non sécurisée (par exemple un appareil mobile) pour permettre à ce périphérique d'accéder à des entités dans le service de Table et de les modifier.
- Vous pouvez décharger certaines tâches effectuées par les rôles web et de travail lors de la gestion de vos entités sur les périphériques clients tels que les ordinateurs et appareils mobiles des utilisateurs finaux.
- Vous pouvez affecter un ensemble d'autorisations contraintes et limitées dans le temps à un client (par exemple, pour autoriser l'accès en lecture seule à des ressources spécifiques).
Pour plus d’informations sur l’utilisation de jetons SAP avec le service de Table, consultez Utilisation des signatures d’accès partagé (SAP).
Toutefois, vous devez toujours générer les jetons SAP qui permettent à une application cliente d'accéder aux entités du service de Table : vous devez le faire dans un environnement qui dispose d'un accès sécurisé à vos clés de compte de stockage. En règle générale, vous utilisez un rôle web ou de travail pour générer les jetons SAP et les transmettre vers les applications clientes qui ont besoin d'accéder à vos entités. Comme il existe toujours une surcharge impliquée dans la génération et l'envoi de jetons SAP aux clients, vous devez envisager la meilleure méthode pour réduire cette surcharge, en particulier dans les scénarios à volumes élevés.
Il est possible de générer un jeton SAP qui accorde l'accès à un sous-ensemble d'entités dans une table. Par défaut, vous créez un jeton SAP pour une table entière, mais il est également possible d’indiquer que le jeton SAP accorde l’accès à une plage de valeurs de PartitionKey, ou de PartitionKey et de RowKey. Vous pouvez choisir de générer des jetons SAP pour des utilisateurs individuels de votre système, de sorte que chaque jeton SAP d’un utilisateur lui permet uniquement d’accéder à ses propres entités dans le service de Table.
Opérations asynchrones et parallèles
Si vous effectuez la diffusion de vos demandes sur plusieurs partitions, vous pouvez améliorer le débit et la réactivité du client en utilisant des requêtes asynchrones ou parallèles. Par exemple, vous pouvez avoir plusieurs instances de rôle de travail accédant à vos tables en parallèle. Vous pouvez avoir des rôles de travail individuels responsables d'ensembles particuliers de partitions ou simplement plusieurs instances de rôle de travail, chacune étant en mesure d'accéder à toutes les partitions d'une table.
Dans une instance cliente, vous pouvez améliorer le débit en exécutant des opérations de stockage en mode asynchrone. La bibliothèque cliente Stockage Azure facilite l'écriture de modifications et de requêtes asynchrones. Par exemple, vous pouvez commencer avec la méthode synchrone qui récupère toutes les entités dans une partition, comme illustré dans le code C# suivant :
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Vous pouvez facilement modifier ce code afin que la requête s'exécute de façon asynchrone, comme suit :
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Dans cet exemple asynchrone, vous pouvez voir les modifications suivantes par rapport à la version synchrone :
- La signature de méthode inclut désormais le modificateur async et renvoie une instance Task.
- Au lieu d’appeler la méthode Query pour récupérer les résultats, la méthode appelle maintenant la méthode QueryAsync et utilise le modificateur await pour récupérer les résultats de façon asynchrone.
L’application cliente peut appeler cette méthode plusieurs fois (avec des valeurs différentes pour le paramètre department ) et chaque requête s’exécute sur un thread distinct.
Vous pouvez également insérer, mettre à jour et supprimer des entités de façon asynchrone. L'exemple C# suivant indique une méthode simple et synchrone pour insérer ou remplacer une entité d'employé :
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Vous pouvez facilement modifier ce code pour que la mise à jour s'exécute de façon asynchrone, comme suit :
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
Dans cet exemple asynchrone, vous pouvez voir les modifications suivantes par rapport à la version synchrone :
- La signature de méthode inclut désormais le modificateur async et renvoie une instance Task.
- Au lieu d’appeler la méthode Execute pour mettre à jour l’entité, la méthode appelle maintenant la méthode ExecuteAsync et utilise le modificateur await pour récupérer les résultats de façon asynchrone.
L'application cliente peut appeler plusieurs méthodes asynchrones comme celle-ci, et chaque appel de méthode s'exécute sur un thread distinct.