Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Vous pouvez implémenter des modèles Machine Learning en tant que fonctions définies par l’utilisateur dans vos tâches Azure Stream Analytics pour effectuer le scoring et les prédictions en temps réel sur vos données d’entrée de streaming. Azure Machine Learning vous permet d’utiliser n’importe quel outil open source populaire, comme TensorFlow, scikit-learn ou PyTorch pour préparer, former et déployer des modèles.
Prérequis
Effectuez les étapes suivantes avant d’ajouter un modèle de Machine Learning en tant que fonction à votre tâche Stream Analytics :
Utilisez Azure Machine Learning pour déployer votre modèle en tant que service web.
Votre point de terminaison Machine Learning doit avoir un swagger associé qui aide Stream Analytics à comprendre le schéma d’entrée et de sortie. Vous pouvez utiliser cet exemple de définition de Swagger comme référence pour vous assurer de l’avoir correctement configuré.
Assurez-vous que votre service web accepte et retourne les données sérialisées JSON.
Déployez votre modèle sur Azure Kubernetes Service pour les déploiements de production à grande échelle. Si le service web ne peut pas gérer le nombre de requêtes provenant de votre tâche, les performances de votre tâche Stream Analytics sont dégradées, ce qui a une incidence sur la latence. Les modèles déployés sur Azure Container Instances sont pris en charge uniquement lorsque vous utilisez le portail Azure.
Ajouter un modèle Machine Learning à votre tâche
Vous pouvez ajouter des fonctions Azure Machine Learning à votre tâche Stream Analytics directement à partir du portail Azure ou depuis Visual Studio Code.
Portail Azure
Accédez à votre tâche Stream Analytics dans le portail Azure, puis sélectionnez Fonctions sous Topologie de la tâche. Ensuite, sélectionnez le Service Azure Machine Learning dans le menu déroulant + Ajouter.
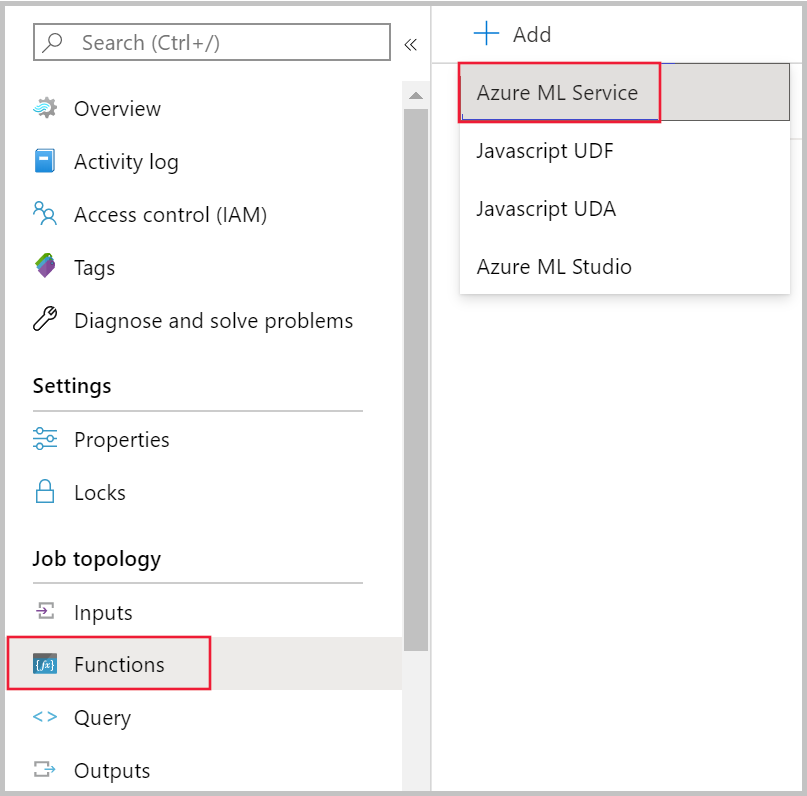
Renseignez le formulaire Fonction Azure Machine Learning Service avec les valeurs de propriété suivantes :
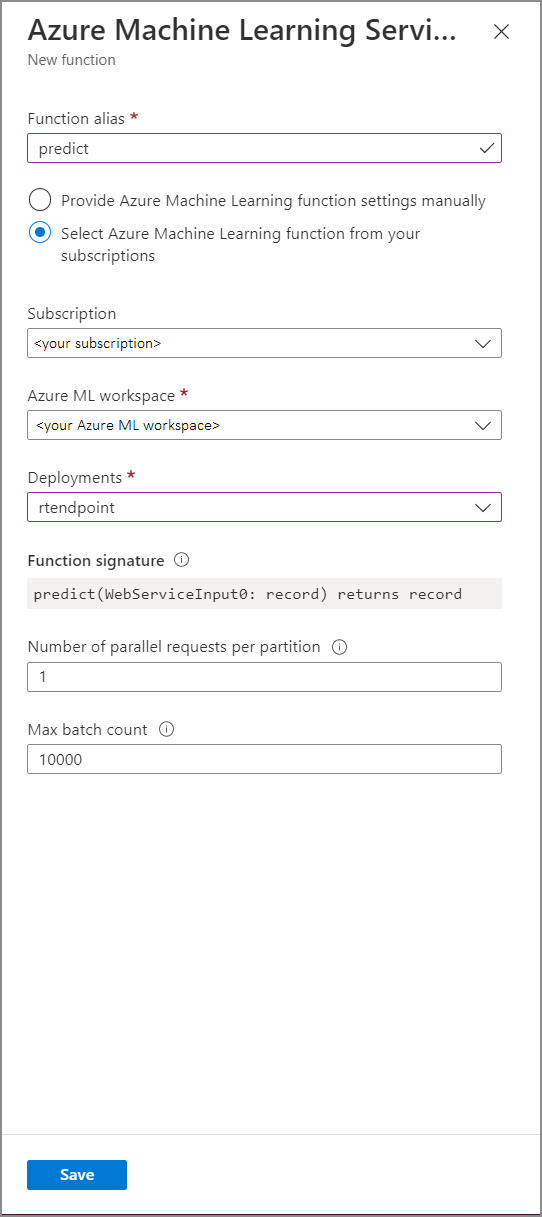
Le tableau suivant décrit chaque propriété des fonctions de service Azure Machine Learning dans Stream Analytics.
| Propriété | Description |
|---|---|
| Alias de fonction | Entrez un nom pour appeler la fonction dans votre requête. |
| Abonnement | Votre abonnement Azure. |
| Espace de travail Azure Machine Learning | L’espace de travail Azure Machine Learning que vous avez utilisé pour déployer votre modèle en tant que service web. |
| Point de terminaison | Service web hébergeant votre modèle. |
| Signature de fonction | La signature de votre service web déduite de la spécification de schéma de l’API. Si le chargement de votre signature échoue, vérifiez que vous avez fourni les exemples d’entrée et de sortie dans votre script de scoring pour générer automatiquement le schéma. |
| Nombre de requêtes parallèles par partition | Il s’agit d’une configuration avancée pour optimiser le débit à grande échelle. Ce nombre représente les requêtes simultanées envoyées à partir de chaque partition de votre tâche au service web. Les tâches avec six unités de diffusion en continu (SU) et moins ont une partition. Les tâches avec 12 SUs ont deux partitions, et celles avec 18 SUs ont trois partitions, et ainsi de suite. Par exemple, si votre tâche a deux partitions et que vous définissez ce paramètre sur quatre, il y aura huit requêtes simultanées de votre tâche à votre service web. |
| Nombre maximal de lots | Il s’agit d’une configuration avancée pour optimiser le débit à grande échelle. Ce nombre représente le nombre maximal d’événements regroupés en une seule requête envoyée à votre service web. |
Appel du point de terminaison de Machine Learning à partir de votre requête
Lorsque votre requête Stream Analytics appelle une FDU Azure Machine Learning, la tâche crée une demande sérialisée JSON auprès du service web. La requête est basée sur un schéma spécifique au modèle déduit par Stream Analytics à partir du swagger du point de terminaison.
Avertissement
Les points de terminaison Machine Learning ne sont pas appelés lorsque vous testez avec l’éditeur de requête du Portail Azure car le travail ne s’exécute pas. Pour tester l’appel du point de terminaison depuis le portail, le job Stream Analytics doit être en cours d'exécution.
La requête Stream Analytics suivante est un exemple d’appel d’une FDU Azure Machine Learning :
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Si vos données d’entrée envoyées à la ML UDF ne sont pas cohérentes avec le schéma attendu, le point de terminaison renvoie une réponse avec le code d’erreur 400, ce qui entraîne l’échec de votre travail Stream Analytics. Nous vous recommandons d’activer les journaux des ressources pour votre travail, ce qui vous permettra de déboguer et de résoudre facilement ces problèmes. Par conséquent, il est fortement recommandé de :
- Vérifier que l’entrée de votre fonction définie par l’utilisateur ML n’est pas null
- Validez le type de chaque champ qui sert d'entrée à votre ML UDF pour vous assurer qu'il correspond à ce que le point de terminaison attend.
Note
Les fonctions UDF de ML sont évaluées pour chaque ligne d’une étape de requête donnée, même lorsqu'elles sont appelées via une expression conditionnelle, par exemple CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END. Si nécessaire, utilisez la clause WITH pour créer des chemins divergents, en appelant l’UDF de ML uniquement lorsque cela est nécessaire, avant d’utiliser UNION pour fusionner à nouveau les chemins.
Passer plusieurs paramètres d’entrée à la FDU
Les exemples les plus courants d’entrée pour les modèles Machine Learning sont les tableaux numpy et les DataFrames. Vous pouvez créer un tableau à l’aide d’une FDU JavaScript et créer un DataFrame sérialisé en JSON à l’aide de la clause WITH.
Créer un tableau d’entrée
Vous pouvez créer une FDU JavaScript qui accepte un nombre N d’entrées et crée un tableau qui peut être utilisé comme entrée pour votre FDU Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Une fois que vous avez ajouté la fonction JavaScript définie par l’utilisateur à votre tâche, vous pouvez appeler votre fonction définie par l’utilisateur Azure Machine Learning à l’aide de la requête suivante :
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
L’extrait JSON ci-dessous est un exemple de requête :
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Créez un DataFrame avec Pandas ou PySpark.
Vous pouvez utiliser la clause WITH pour créer un DataFrame sérialisé JSON qui peut être transmis en tant qu’entrée à votre FDU Azure Machine Learning, comme indiqué ci-dessous.
La requête suivante crée un DataFrame en sélectionnant les champs nécessaires et utilise le DataFrame comme entrée pour la FDU Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Le code JSON suivant est un exemple de requête de la requête précédente :
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optimiser les performances pour les fonctions définies par l’utilisateur (FDU) Azure Machine Learning
Lorsque vous déployez votre modèle sur le service Azure Kubernetes, vous pouvez profiler votre modèle pour déterminer l’utilisation des ressources. Vous pouvez également activer Application Insights pour vos déploiements pour comprendre les taux de demande, les temps de réponse et les taux d’échec.
Si vous avez un scénario avec un débit d’événements élevé, vous devrez peut-être modifier les paramètres suivants dans Stream Analytics pour obtenir des performances optimales avec des latences de bout en bout faibles :
- Nombre maximal de lots.
- Nombre de demandes parallèles par partition.
Déterminer la taille de lot appropriée
Une fois que vous avez déployé votre service web, vous envoyez l’exemple de requête avec des tailles de lot variables, en commençant à 50 et en incrémentant ce nombre par centaines. Par exemple, 200, 500, 1000, 2000 et ainsi de suite. Vous remarquerez qu’après une certaine taille de lot, la latence de la réponse augmente. Le nombre de lots maximal pour votre tâche est le point après lequel la latence de la réponse augmente.
Déterminer le nombre de requêtes parallèles par partition
Pour une mise à l’échelle optimale, votre tâche Stream Analytics doit être en mesure d’envoyer plusieurs requêtes parallèles à votre service web et d’obtenir une réponse dans un délai de quelques millisecondes. La latence de la réponse du service web peut avoir un impact direct sur la latence et les performances de votre tâche Stream Analytics. Si l’appel de votre tâche au service web prend beaucoup de temps, vous verrez probablement une augmentation du délai en filigrane et vous pourrez également constater une augmentation du nombre d’événements d’entrée en retard.
Vous pouvez éviter une telle latence, en vous assurant que votre cluster Azure Kubernetes Service (AKS) a été configuré avec le bon nombre de nœuds et de réplicas. Il est essentiel que votre service web soit hautement disponible et renvoie des réponses réussies. Si votre tâche reçoit une erreur reproductible telle qu’une réponse de service indisponible (503), elle refera automatiquement une nouvelle tentative avec un backoff exponentiel. Si votre travail reçoit l’une de ces erreurs en tant que réponse du point de terminaison, le travail passe à l’état d’échec.
- Demande incorrecte (400)
- Conflit (409)
- Introuvable (404)
- Non autorisé (401)
Limites
Si vous utilisez un service de point de terminaison managé Azure ML, Stream Analytics peut actuellement accéder uniquement aux points de terminaison dont l’accès réseau public est activé. En savoir plus sur la page dédiée aux points de terminaison privés Azure ML.