Tutoriel : Vision avec Azure AI services
Azure AI Vision est un service Azure AI qui vous permet de traiter des images et de retourner des informations basées sur les fonctionnalités visuelles. Dans ce tutoriel, vous allez apprendre à utiliser Azure AI Vision pour analyser des images sur Azure Synapse Analytics.
Ce tutoriel montre comment utiliser l’analyse de texte avec SynapseML pour :
- Extraire des fonctionnalités visuelles du contenu de l’image
- Reconnaître les caractères des images (OCR)
- Analyser le contenu de l’image et générer une miniature
- Détecter et identifier le contenu spécifique à un domaine dans une image
- Générer des balises associées à une image
- Générer une description d'une image entière dans un langage lisible par l'homme
Analyser l’image
Extrait un ensemble complet de caractéristiques visuelles basées sur le contenu de l’image, comme les objets, les visages, le contenu pour adulte et des descriptions textuelles générées automatiquement.
Exemple d’entrée

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Azure AI Vision service. Analyze Image extracts infortmation from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Résultats attendus
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
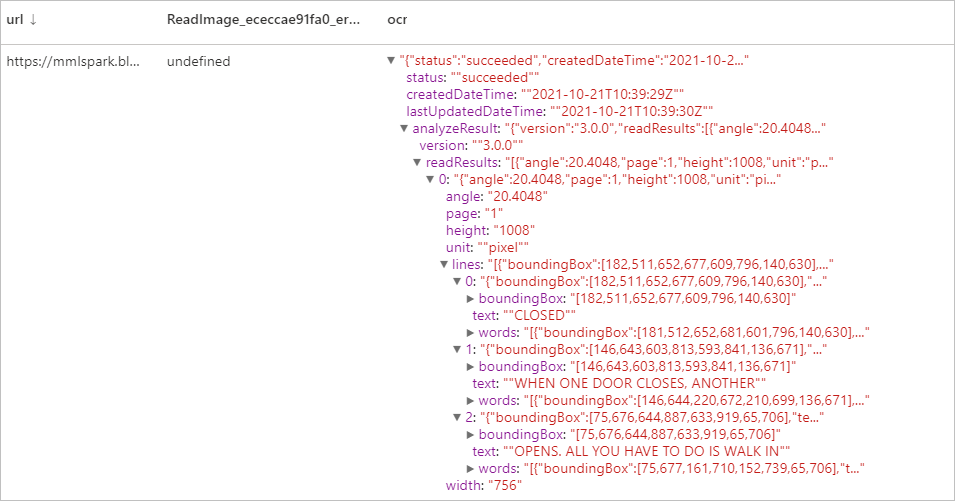
Reconnaissance optique de caractères
Extrayez du texte imprimé, du texte manuscrit, des chiffres et des symboles monétaires à partir d'images, telles que des photos de panneaux de signalisation et de produits, ainsi que de documents (factures, rapports financiers, articles, etc.). Elle est optimisée pour extraire le texte d’images à forte composante textuelle et de documents PDF multipages en langue mixte. Elle prend en charge la détection de texte imprimé et manuscrit dans la même image ou le même document.
Exemple d’entrée

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
Résultats attendus
Génération de miniatures
Analyser le contenu d’une image pour en générer une miniature. Le service Vision commence par générer une miniature de haute qualité, puis analyse les objets dans l’image pour déterminer la zone d’intérêt. Vision rogne ensuite l’image pour conserver uniquement la zone d’intérêt. La miniature générée peut être présentée à l’aide de proportions différentes de celles de l’image d’origine selon les besoins de chacun.
Exemple d’entrée

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Résultats attendus

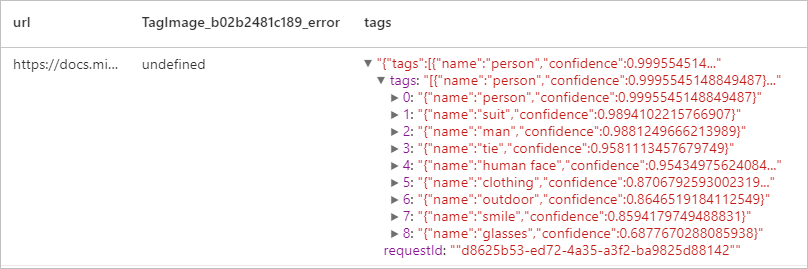
Image de balise
Cette opération génère une liste de mots, ou balises, qui sont pertinents pour le contenu de l’image fournie. Les balises sont retournées en fonction de milliers d’objets reconnaissables, d’êtres vivants, de scènes ou d’actions trouvés dans des images. Les étiquettes peuvent contenir des indices pour éviter toute ambiguïté ou fournir un contexte, par exemple l'étiquette "ascomycète" peut être accompagnée de l'indice "fungus".
Nous allons continuer à utiliser l’image de Satya comme exemple.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
Résultat attendu
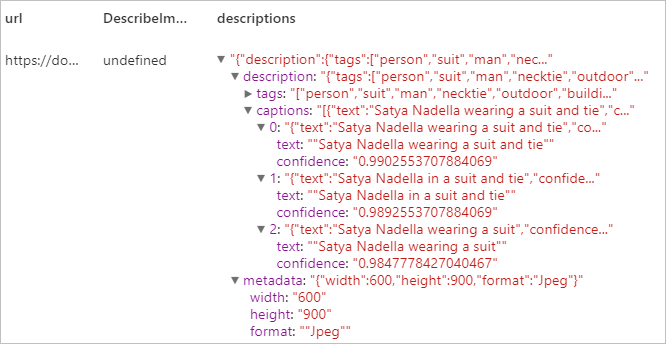
Décrire l’image
Générer une description de l’intégralité d’une image dans un langage lisible utilisant des phrases complètes. Les algorithmes du service Vision génèrent différentes descriptions selon les objets identifiés dans l’image. Chacune des descriptions est évaluée, et un score de confiance est généré. Une liste est ensuite renvoyée, classée du score de confiance plus élevé au plus bas.
Nous allons continuer à utiliser l’image de Satya comme exemple.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
Résultat attendu
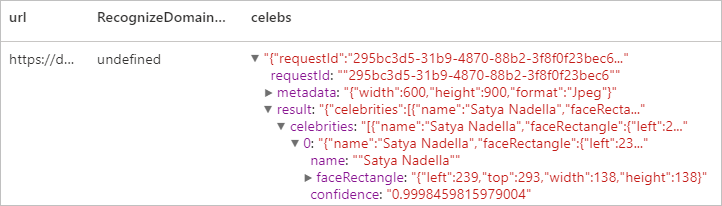
Reconnaître le contenu spécifique à un domaine.
Utiliser des modèles de domaine pour détecter et identifier le contenu spécifique à un domaine dans une image, notamment pour reconnaître des célébrités ou des éléments géographiques. Par exemple, si une image contient des célébrités, le service Vision peut utiliser un modèle de domaine pour célébrités afin de déterminer si les personnes détectées dans l’image correspondent à des célébrités connues.
Nous allons continuer à utiliser l’image de Satya comme exemple.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
Résultat attendu
Nettoyer les ressources
Pour vous assurer que l’instance Spark est arrêtée, mettez fin aux sessions connectées (notebooks). Le pool s’arrête quand la durée d’inactivité spécifiée dans le pool Apache Spark est atteinte. Vous pouvez également sélectionner Arrêter la session dans la barre d’état en haut à droite du notebook.
