Tutoriel : Intelligence documentaire avec Azure AI services
Azure AI Intelligence documentaire est un service Azure AI qui vous permet de générer des applications de traitement de données automatisées à l’aide de la technologie du Machine Learning. Dans ce didacticiel, vous allez apprendre à enrichir facilement vos données dans Azure Synapse Analytics. Vous allez utiliser Intelligence documentaire pour analyser vos formulaires et documents, extraire le texte et les données et retourner une sortie JSON structurée. Vous pouvez rapidement obtenir des résultats justes et adaptés à votre contenu en particulier, sans avoir besoin d’une intervention manuelle excessive ou de compétences approfondies en science des données.
Ce tutoriel montre comment utiliser Intelligence documentaire avec SynapseML pour :
- Extraire du texte et des informations de disposition à partir d’un document donné
- Détecter et extraire des données à partir de reçus
- Détecter et extraire des données à partir de cartes de visite
- Détecter et extraire des données à partir de factures
- Détecter et extraire des données à partir de documents d’identification
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Espace de travail Azure Synapse Analytics avec un compte de stockage Azure Data Lake Storage Gen2 configuré comme stockage par défaut. Vous devez être le contributeur aux données Blob de stockage du système de fichiers Data Lake Storage Gen2 que vous utilisez.
- Pool Spark dans votre espace de travail Azure Synapse Analytics. Pour plus d’informations, consultez Créer un pool Spark dans Azure Synapse.
- Les étapes de pré-configuration décrites dans le tutoriel Configurer Azure AI services dans Azure Synapse.
Bien démarrer
Ouvrez Synapse Studio et créez un nouveau notebook. Pour commencer, importez SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Configurer l’intelligence documentaire
Utilisez l’intelligence documentaire liée que vous avez configurée dans les étapes de préconfiguration.
ai_service_name = "<Your linked service for Document Intelligence>"
Analyser la disposition
Extraire des informations de texte et de disposition d’un document donné. Le document d’entrée doit être de l’un des types de contenus pris en charge : « application/pdf », « image/jpeg », « image/png » ou « image/tiff ».
Exemple d’entrée

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Résultats attendus
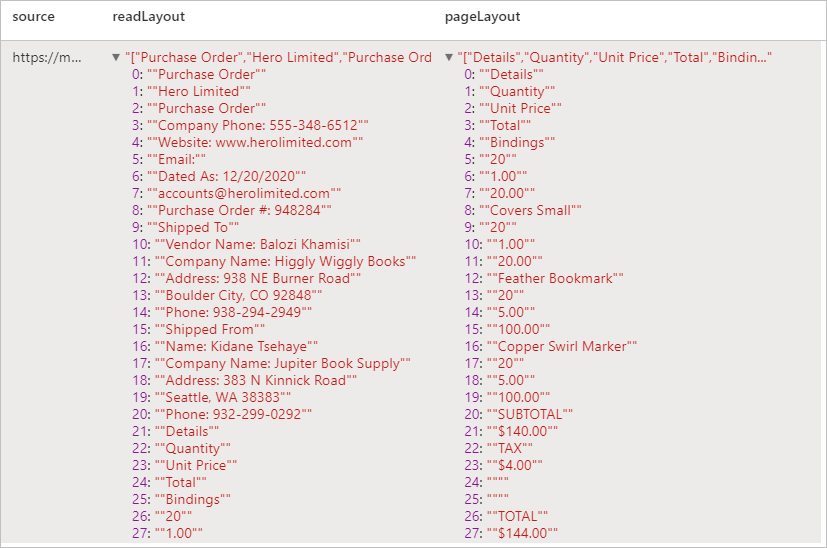
Analyser les reçus
Détecte et extrait des données à partir de reçus à l’aide de la reconnaissance optique de caractères (OCR) et de notre modèle de réception, ce qui vous permet d’extraire facilement des données structurées à partir de reçus, telles que le nom du commerçant, le numéro de téléphone du commerçant, la date de transaction, le total de la transaction, etc.
Exemple d’entrée

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Résultats attendus
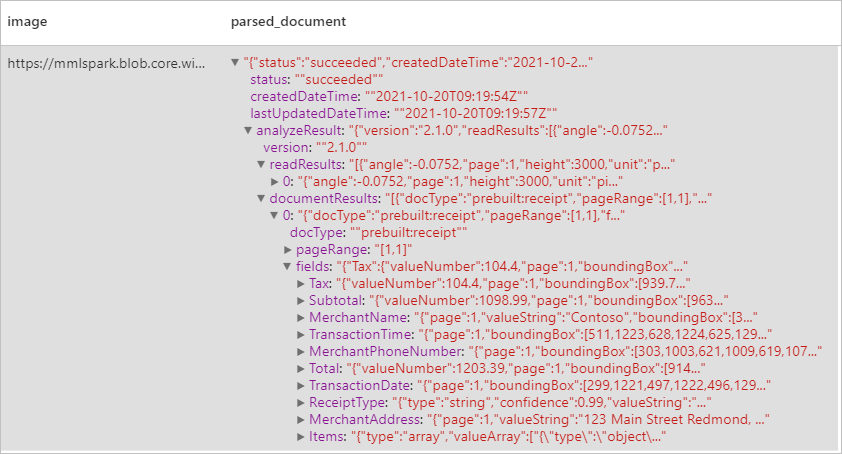
Analyser les cartes de visite
Détecte et extrait des données à partir de cartes de visite à l’aide de la reconnaissance optique de caractères (OCR) et notre modèle de carte de visite, ce qui vous permet d’extraire facilement des données structurées à partir de cartes de visite, telles que des noms de contacts, des noms d’entreprise, des numéros de téléphone, des adresses e-mail, etc.
Exemple d’entrée

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Résultats attendus
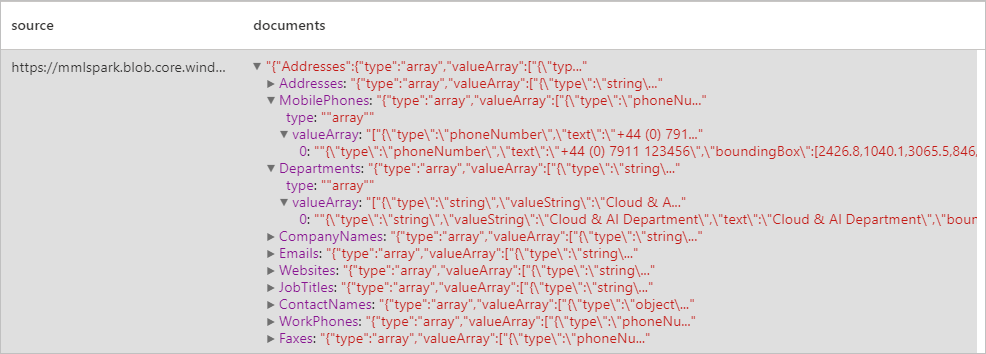
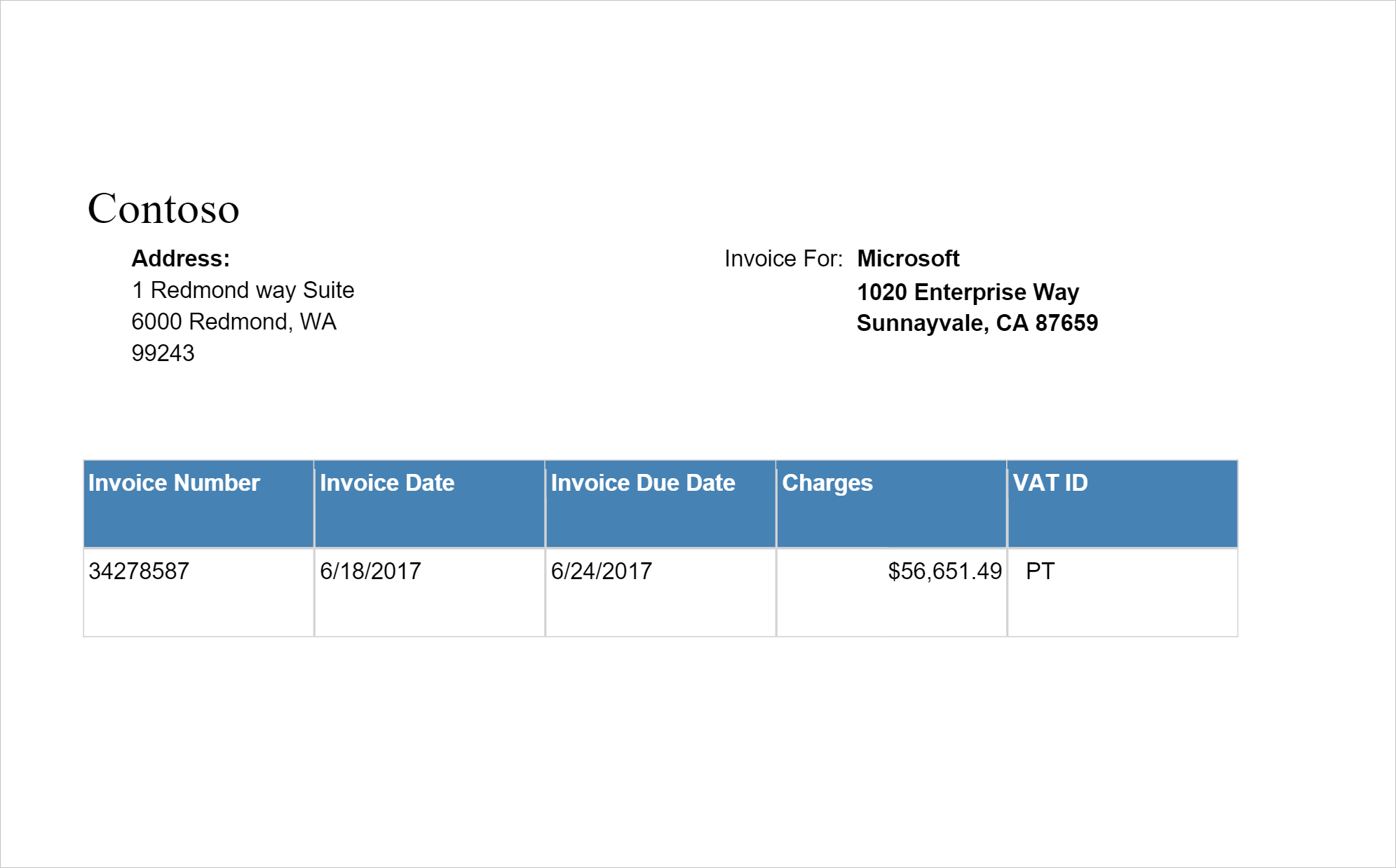
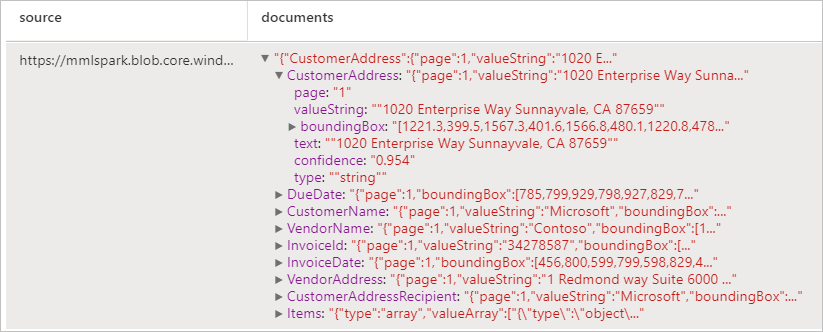
Analyser les factures
Détecte et extrait des données à partir de factures à l’aide de la reconnaissance optique de caractères (OCR) et de nos modèles de Deep Learning comprenant des factures, ce qui vous permet d’extraire facilement des données structurées à partir de factures, telles que le client, le fournisseur, l’ID de facture, la date d’échéance de la facture, le total, le montant dû, le montant des taxes, l’adresse de facturation, les éléments de ligne, etc.
Exemple d’entrée
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Résultats attendus
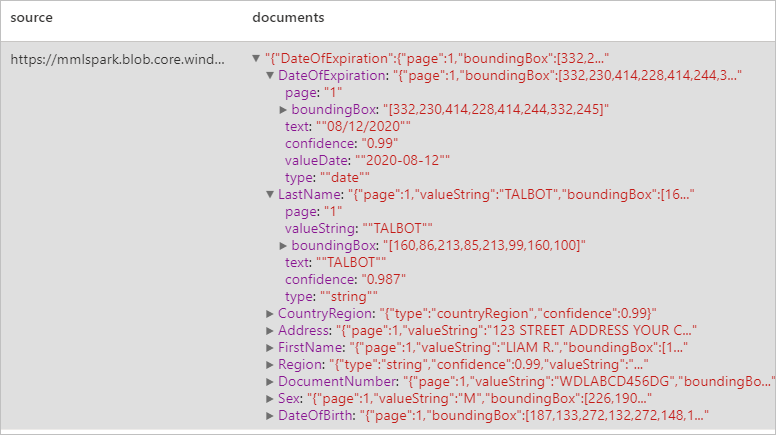
Analyser des documents d’identité
Détecte et extrait des données à partir de documents d’identification à l’aide de la reconnaissance optique de caractères (OCR) et de notre modèle de document d’identité, ce qui vous permet d’extraire facilement des données structurées à partir de documents d’identité, telles que le prénom, le nom, la date de naissance, le numéro de document, etc.
Exemple d’entrée

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Résultats attendus
Nettoyer les ressources
Pour vous assurer que l’instance Spark est arrêtée, mettez fin aux sessions connectées (notebooks). Le pool s’arrête quand la durée d’inactivité spécifiée dans le pool Apache Spark est atteinte. Vous pouvez également sélectionner Arrêter la session dans la barre d’état en haut à droite du notebook.
