Sécurité, accès et opérations pour les migrations Netezza
Cet article est la partie trois d’une série de sept parties qui fournit des conseils sur la migration de Netezza vers Azure Synapse Analytics. Cet article présente les bonnes pratiques pour les opérations d’accès à la sécurité.
Considérations relatives à la sécurité
Cet article décrit les méthodes de connexion pour les environnements Netezza hérités existants et comment ils peuvent être migrés vers Azure Synapse Analytics avec un risque et un impact minimaux sur l’utilisateur.
Cet article part du principe qu’il est nécessaire de migrer les méthodes de connexion existantes et la structure utilisateur/rôle/autorisation en l’état. Sinon, utilisez le portail Azure pour créer et gérer un nouveau régime de sécurité.
Pour plus d’informations sur les options de sécurité Azure Synapse, consultez le livre blanc sur la sécurité.
Connexion et authentification
Conseil
L’authentification dans Netezza et Azure Synapse peut être « dans la base de données » ou via des méthodes externes.
Options d’autorisation Netezza
Le système IBM Netezza offre plusieurs méthodes d’authentification pour les utilisateurs de base de données Netezza :
Authentification locale : les administrateurs Netezza définissent les utilisateurs de base de données et leurs mots de passe à l’aide de la
CREATE USERcommande ou via des interfaces administratives Netezza. Dans l’authentification locale, utilisez le système Netezza pour gérer les comptes et les mots de passe de base de données, et pour ajouter et supprimer des utilisateurs de base de données du système. Cette méthode est la méthode d’authentification par défaut.Authentification LDAP : utilisez un serveur de noms LDAP pour authentifier les utilisateurs de base de données, et gérer les mots de passe, les activations de compte de base de données et les désactivations. Le système Netezza utilise un module d’authentification enfichable (PAM) pour authentifier les utilisateurs sur le serveur de noms LDAP. Microsoft Active Directory est conforme au protocole LDAP. Il peut donc être traité comme un serveur LDAP à des fins d’authentification LDAP.
Authentification Kerberos : utilisez un serveur de distribution Kerberos pour authentifier les utilisateurs de base de données, et gérer les mots de passe, les activations de compte de base de données et les désactivations.
L’authentification est un paramètre à l’échelle du système. Les utilisateurs doivent être authentifiés localement ou authentifiés à l’aide de la méthode LDAP ou Kerberos. Si vous choisissez l’authentification LDAP ou Kerberos, créez des utilisateurs avec une authentification locale par utilisateur. LDAP et Kerberos ne peuvent pas être utilisés en même temps pour authentifier les utilisateurs. L’hôte Netezza prend en charge l’authentification LDAP ou Kerberos pour les connexions utilisateur de base de données uniquement, et non pour les connexions du système d’exploitation sur l’hôte.
Options d’autorisation Azure Synapse
Azure Synapse prend en charge deux options de base pour la connexion et l’autorisation :
Authentification SQL : l’authentification SQL se fait via une connexion de base de données qui inclut un identificateur de base de données, un ID utilisateur et un mot de passe, ainsi que d’autres paramètres facultatifs. Cela équivaut fonctionnellement aux connexions locales Netezza.
Authentification Microsoft Entra : avec l’authentification Microsoft Entra, vous pouvez gérer de manière centralisée les identités des utilisateurs de base de données et d’autres services Microsoft dans un emplacement central. La gestion centralisée des ID fournit un emplacement unique pour gérer les utilisateurs Azure Synapse et simplifie la gestion des autorisations. Microsoft Entra ID peut également prendre en charge les connexions aux services LDAP et Kerberos, par exemple, Microsoft Entra ID peut être utilisé pour se connecter à des annuaires LDAP existants s’ils doivent rester en place après la migration de la base de données.
Utilisateurs, rôles et autorisations
Vue d’ensemble
Conseil
Une planification générale est essentielle pour un projet de migration réussi.
Netezza et Azure Synapse implémentent le contrôle d’accès à la base de données via une combinaison d’utilisateurs, de rôles (groupes dans Netezza) et d’autorisations. Les deux utilisent des instructions SQL CREATE USER et CREATE ROLE/GROUP standard pour définir des utilisateurs et des rôles, et des instructions GRANT et REVOKE pour attribuer ou supprimer des autorisations pour ces utilisateurs et/ou rôles.
Conseil
L’automatisation des processus de migration est recommandée pour réduire le temps écoulé et l’étendue des erreurs.
Conceptuellement, les deux bases de données sont similaires et il peut être possible d’automatiser la migration des ID d’utilisateur, des groupes et des autorisations existants à un certain degré. Migrez ces données en extrayant les informations existantes de l’utilisateur et du groupe hérités des tables de catalogue système Netezza et en générant des instructions équivalentes CREATE USER et CREATE ROLE correspondantes à exécuter dans Azure Synapse pour recréer la même hiérarchie utilisateur/rôle.
Après l’extraction des données, utilisez des tables de catalogue système Netezza pour générer des instructions GRANT équivalentes pour attribuer des autorisations (où il existe un équivalent). Le diagramme suivant montre comment utiliser les métadonnées existantes pour générer les SQL nécessaires.
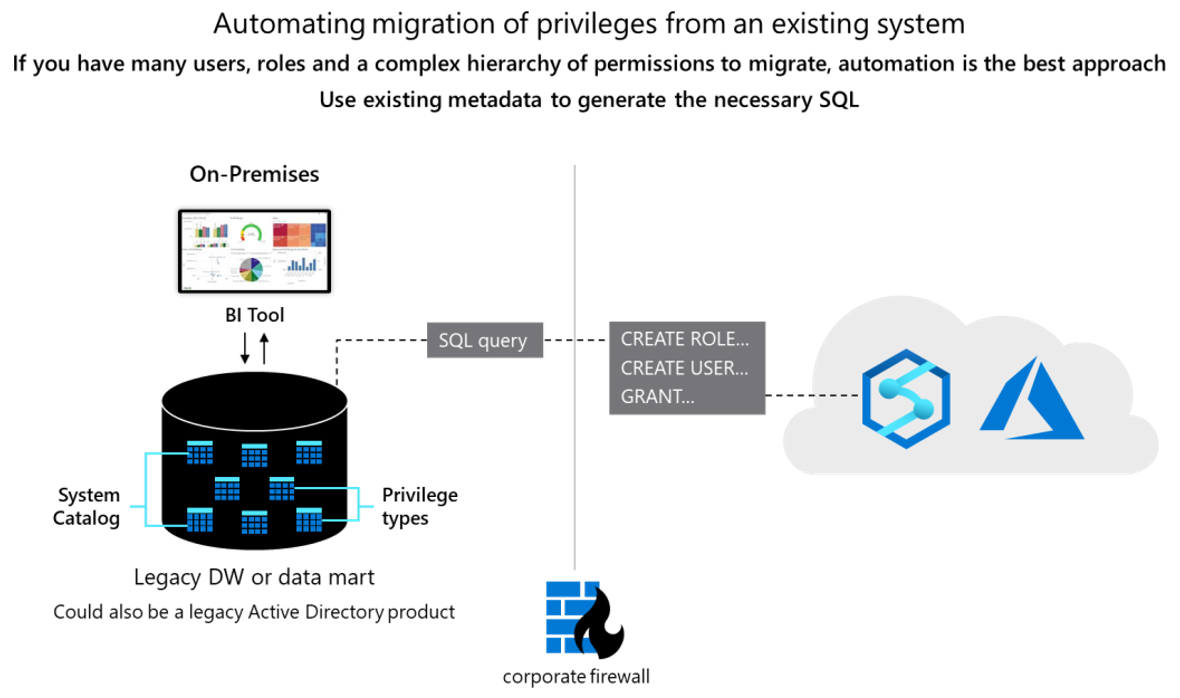
Consultez les sections suivantes pour plus de détails.
Utilisateurs et rôles
Conseil
La migration d’un entrepôt de données nécessite plus que de simples tables, vues et instructions SQL.
Les informations sur les utilisateurs et les groupes actuels dans un système Netezza sont conservées dans les affichages de catalogue système _v_users et _v_groupusers. Utilisez l’utilitaire nzsql ou les outils tels que Netezza Performance, NzAdmin ou des scripts de l’utilitaire Netezza pour répertorier les privilèges utilisateur. Par exemple, utilisez les commandes dpu et dpgu dans nzsql pour afficher des utilisateurs ou des groupes avec leurs autorisations.
Utilisez ou modifiez les scripts utilitaires nz_get_users et nz_get_user_groups pour récupérer les mêmes informations au format requis.
Demander directement les vues de catalogue du système (si l’utilisateur dispose de l’accès SELECT à ces vues) pour obtenir des listes actuelles d’utilisateurs et de rôles définis dans le système. Consultez des exemples pour répertorier les utilisateurs, les groupes ou les utilisateurs et leurs groupes associés :
-- List of users
SELECT USERNAME FROM _V_USER;
--List of groups
SELECT DISTINCT(GROUPNAME) FROM _V_USERGROUPS;
--List of users and their associated groups
SELECT USERNAME, GROUPNAME FROM _V_GROUPUSERS;
Modifiez l’exemple d’instruction SELECT pour produire un jeu de résultats qui est une série et d’instructions CREATE USER et CREATE GROUP en incluant le texte approprié en tant que littéral dans l’instruction SELECT.
Il n’existe aucun moyen de récupérer les mots de passe existants. Vous devez donc implémenter un schéma pour allouer de nouveaux mots de passe initiaux sur Azure Synapse.
Autorisations
Conseil
Il existe des autorisations Azure Synapse équivalentes pour les opérations de base de données standard telles que DML et DDL.
Dans un système Netezza, la table système _t_usrobj_priv contient les droits d’accès pour les utilisateurs et les rôles. Interrogez ces tables (si l’utilisateur dispose de l’accès SELECT à ces tables) pour obtenir les listes actuelles de droits d’accès définis dans le système.
Dans Netezza, les autorisations individuelles sont représentées en tant que bits individuels au sein des privilèges de champ ou g_privileges. Voir l’exemple d’instruction SQL dans les autorisations de groupe d’utilisateurs
La façon la plus simple d’obtenir un script DDL qui contient les commandes GRANT pour répliquer les privilèges actuels pour les utilisateurs et les groupes consiste à utiliser les scripts d’utilitaire Netezza appropriés :
--List of group privileges
nz_ddl_grant_group -usrobj dbname > output_file_dbname;
--List of user privileges
nz_ddl_grant_user -usrobj dbname > output_file_dbname;
Le fichier de sortie peut être modifié pour produire un script qui est une série d’instructions GRANT pour Azure Synapse.
Netezza prend en charge deux classes de droits d’accès, Administration et Objet. Consultez les tableaux suivants pour obtenir la liste des droits d’accès Netezza et leur équivalent dans Azure Synapse.
| Privilège Administrateur | Description | Équivalent Azure Synapse |
|---|---|---|
| Sauvegarde | Permet à l’utilisateur de créer des sauvegardes. L’utilisateur peut exécuter des sauvegardes. L’utilisateur peut exécuter la commande nzbackup. |
1 |
| [Créer] un agrégat | Permet à l’utilisateur de créer des agrégats définis par l’utilisateur (UDA). L’autorisation d’exploiter des UDA existants est contrôlée par des privilèges d’objet. | CREATE FUNCTION 3 |
| [Créer] une base de données | Permet à l’utilisateur de créer des bases de données. L’autorisation d’exploiter des bases de données existantes est contrôlée par des privilèges d’objet. | CREATE DATABASE |
| [Créer] une table externe | Permet à l’utilisateur de créer des tables externes. L’autorisation d’exploiter des tables existantes est contrôlée par des privilèges d’objet. | CREATE TABLE |
| Fonction [Créer] | Permet à l’utilisateur de créer des fonctions définies par l’utilisateur (UDF). L’autorisation d’exploiter des UDF existants est contrôlée par des privilèges d’objet. | CREATE FUNCTION |
| Groupe [Créer] | Permet à l’utilisateur de créer des groupes. L’autorisation d’exploiter des groupes existants est contrôlée par des privilèges d’objet. | CREATE ROLE |
| Index [Créer] | Utilisation réservée au système. Les utilisateurs ne peuvent pas créer d’index. | CREATE INDEX |
| Bibliothèque [Créer] | Permet à l’utilisateur de créer des bibliothèques partagées. L’autorisation d’exploiter des bibliothèques partagées existantes est contrôlée par des privilèges d’objet. | 1 |
| Vues matérialisées [Créer] | Permet à l’utilisateur de créer des vues matérialisées. | CREATE VIEW |
| Procédure [Créer] | Permet à l’utilisateur de créer des procédures stockées. L’autorisation d’exploiter des procédures stockées existantes est contrôlée par des privilèges d’objet. | CREATE PROCEDURE |
| Schéma [Créer] | Permet à l’utilisateur de créer des schémas. L’autorisation d’exploiter des schémas existants est contrôlée par des privilèges d’objet. | CREATE SCHEMA |
| Séquence [Créer] | Permet à l’utilisateur de créer des séquences de bases de données. | 1 |
| Synonyme [Créer] | Permet à l’utilisateur de créer des synonymes. | CREATE SYNONYM |
| Table [Créer] | Permet à l’utilisateur de créer des tables. L’autorisation d’exploiter des tables existantes est contrôlée par des privilèges d’objet. | CREATE TABLE |
| Table temporaire [Créer] | Permet à l’utilisateur de créer des tables temporaires. L’autorisation d’exploiter des tables existantes est contrôlée par des privilèges d’objet. | CREATE TABLE |
| Utilisateur [Créer] | Permet à l’utilisateur de créer des utilisateurs. L’autorisation d’exploiter des utilisateurs existants est contrôlée par des privilèges d’objet. | CREATE USER |
| Vue [Créer] | Permet à l’utilisateur de créer des vues. L’autorisation d’exploiter des vues existantes est contrôlée par des privilèges d’objet. | CREATE VIEW |
| [Gérer le matériel | Permet à l’utilisateur d’effectuer les opérations matérielles suivantes : afficher l’état du matériel, gérer les SPU, gérer la topologie et la mise en miroir, et exécuter des tests de diagnostic. L’utilisateur peut exécuter ces commandes : nzhw et nzds. | 4 |
| [Gérer la sécurité | Permet à l’utilisateur d’exécuter des commandes et des opérations liées aux options de sécurité avancées suivantes, telles que : la gestion et la configuration des bases de données d’historique, la gestion des objets de sécurité multiniveaux et la spécification de la sécurité pour les utilisateurs et les groupes, la gestion des magasins de clés de base de données, des clés et des magasins de clés pour la signature numérique des données d’audit. | 4 |
| [Gérer le système | Permet à l’utilisateur d’effectuer les opérations de gestion suivantes : démarrer/arrêter/suspendre/reprendre le système, abandonner les sessions, afficher la carte de distribution, les statistiques système et les journaux. L’utilisateur peut utiliser ces commandes : nzsystem, nzstate, nzstats et nzsession. | 4 |
| Restaurer | Permet à l’utilisateur de restaurer le système. L’utilisateur peut exécuter la commande nzrestore. | 2 |
| Illimité | Permet à l’utilisateur de créer ou de modifier une fonction définie par l’utilisateur ou un agrégat pour s’exécuter en mode illimité. | 1 |
| Abandon des privilèges d’objet | Description | Équivalent Azure Synapse |
|---|---|---|
| Abandon | Permet à l’utilisateur d’abandonner les sessions. S’applique aux groupes et aux utilisateurs. | KILL DATABASE CONNECTION |
| Alter | Permet à l’utilisateur de modifier les attributs d’objet. S’applique à tous les objets. | ALTER |
| Supprimer | Permet à l’utilisateur de supprimer des lignes de table. S’applique uniquement aux tables. | Suppression |
| Supprimer | Permet à l’utilisateur de supprimer des objets. S’applique à tous les types d’objets. | DROP |
| Execute | Permet à l’utilisateur d’exécuter des fonctions définies par l’utilisateur, des agrégats définis par l’utilisateur ou des procédures stockées. | Exécutez |
| GenStats | Permet à l’utilisateur de générer des statistiques sur des tables ou des bases de données. L’utilisateur peut exécuter la commande GENERATE STATISTICS. | 2 |
| Nettoyer | Permet à l’utilisateur de récupérer de l’espace disque pour les lignes supprimées ou obsolètes, et de réorganiser une table par les clés d’organisation ou de migrer des données pour les tables qui ont plusieurs versions stockées. | 2 |
| Insérer | Permet à l’utilisateur d’insérer des lignes dans une table. S’applique uniquement aux tables. | INSERT |
| List | Permet à l’utilisateur d’afficher un nom d’objet, dans une liste ou d’une autre manière. S’applique à tous les objets. | Liste |
| Sélectionnez | Permet à l’utilisateur de sélectionner (ou interroger) des lignes dans une table. S’applique aux tables et aux vues. | SELECT |
| Tronquer | Permet à l’utilisateur de supprimer toutes les lignes d’une table. S’applique uniquement aux tables. | TRUNCATE |
| Update | Permet à l’utilisateur de modifier les lignes de table. S’applique uniquement aux tables. | UPDATE |
Notes de la table :
Il n’y a pas d’équivalent direct à cette fonction dans Azure Synapse.
Ces fonctions Netezza sont gérées automatiquement dans Azure Synapse.
La fonctionnalité Azure Synapse
CREATE FUNCTIONincorpore la fonctionnalité d’agrégation Netezza.Ces fonctionnalités sont gérées automatiquement par le système ou via le portail Azure dans Azure Synapse. Consultez la section suivante sur les considérations opérationnelles.
Reportez-vous aux autorisations de sécurité Azure Synapse Analytics.
Considérations opérationnelles
Conseil
Les tâches opérationnelles sont nécessaires pour assurer l’efficacité de tout entrepôt de données.
Cette section explique comment implémenter des tâches opérationnelles Netezza classiques dans Azure Synapse avec un risque et un impact minimal sur les utilisateurs.
Comme pour tous les produits de l’entrepôt de données, une fois en production, il existe des tâches de gestion en cours qui sont nécessaires pour maintenir l’exécution efficace du système et fournir des données pour la surveillance et l’audit. L’utilisation des ressources et la planification de la capacité pour une croissance future se situent également dans cette catégorie, comme la sauvegarde/restauration des données.
Les tâches d’administration Netezza appartiennent généralement à deux catégories :
Administration du système, qui gère le matériel, les paramètres de configuration, l’état du système, l’accès, l’espace disque, l’utilisation, les mises à niveau et d’autres tâches.
Administration de base de données, qui gère les bases de données utilisateur et leur contenu, le chargement des données, la sauvegarde des données, la restauration des données et le contrôle de l’accès aux données et les autorisations.
IBM Netezza offre plusieurs méthodes ou interfaces que vous pouvez utiliser pour effectuer les différentes tâches de gestion du système et de la base de données :
Les commandes Netezza (commandes
nz*) sont installées dans le répertoire/nz/kit/binsur l’hôte Netezza. Pour la plupart des commandesnz*, vous devez être en mesure de vous connecter au système Netezza pour accéder et exécuter ces commandes. Dans la plupart des cas, les utilisateurs se connectent en tant que compte d’utilisateurnzpar défaut, mais vous pouvez créer d’autres comptes d’utilisateur Linux sur votre système. Certaines commandes vous obligent à spécifier un compte d’utilisateur, un mot de passe et une base de données de base de données pour vous assurer que vous êtes autorisé à effectuer la tâche.Les kits clients CLI Netezza empaquettent un sous-ensemble des commandes
nz*qui peuvent être exécutées à partir de Windows et de systèmes clients UNIX. Les commandes clientes peuvent également vous obliger à spécifier un compte d’utilisateur, un mot de passe et une base de données de base de données pour vous assurer que vous disposez des autorisations d’administration et d’objet de base de données pour effectuer la tâche.Les commandes SQL prennent en charge les tâches d’administration et les requêtes au sein d’une session de base de données SQL. Vous pouvez exécuter les commandes SQL à partir de l’interpréteur de commandes Netezza nzsql ou via des API SQL telles qu’ODBC, JDBC et le fournisseur OLE DB. Vous devez disposer d’un compte d’utilisateur de base de données pour exécuter les commandes SQL avec les autorisations appropriées pour les requêtes et les tâches que vous effectuez.
L’outil NzAdmin est une interface Netezza qui s’exécute sur les stations de travail clientes Windows pour gérer les systèmes Netezza.
Bien que les tâches conceptuelles de gestion et d’exploitation pour différents entrepôts de données soient similaires, les implémentations individuelles peuvent différer. En général, les produits modernes basés sur le cloud tels qu’Azure Synapse ont tendance à incorporer une approche plus automatisée et « gérée par le système » (par opposition à une approche plus « manuelle » dans les entrepôts de données hérités tels que Netezza).
Les sections suivantes comparent les options Netezza et Azure Synapse pour différentes tâches opérationnelles.
Tâches de nettoyage
Conseil
Les tâches de nettoyage permettent à un entrepôt de production de fonctionner efficacement et d’optimiser l’utilisation des ressources telles que le stockage.
Dans la plupart des environnements d’entrepôt de données hérités, les tâches régulières de « nettoyage » sont fastidieuses. Récupérez de l’espace de stockage sur disque en supprimant les anciennes versions des lignes mises à jour ou supprimées ou en réorganisant des données, des fichiers journaux ou des blocs d’index pour une efficacité (GROOM et VACUUM dans Netezza). La collecte des statistiques est également une tâche potentiellement fastidieuse, nécessaire après l’ingestion de données en bloc pour fournir à l’optimiseur de requête des données à jour sur lesquelles baser les plans d’exécution des requêtes.
Netezza recommande de collecter des statistiques comme suit :
Collectez des statistiques sur les tables non renseignées pour configurer l’histogramme d’intervalle utilisé dans le traitement interne. Cette collection initiale accélère les collections de statistiques suivantes. Veillez à récoltez les statistiques une fois les données ajoutées.
Collectez les statistiques de phase de prototype pour les tables nouvellement remplies.
Collectez les statistiques de phase de production, après un pourcentage significatif de modifications de la table ou de la partition (environ 10 % de lignes). Pour les volumes élevés de valeurs non uniques, telles que les dates ou les horodatages, il peut être avantageux de recollecter à 7 %.
Collectez les statistiques de phase de production une fois que vous avez créé des utilisateurs et appliqué des charges de requête réelles à la base de données (jusqu’à environ trois mois d’interrogation).
Collectez des statistiques au cours des premières semaines après une mise à niveau ou une migration pendant des périodes d’utilisation faible du processeur.
La base de données Netezza contient de nombreuses tables de journaux dans le dictionnaire de données qui accumulent des données, automatiquement ou après l’activation de certaines fonctionnalités. Étant donné que les données de journal augmentent au fil du temps, videz les informations plus anciennes pour éviter d’utiliser de l’espace permanent. Il existe des options permettant d’automatiser la maintenance de ces journaux disponibles.
Conseil
Automatisez et surveillez les tâches de nettoyage dans Azure.
Azure Synapse a la possibilité de créer automatiquement des statistiques afin qu’elles puissent être utilisées en fonction des besoins. Effectuez une défragmentation manuelle des index et des blocs de données, sur une base planifiée ou automatiquement. L’utilisation des fonctionnalités Azure intégrées natives peut réduire l’effort requis dans un exercice de migration.
Supervision et audit
Conseil
Le Portail de performances Netezza est la méthode recommandée de surveillance et de journalisation pour les systèmes Netezza.
Netezza fournit le portail de performances Netezza pour surveiller différents aspects d’un ou plusieurs systèmes Netezza, notamment l’activité, les performances, la mise en file d’attente et l’utilisation des ressources. Le Portail de performances Netezza est une interface graphique interactive qui permet aux utilisateurs d’explorer les détails de bas niveau pour n’importe quel graphique.
Conseil
Le portail Azure fournit une interface utilisateur pour gérer les tâches de monitoring et d’audit pour l’ensemble des données et processus Azure.
De même, Azure Synapse fournit une expérience de supervision enrichie dans le Portail Azure pour fournir des insights à la charge de travail de votre entrepôt de données. Le portail Azure est l’outil recommandé pour superviser votre entrepôt de données car il offre des périodes de conservation configurables, des alertes, des suggestions, ainsi que des graphiques et des tableaux de bord personnalisables pour les métriques et les journaux d’activité.
Le portail permet également une intégration à d’autres services de monitoring Azure, comme OMS (Operations Management Suite) et Azure Monitor (journaux), pour fournir une expérience de monitoring globale non seulement pour l’entrepôt de données, mais également pour l’ensemble de la plateforme d’analytique Azure afin de bénéficier d’une expérience de monitoring intégrée.
Conseil
Les métriques de bas niveau et à l’échelle du système sont automatiquement enregistrées dans Azure Synapse.
Les statistiques d’utilisation des ressources pour Azure Synapse sont automatiquement enregistrées dans le système. Les métriques de chaque requête incluent des statistiques d’utilisation pour le processeur, la mémoire, le cache, les E/S et l’espace de travail temporaire, ainsi que des informations de connectivité telles que les tentatives de connexion ayant échoué.
Azure Synapse fournit un ensemble de vues de gestion dynamique (DMV). Ces vues sont utiles quand vous dépannez et identifiez activement les goulots d’étranglement des performances de votre charge de travail.
Pour plus d’informations, consultez les options d’opérations et de gestion d’Azure Synapse.
Haute disponibilité et récupération d’urgence
Les appareils Netezza sont des systèmes redondants, tolérants aux pannes et il existe diverses options dans un système Netezza pour permettre la haute disponibilité et la récupération d’urgence.
L’ajout des Services de réplication IBM Netezza pour la récupération d’urgence améliore la tolérance de panne en étendant la redondance sur les réseaux locaux et étendus.
Les Services de réplication IBM Netezza protègent contre la perte de données en synchronisant les données sur un système principal (le nœud principal) avec des données sur un ou plusieurs nœuds cibles (subordonnés). Ces nœuds constituent un jeu de réplication.
High-Availability Linux (également appelé Linux-HA) fournit les fonctionnalités de basculement d’un hôte Netezza principal ou actif vers un hôte Netezza secondaire ou de secours. Le démon de gestion de cluster principal dans la solution Linux-HA est appelé Pulsation. Pulsation surveille les hôtes et gère les contrôles de communication et d’état des services.
Chaque service est une ressource.
Netezza regroupe les services spécifiques à Netezza dans le groupe de ressources nps. Lorsque Pulsation détecte des problèmes qui impliquent une condition d’échec de l’hôte ou une perte de service pour les utilisateurs Netezza, Pulsation peut lancer un basculement vers l’hôte de secours.
DRBD (Distributed Replicated Block Device) est un pilote de périphérique de bloc qui reflète le contenu des périphériques de bloc (disques durs, partitions et volumes logiques) entre les hôtes. Netezza utilise la réplication DRBD uniquement sur les partitions /nz et /export/home . À mesure que de nouvelles données sont écrites dans la partition /nz et la partition /export/home sur l’hôte principal, le logiciel DRBD apporte automatiquement les mêmes modifications à la partition /nz et /export/home de l’hôte de secours.
Conseil
Azure Synapse crée automatiquement des instantanés pour garantir des temps de récupération rapides.
Azure Synapse utilise des captures instantanées de base de données pour fournir une haute disponibilité de l’entrepôt. Une capture instantanée d’entrepôt de données crée un point de restauration qui peut être utilisé pour récupérer ou copier un entrepôt de données dans un état antérieur. Comme Azure Synapse est un système distribué, une capture instantanée d’entrepôt de données est constituée de nombreux fichiers qui sont stockés dans le Stockage Azure. Les captures instantanées capturent les changements incrémentiels à partir des données stockées dans votre entrepôt de données.
Conseil
Utilisez des instantanés définis par l’utilisateur pour définir un point de récupération avant les mises à jour clés.
Conseil
Microsoft Azure fournit des sauvegardes automatiques à un emplacement géographique distinct pour activer la récupération d’urgence.
Azure Synapse prend automatiquement des captures instantanées pendant la journée, créant ainsi des points de restauration qui sont disponibles pendant sept jours. Vous ne pouvez pas modifier cette période de rétention. Azure Synapse prend en charge un objectif de point de récupération de huit heures. Un entrepôt de données peut être restauré dans la région primaire à partir de n’importe quelle capture instantanée prise au cours des sept derniers jours.
Les points de restauration définis par l’utilisateur sont également pris en charge, ce qui permet de déclencher manuellement des captures instantanées pour créer des points de restauration d’un entrepôt de données avant et après des modifications importantes. Cette fonctionnalité garantit que les points de restauration sont logiquement cohérents, ce qui renforce la protection des données en cas d’interruptions de la charge de travail ou d’erreurs d’utilisateur pendant le temps de récupération rapide.
A l’instar des captures instantanées décrites précédemment, Azure Synapse effectue également une géosauvegarde standard une fois par jour dans un centre de données associé. Le RPO pour une géo-restauration est de 24 heures. Vous pouvez restaurer la géosauvegarde sur un serveur dans n’importe quelle autre région où Azure Synapse est pris en charge. Une géosauvegarde garantit qu’un entrepôt de données peut être restauré si les points de restauration de la région primaire ne sont pas disponibles.
Gestion des charges de travail
Conseil
Dans un entrepôt de données de production, il existe généralement des charges de travail mixtes avec différentes caractéristiques d’utilisation des ressources s’exécutant simultanément.
Netezza incorpore différentes fonctionnalités pour la gestion des charges de travail :
| Technique | Description |
|---|---|
| Règles du planificateur | Les règles du planificateur influencent la planification des plans. Chaque règle de planificateur spécifie une condition ou un ensemble de conditions. Chaque fois que le planificateur reçoit un plan, il évalue toutes les règles du planificateur et effectue les actions appropriées. Chaque fois que le planificateur sélectionne un plan d’exécution, il évalue toutes les règles de planificateur de limitation. Le plan n’est exécuté que si cela ne dépasse pas une limite imposée par une règle de planificateur de limitation. Sinon, le plan attend. Cela vous permet de classifier et de manipuler des plans d’une manière qui influence les autres techniques WLM (SQB, GRA et PQE). |
| Allocation de ressources garantie (GRA) | Vous pouvez attribuer un partage minimal et un pourcentage maximal de ressources système totales aux entités appelées groupes de ressources. Le planificateur garantit que chaque groupe de ressources reçoit des ressources système proportionnellement à son partage minimal. Un groupe de ressources reçoit une plus grande part des ressources lorsque d’autres groupes de ressources sont inactifs, mais ne reçoit jamais plus que son pourcentage maximal configuré. Chaque plan est associé à un groupe de ressources et les paramètres de ces paramètres de groupe de ressources déterminent quelle fraction des ressources système disponibles doivent être mises à disposition pour traiter le plan. |
| Biais de requête courte (SQB) | Les ressources (autrement dit, les emplacements de planification, la mémoire et la mise en file d’attente privilégiée) sont réservées aux requêtes courtes. Une requête courte est une requête pour laquelle l’estimation des coûts est inférieure à une valeur maximale spécifiée (la valeur par défaut est de deux secondes). Avec SQB, les requêtes courtes peuvent s’exécuter même lorsque le système traite d’autres requêtes plus longues. |
| Exécution de requête hiérarchisée (PQE) | En fonction des paramètres que vous configurez, le système affecte une priorité critique, élevée, normale ou faible à chaque requête. La priorité dépend de facteurs tels que l’utilisateur, le groupe ou la session associée à la requête. Le système peut ensuite utiliser la priorité comme base pour allouer des ressources. |
Azure Synapse journalise automatiquement les statistiques d’utilisation des ressources. Les métriques incluent des statistiques d’utilisation pour le processeur, la mémoire, le cache, les E/S et l’espace de travail temporaire pour chaque requête. Azure Synapse journalise également les informations de connectivité, comme les tentatives de connexion ayant échoué.
Conseil
Les métriques de bas niveau et à l’échelle du système sont automatiquement enregistrées dans Azure.
Dans Azure Synapse, les classes de ressources sont des limites de ressources prédéterminées qui régissent les ressources de calcul et la concurrence lors de l’exécution des requêtes. Les classes de ressources peuvent vous aider à gérer votre charge de travail en définissant des limites quant au nombre de requêtes qui s’exécutent simultanément et sur les ressources de calcul qui leur sont respectivement attribuées. Il faut faire un compromis entre la mémoire et la concurrence.
Azure Synapse prend en charge les concepts de gestion des charges de travail de base suivants :
Classification des charges de travail : vous pouvez attribuer une requête à un groupe de charges de travail pour définir des niveaux d’importance.
Importance de la charge de travail : vous pouvez influencer l’ordre dans lequel une requête accède aux ressources. Par défaut, les requêtes sont libérées de la file d’attente sur la base du premier entré/premier sorti à mesure que les ressources deviennent disponibles. L’importance de la charge de travail permet aux requêtes de priorité plus élevée de recevoir les ressources immédiatement.
Isolation des charges de travail : vous pouvez réserver des ressources pour un groupe de charges de travail, affecter une utilisation maximale et minimale pour différentes ressources, limiter les ressources qu’un groupe de requêtes peut consommer et définir une valeur de délai d’expiration pour tuer automatiquement les requêtes avec perte de contrôle.
L’exécution de charges de travail mixtes peut poser des problèmes de ressources sur les systèmes chargés. Un schéma de gestion des charges de travail réussi gère efficacement les ressources, garantit une utilisation hautement efficace des ressources et optimise le retour sur investissement (ROI). La classification de la charge de travail, l’importance de la charge de travail et l’isolation de la charge de travail donnent plus de contrôle sur la façon dont la charge de travail utilise les ressources système.
Le guide de gestion des charges de travail décrit les techniques permettant d’analyser la charge de travail, de gérer et de surveiller l’importance de la charge de travail](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md), et les étapes de conversion d’une classe de ressources en groupe de charge de travail. Utilisez le Portail Azure et les requêtes T-SQL sur les DMV pour surveiller la charge de travail pour vous assurer que les ressources applicables sont utilisées efficacement. Azure Synapse fournit un ensemble de vues de gestion dynamique (DMV) pour surveiller tous les aspects de la gestion des charges de travail. Ces vues sont utiles quand vous dépannez et identifiez activement les goulots d’étranglement des performances de votre charge de travail.
Ces informations peuvent également être utilisées pour la planification de la capacité, en déterminant les ressources requises pour des utilisateurs supplémentaires ou une charge de travail d’application. Cela s’applique également à la planification de scale-up/scale-down des ressources de calcul pour la prise en charge rentable des charges de travail « pointues », telles que des charges de travail avec des pics d’activité temporaires intenses, entourés de périodes d’activité peu fréquente.
Pour plus d’informations sur la gestion des charges de travail dans Azure Synapse, consultez Gestion des charges de travail avec des classes de ressources.
Mettre à l’échelle des ressources de calcul
Conseil
L’un des principaux avantages d’Azure est la possibilité de mettre à l’échelle indépendamment les ressources de calcul à la demande pour gérer les charges de travail maximales de manière rentable.
L’architecture de l’entrepôt de données sépare le stockage et le calcul, ce qui permet de les mettre à l’échelle indépendamment l’un de l’autre. En conséquence, les ressources de calcul peuvent être mises à l’échelle pour répondre aux exigences de performance, indépendamment du stockage de données. Vous avez également la possibilité de suspendre ou reprendre des ressources de calcul. L’un des avantages naturels de cette architecture est que la facturation du calcul est effectuée séparément de celle du stockage. Si un entrepôt de données n’est pas utilisé, vous pouvez économiser sur les coûts de calcul en interrompant le calcul.
Les ressources de calcul peuvent être mises à l’échelle ou mises à l’échelle en ajustant le paramètre d’unités d’entrepôt de données pour l’entrepôt de données. Les performances de chargement et de requête s’accroîtront de manière linéaire à mesure que vous augmentez la valeur DWU.
L’ajout de nœuds de calcul supplémentaires ajoute plus de puissance de calcul et la capacité à tirer parti d’un traitement plus parallèle. À mesure que le nombre de nœuds de calcul augmente, le nombre de distributions par nœud de calcul diminue, ce qui fournit davantage de puissance de calcul et de traitement parallèle pour vos requêtes. De même, la diminution des unités d’entrepôt de données réduit le nombre de nœuds de calcul, ce qui réduit les ressources de calcul pour les requêtes.
Étapes suivantes
Pour en savoir plus sur la visualisation et la création de rapports, consultez l’article suivant de cette série : Visualisation et création de rapports pour les migrations Netezza.