Après la migration d’Oracle, implémentez un entrepôt de données moderne dans Microsoft Azure
Cet article est la dernière partie d’une série de sept parties qui fournit des conseils sur la migration d’Oracle vers Azure Synapse Analytics. Cet article se concentre sur les bonnes pratiques à suivre pour implémenter des entrepôts de données modernes.
Au-delà de la migration de l’entrepôt de données vers Azure
L’une des principales raisons de migrer votre entrepôt de données existant vers Azure Synapse Analytics est la possibilité d’utiliser à grande échelle une base de données analytique sécurisée, scalable, économique, native cloud, avec paiement à l’utilisation. Grâce à Azure Synapse, vous pouvez également intégrer votre entrepôt de données migré à l’écosystème analytique complet Microsoft Azure pour tirer parti d’autres technologies Microsoft et moderniser votre entrepôt de données migré. Ces technologies sont les suivantes :
Azure Data Lake Storage pour l’ingestion, la mise en lots, le nettoyage et la transformation des données de manière rentable. Data Lake Storage permet de libérer la capacité de l’entrepôt de données occupée par des tables de mise en lots à croissance rapide.
Azure Data Factory pour une intégration collaborative de l’informatique et des données en libre-service avec des connecteurs vers des sources de données cloud et locales, et des données de streaming.
Common Data Model pour partager des données fiables et cohérentes entre plusieurs technologies, notamment :
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Partenaires Microsoft ISV
Technologies de science des données de Microsoft, notamment :
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark en tant que service)
- Notebooks Jupyter
- RStudio
- ML.NET
- .NET pour Apache Spark, qui permet aux scientifiques des données d’utiliser des données Azure Synapse pour entraîner des modèles Machine Learning à grande échelle.
Azure HDInsight pour traiter de grandes quantités de données et joindre le Big Data aux données Azure Synapse en créant un entrepôt de données logique à l’aide de PolyBase.
Azure Event Hubs, Azure Stream Analytics et Apache Kafka pour intégrer des données de streaming en direct à partir d’Azure Synapse.
La croissance du Big Data a entraîné une demande importante de Machine Learning pour pouvoir utiliser des modèles de Machine Learning personnalisés et entraînés dans Azure Synapse. Les modèles Machine Learning permettent d’effectuer l’analytique dans une base de données à grande échelle, par lots, en fonction des événements et à la demande. L’analytique dans la base de données dans Azure Synapse à partir de plusieurs outils et applications décisionnels garantit également des prédictions et recommandations cohérentes.
De plus, vous pouvez intégrer Azure Synapse aux outils des partenaires Microsoft sur Azure pour avoir un retour sur investissement plus rapidement.
Examinons de plus près comment tirer parti des technologies de l’écosystème analytique de Microsoft pour moderniser votre entrepôt de données une fois que vous avez migré vers Azure Synapse.
Déplacer le traitement des données intermédiaires et ETL vers Data Lake Storage et Data Factory
La transformation numérique a créé un défi majeur pour les entreprises en générant des flots de nouvelles données à capturer et à analyser. C’est le cas, par exemple, des données de transaction créées par l’ouverture des systèmes OLTP (traitement transactionnel en ligne) pour permettre un accès aux services à partir d’appareils mobiles. La plupart de ces données se retrouvent dans des entrepôts de données, et les systèmes OLTP en sont la source principale. Dans la mesure où ce sont désormais les clients, plutôt que les employés, qui déterminent le taux de transaction, le volume des données des tables de mise en lots de l’entrepôt de données augmente rapidement.
Avec l’afflux rapide de données dans l’entreprise, ainsi que de nouvelles sources de données comme l’Internet des objets (l’IoT), les entreprises doivent trouver des moyens de faire évoluer le traitement ETL de l’intégration des données. L’un des moyens est de déplacer l’ingestion, le nettoyage, la transformation et l’intégration des données vers un lac de données afin d’y traiter les données à grande échelle, dans le cadre d’un programme de modernisation de l’entrepôt de données.
Une fois que vous avez migré votre entrepôt de données vers Azure Synapse, Microsoft peut moderniser votre traitement ETL en ingérant et en mettant en lots les données dans Data Lake Storage. Vous pouvez ensuite nettoyer, transformer et intégrer vos données à grande échelle à l’aide de Data Factory avant de les charger dans Azure Synapse en parallèle via PolyBase.
Pour les stratégies ELT, vous pouvez déplacer le traitement ELT vers Data Lake Storage pour faciliter la mise à l’échelle à mesure que le volume ou la fréquence des données augmente.
Microsoft Azure Data Factory
Azure Data Factory est un service d’intégration de données hybride avec paiement à l’utilisation pour un traitement ETL et ELT hautement scalable. Data Factory fournit une interface utilisateur web pour générer des pipelines d’intégration de données sans code. Avec Data Factory :
Créez des pipelines d’intégration de données évolutifs sans code.
Acquérez facilement des données à grande échelle.
Vous ne payez que pour ce que vous utilisez.
Connectez-vous à des sources de données locales, cloud et SaaS.
Ingérez, déplacez, nettoyez, transformez, intégrez et analysez des données cloud et locales à grande échelle.
Créez, surveillez et gérez en toute transparence des pipelines qui couvrent les magasins de données locaux et dans le cloud.
Activez le scale-out du paiement à l’utilisation en fonction de la croissance des clients.
Vous pouvez utiliser ces fonctionnalités sans écrire de code, ou ajouter du code personnalisé aux pipelines Data Factory. La capture d’écran suivante montre un exemple de pipeline Data Factory.

Conseil
Data Factory vous permet de créer des pipelines d’intégration de données évolutifs et sans code.
Vous pouvez implémenter le développement de pipeline Data Factory à partir de plusieurs emplacements, notamment :
Le portail Microsoft Azure.
Microsoft Azure PowerShell.
Par programmation à partir de .NET et Python à l’aide d’un kit SDK multilangage.
Modèles Azure Resource Manager (ARM)
Des API Rest.
Conseil
Data Factory peut se connecter aux données locales, cloud et SaaS.
Les développeurs et les scientifiques des données qui préfèrent écrire du code peuvent facilement créer des pipelines Data Factory en Java, Python et .NET à l’aide des kits de développement logiciel (SDK) disponibles pour ces langages de programmation. Les pipelines Data Factory peuvent être des pipelines de données hybrides, puisqu’ils peuvent se connecter aux données, les ingérer, les nettoyer, les transformer et les analyser dans les centres de données locaux, dans Microsoft Azure, dans d’autres clouds et dans les offres SaaS.
Après avoir développé des pipelines Data Factory pour intégrer et analyser des données, vous pouvez les déployer à grande échelle, planifier leur exécution par lots, les appeler à la demande en tant que service (as a service) ou les exécuter en temps réel en fonction des événements. Un pipeline Data Factory peut également s’exécuter sur un ou plusieurs moteurs d’exécution. De plus, il peut effectuer le monitoring de l’exécution pour garantir les performances et fournir un suivi des erreurs.
Conseil
Dans Azure Data Factory, les pipelines contrôlent l’intégration et l’analyse des données. Data Factory est un logiciel d’intégration de données d’entreprise destiné aux professionnels de l’informatique ; il offre une fonctionnalité de data wrangling pour les utilisateurs métier.
Cas d'utilisation
Data Factory prend en charge de nombreux cas d’usage. Par exemple :
Préparer, intégrer et enrichir des données provenant de sources de données cloud et locales pour remplir votre entrepôt de données et vos datamarts migrés sur Microsoft Azure Synapse.
Préparer, intégrer et enrichir des données provenant de sources de données cloud et locales pour produire des données d’entraînement à utiliser dans le développement de modèles Machine Learning et le réentraînement de modèles analytiques.
Orchestrer la préparation et l’analytique des données pour créer des pipelines analytiques prédictifs et normatifs afin de traiter et d’analyser les données par lots, par exemple dans le cadre de l’analyse des sentiments. Agir sur les résultats de l’analyse ou remplir votre entrepôt de données avec les résultats.
Préparer, intégrer et enrichir des données pour les applications métier basées sur des données qui s’exécutent dans le cloud Azure en plus des magasins de données opérationnelles tels qu’Azure Cosmos DB.
Conseil
Créez des jeux de données d’apprentissage dans la science des données pour développer des modèles Machine Learning.
Sources de données
Data Factory vous permet d’utiliser des connecteurs provenant à la fois de sources de données cloud et locales. Le logiciel de l’agent, appelé runtime d’intégration auto-hébergé, accède en toute sécurité aux sources de données locales et prend en charge le transfert de données sécurisé et évolutif.
Transformer des données à l’aide d’Azure Data Factory
Dans un pipeline Data Factory, vous pouvez ingérer, nettoyer, transformer, intégrer et analyser n’importe quel type de données à partir de ces sources. Les données peuvent être structurées, semi-structurées comme JSON ou Avro, ou non structurées.
Sans avoir à écrire aucun code, les développeurs ETL professionnels peuvent utiliser les flux de données de mappage Data Factory pour filtrer, diviser, joindre plusieurs types, rechercher, croiser dynamiquement, ne pas croiser dynamiquement, trier, unir et agréger les données. En outre, Data Factory prend en charge les clés de substitution, plusieurs options de traitement d’écriture telles que l’insertion, l’upsert, la mise à jour, la recréation de table et la troncation de table, ainsi que plusieurs types de magasins de données cibles, également appelés récepteurs. Les développeurs ETL peuvent également créer des agrégations, y compris des agrégations de séries chronologiques qui nécessitent qu’une fenêtre soit placée sur des colonnes de données.
Conseil
Les développeurs ETL professionnels peuvent utiliser les flux de données de mappage Data Factory pour nettoyer, transformer et intégrer les données sans avoir à écrire du code.
Vous pouvez exécuter des flux de données de mappage qui transforment les données en activités dans un pipeline Data Factory et, si nécessaire, vous pouvez inclure plusieurs flux de données de mappage dans un même pipeline. De cette façon, vous pouvez gérer la complexité en décomposant les tâches de transformation et d’intégration de données difficiles en flux de données de mappage plus petits qui peuvent être combinés. Vous pouvez également ajouter du code personnalisé si nécessaire. Les flux de données de mappage Data Factory incluent d’autres fonctionnalités qui permettent les opérations suivantes :
Définissez des expressions pour nettoyer et transformer des données, calculer des agrégations et enrichir des données. Par exemple, ces expressions peuvent effectuer l’ingénierie des caractéristiques sur un champ de date pour les décomposer en plusieurs champs pour créer des données d’entraînement pendant le développement du modèle Machine Learning. Vous pouvez construire des expressions à partir d’un vaste ensemble de fonctions comprenant des fonctions mathématiques, temporelles, de division, de fusion, de concaténation de chaînes, de conditions, de correspondance au modèle, de remplacement et bien d’autres fonctions.
Gérez automatiquement la dérive de schéma afin que les pipelines de transformation de données puissent éviter d’être affectés par les modifications de schéma dans les sources de données. Cela est particulièrement important pour le streaming de données IoT, où des changements de schéma peuvent se produire de manière imprévue si les appareils sont mis à niveau ou quand les lectures sont manquées par les appareils de passerelle qui collectent des données IoT.
Partitionnez des données pour permettre l’exécution de transformations en parallèle à grande échelle.
Inspectez les données de streaming pour voir les métadonnées d’un flux que vous transformez.
Conseil
Data Factory prend en charge la possibilité de détecter et de gérer automatiquement les modifications de schéma dans les données entrantes, telles que les données de streaming.
La capture d’écran suivante montre un exemple de flux de données de mappage Data Factory.

Les ingénieurs de données peuvent profiler la qualité des données et voir les résultats des transformations de données individuelles en activant une fonctionnalité de débogage durant le développement.
Conseil
Data Factory peut également partitionner des données pour permettre au traitement ETL de s’exécuter à grande échelle.
Si nécessaire, vous pouvez étendre les fonctionnalités de transformation et d’analyse de Data Factory en ajoutant un service lié qui stocke votre code dans un pipeline. Par exemple, un notebook de pool Azure Synapse Spark peut contenir du code Python qui utilise un modèle entraîné pour effectuer le scoring des données intégrées par un flux de données de mappage.
Vous pouvez stocker les données intégrées et les résultats de l’analytique d’un pipeline Data Factory dans un ou plusieurs magasins de données tels que Data Lake Storage, Azure Synapse ou des tables Hive dans HDInsight. Vous pouvez également appeler d’autres activités pour agir sur les insights générés par un pipeline analytique Data Factory.
Conseil
Les pipelines Data Factory sont extensibles, car Data Factory vous permet d’écrire votre propre code et de l’exécuter dans un pipeline.
Utiliser Spark pour mettre à l’échelle l’intégration des données
Au moment de l’exécution, Data Factory utilise en interne les pools Azure Synapse Spark, qui sont des offres Spark fournies en tant que services (as a service) par Microsoft, pour nettoyer et intégrer les données dans le cloud Azure. Vous pouvez nettoyer, intégrer et analyser des données très volumineuses et à vélocité élevée, comme les données de parcours de visite, à grande échelle. L’intention de Microsoft est également d’exécuter des pipelines Data Factory sur d’autres distributions Spark. En plus d’exécuter des travaux ETL sur Spark, Data Factory peut appeler des scripts Pig et des requêtes Hive pour accéder aux données stockées dans HDInsight et les transformer.
Liez la préparation des données en libre-service et le traitement ETL Data Factory à l’aide de flux de wrangling data
Le data wrangling permet aux utilisateurs métier, également appelés intégrateurs de données citoyens et ingénieurs Données, d’utiliser la plateforme pour découvrir, explorer et préparer visuellement les données à grande échelle sans écrire de code. Cette fonctionnalité Data Factory facile à utiliser est similaire aux flux de données Microsoft Excel Power Query ou Microsoft Power BI, où les utilisateurs métier libre-service se servent d’une IU de type feuille de calcul avec des listes déroulantes de transformations pour préparer et intégrer les données. La capture d’écran suivante montre un exemple de flux de wrangling Data Factory.

Contrairement à Excel et Power BI, les flux de wrangling data dans Data Factory utilisent Power Query pour générer du code M et ensuite le traduire en un travail Spark en mémoire massivement parallèle en vue d’une exécution à l’échelle du cloud. La combinaison des flux de données de mappage et des flux de wrangling data dans Data Factory permet aux développeurs ETL professionnels et aux utilisateurs métier de travailler en collaboration pour préparer, intégrer et analyser les données dans un objectif métier commun. Le diagramme de flux de données de mappage Data Factory précédent montre comment Data Factory et les notebooks de pool Azure Synapse Spark peuvent être combinés dans le même pipeline Data Factory. La combinaison de flux de données de mappage et de flux de wrangling data dans Data Factory permet aux professionnels de l’informatique et aux utilisateurs métier de connaître les flux de données que chacun a créés. De plus, elle prend en charge la réutilisation des flux de données pour réduire le travail de réinvention et optimiser la productivité et la cohérence.
Conseil
Data Factory prend en charge les flux de wrangling data et les flux de données de mappage. Les utilisateurs métier et les professionnels de l’informatique peuvent ainsi intégrer des données en collaboration sur une plateforme commune.
Lier des données et des analyses dans des pipelines analytiques
Outre le nettoyage et la transformation des données, Data Factory peut combiner l’intégration et l’analytique des données dans le même pipeline. Vous pouvez utiliser Data Factory pour créer à la fois des pipelines d’intégration de données et des pipelines analytiques, les seconds étant des extensions des premiers. Vous pouvez supprimer un modèle analytique dans un pipeline si vous souhaitez créer un autre pipeline analytique qui génère des données intégrées propres pour les prédictions ou les recommandations. Ensuite, vous pouvez agir immédiatement sur les prédictions ou recommandations, ou les stocker dans votre entrepôt de données pour fournir de nouveaux insights et recommandations consultables dans les outils décisionnels.
Pour effectuer le scoring de vos données par lots, vous pouvez développer un modèle analytique que vous appelez en tant que service dans un pipeline Data Factory. Vous pouvez développer des modèles analytiques sans code en utilisant Azure Machine Learning studio ou le SDK Azure Machine Learning avec des notebooks de pool Azure Synapse Spark ou R dans RStudio. Lorsque vous exécutez des pipelines de Machine Learning Spark sur des notebooks de pool Azure Synapse Spark, l’analyse se fait à grande échelle.
Vous pouvez stocker les données intégrées et les résultats de l’analytique du pipeline Data Factory dans un ou plusieurs magasins de données, par exemple Data Lake Storage, Azure Synapse ou des tables Hive dans HDInsight. Vous pouvez également appeler d’autres activités pour agir sur les insights générés par un pipeline analytique Data Factory.
Utiliser une base de données de lac pour partager des données fiables et cohérentes
L’un des principaux objectifs dans une configuration d’intégration de données est la capacité à intégrer les données une seule fois et à les réutiliser partout, et pas seulement dans un entrepôt de données. Par exemple, vous pouvez utiliser des données intégrées dans la science des données. La réutilisation évite de devoir réinventer et garantit des données cohérentes et couramment comprises que tout le monde peut approuver.
Common Data Model décrit les entités de données principales qui peuvent être partagées et réutilisées dans l’entreprise. Pour permettre cette réutilisation, Common Data Model établit un ensemble de noms et de définitions de données courants qui décrivent des entités de données logiques. Parmi les noms de données courants, citons Client, Compte, Produit, Fournisseur, Commandes, Paiements et Retours. Les professionnels de l’informatique et les utilisateurs métier peuvent se servir d’un logiciel d’intégration de données pour créer et stocker des ressources de données courantes afin d’optimiser leur réutilisation et d’assurer une cohérence globale.
Azure Synapse fournit des modèles de base de données propres aux secteurs d’activité pour faciliter la standardisation des données dans le lac. Les modèles de base de données de lac fournissent des schémas pour des domaines métier prédéfinis, ce qui permet de charger les données dans une base de données de lac de manière structurée. L’intérêt est d’utiliser un logiciel d’intégration de données pour créer des ressources de données courantes dans la base de données de lac. En effet, vous obtenez alors des données autodescriptives qui peuvent être consommées par des applications et des systèmes analytiques. Vous pouvez créer des ressources de données courantes dans Data Lake Storage à l’aide de Data Factory.
Conseil
Data Lake Storage est un stockage partagé sur lequel s’appuient Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark et HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse et Azure Machine Learning peuvent consommer des ressources de données courantes. Le diagramme suivant montre comment une base de données de lac est utilisée dans Azure Synapse.
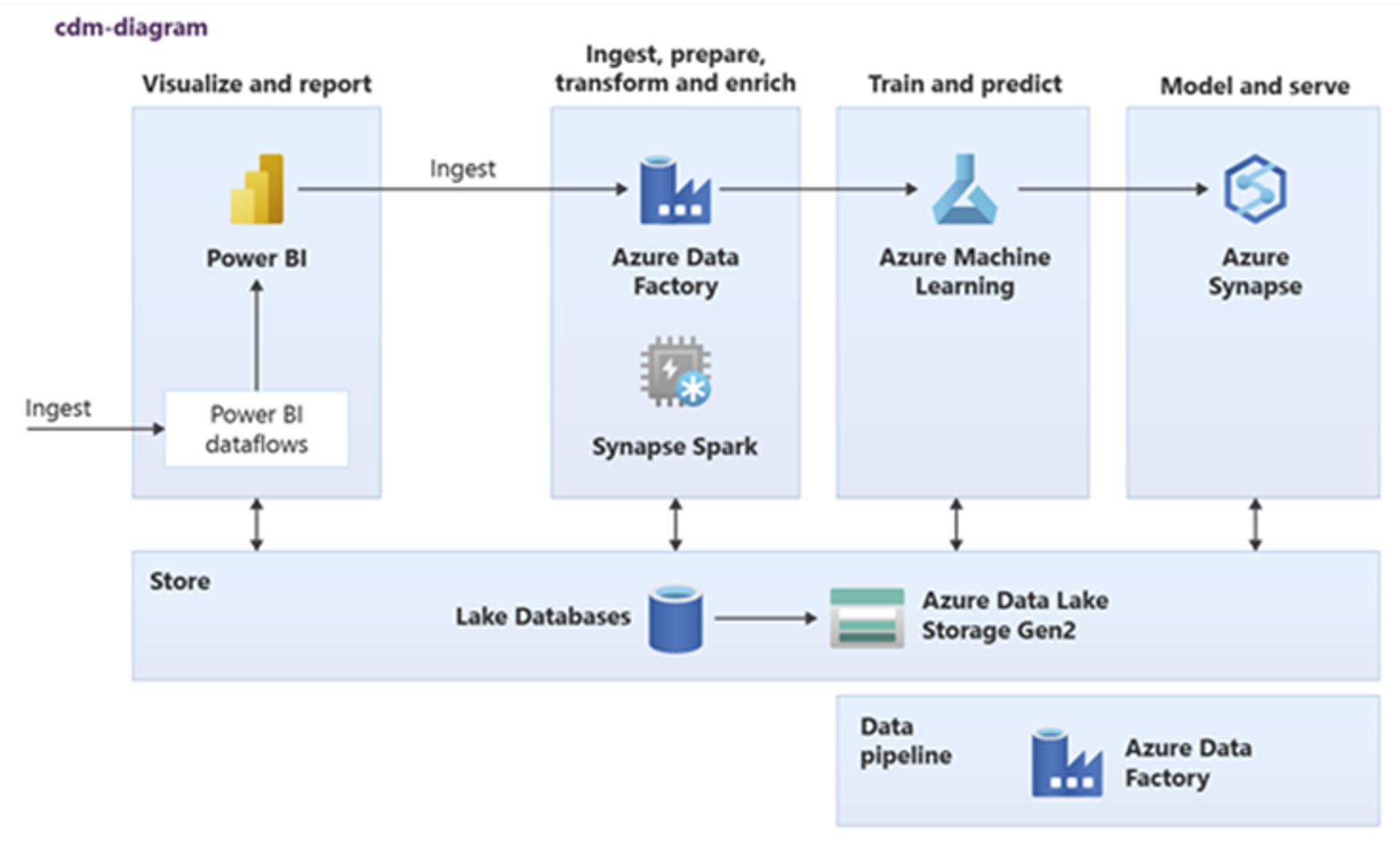
Conseil
Intégrez des données pour créer des entités logiques de base de données de lac dans un stockage partagé. Vous permettrez ainsi une réutilisation maximale des ressources de données courantes.
Intégration aux technologies de science des données Microsoft sur Azure
Un autre objectif clé de la modernisation d’un entrepôt de données consiste à produire des insights qui apportent un avantage concurrentiel. Vous pouvez produire des insights en intégrant dans Azure votre entrepôt de données migré, au moyen des technologies de science des données de Microsoft et de fournisseurs tiers. Les sections suivantes décrivent les technologies de Machine Learning et de science des données fournies par Microsoft. Elles expliquent comment utiliser ces technologies avec Azure Synapse dans un environnement d’entrepôt de données moderne.
Technologies Microsoft pour la science des données sur Azure
Microsoft propose toute une gamme de technologies qui prennent en charge l’analyse avancée. Grâce à ces technologies, vous pouvez créer des modèles analytiques prédictifs avec le Machine Learning ou encore analyser des données non structurées avec le Deep Learning. Ces technologies sont les suivantes :
Azure Machine Learning Studio
Azure Machine Learning
Notebooks de pool Azure Synapse Spark
ML.NET (API, CLI ou ML.NET Model Builder pour Visual Studio)
.NET pour Apache Spark
Les scientifiques des données peuvent utiliser RStudio (R) et Jupyter Notebook (Python) pour développer des modèles analytiques, ou utiliser des infrastructures comme Keras ou TensorFlow.
Conseil
Développez des modèles Machine Learning selon une approche avec peu ou pas de code, ou en utilisant des langages de programmation comme Python, R et .NET.
Azure Machine Learning Studio
Azure Machine Learning studio est un service cloud complètement managé qui vous permet de créer, déployer et partager l’analytique prédictive via une interface utilisateur web par glisser-déposer. La capture d’écran suivante montre l’interface utilisateur d’Azure Machine Learning studio.

Azure Machine Learning
Azure Machine Learning fournit un kit SDK et des services pour Python qui peuvent vous aider à préparer rapidement des données, mais aussi à entraîner et déployer des modèles Machine Learning. Vous pouvez utiliser Azure Machine Learning dans des notebooks Azure en utilisant Jupyter Notebook, avec des frameworks open source, tels que PyTorch, TensorFlow, scikit-learn ou Spark MLlib, la bibliothèque Machine Learning pour Spark.
Conseil
Azure Machine Learning fournit un Kit de développement logiciel (SDK) pour le développement de modèles Machine Learning à l’aide de plusieurs infrastructures open source.
Vous pouvez également utiliser Azure Machine Learning pour créer des pipelines de Machine Learning qui gèrent le workflow de bout en bout, effectuent un scale-in par programmation dans le cloud, et déploient des modèles à la fois dans le cloud et en périphérie. Azure Machine Learning contient des espaces de travail, qui sont des espaces logiques que vous pouvez créer par programmation ou bien manuellement dans le portail Azure. Ces espaces de travail conservent les cibles de calcul, les expériences, les magasins de données, les modèles Machine Learning entraînés, les images Docker et les services déployés à un seul endroit pour permettre aux équipes de travailler ensemble. Vous pouvez utiliser Azure Machine Learning dans Visual Studio avec l’extension Visual Studio pour IA.
Conseil
Organisez et gérez les magasins de données associés, les expériences, les modèles entraînés, les images Docker et les services déployés dans les espaces de travail.
Notebooks de pool Spark Azure Synapse
Un notebook de pool Azure Synapse Spark est un service Apache Spark optimisé pour Azure. Grâce aux notebooks de pool Azure Synapse Spark :
Les ingénieurs de données peuvent créer et exécuter des travaux scalables de préparation des données à l’aide de Data Factory.
Les scientifiques des données peuvent créer et exécuter des modèles Machine Learning à grande échelle à l’aide de notebooks écrits dans des langages tels que Scala, R, Python, Java et SQL, et visualiser les résultats.
Conseil
Azure Synapse Spark est une offre Spark scalable dynamiquement qui est fournie en tant que service par Microsoft. Spark permet une exécution scalable de la préparation des données, du développement de modèles et de l’exécution de modèles déployés.
Les travaux exécutés dans les notebooks de pool Azure Synapse Spark peuvent récupérer, traiter et analyser des données à grande échelle qui proviennent du Stockage Blob Azure, de Data Lake Storage, d’Azure Synapse, de HDInsight et de services de données de streaming comme Apache Kafka.
Conseil
Azure Synapse Spark peut accéder aux données dans toute une série de magasins de données de l’écosystème analytique Microsoft sur Azure.
Les notebooks de pool Azure Synapse Spark prennent en charge la mise à l’échelle automatique et l’arrêt automatique pour réduire le coût total de possession (TCO). Les scientifiques des données peuvent utiliser l’infrastructure open source MLflow pour gérer le cycle de vie du Machine Learning.
ML.NET
ML.NET est un framework de Machine Learning open source et multiplateforme pour Windows, Linux et macOS. Microsoft a créé ML.NET afin que les développeurs .NET puissent utiliser des outils existants, tels que ML.NET Model Builder pour Visual Studio, pour développer des modèles Machine Learning personnalisés et les intégrer ensuite à leurs applications .NET.
Conseil
Microsoft a étendu sa capacité de Machine Learning aux développeurs .NET.
.NET pour Apache Spark
.NET pour Apache Spark étend la prise en charge de Spark à .NET, en plus de R, Scala, Python et Java. Il vise à rendre Spark accessible aux développeurs .NET sur toutes les API Spark. .NET pour Apache Spark est actuellement disponible uniquement sur Apache Spark dans HDInsight, mais Microsoft a l’intention de rendre .NET pour Apache Spark disponible sur les notebooks de pool Azure Synapse Spark.
Utiliser Azure Synapse Analytics avec votre entrepôt de données
Pour combiner des modèles Machine Learning avec Azure Synapse, vous pouvez :
Utiliser des modèles Machine Learning qui traitent par lots ou en temps réel des données de streaming pour produire de nouveaux insights, et ajouter ces insights à ceux que vous avez déjà dans Azure Synapse.
Utiliser les données dans Azure Synapse afin de développer et d’entraîner de nouveaux modèles prédictifs pour un déploiement à un autre emplacement, par exemple dans d’autres applications.
Déployer des modèles Machine Learning, notamment les modèles entraînés ailleurs, dans Azure Synapse pour analyser les données dans votre entrepôt de données et générer une nouvelle valeur métier.
Conseil
Entraînez, testez, évaluez et exécutez des modèles Machine Learning à grande échelle sur les notebooks Azure Synapse Spark avec des données dans Azure Synapse.
Les scientifiques des données peuvent utiliser RStudio, Jupyter Notebooks et des notebooks de pool Azure Synapse Spark avec Azure Machine Learning pour développer des modèles Machine Learning qui s’exécutent à grande échelle sur les notebooks de pool Azure Synapse Spark en utilisant des données dans Azure Synapse. Par exemple, les scientifiques des données peuvent créer un modèle non supervisé pour segmenter les clients dans le cadre de campagnes marketing différenciées. Utilisez le machine learning supervisé afin d’entraîner un modèle à prédire un résultat spécifique, par exemple la propension d’un client à l’attrition, ou recommander à un client la prochaine meilleure offre susceptible d’augmenter sa valeur. Le diagramme suivant montre comment Azure Synapse peut être utilisé pour Azure Machine Learning.

Dans un autre scénario, vous pouvez ingérer des données de réseaux sociaux ou de sites web d’avis dans Data Lake Storage, puis préparer et analyser les données à grande échelle sur un notebook de pool Azure Synapse Spark par un traitement du langage naturel pour évaluer le sentiment des clients à l’égard de vos produits ou votre marque. Vous pouvez ensuite ajouter les scores de l’évaluation à votre entrepôt de données. En utilisant l’analytique du Big Data pour comprendre l’effet du sentiment négatif sur les ventes de produits, vous ajoutez de nouveaux insights aux informations déjà connues dans votre entrepôt de données.
Conseil
Produisez de nouvelles insights à l’aide de Machine Learning sur Azure en lot ou en temps réel et ajoutez à ce que vous connaissez dans votre entrepôt de données.
Intégrer des données de diffusion en direct dans Azure Synapse Analytics
Lors de l’analyse des données dans un entrepôt de données moderne, vous devez être en mesure d’analyser les données de streaming en temps réel et de les joindre à des données historiques dans votre entrepôt de données. La combinaison de données IoT avec des données de produits ou de ressources en est un exemple.
Conseil
Intégrez à votre entrepôt de données des données de streaming provenant d’appareils IoT ou de parcours de visite.
Une fois que vous avez terminé la migration de votre entrepôt de données vers Azure Synapse, vous pouvez commencer l’intégration des données de streaming en direct dans le cadre d’un exercice de modernisation de l’entrepôt de données en tirant parti des fonctionnalités supplémentaires dans Azure Synapse. Pour ce faire, ingérez les données de streaming via Event Hubs, d’autres technologies comme Apache Kafka, ou potentiellement votre outil ETL existant s’il prend en charge les sources de données de streaming. Stockez les données dans Data Lake Storage. Ensuite, créez une table externe dans Azure Synapse à l’aide de PolyBase et faites-la pointer sur les données diffusées en streaming dans Data Lake Storage. De cette manière, votre entrepôt de données contient de nouvelles tables qui fournissent un accès aux données de streaming en temps réel. Interrogez la table externe comme si les données se trouvaient dans l’entrepôt de données, en utilisant le langage T-SQL standard à partir de n’importe quel outil décisionnel ayant accès à Azure Synapse. Vous pouvez également joindre les données de streaming à d’autres tables contenant des données historiques afin de créer des vues qui facilitent l’accès aux données par les utilisateurs métier.
Conseil
Ingérez les données de streaming dans Data Lake Storage à partir d’Event Hubs ou d’Apache Kafka, et accédez aux données à partir d’Azure Synapse à l’aide de tables externes PolyBase.
Dans le diagramme suivant, un entrepôt de données en temps réel sur Azure Synapse est intégré aux données de streaming dans Data Lake Storage.
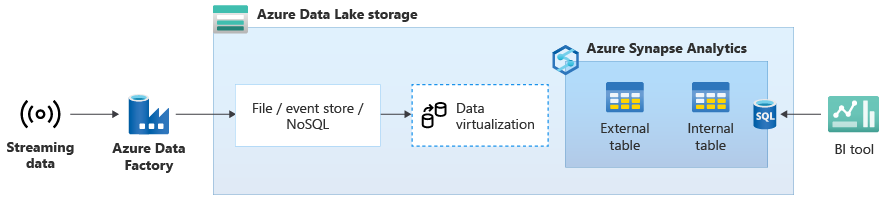
Créer un entrepôt de données logique à l’aide de PolyBase
Grâce à PolyBase, vous pouvez créer un entrepôt de données logique pour simplifier l’accès des utilisateurs à plusieurs magasins de données analytiques. Au cours des dernières années, beaucoup d’entreprises ont choisi d’utiliser des magasins de données analytiques à « charge de travail optimisée » en plus de leurs entrepôts de données. Les plateformes analytiques sur Azure incluent :
Data Lake Storage avec le notebook de pool Azure Synapse Spark (Spark as a service), pour l’analytique du Big Data.
HDInsight (Hadoop as a service), également pour l’analytique du Big Data.
Bases de données NoSQL Graph pour l’analyse de graphiques, qui peut être effectuée dans Azure Cosmos DB.
Event Hubs et Stream Analytics, pour l’analyse en temps réel des données en mouvement.
Il se peut que vous ayez des équivalents non-Microsoft de ces plateformes, ou que vous disposiez d’un système de gestion des données de référence (MDM) qui doit rester accessible pour obtenir des données fiables et cohérentes sur les clients, les fournisseurs, les produits, les ressources, etc.
Conseil
PolyBase simplifie l’accès aux différents magasins de données analytiques sous-jacents sur Azure pour faciliter l’accès aux données par les utilisateurs métier.
L’émergence de ces plateformes analytiques est due à l’explosion des nouvelles sources de données, qu’elles soient internes ou externes à l’entreprise, et aux besoins des utilisateurs métier de capturer et d’analyser les nouvelles données. Les nouvelles sources de données sont notamment les suivantes :
Données générées par l’ordinateur, telles que les données de capteur IoT et les données de flux de clic.
Données générées manuellement, par exemple les données des réseaux sociaux, les données de sites web d’avis, les e-mails entrants des clients, les images et les vidéos.
Autres données externes, telles que les données publiques ouvertes et les données météorologiques.
Ces nouvelles données dépassent les données de transaction structurées et les principales sources de données qui alimentent généralement les entrepôts de données. Elles incluent souvent :
- Des données semi-structurées telles que JSON, XML ou Avro.
- Des données non structurées de type texte, voix, image ou vidéo, qui sont plus complexes à traiter et à analyser.
- Des données très volumineuses, des données à vélocité élevée ou les deux.
Ainsi, de nouveaux genres d’analyses plus complexes ont émergé, par exemple le traitement du langage naturel, l’analyse de graphes, le Deep Learning, l’analytique de données de streaming ou encore l’analyse complexe de gros volumes de données structurées. En règle générale, ces types d’analyses ne s’effectuent pas dans un entrepôt de données. Il n’est donc pas surprenant de voir différentes plateformes analytiques pour différents types de charges de travail analytiques, comme l’illustre le diagramme suivant.
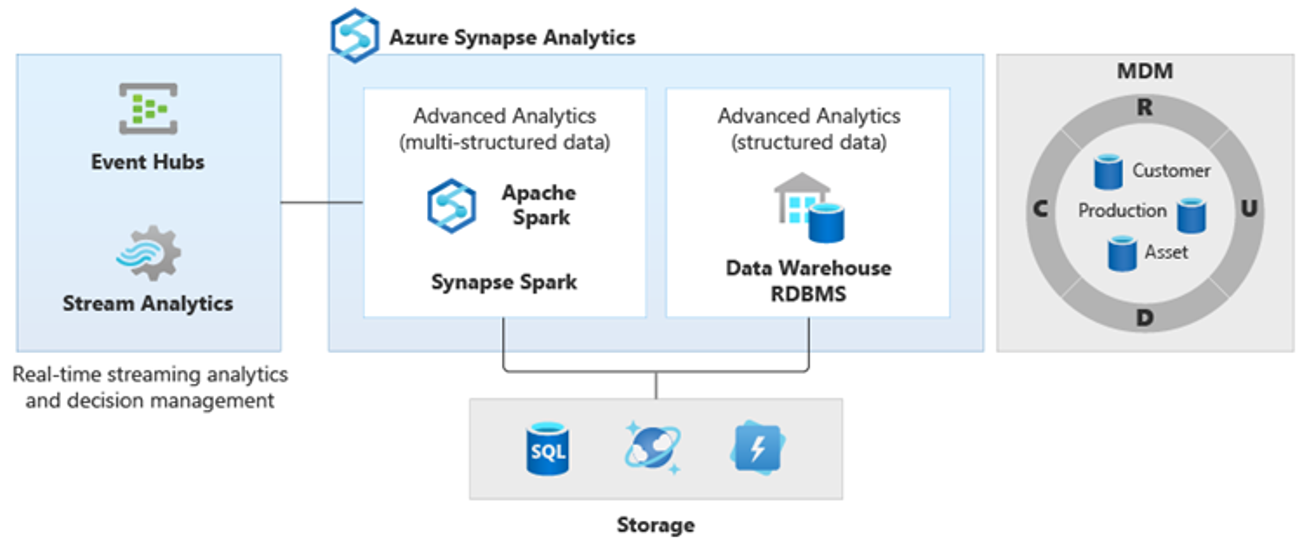
Conseil
Le fait de montrer les données de plusieurs magasins de données analytiques comme si elles se trouvaient sur un même système, et de les joindre à Azure Synapse, s’appelle créer une architecture d’entrepôt de données logique.
Comme ces plateformes produisent de nouveaux insights, il est normal de voir une exigence de combinaison des nouveaux insights avec les données déjà connues dans Azure Synapse, ce que PolyBase rend possible.
Avec la virtualisation des données PolyBase dans Azure Synapse, vous pouvez implémenter un entrepôt de données logique dans lequel les données Azure Synapse sont jointes aux données stockées dans d’autres magasins de données analytiques Azure et locaux tels que HDInsight, Azure Cosmos DB ou le flux de données de streaming entrant dans Data Lake Storage à partir de Stream Analytics ou d’Event Hubs. Cette approche est plus simple pour les utilisateurs, qui peuvent accéder aux tables externes dans Azure Synapse sans avoir besoin de savoir que les données auxquelles ils accèdent sont stockées dans plusieurs systèmes analytiques sous-jacents. Le diagramme ci-dessous montre une structure complexe d’entrepôt de données accessible par des méthodes d’interface utilisateur globalement plus simples mais toujours aussi puissantes.
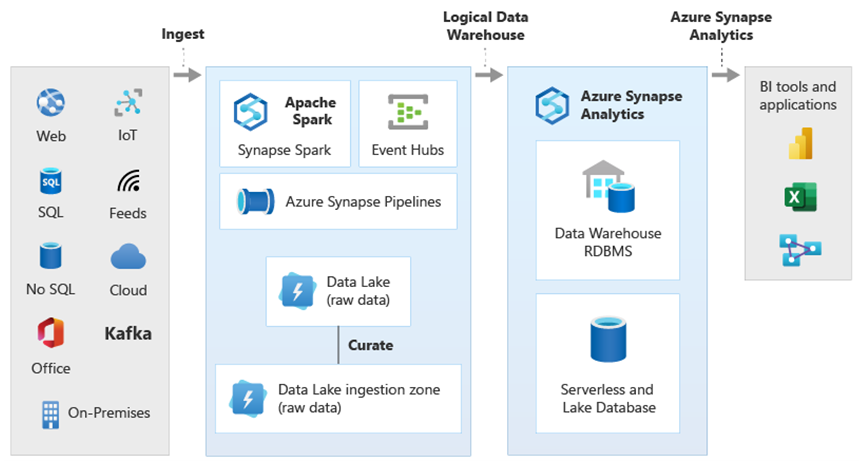
Le diagramme montre les possibilités de combiner d’autres technologies de l’écosystème analytique de Microsoft avec les fonctionnalités de l’architecture d’entrepôt de données logique dans Azure Synapse. Par exemple, les données peuvent être ingérées dans Azure Data Lake Storage et organisées avec Data Factory pour créer des produits de données fiables qui représentent les entités de données logiques de la base de données de lac Microsoft. Ces données approuvées, couramment comprises, peuvent ensuite être consommées et réutilisées dans différents environnements analytiques tels que Azure Synapse, des notebooks de pool Azure Synapse Spark ou Azure Cosmos DB. Tous les insights produits dans ces environnements sont accessibles via une couche de virtualisation des données d’entrepôt de données logique rendue possible par PolyBase.
Conseil
Une architecture d’entrepôt de données logique simplifie l’accès des utilisateurs métier aux données, et ajoute une nouvelle valeur aux informations dont vous disposez déjà dans votre entrepôt de données.
Conclusions
Une fois que vous avez migré votre entrepôt de données vers Azure Synapse, vous pouvez tirer parti d’autres technologies de l’écosystème analytique de Microsoft. Ainsi, vous pouvez non seulement moderniser votre entrepôt de données, mais également regrouper les insights produits dans d’autres magasins de données analytiques Azure au sein d’une architecture analytique intégrée.
Vous pouvez étendre votre traitement ETL pour ingérer des données de tout type dans Data Lake Storage, puis préparer et intégrer les données à grande échelle en utilisant Data Factory afin de produire des ressources de données fiables et largement comprises. Ces ressources peuvent être consommées par votre entrepôt de données et sont accessibles aux scientifiques des données et à d’autres applications. Vous pouvez créer des pipelines analytiques en temps réel et par lots, ainsi que des modèles Machine Learning à exécuter par lots, en temps réel sur des données de streaming et à la demande en tant que service.
Vous pouvez utiliser PolyBase ou COPY INTO en plus de votre entrepôt de données pour simplifier l’accès aux insights à partir de plusieurs plateformes analytiques sous-jacentes sur Azure. Pour cela, créez des vues holistiques intégrées dans un entrepôt de données logique qui prend en charge l’accès aux données de streaming, aux données volumineuses (Big Data) et aux insights d’entrepôts de données traditionnels à partir d’outils et d’applications décisionnels.
En migrant votre entrepôt de données vers Azure Synapse, vous pouvez tirer parti de la puissance de l’écosystème analytique de Microsoft sur Azure pour ajouter de la valeur à votre entreprise.
Étapes suivantes
Pour en savoir plus sur la migration vers un pool SQL dédié, consultez Migrer un entrepôt de données vers un pool SQL dédié dans Azure Synapse Analytics.