Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Synapse Analytics vous permet d’utiliser Apache Spark pour exécuter des blocs-notes, des travaux et d’autres types d’applications sur vos pools Apache Spark dans votre espace de travail.
Cet article explique comment surveiller vos applications Apache Spark, et ainsi garder un œil sur leur état, leurs problèmes et leur progression.
Afficher les applications Apache Spark
Vous pouvez voir toutes les applications Apache Spark sous Monitorer ->Applications Apache Spark.
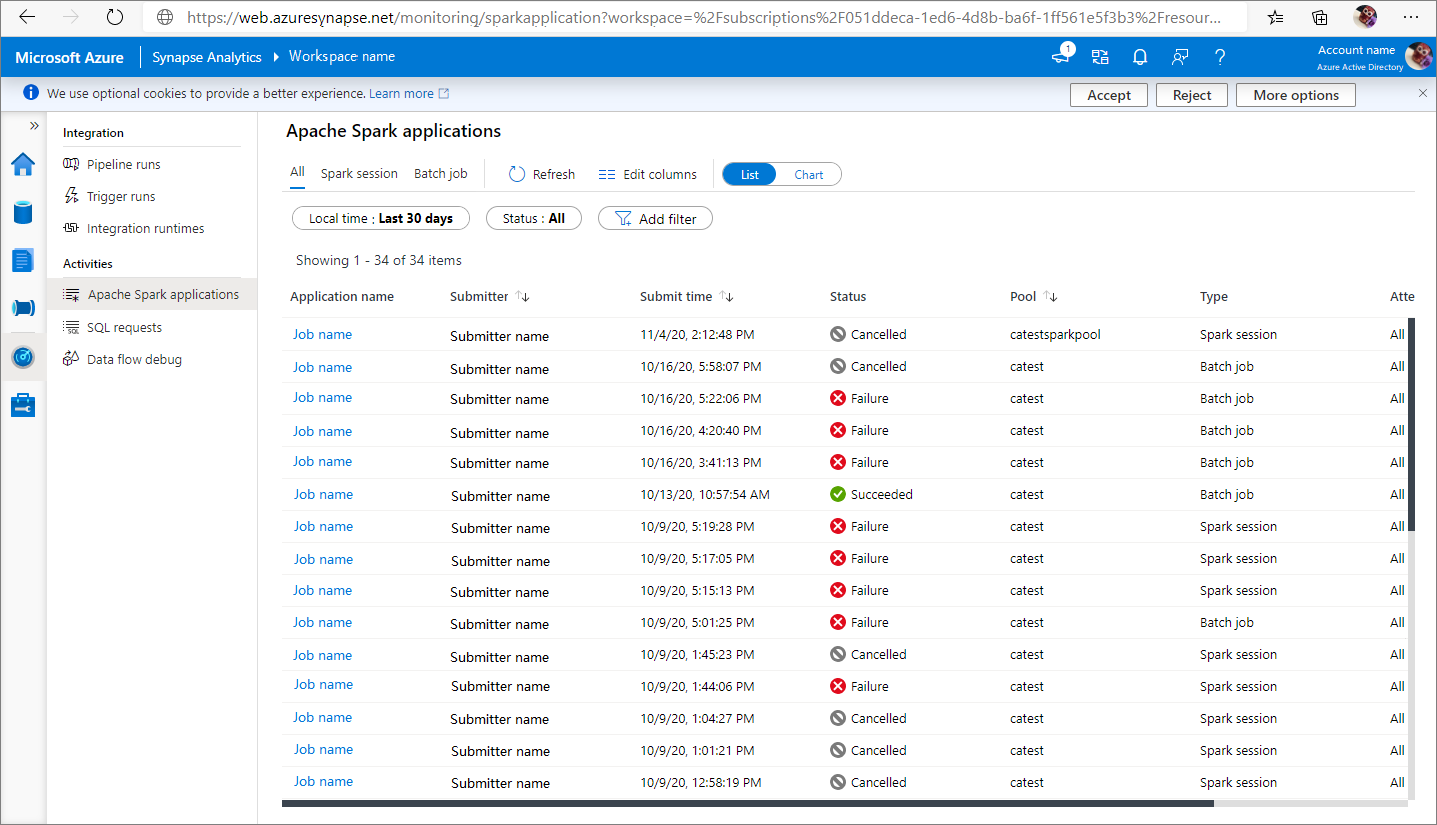
Afficher les applications Apache Spark terminées
Ouvrez Superviser, puis sélectionnez Applications Apache Spark. Pour afficher les détails des applications Apache Spark terminées, sélectionnez l’application Apache Spark concernée.

Consultez Tâches terminées, Statut et Durée totale.
Actualisez le travail.
Cliquez sur Comparer les applications pour utiliser la fonctionnalité de comparaison. Pour plus d’informations sur cette fonctionnalité, consultez Comparer des applications Apache Spark.
Cliquez sur Serveur d’historique Spark pour ouvrir la page Serveur d’historique.
Vérifiez les informations dans Résumé.
Vérifiez les diagnostics dans l’onglet Diagnostic.
Consultez les Journaux. Vous pouvez afficher l’enregistrement complet des journaux Livy, Prelaunch et Driver en sélectionnant différentes options dans la liste déroulante. Vous pouvez également récupérer directement les informations de journal requises en recherchant des mots clés. Cliquez sur Télécharger le journal pour télécharger les informations du journal sur l’emplacement local, puis cochez la case Filtrer les erreurs et les avertissements pour filtrer les erreurs et les avertissements dont vous avez besoin.
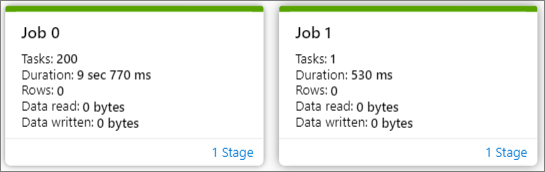
Vous pouvez voir une vue d’ensemble de votre travail dans le graphique du travail ainsi généré. Par défaut, le graphique affiche tous les travaux. Vous pouvez filtrer cet affichage par ID de travail.
Par défaut, l’affichage Progress (Progression) est sélectionné. Vous pouvez vérifier le flux de données en sélectionnant Progression/Lecture/Écriture/Durée dans la liste déroulante Affichage.
Pour lire le travail, cliquez sur le bouton Lire. Vous pouvez cliquer sur le bouton Arrêter à tout moment pour arrêter.
Utilisez la barre de défilement pour effectuer un zoom avant et un zoom arrière sur le graphique du travail. Vous pouvez également sélectionner Zoom ajusté pour l’ajuster à l’écran.

Le nœud de graphique du travail affiche les informations suivantes de chaque phase :
ID de travail
Nombre de tâches
Durée
Nombre de lignes
Lecture de données : somme de la taille d’entrée et de la taille de lecture aléatoire
Écriture de données : somme de la taille de sortie et de la taille des écritures aléatoires
Nombre d’étapes
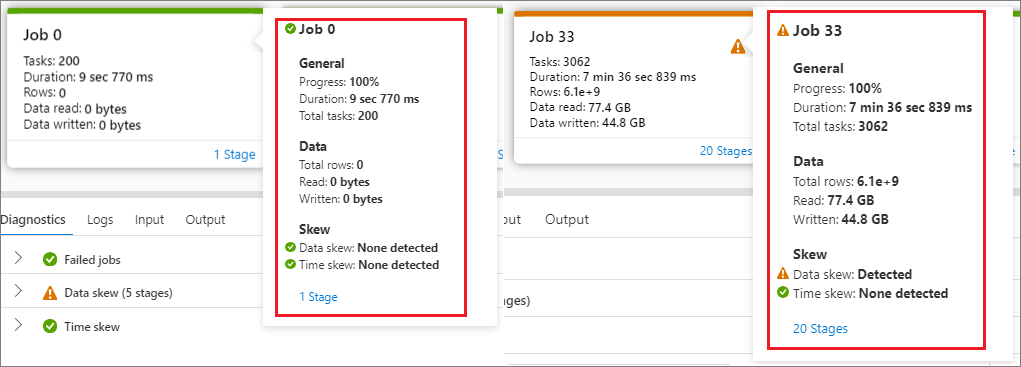
Pointez le curseur de la souris sur un travail, et les détails du travail s’affichent dans l’info-bulle :
Icône de l’état du travail : si l’état du travail est réussi, il s’affiche sous la forme d’un « √ » vert ; si le travail détecte un problème, il affiche un « ! » jaune.
ID de travail
Partie générale :
- Avancement
- Durée
- Nombre total de tâches
Partie sur les données :
- Nombre total de lignes
- Taille de lecture
- Taille d’écriture
Partie sur l’asymétrie :
- Asymétrie des données
- Asymétrie temporelle
Nombre d’étapes
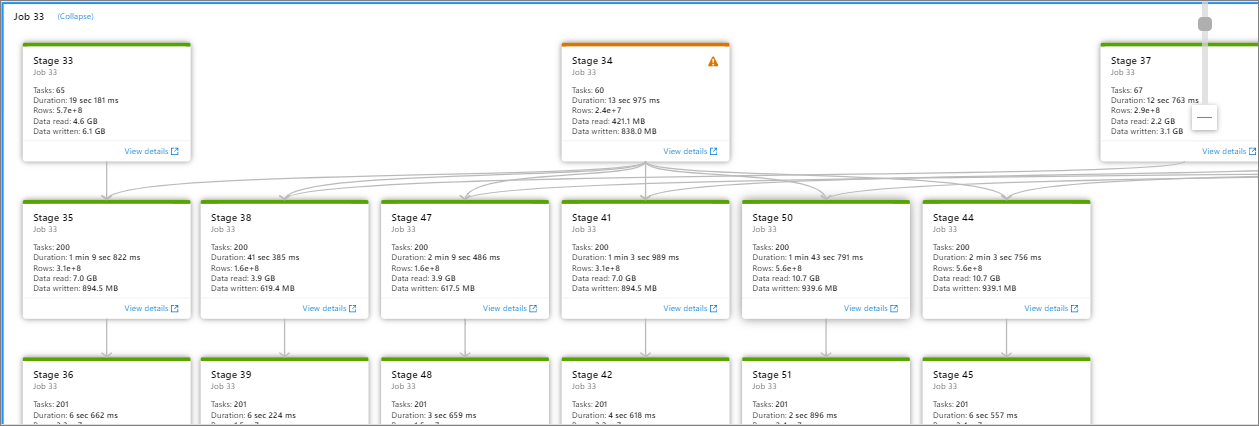
Cliquez sur Nombre d’étapes pour développer toutes les étapes contenues dans le travail. Cliquez sur Réduire à côté de l’ID de travail pour réduire toutes les étapes du travail.
Cliquez sur Afficher les détails dans le graphique d’une étape pour que les détails de l’étape s’affichent.

Surveiller la progression des applications Apache Spark
Ouvrez Superviser, puis sélectionnez Applications Apache Spark. Pour afficher les détails des applications Apache Spark en cours d’exécution, sélectionnez l’application Apache Spark concernée. Si l’application Apache Spark est toujours en cours d’exécution, vous pouvez surveiller la progression.

Consultez Tâches terminées, Statut et Durée totale.
Annulez l’exécution de l’application Apache Spark.
Actualisez le travail.
Cliquez sur le bouton Interface utilisateur Spark pour accéder à la page Travail Spark.
Pour Graphique du travail, Résumé, Diagnostics et Journaux, Vous pouvez voir une vue d’ensemble de votre travail dans le graphique du travail ainsi généré. Reportez-vous aux étapes 5 à 15 de la section Afficher les applications Apache Spark terminées.

Afficher les applications Apache Spark annulées
Ouvrez Superviser, puis sélectionnez Applications Apache Spark. Pour afficher les détails des applications Apache Spark annulées, sélectionnez l’application Apache Spark concernée.

Consultez Tâches terminées, Statut et Durée totale.
Actualisez le travail.
Cliquez sur Comparer les applications pour utiliser la fonctionnalité de comparaison. Pour plus d’informations sur cette fonctionnalité, consultez Comparer des applications Apache Spark.
Ouvrez le lien vers le serveur d’historique Apache en cliquant sur Serveur d’historique Spark.
Affichez le graphique. Vous pouvez voir une vue d’ensemble de votre travail dans le graphique du travail ainsi généré. Reportez-vous aux étapes 5 à 15 de la section Afficher les applications Apache Spark terminées.

Déboguer une application Apache Spark défaillante
Ouvrez Superviser, puis sélectionnez Applications Apache Spark. Pour afficher les détails des applications Apache Spark défaillantes, sélectionnez l’application Apache Spark concernée.

Consultez Tâches terminées, Statut et Durée totale.
Actualisez le travail.
Cliquez sur Comparer les applications pour utiliser la fonctionnalité de comparaison. Pour plus d’informations sur cette fonctionnalité, consultez Comparer des applications Apache Spark.
Ouvrez le lien vers le serveur d’historique Apache en cliquant sur Serveur d’historique Spark.
Affichez le graphique. Vous pouvez voir une vue d’ensemble de votre travail dans le graphique du travail ainsi généré. Reportez-vous aux étapes 5 à 15 de la section Afficher les applications Apache Spark terminées.

Afficher les données d’entrée/de sortie
Sélectionnez une application Apache Spark, puis cliquez sur l’onglet Données d’entrée/de sortie pour afficher les dates de l’entrée et de la sortie des applications Apache Spark. Cette fonction peut vous aider à déboguer le travail Spark. De plus, la source de données prend en charge trois méthodes de stockage : gen1, gen2 et blob.
Onglet Données d’entrée
Cliquez sur le bouton Copier l’entrée pour coller le fichier d’entrée dans l’emplacement local.
Cliquez sur le bouton Exporter au format CSV pour exporter le fichier d’entrée au format CSV.
Vous pouvez rechercher des fichiers en entrant des mots clés dans Zone de recherche (les mots clés incluent le nom du fichier, le format de lecture et le chemin d’accès).
Vous pouvez trier les fichiers d’entrée en cliquant sur Nom, Format de lecture et Chemin d’accès.
Si vous pointez le curseur de la souris sur un fichier d’entrée, le bouton Télécharger/Copier le chemin d’accès/Plus s’affiche.
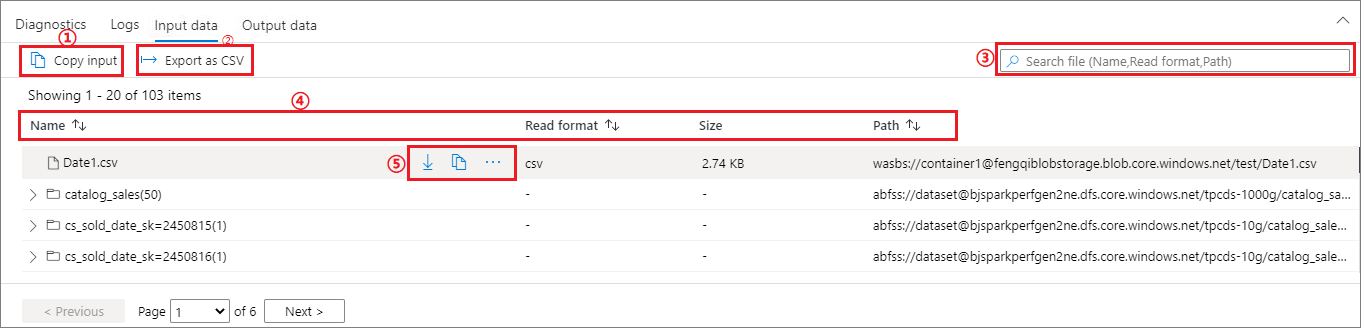
Cliquez sur le bouton Plus. Copier le chemin d’accès/Afficher dans Explorer/Propriétés apparaît dans le menu contextuel.
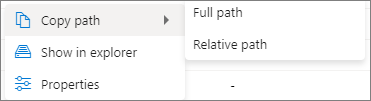
Copier le chemin d’accès : peut copier le chemin d’accès complet et le chemin d’accès relatif.
Afficher dans l’explorateur : permet d’accéder au compte de stockage lié (Données->Lié).
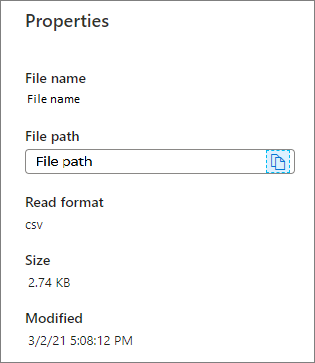
Propriétés : affiche les propriétés de base du fichier (Nom de fichier, Chemin d’accès du fichier, Format de lecture, Taille, Modifié).
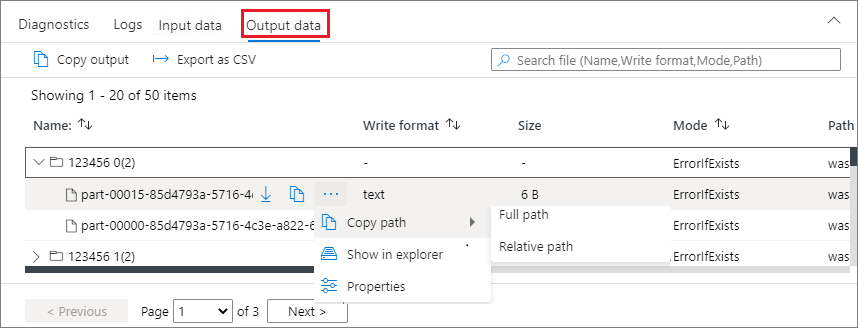
Onglet Données de sortie
Affiche les mêmes fonctionnalités que l’onglet d’entrée.
Comparer des applications Apache Spark
Il existe deux façons de comparer des applications. Vous pouvez comparer en choisissant de comparer une applicationou en cliquant sur le bouton Comparer dans le notebook pour afficher la comparaison dans le notebook.
Comparer par application
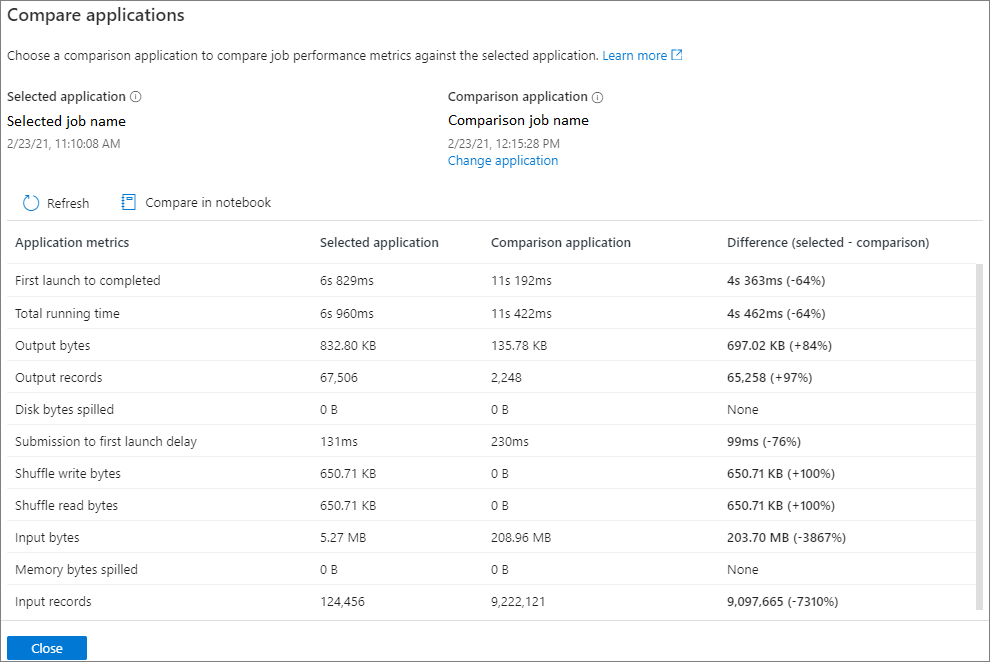
Cliquez sur le bouton Comparer des applications et choisissez une application pour comparer ses performances. Vous pouvez voir la différence entre les deux applications.


Utilisez la souris pour survoler une application et l’icône Comparer des applications s’affiche.
Cliquez sur l’icône Comparer des applications et la page Comparer des applications s’affiche.
Cliquez sur le bouton Choisir une application pour ouvrir la page Choisir une application de comparaison.
Lorsque vous choisissez l’application pour la comparaison, vous devez entrer l’URL de l’application ou choisir dans la liste périodique. Cliquez ensuite sur le bouton OK.
Le résultat de la comparaison s’affiche sur la page comparer des applications.
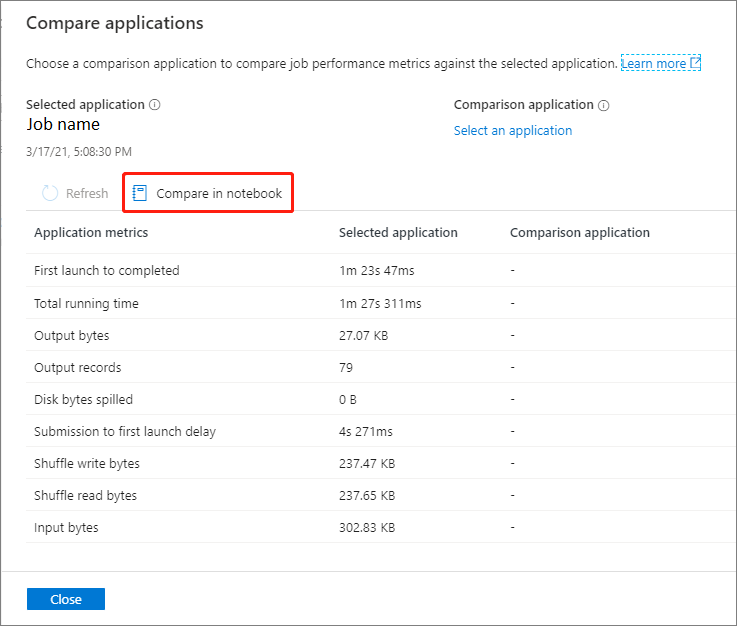
Comparer dans le notebook
Cliquez sur le bouton Comparer dans le bloc-notes sur la page Comparer les applications pour ouvrir le bloc-notes. Le nom par défaut du fichier .ipynb est Analyse de l’application actualisée.
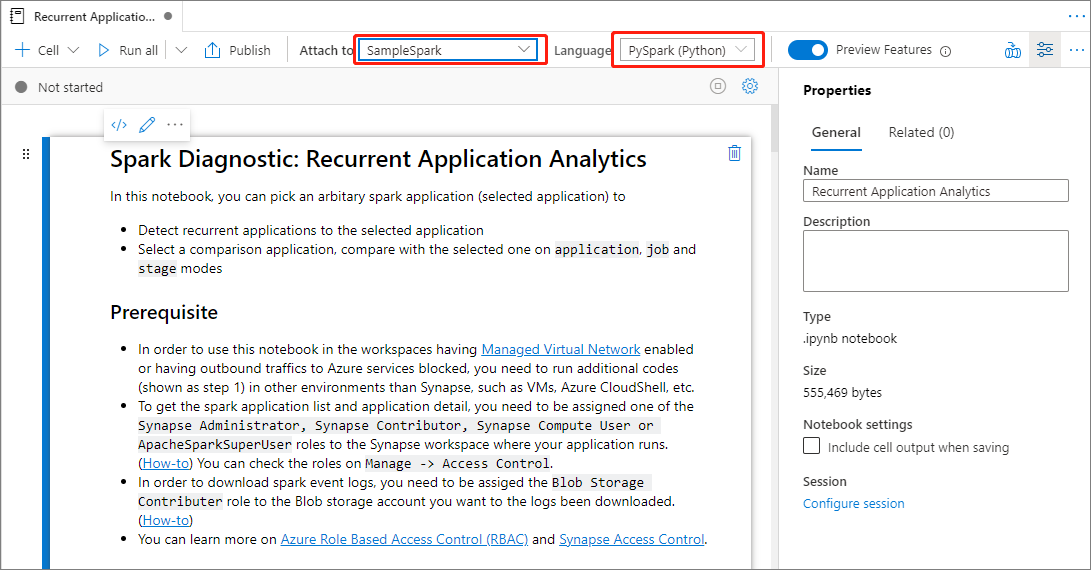
Dans le bloc-notes : fichier d’analyse de l’application actualisée, vous pouvez exécuter l’application directement après avoir défini le pool Spark et la langue.
Étapes suivantes
Pour plus d’informations sur la surveillance des exécutions de pipeline, consultez l’article Surveiller les exécutions de pipeline à l’aide de Synapse Studio.