Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Après avoir identifié les packages Scala, Java, R (préversion) ou Python que vous souhaitez utiliser ou mettre à jour pour votre application Spark, vous pouvez les installer ou les supprimer depuis un pool Spark. Les bibliothèques de pools sont disponibles pour tous les notebooks et toutes les tâches qui s’exécutent sur le pool.
Vous pouvez installer une bibliothèque sur un pool Spark de deux manières principales :
- Installer une bibliothèque d’espace de travail qui a été chargée en tant que package d’espace de travail.
- Pour mettre à jour les bibliothèques Python, fournir une spécification d’environnement requirements.txt ou Conda environment.yml pour installer des packages à partir de référentiels tels que PyPI ou Conda-Forge. Pour plus d’informations, consultez la section Formats de spécification d’environnement.
Une fois les modifications enregistrées, un travail Spark exécute l’installation et met en cache l’environnement obtenu pour une réutilisation ultérieure. Une fois le travail terminé, les nouveaux travaux Spark ou les nouvelles sessions de notebook utilisent les bibliothèques de pools mises à jour.
Important
- Si le package que vous installez est volumineux ou si son installation prend beaucoup de temps, le temps de démarrage de l’instance Spark est affecté.
- La modification de la version de PySpark, Python, Scala/Java, .NET, R ou Spark n’est pas prise en charge.
- L’installation de packages à partir de dépôts externes comme PyPI, Conda-Forge ou des canaux Conda par défaut n’est pas prise en charge dans les espaces de travail avec la protection contre l’exfiltration de données activée.
Gérer les packages à partir de Synapse Studio ou du Portail Azure
Vous pouvez gérer les bibliothèques de pools Spark depuis Synapse Studio ou le Portail Azure.
Accédez à votre espace de travail Azure Synapse Analytics dans le portail Azure.
Depuis la section Pools Analytics, sélectionnez l’onglet Pools Apache Spark et sélectionnez un pool Spark dans la liste.
Sélectionnez les packages dans la section Paramètres du pool Spark.
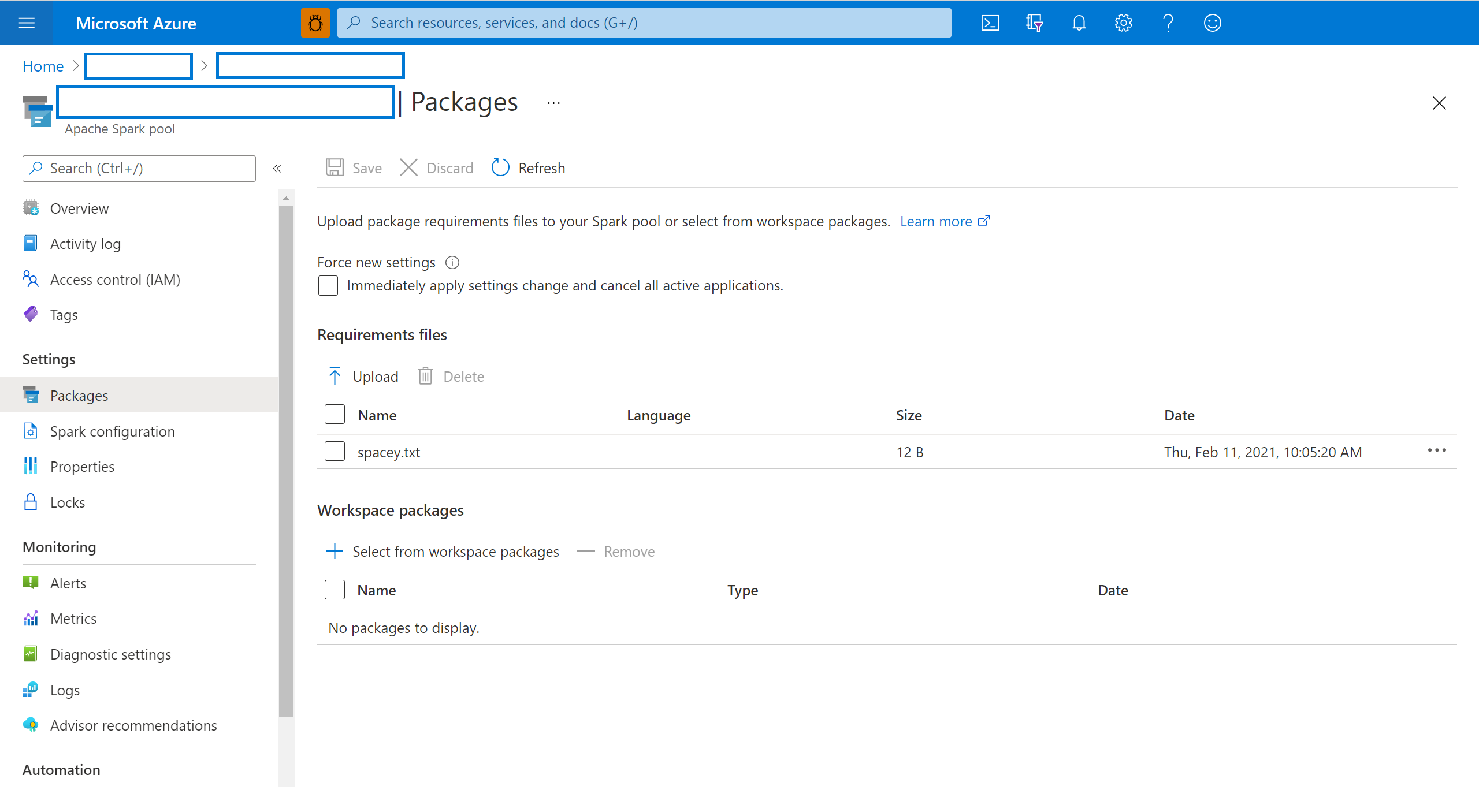
Pour les bibliothèques de flux Python, chargez le fichier config de l’environnement en utilisant le sélecteur de fichiers dans la section Packages de la page.
Vous pouvez également sélectionner des packages d’espace de travail supplémentaires pour ajouter des fichiers Jar, Wheel ou Tar.gz à votre pool.
Vous pouvez également supprimer les packages déconseillés de la section Packages d’espace de travail. Votre pool n’attachera plus ces packages.
Une fois vos modifications enregistrées, une tâche système se déclenche pour installer et mettre en cache les bibliothèques spécifiées. Ce processus permet de réduire le temps de démarrage global de la session.
Une fois le travail terminé, toutes les nouvelles sessions récupèrent les bibliothèques de pool mises à jour.


Important
En sélectionnant l’option Forcer les nouveaux paramètres, vous terminez toutes les sessions actives pour le pool Spark sélectionné. Une fois les sessions terminées, vous devez attendre le redémarrage du pool.
Si ce paramètre est désactivé, vous devez attendre que la session Spark en cours se termine ou l’arrêter manuellement. Une fois la session terminée, vous devez laisser le pool redémarrer.
Vérifier la progression de l’installation
Un travail Spark réservé au système démarre chaque fois qu’un pool est mis à jour avec un nouvel ensemble de bibliothèques. Ce travail Spark permet de surveiller l’état de l’installation de la bibliothèque. En cas d’échec de l’installation suite à des conflits avec la bibliothèque ou à d’autres problèmes, l’état précédent ou l’état par défaut du pool Spark est rétabli.
De plus, les utilisateurs peuvent consulter les journaux d’installation pour identifier les conflits de dépendance ou vérifier quelles bibliothèques ont été installées lors de la mise à jour du pool.
Pour afficher ces journaux :
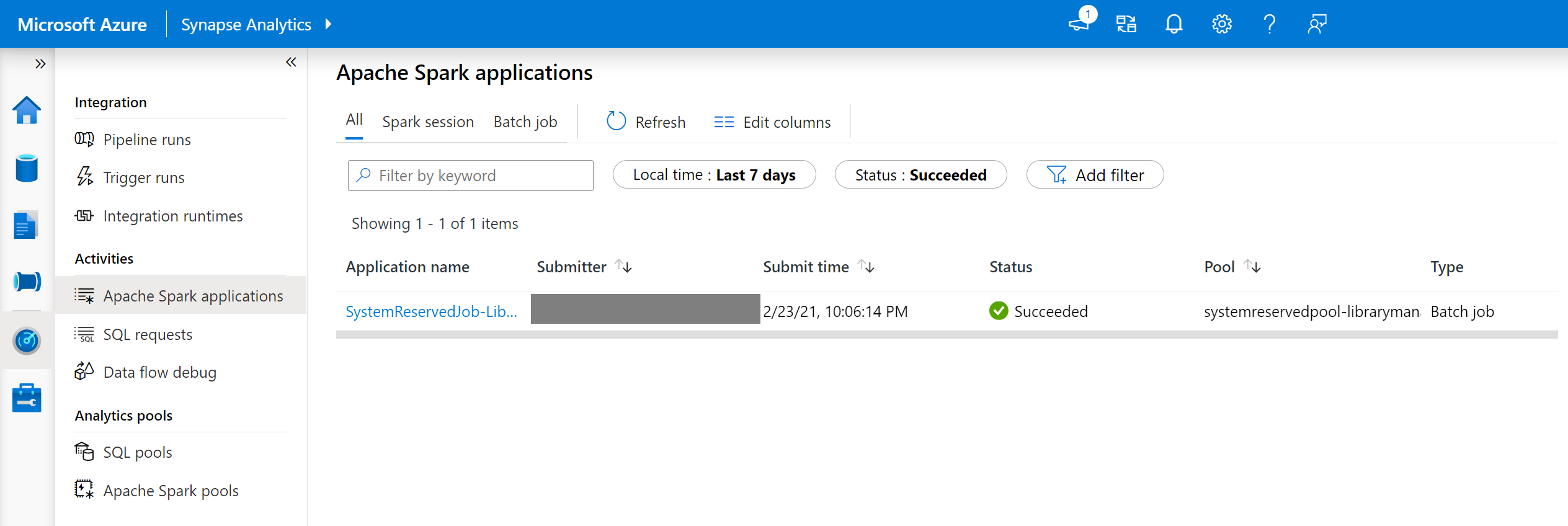
Dans Synapse Studio, accédez à la liste des applications Spark dans l’onglet Surveiller.
Sélectionnez la tâche de l’application Spark du système qui correspond à la mise à jour de votre pool. Ces tâches système s’exécutent sous le titre SystemReservedJob-LibraryManagement.
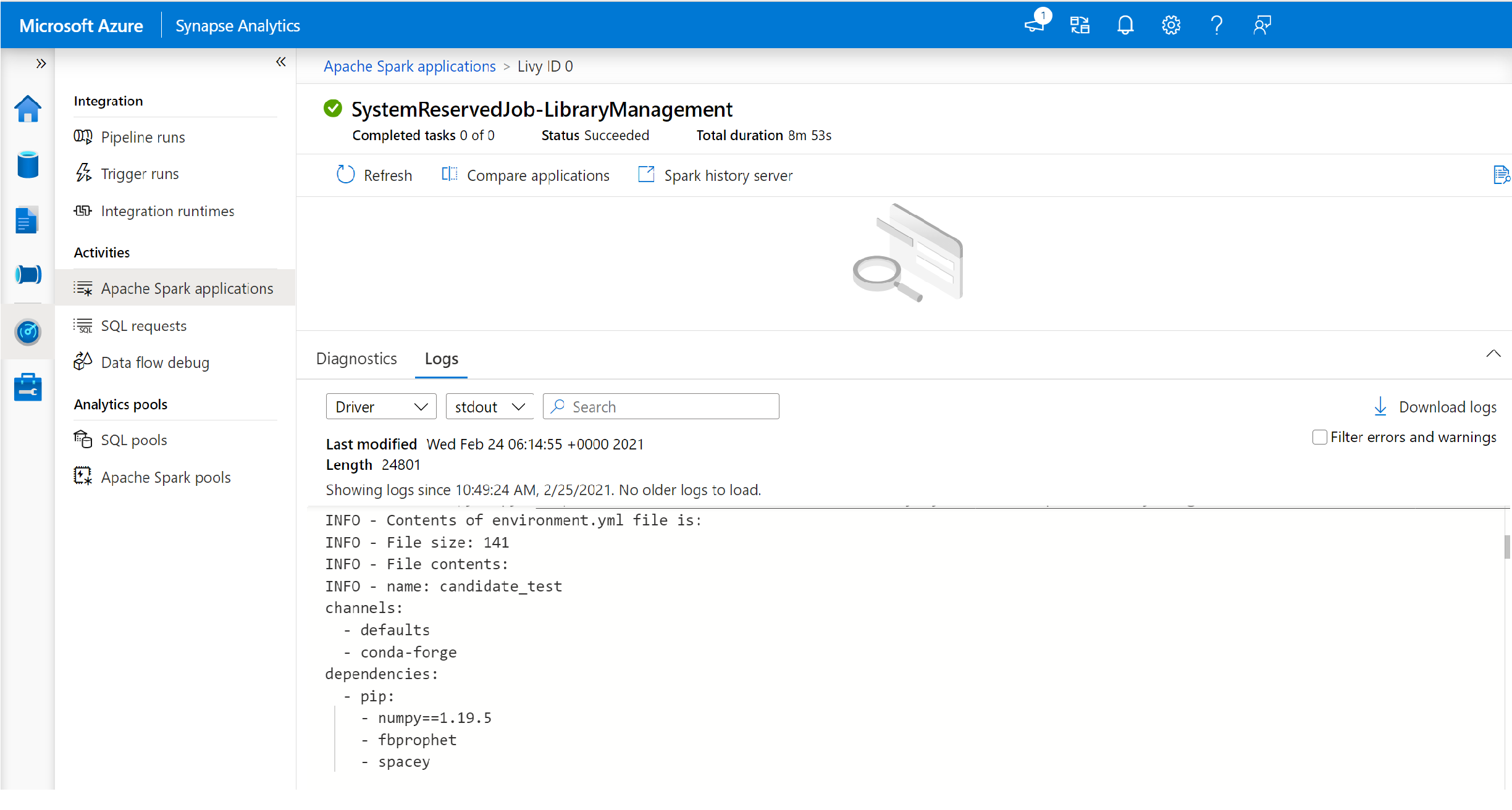
Affichez les journaux du pilote et stdout.
Les résultats contiennent les journaux liés à l’installation de vos dépendances.


Formats des spécifications d’environnement
PIP requirements.txt
Un fichier requirements.txt (sortie de la commande pip freeze) permet de mettre à niveau l’environnement. Lorsqu’un pool est mis à jour, les packages répertoriés dans ce fichier sont téléchargés à partir de PyPI. Les dépendances complètes sont ensuite mises en cache et enregistrées pour une réutilisation ultérieure du pool.
L’extrait de code suivant montre le format du fichier de configuration requise. Le nom du package PyPI est mentionné avec une version exacte. Ce fichier est au format décrit dans la documentation de référence pip freeze.
Cet exemple épingle une version spécifique.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Format YML
Par ailleurs, vous pouvez également fournir un fichier environment.yml pour mettre à jour l’environnement du pool. Les packages répertoriés dans ce fichier sont téléchargés à partir des canaux Conda par défaut, Conda-Forge et PyPI. Vous pouvez spécifier d’autres canaux ou supprimer les canaux par défaut à l’aide des options de configuration.
Cet exemple spécifie les canaux et les dépendances Conda/PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Pour plus d’informations sur la création d’un environnement à partir de ce fichier environment.yml, consultez Activation d’un environnement.